 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Emergent Communication in Interactive Sketch Question Answering
Oct 24, 2023
Vision-based emergent communication (EC) aims to learn to communicate through sketches and demystify the evolution of human communication. Ironically, previous works neglect multi-round interaction, which is indispensable in human communication. To fill this gap, we first introduce a novel Interactive Sketch Question Answering (ISQA) task, where two collaborative players are interacting through sketches to answer a question about an image in a multi-round manner. To accomplish this task, we design a new and efficient interactive EC system, which can achieve an effective balance among three evaluation factors, including the question answering accuracy, drawing complexity and human interpretability. Our experimental results including human evaluation demonstrate that multi-round interactive mechanism facilitates targeted and efficient communication between intelligent agents with decent human interpretability.
Mixed Graph Signal Analysis of Joint Image Denoising / Interpolation
Sep 18, 2023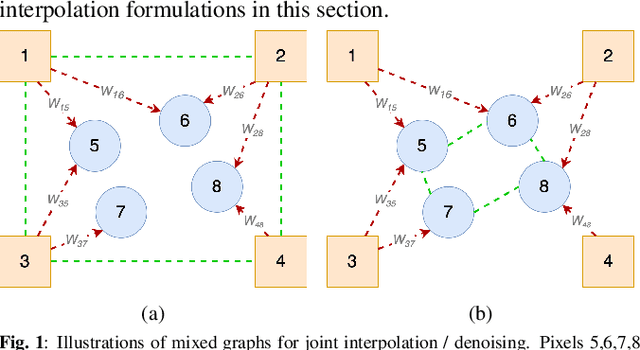
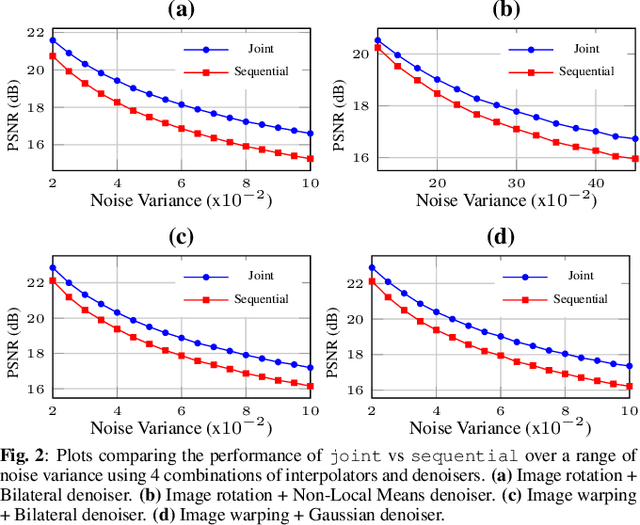
A noise-corrupted image often requires interpolation. Given a linear denoiser and a linear interpolator, when should the operations be independently executed in separate steps, and when should they be combined and jointly optimized? We study joint denoising / interpolation of images from a mixed graph filtering perspective: we model denoising using an undirected graph, and interpolation using a directed graph. We first prove that, under mild conditions, a linear denoiser is a solution graph filter to a maximum a posteriori (MAP) problem regularized using an undirected graph smoothness prior, while a linear interpolator is a solution to a MAP problem regularized using a directed graph smoothness prior. Next, we study two variants of the joint interpolation / denoising problem: a graph-based denoiser followed by an interpolator has an optimal separable solution, while an interpolator followed by a denoiser has an optimal non-separable solution. Experiments show that our joint denoising / interpolation method outperformed separate approaches noticeably.
Multi-task deep learning for large-scale building detail extraction from high-resolution satellite imagery
Oct 29, 2023Understanding urban dynamics and promoting sustainable development requires comprehensive insights about buildings. While geospatial artificial intelligence has advanced the extraction of such details from Earth observational data, existing methods often suffer from computational inefficiencies and inconsistencies when compiling unified building-related datasets for practical applications. To bridge this gap, we introduce the Multi-task Building Refiner (MT-BR), an adaptable neural network tailored for simultaneous extraction of spatial and attributional building details from high-resolution satellite imagery, exemplified by building rooftops, urban functional types, and roof architectural types. Notably, MT-BR can be fine-tuned to incorporate additional building details, extending its applicability. For large-scale applications, we devise a novel spatial sampling scheme that strategically selects limited but representative image samples. This process optimizes both the spatial distribution of samples and the urban environmental characteristics they contain, thus enhancing extraction effectiveness while curtailing data preparation expenditures. We further enhance MT-BR's predictive performance and generalization capabilities through the integration of advanced augmentation techniques. Our quantitative results highlight the efficacy of the proposed methods. Specifically, networks trained with datasets curated via our sampling method demonstrate improved predictive accuracy relative to those using alternative sampling approaches, with no alterations to network architecture. Moreover, MT-BR consistently outperforms other state-of-the-art methods in extracting building details across various metrics. The real-world practicality is also demonstrated in an application across Shanghai, generating a unified dataset that encompasses both the spatial and attributional details of buildings.
Model Uncertainty based Active Learning on Tabular Data using Boosted Trees
Oct 30, 2023Supervised machine learning relies on the availability of good labelled data for model training. Labelled data is acquired by human annotation, which is a cumbersome and costly process, often requiring subject matter experts. Active learning is a sub-field of machine learning which helps in obtaining the labelled data efficiently by selecting the most valuable data instances for model training and querying the labels only for those instances from the human annotator. Recently, a lot of research has been done in the field of active learning, especially for deep neural network based models. Although deep learning shines when dealing with image\textual\multimodal data, gradient boosting methods still tend to achieve much better results on tabular data. In this work, we explore active learning for tabular data using boosted trees. Uncertainty based sampling in active learning is the most commonly used querying strategy, wherein the labels of those instances are sequentially queried for which the current model prediction is maximally uncertain. Entropy is often the choice for measuring uncertainty. However, entropy is not exactly a measure of model uncertainty. Although there has been a lot of work in deep learning for measuring model uncertainty and employing it in active learning, it is yet to be explored for non-neural network models. To this end, we explore the effectiveness of boosted trees based model uncertainty methods in active learning. Leveraging this model uncertainty, we propose an uncertainty based sampling in active learning for regression tasks on tabular data. Additionally, we also propose a novel cost-effective active learning method for regression tasks along with an improved cost-effective active learning method for classification tasks.
Grokking Tickets: Lottery Tickets Accelerate Grokking
Oct 30, 2023Grokking is one of the most surprising puzzles in neural network generalization: a network first reaches a memorization solution with perfect training accuracy and poor generalization, but with further training, it reaches a perfectly generalized solution. We aim to analyze the mechanism of grokking from the lottery ticket hypothesis, identifying the process to find the lottery tickets (good sparse subnetworks) as the key to describing the transitional phase between memorization and generalization. We refer to these subnetworks as ''Grokking tickets'', which is identified via magnitude pruning after perfect generalization. First, using ''Grokking tickets'', we show that the lottery tickets drastically accelerate grokking compared to the dense networks on various configurations (MLP and Transformer, and an arithmetic and image classification tasks). Additionally, to verify that ''Grokking ticket'' are a more critical factor than weight norms, we compared the ''good'' subnetworks with a dense network having the same L1 and L2 norms. Results show that the subnetworks generalize faster than the controlled dense model. In further investigations, we discovered that at an appropriate pruning rate, grokking can be achieved even without weight decay. We also show that speedup does not happen when using tickets identified at the memorization solution or transition between memorization and generalization or when pruning networks at the initialization (Random pruning, Grasp, SNIP, and Synflow). The results indicate that the weight norm of network parameters is not enough to explain the process of grokking, but the importance of finding good subnetworks to describe the transition from memorization to generalization. The implementation code can be accessed via this link: \url{https://github.com/gouki510/Grokking-Tickets}.
FreqAlign: Excavating Perception-oriented Transferability for Blind Image Quality Assessment from A Frequency Perspective
Sep 29, 2023
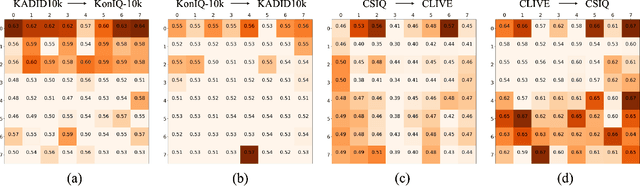
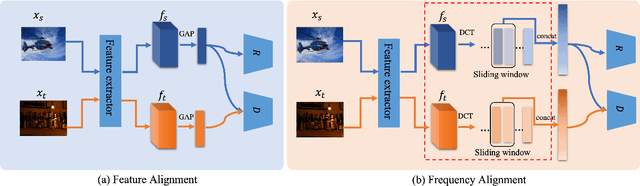
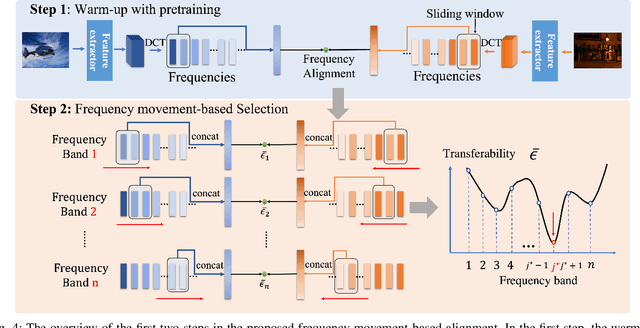
Blind Image Quality Assessment (BIQA) is susceptible to poor transferability when the distribution shift occurs, e.g., from synthesis degradation to authentic degradation. To mitigate this, some studies have attempted to design unsupervised domain adaptation (UDA) based schemes for BIQA, which intends to eliminate the domain shift through adversarial-based feature alignment. However, the feature alignment is usually taken at the low-frequency space of features since the global average pooling operation. This ignores the transferable perception knowledge in other frequency components and causes the sub-optimal solution for the UDA of BIQA. To overcome this, from a novel frequency perspective, we propose an effective alignment strategy, i.e., Frequency Alignment (dubbed FreqAlign), to excavate the perception-oriented transferability of BIQA in the frequency space. Concretely, we study what frequency components of features are more proper for perception-oriented alignment. Based on this, we propose to improve the perception-oriented transferability of BIQA by performing feature frequency decomposition and selecting the frequency components that contained the most transferable perception knowledge for alignment. To achieve a stable and effective frequency selection, we further propose the frequency movement with a sliding window to find the optimal frequencies for alignment, which is composed of three strategies, i.e., warm up with pre-training, frequency movement-based selection, and perturbation-based finetuning. Extensive experiments under different domain adaptation settings of BIQA have validated the effectiveness of our proposed method. The code will be released at https://github.com/lixinustc/Openworld-IQA.
Set-of-Mark Prompting Unleashes Extraordinary Visual Grounding in GPT-4V
Oct 17, 2023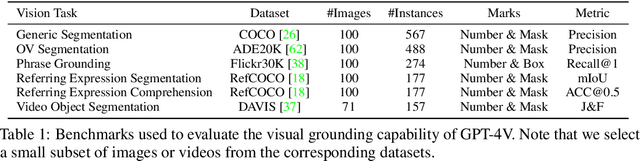

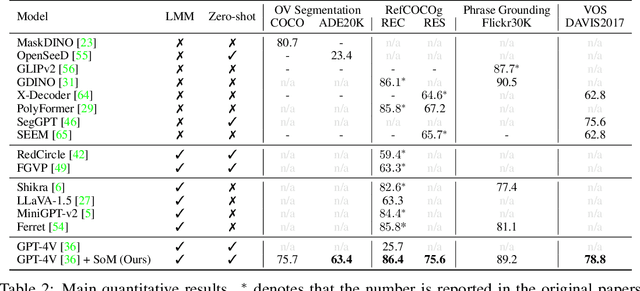

We present Set-of-Mark (SoM), a new visual prompting method, to unleash the visual grounding abilities of large multimodal models (LMMs), such as GPT-4V. As illustrated in Fig. 1 (right), we employ off-the-shelf interactive segmentation models, such as SAM, to partition an image into regions at different levels of granularity, and overlay these regions with a set of marks e.g., alphanumerics, masks, boxes. Using the marked image as input, GPT-4V can answer the questions that require visual grounding. We perform a comprehensive empirical study to validate the effectiveness of SoM on a wide range of fine-grained vision and multimodal tasks. For example, our experiments show that GPT-4V with SoM outperforms the state-of-the-art fully-finetuned referring segmentation model on RefCOCOg in a zero-shot setting.
Multi-scale Diffusion Denoised Smoothing
Oct 27, 2023Along with recent diffusion models, randomized smoothing has become one of a few tangible approaches that offers adversarial robustness to models at scale, e.g., those of large pre-trained models. Specifically, one can perform randomized smoothing on any classifier via a simple "denoise-and-classify" pipeline, so-called denoised smoothing, given that an accurate denoiser is available - such as diffusion model. In this paper, we present scalable methods to address the current trade-off between certified robustness and accuracy in denoised smoothing. Our key idea is to "selectively" apply smoothing among multiple noise scales, coined multi-scale smoothing, which can be efficiently implemented with a single diffusion model. This approach also suggests a new objective to compare the collective robustness of multi-scale smoothed classifiers, and questions which representation of diffusion model would maximize the objective. To address this, we propose to further fine-tune diffusion model (a) to perform consistent denoising whenever the original image is recoverable, but (b) to generate rather diverse outputs otherwise. Our experiments show that the proposed multi-scale smoothing scheme combined with diffusion fine-tuning enables strong certified robustness available with high noise level while maintaining its accuracy close to non-smoothed classifiers.
LipSim: A Provably Robust Perceptual Similarity Metric
Oct 27, 2023Recent years have seen growing interest in developing and applying perceptual similarity metrics. Research has shown the superiority of perceptual metrics over pixel-wise metrics in aligning with human perception and serving as a proxy for the human visual system. On the other hand, as perceptual metrics rely on neural networks, there is a growing concern regarding their resilience, given the established vulnerability of neural networks to adversarial attacks. It is indeed logical to infer that perceptual metrics may inherit both the strengths and shortcomings of neural networks. In this work, we demonstrate the vulnerability of state-of-the-art perceptual similarity metrics based on an ensemble of ViT-based feature extractors to adversarial attacks. We then propose a framework to train a robust perceptual similarity metric called LipSim (Lipschitz Similarity Metric) with provable guarantees. By leveraging 1-Lipschitz neural networks as the backbone, LipSim provides guarded areas around each data point and certificates for all perturbations within an $\ell_2$ ball. Finally, a comprehensive set of experiments shows the performance of LipSim in terms of natural and certified scores and on the image retrieval application. The code is available at https://github.com/SaraGhazanfari/LipSim.
SmooSeg: Smoothness Prior for Unsupervised Semantic Segmentation
Oct 27, 2023Unsupervised semantic segmentation is a challenging task that segments images into semantic groups without manual annotation. Prior works have primarily focused on leveraging prior knowledge of semantic consistency or priori concepts from self-supervised learning methods, which often overlook the coherence property of image segments. In this paper, we demonstrate that the smoothness prior, asserting that close features in a metric space share the same semantics, can significantly simplify segmentation by casting unsupervised semantic segmentation as an energy minimization problem. Under this paradigm, we propose a novel approach called SmooSeg that harnesses self-supervised learning methods to model the closeness relationships among observations as smoothness signals. To effectively discover coherent semantic segments, we introduce a novel smoothness loss that promotes piecewise smoothness within segments while preserving discontinuities across different segments. Additionally, to further enhance segmentation quality, we design an asymmetric teacher-student style predictor that generates smoothly updated pseudo labels, facilitating an optimal fit between observations and labeling outputs. Thanks to the rich supervision cues of the smoothness prior, our SmooSeg significantly outperforms STEGO in terms of pixel accuracy on three datasets: COCOStuff (+14.9%), Cityscapes (+13.0%), and Potsdam-3 (+5.7%).