 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
High-Quality 3D Face Reconstruction with Affine Convolutional Networks
Oct 22, 2023
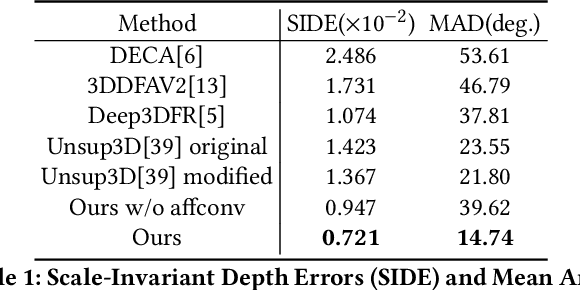
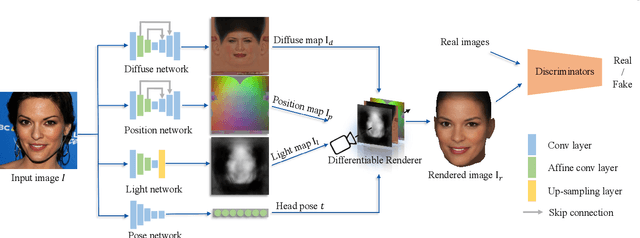
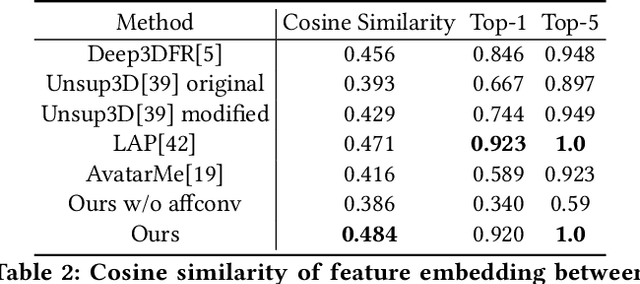
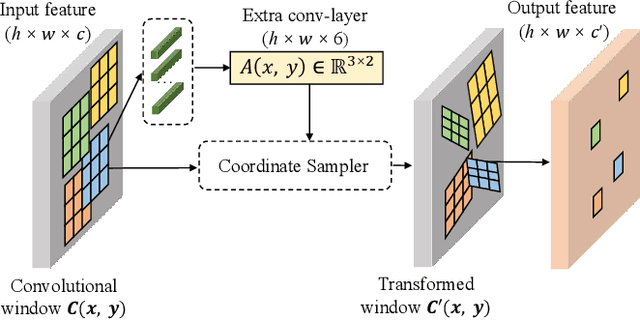
Recent works based on convolutional encoder-decoder architecture and 3DMM parameterization have shown great potential for canonical view reconstruction from a single input image. Conventional CNN architectures benefit from exploiting the spatial correspondence between the input and output pixels. However, in 3D face reconstruction, the spatial misalignment between the input image (e.g. face) and the canonical/UV output makes the feature encoding-decoding process quite challenging. In this paper, to tackle this problem, we propose a new network architecture, namely the Affine Convolution Networks, which enables CNN based approaches to handle spatially non-corresponding input and output images and maintain high-fidelity quality output at the same time. In our method, an affine transformation matrix is learned from the affine convolution layer for each spatial location of the feature maps. In addition, we represent 3D human heads in UV space with multiple components, including diffuse maps for texture representation, position maps for geometry representation, and light maps for recovering more complex lighting conditions in the real world. All the components can be trained without any manual annotations. Our method is parametric-free and can generate high-quality UV maps at resolution of 512 x 512 pixels, while previous approaches normally generate 256 x 256 pixels or smaller. Our code will be released once the paper got accepted.
Feature Proliferation -- the "Cancer" in StyleGAN and its Treatments
Oct 13, 2023
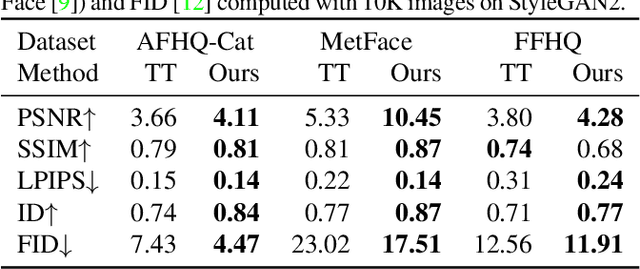
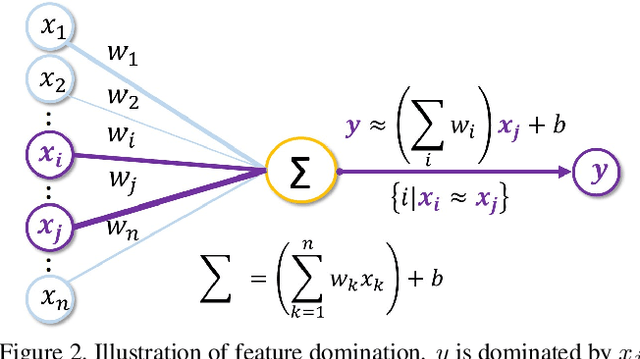
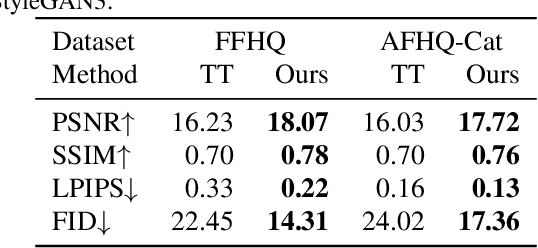
Despite the success of StyleGAN in image synthesis, the images it synthesizes are not always perfect and the well-known truncation trick has become a standard post-processing technique for StyleGAN to synthesize high-quality images. Although effective, it has long been noted that the truncation trick tends to reduce the diversity of synthesized images and unnecessarily sacrifices many distinct image features. To address this issue, in this paper, we first delve into the StyleGAN image synthesis mechanism and discover an important phenomenon, namely Feature Proliferation, which demonstrates how specific features reproduce with forward propagation. Then, we show how the occurrence of Feature Proliferation results in StyleGAN image artifacts. As an analogy, we refer to it as the" cancer" in StyleGAN from its proliferating and malignant nature. Finally, we propose a novel feature rescaling method that identifies and modulates risky features to mitigate feature proliferation. Thanks to our discovery of Feature Proliferation, the proposed feature rescaling method is less destructive and retains more useful image features than the truncation trick, as it is more fine-grained and works in a lower-level feature space rather than a high-level latent space. Experimental results justify the validity of our claims and the effectiveness of the proposed feature rescaling method. Our code is available at https://github. com/songc42/Feature-proliferation.
INCODE: Implicit Neural Conditioning with Prior Knowledge Embeddings
Oct 28, 2023Implicit Neural Representations (INRs) have revolutionized signal representation by leveraging neural networks to provide continuous and smooth representations of complex data. However, existing INRs face limitations in capturing fine-grained details, handling noise, and adapting to diverse signal types. To address these challenges, we introduce INCODE, a novel approach that enhances the control of the sinusoidal-based activation function in INRs using deep prior knowledge. INCODE comprises a harmonizer network and a composer network, where the harmonizer network dynamically adjusts key parameters of the activation function. Through a task-specific pre-trained model, INCODE adapts the task-specific parameters to optimize the representation process. Our approach not only excels in representation, but also extends its prowess to tackle complex tasks such as audio, image, and 3D shape reconstructions, as well as intricate challenges such as neural radiance fields (NeRFs), and inverse problems, including denoising, super-resolution, inpainting, and CT reconstruction. Through comprehensive experiments, INCODE demonstrates its superiority in terms of robustness, accuracy, quality, and convergence rate, broadening the scope of signal representation. Please visit the project's website for details on the proposed method and access to the code.
ODM3D: Alleviating Foreground Sparsity for Enhanced Semi-Supervised Monocular 3D Object Detection
Oct 28, 2023Monocular 3D object detection (M3OD) is a significant yet inherently challenging task in autonomous driving due to absence of implicit depth cues in a single RGB image. In this paper, we strive to boost currently underperforming monocular 3D object detectors by leveraging an abundance of unlabelled data via semi-supervised learning. Our proposed ODM3D framework entails cross-modal knowledge distillation at various levels to inject LiDAR-domain knowledge into a monocular detector during training. By identifying foreground sparsity as the main culprit behind existing methods' suboptimal training, we exploit the precise localisation information embedded in LiDAR points to enable more foreground-attentive and efficient distillation via the proposed BEV occupancy guidance mask, leading to notably improved knowledge transfer and M3OD performance. Besides, motivated by insights into why existing cross-modal GT-sampling techniques fail on our task at hand, we further design a novel cross-modal object-wise data augmentation strategy for effective RGB-LiDAR joint learning. Our method ranks 1st in both KITTI validation and test benchmarks, significantly surpassing all existing monocular methods, supervised or semi-supervised, on both BEV and 3D detection metrics.
Exploring Data Augmentations on Self-/Semi-/Fully- Supervised Pre-trained Models
Oct 28, 2023Data augmentation has become a standard component of vision pre-trained models to capture the invariance between augmented views. In practice, augmentation techniques that mask regions of a sample with zero/mean values or patches from other samples are commonly employed in pre-trained models with self-/semi-/fully-supervised contrastive losses. However, the underlying mechanism behind the effectiveness of these augmentation techniques remains poorly explored. To investigate the problems, we conduct an empirical study to quantify how data augmentation affects performance. Concretely, we apply 4 types of data augmentations termed with Random Erasing, CutOut, CutMix and MixUp to a series of self-/semi-/fully- supervised pre-trained models. We report their performance on vision tasks such as image classification, object detection, instance segmentation, and semantic segmentation. We then explicitly evaluate the invariance and diversity of the feature embedding. We observe that: 1) Masking regions of the images decreases the invariance of the learned feature embedding while providing a more considerable diversity. 2) Manual annotations do not change the invariance or diversity of the learned feature embedding. 3) The MixUp approach improves the diversity significantly, with only a marginal decrease in terms of the invariance.
Product of Gaussian Mixture Diffusion Models
Oct 19, 2023In this work we tackle the problem of estimating the density $ f_X $ of a random variable $ X $ by successive smoothing, such that the smoothed random variable $ Y $ fulfills the diffusion partial differential equation $ (\partial_t - \Delta_1)f_Y(\,\cdot\,, t) = 0 $ with initial condition $ f_Y(\,\cdot\,, 0) = f_X $. We propose a product-of-experts-type model utilizing Gaussian mixture experts and study configurations that admit an analytic expression for $ f_Y (\,\cdot\,, t) $. In particular, with a focus on image processing, we derive conditions for models acting on filter-, wavelet-, and shearlet responses. Our construction naturally allows the model to be trained simultaneously over the entire diffusion horizon using empirical Bayes. We show numerical results for image denoising where our models are competitive while being tractable, interpretable, and having only a small number of learnable parameters. As a byproduct, our models can be used for reliable noise estimation, allowing blind denoising of images corrupted by heteroscedastic noise.
Mixed Graph Signal Analysis of Joint Image Denoising / Interpolation
Sep 18, 2023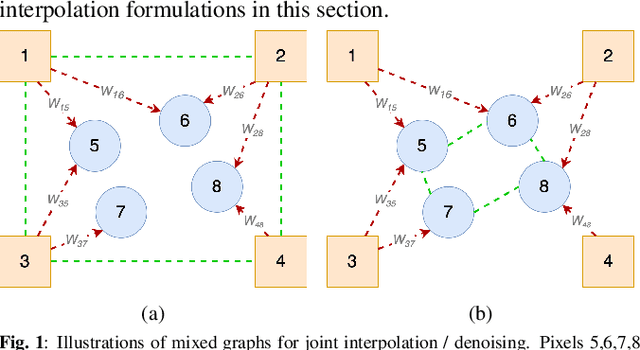
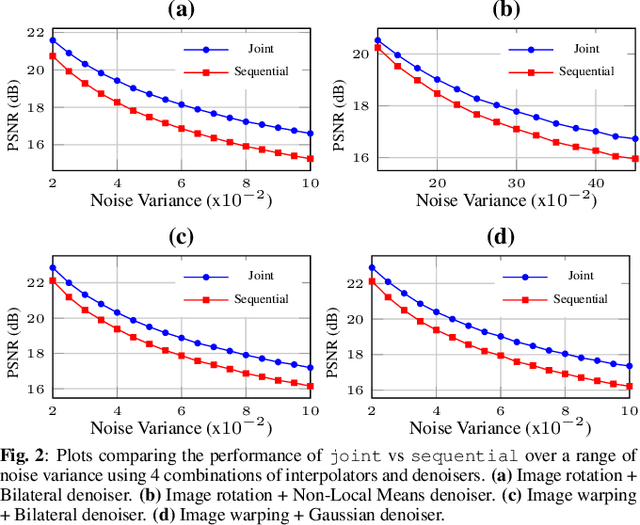
A noise-corrupted image often requires interpolation. Given a linear denoiser and a linear interpolator, when should the operations be independently executed in separate steps, and when should they be combined and jointly optimized? We study joint denoising / interpolation of images from a mixed graph filtering perspective: we model denoising using an undirected graph, and interpolation using a directed graph. We first prove that, under mild conditions, a linear denoiser is a solution graph filter to a maximum a posteriori (MAP) problem regularized using an undirected graph smoothness prior, while a linear interpolator is a solution to a MAP problem regularized using a directed graph smoothness prior. Next, we study two variants of the joint interpolation / denoising problem: a graph-based denoiser followed by an interpolator has an optimal separable solution, while an interpolator followed by a denoiser has an optimal non-separable solution. Experiments show that our joint denoising / interpolation method outperformed separate approaches noticeably.
Practical Deep Dispersed Watermarking with Synchronization and Fusion
Oct 23, 2023Deep learning based blind watermarking works have gradually emerged and achieved impressive performance. However, previous deep watermarking studies mainly focus on fixed low-resolution images while paying less attention to arbitrary resolution images, especially widespread high-resolution images nowadays. Moreover, most works usually demonstrate robustness against typical non-geometric attacks (\textit{e.g.}, JPEG compression) but ignore common geometric attacks (\textit{e.g.}, Rotate) and more challenging combined attacks. To overcome the above limitations, we propose a practical deep \textbf{D}ispersed \textbf{W}atermarking with \textbf{S}ynchronization and \textbf{F}usion, called \textbf{\proposed}. Specifically, given an arbitrary-resolution cover image, we adopt a dispersed embedding scheme which sparsely and randomly selects several fixed small-size cover blocks to embed a consistent watermark message by a well-trained encoder. In the extraction stage, we first design a watermark synchronization module to locate and rectify the encoded blocks in the noised watermarked image. We then utilize a decoder to obtain messages embedded in these blocks, and propose a message fusion strategy based on similarity to make full use of the consistency among messages, thus determining a reliable message. Extensive experiments conducted on different datasets convincingly demonstrate the effectiveness of our proposed {\proposed}. Compared with state-of-the-art approaches, our blind watermarking can achieve better performance: averagely improve the bit accuracy by 5.28\% and 5.93\% against single and combined attacks, respectively, and show less file size increment and better visual quality. Our code is available at https://github.com/bytedance/DWSF.
Incorporating Probing Signals into Multimodal Machine Translation via Visual Question-Answering Pairs
Oct 26, 2023This paper presents an in-depth study of multimodal machine translation (MMT), examining the prevailing understanding that MMT systems exhibit decreased sensitivity to visual information when text inputs are complete. Instead, we attribute this phenomenon to insufficient cross-modal interaction, rather than image information redundancy. A novel approach is proposed to generate parallel Visual Question-Answering (VQA) style pairs from the source text, fostering more robust cross-modal interaction. Using Large Language Models (LLMs), we explicitly model the probing signal in MMT to convert it into VQA-style data to create the Multi30K-VQA dataset. An MMT-VQA multitask learning framework is introduced to incorporate explicit probing signals from the dataset into the MMT training process. Experimental results on two widely-used benchmarks demonstrate the effectiveness of this novel approach. Our code and data would be available at: \url{https://github.com/libeineu/MMT-VQA}.
Instability of computer vision models is a necessary result of the task itself
Oct 26, 2023Adversarial examples resulting from instability of current computer vision models are an extremely important topic due to their potential to compromise any application. In this paper we demonstrate that instability is inevitable due to a) symmetries (translational invariance) of the data, b) the categorical nature of the classification task, and c) the fundamental discrepancy of classifying images as objects themselves. The issue is further exacerbated by non-exhaustive labelling of the training data. Therefore we conclude that instability is a necessary result of how the problem of computer vision is currently formulated. While the problem cannot be eliminated, through the analysis of the causes, we have arrived at ways how it can be partially alleviated. These include i) increasing the resolution of images, ii) providing contextual information for the image, iii) exhaustive labelling of training data, and iv) preventing attackers from frequent access to the computer vision system.