 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Inter-vendor harmonization of Computed Tomography (CT) reconstruction kernels using unpaired image translation
Sep 22, 2023
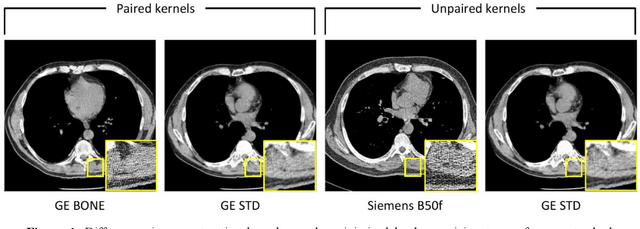
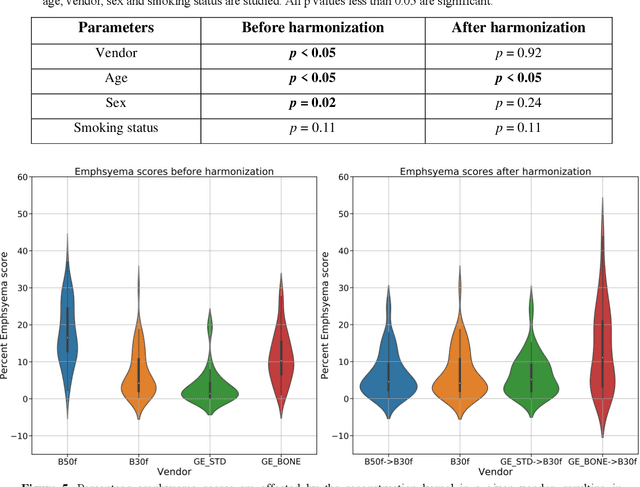
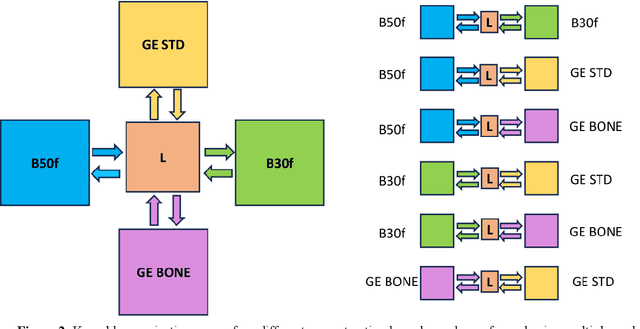
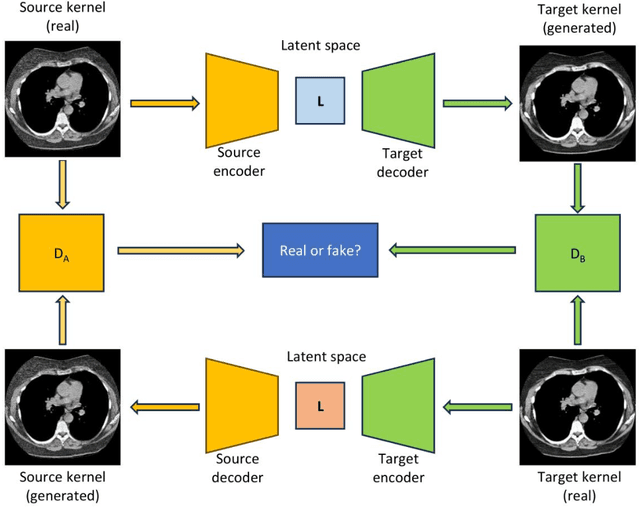
The reconstruction kernel in computed tomography (CT) generation determines the texture of the image. Consistency in reconstruction kernels is important as the underlying CT texture can impact measurements during quantitative image analysis. Harmonization (i.e., kernel conversion) minimizes differences in measurements due to inconsistent reconstruction kernels. Existing methods investigate harmonization of CT scans in single or multiple manufacturers. However, these methods require paired scans of hard and soft reconstruction kernels that are spatially and anatomically aligned. Additionally, a large number of models need to be trained across different kernel pairs within manufacturers. In this study, we adopt an unpaired image translation approach to investigate harmonization between and across reconstruction kernels from different manufacturers by constructing a multipath cycle generative adversarial network (GAN). We use hard and soft reconstruction kernels from the Siemens and GE vendors from the National Lung Screening Trial dataset. We use 50 scans from each reconstruction kernel and train a multipath cycle GAN. To evaluate the effect of harmonization on the reconstruction kernels, we harmonize 50 scans each from Siemens hard kernel, GE soft kernel and GE hard kernel to a reference Siemens soft kernel (B30f) and evaluate percent emphysema. We fit a linear model by considering the age, smoking status, sex and vendor and perform an analysis of variance (ANOVA) on the emphysema scores. Our approach minimizes differences in emphysema measurement and highlights the impact of age, sex, smoking status and vendor on emphysema quantification.
Visual Explanations via Iterated Integrated Attributions
Oct 28, 2023We introduce Iterated Integrated Attributions (IIA) - a generic method for explaining the predictions of vision models. IIA employs iterative integration across the input image, the internal representations generated by the model, and their gradients, yielding precise and focused explanation maps. We demonstrate the effectiveness of IIA through comprehensive evaluations across various tasks, datasets, and network architectures. Our results showcase that IIA produces accurate explanation maps, outperforming other state-of-the-art explanation techniques.
End-to-End Learned Event- and Image-based Visual Odometry
Sep 18, 2023Visual Odometry (VO) is crucial for autonomous robotic navigation, especially in GPS-denied environments like planetary terrains. While standard RGB cameras struggle in low-light or high-speed motion, event-based cameras offer high dynamic range and low latency. However, seamlessly integrating asynchronous event data with synchronous frames remains challenging. We introduce RAMP-VO, the first end-to-end learned event- and image-based VO system. It leverages novel Recurrent, Asynchronous, and Massively Parallel (RAMP) encoders that are 8x faster and 20% more accurate than existing asynchronous encoders. RAMP-VO further employs a novel pose forecasting technique to predict future poses for initialization. Despite being trained only in simulation, RAMP-VO outperforms image- and event-based methods by 52% and 20%, respectively, on traditional, real-world benchmarks as well as newly introduced Apollo and Malapert landing sequences, paving the way for robust and asynchronous VO in space.
Meaning Representations from Trajectories in Autoregressive Models
Nov 02, 2023We propose to extract meaning representations from autoregressive language models by considering the distribution of all possible trajectories extending an input text. This strategy is prompt-free, does not require fine-tuning, and is applicable to any pre-trained autoregressive model. Moreover, unlike vector-based representations, distribution-based representations can also model asymmetric relations (e.g., direction of logical entailment, hypernym/hyponym relations) by using algebraic operations between likelihood functions. These ideas are grounded in distributional perspectives on semantics and are connected to standard constructions in automata theory, but to our knowledge they have not been applied to modern language models. We empirically show that the representations obtained from large models align well with human annotations, outperform other zero-shot and prompt-free methods on semantic similarity tasks, and can be used to solve more complex entailment and containment tasks that standard embeddings cannot handle. Finally, we extend our method to represent data from different modalities (e.g., image and text) using multimodal autoregressive models.
Deep Nonparametric Convexified Filtering for Computational Photography, Image Synthesis and Adversarial Defense
Sep 13, 2023
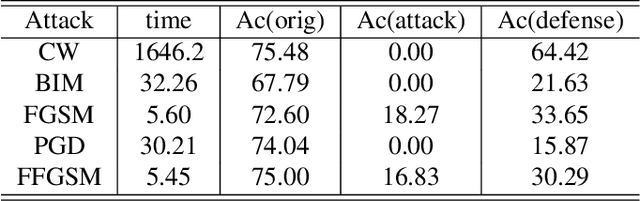


We aim to provide a general framework of for computational photography that recovers the real scene from imperfect images, via the Deep Nonparametric Convexified Filtering (DNCF). It is consists of a nonparametric deep network to resemble the physical equations behind the image formation, such as denoising, super-resolution, inpainting, and flash. DNCF has no parameterization dependent on training data, therefore has a strong generalization and robustness to adversarial image manipulation. During inference, we also encourage the network parameters to be nonnegative and create a bi-convex function on the input and parameters, and this adapts to second-order optimization algorithms with insufficient running time, having 10X acceleration over Deep Image Prior. With these tools, we empirically verify its capability to defend image classification deep networks against adversary attack algorithms in real-time.
Uncovering Prototypical Knowledge for Weakly Open-Vocabulary Semantic Segmentation
Oct 29, 2023This paper studies the problem of weakly open-vocabulary semantic segmentation (WOVSS), which learns to segment objects of arbitrary classes using mere image-text pairs. Existing works turn to enhance the vanilla vision transformer by introducing explicit grouping recognition, i.e., employing several group tokens/centroids to cluster the image tokens and perform the group-text alignment. Nevertheless, these methods suffer from a granularity inconsistency regarding the usage of group tokens, which are aligned in the all-to-one v.s. one-to-one manners during the training and inference phases, respectively. We argue that this discrepancy arises from the lack of elaborate supervision for each group token. To bridge this granularity gap, this paper explores explicit supervision for the group tokens from the prototypical knowledge. To this end, this paper proposes the non-learnable prototypical regularization (NPR) where non-learnable prototypes are estimated from source features to serve as supervision and enable contrastive matching of the group tokens. This regularization encourages the group tokens to segment objects with less redundancy and capture more comprehensive semantic regions, leading to increased compactness and richness. Based on NPR, we propose the prototypical guidance segmentation network (PGSeg) that incorporates multi-modal regularization by leveraging prototypical sources from both images and texts at different levels, progressively enhancing the segmentation capability with diverse prototypical patterns. Experimental results show that our proposed method achieves state-of-the-art performance on several benchmark datasets. The source code is available at https://github.com/Ferenas/PGSeg.
Mask Propagation for Efficient Video Semantic Segmentation
Oct 29, 2023
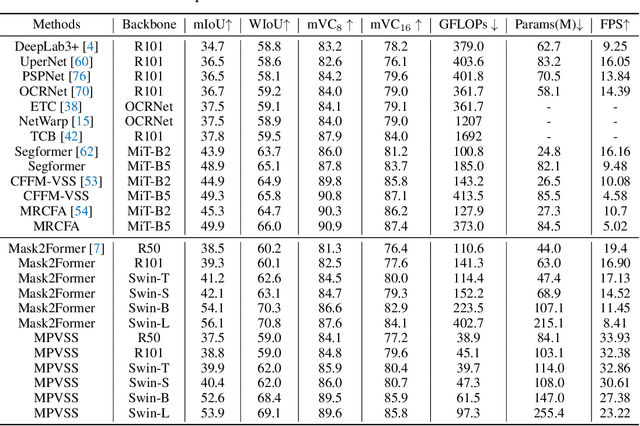
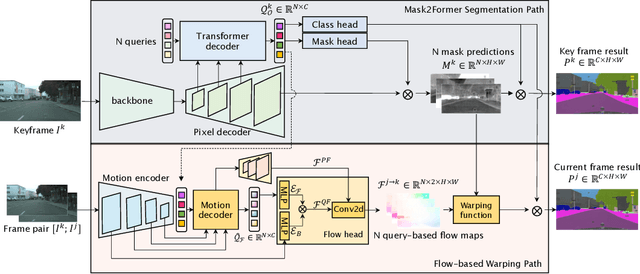
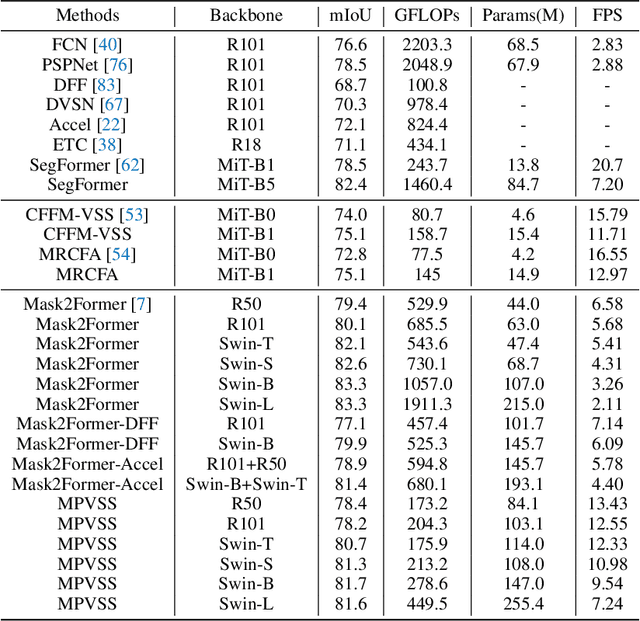
Video Semantic Segmentation (VSS) involves assigning a semantic label to each pixel in a video sequence. Prior work in this field has demonstrated promising results by extending image semantic segmentation models to exploit temporal relationships across video frames; however, these approaches often incur significant computational costs. In this paper, we propose an efficient mask propagation framework for VSS, called MPVSS. Our approach first employs a strong query-based image segmentor on sparse key frames to generate accurate binary masks and class predictions. We then design a flow estimation module utilizing the learned queries to generate a set of segment-aware flow maps, each associated with a mask prediction from the key frame. Finally, the mask-flow pairs are warped to serve as the mask predictions for the non-key frames. By reusing predictions from key frames, we circumvent the need to process a large volume of video frames individually with resource-intensive segmentors, alleviating temporal redundancy and significantly reducing computational costs. Extensive experiments on VSPW and Cityscapes demonstrate that our mask propagation framework achieves SOTA accuracy and efficiency trade-offs. For instance, our best model with Swin-L backbone outperforms the SOTA MRCFA using MiT-B5 by 4.0% mIoU, requiring only 26% FLOPs on the VSPW dataset. Moreover, our framework reduces up to 4x FLOPs compared to the per-frame Mask2Former baseline with only up to 2% mIoU degradation on the Cityscapes validation set. Code is available at https://github.com/ziplab/MPVSS.
Addressing Data Misalignment in Image-LiDAR Fusion on Point Cloud Segmentation
Sep 26, 2023

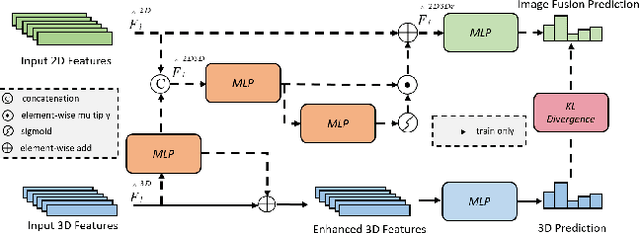
With the advent of advanced multi-sensor fusion models, there has been a notable enhancement in the performance of perception tasks within in terms of autonomous driving. Despite these advancements, the challenges persist, particularly in the fusion of data from cameras and LiDAR sensors. A critial concern is the accurate alignment of data from these disparate sensors. Our observations indicate that the projected positions of LiDAR points often misalign on the corresponding image. Furthermore, fusion models appear to struggle in accurately segmenting these misaligned points. In this paper, we would like to address this problem carefully, with a specific focus on the nuScenes dataset and the SOTA of fusion models 2DPASS, and providing the possible solutions or potential improvements.
Continual Learning of Unsupervised Monocular Depth from Videos
Nov 04, 2023Spatial scene understanding, including monocular depth estimation, is an important problem in various applications, such as robotics and autonomous driving. While improvements in unsupervised monocular depth estimation have potentially allowed models to be trained on diverse crowdsourced videos, this remains underexplored as most methods utilize the standard training protocol, wherein the models are trained from scratch on all data after new data is collected. Instead, continual training of models on sequentially collected data would significantly reduce computational and memory costs. Nevertheless, naive continual training leads to catastrophic forgetting, where the model performance deteriorates on older domains as it learns on newer domains, highlighting the trade-off between model stability and plasticity. While several techniques have been proposed to address this issue in image classification, the high-dimensional and spatiotemporally correlated outputs of depth estimation make it a distinct challenge. To the best of our knowledge, no framework or method currently exists focusing on the problem of continual learning in depth estimation. Thus, we introduce a framework that captures the challenges of continual unsupervised depth estimation (CUDE), and define the necessary metrics to evaluate model performance. We propose a rehearsal-based dual-memory method, MonoDepthCL, which utilizes spatiotemporal consistency for continual learning in depth estimation, even when the camera intrinsics are unknown.
Maximal Volume Matrix Cross Approximation for Image Compression and Least Squares Solution
Sep 29, 2023We study the classic cross approximation of matrices based on the maximal volume submatrices. Our main results consist of an improvement of a classic estimate for matrix cross approximation and a greedy approach for finding the maximal volume submatrices. Indeed, we present a new proof of a classic estimate of the inequality with an improved constant. Also, we present a family of greedy maximal volume algorithms which improve the error bound of cross approximation of a matrix in the Chebyshev norm and also improve the computational efficiency of classic maximal volume algorithm. The proposed algorithms are shown to have theoretical guarantees of convergence. Finally, we present two applications: one is image compression and the other is least squares approximation of continuous functions. Our numerical results in the end of the paper demonstrate the effective performances of our approach.