 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Large Language Model Can Interpret Latent Space of Sequential Recommender
Oct 31, 2023
Sequential recommendation is to predict the next item of interest for a user, based on her/his interaction history with previous items. In conventional sequential recommenders, a common approach is to model item sequences using discrete IDs, learning representations that encode sequential behaviors and reflect user preferences. Inspired by recent success in empowering large language models (LLMs) to understand and reason over diverse modality data (e.g., image, audio, 3D points), a compelling research question arises: ``Can LLMs understand and work with hidden representations from ID-based sequential recommenders?''.To answer this, we propose a simple framework, RecInterpreter, which examines the capacity of open-source LLMs to decipher the representation space of sequential recommenders. Specifically, with the multimodal pairs (\ie representations of interaction sequence and text narrations), RecInterpreter first uses a lightweight adapter to map the representations into the token embedding space of the LLM. Subsequently, it constructs a sequence-recovery prompt that encourages the LLM to generate textual descriptions for items within the interaction sequence. Taking a step further, we propose a sequence-residual prompt instead, which guides the LLM in identifying the residual item by contrasting the representations before and after integrating this residual into the existing sequence. Empirical results showcase that our RecInterpreter enhances the exemplar LLM, LLaMA, to understand hidden representations from ID-based sequential recommenders, especially when guided by our sequence-residual prompts. Furthermore, RecInterpreter enables LLaMA to instantiate the oracle items generated by generative recommenders like DreamRec, concreting the item a user would ideally like to interact with next. Codes are available at https://github.com/YangZhengyi98/RecInterpreter.
Overview of ImageArg-2023: The First Shared Task in Multimodal Argument Mining
Oct 15, 2023This paper presents an overview of the ImageArg shared task, the first multimodal Argument Mining shared task co-located with the 10th Workshop on Argument Mining at EMNLP 2023. The shared task comprises two classification subtasks - (1) Subtask-A: Argument Stance Classification; (2) Subtask-B: Image Persuasiveness Classification. The former determines the stance of a tweet containing an image and a piece of text toward a controversial topic (e.g., gun control and abortion). The latter determines whether the image makes the tweet text more persuasive. The shared task received 31 submissions for Subtask-A and 21 submissions for Subtask-B from 9 different teams across 6 countries. The top submission in Subtask-A achieved an F1-score of 0.8647 while the best submission in Subtask-B achieved an F1-score of 0.5561.
OBSUM: An object-based spatial unmixing model for spatiotemporal fusion of remote sensing images
Oct 14, 2023Spatiotemporal fusion aims to improve both the spatial and temporal resolution of remote sensing images, thus facilitating time-series analysis at a fine spatial scale. However, there are several important issues that limit the application of current spatiotemporal fusion methods. First, most spatiotemporal fusion methods are based on pixel-level computation, which neglects the valuable object-level information of the land surface. Moreover, many existing methods cannot accurately retrieve strong temporal changes between the available high-resolution image at base date and the predicted one. This study proposes an Object-Based Spatial Unmixing Model (OBSUM), which incorporates object-based image analysis and spatial unmixing, to overcome the two abovementioned problems. OBSUM consists of one preprocessing step and three fusion steps, i.e., object-level unmixing, object-level residual compensation, and pixel-level residual compensation. OBSUM can be applied using only one fine image at the base date and one coarse image at the prediction date, without the need of a coarse image at the base date. The performance of OBSUM was compared with five representative spatiotemporal fusion methods. The experimental results demonstrated that OBSUM outperformed other methods in terms of both accuracy indices and visual effects over time-series. Furthermore, OBSUM also achieved satisfactory results in two typical remote sensing applications. Therefore, it has great potential to generate accurate and high-resolution time-series observations for supporting various remote sensing applications.
End-to-End (Instance)-Image Goal Navigation through Correspondence as an Emergent Phenomenon
Sep 28, 2023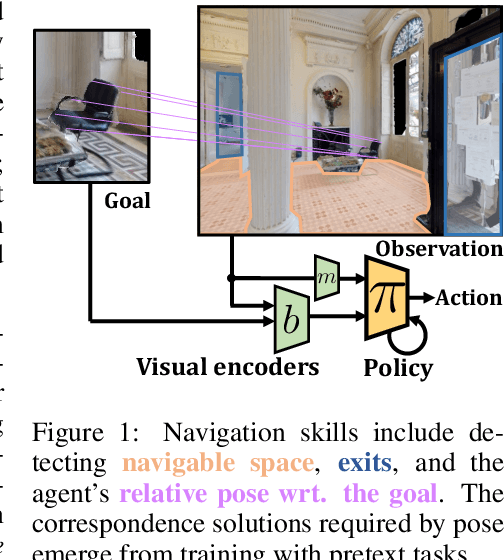


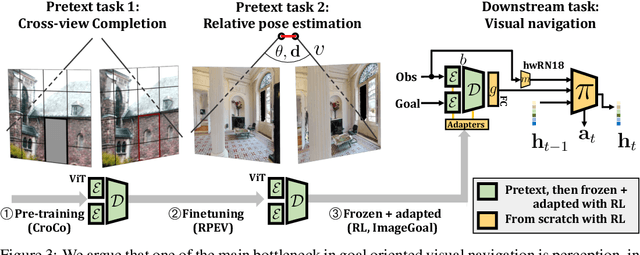
Most recent work in goal oriented visual navigation resorts to large-scale machine learning in simulated environments. The main challenge lies in learning compact representations generalizable to unseen environments and in learning high-capacity perception modules capable of reasoning on high-dimensional input. The latter is particularly difficult when the goal is not given as a category ("ObjectNav") but as an exemplar image ("ImageNav"), as the perception module needs to learn a comparison strategy requiring to solve an underlying visual correspondence problem. This has been shown to be difficult from reward alone or with standard auxiliary tasks. We address this problem through a sequence of two pretext tasks, which serve as a prior for what we argue is one of the main bottleneck in perception, extremely wide-baseline relative pose estimation and visibility prediction in complex scenes. The first pretext task, cross-view completion is a proxy for the underlying visual correspondence problem, while the second task addresses goal detection and finding directly. We propose a new dual encoder with a large-capacity binocular ViT model and show that correspondence solutions naturally emerge from the training signals. Experiments show significant improvements and SOTA performance on the two benchmarks, ImageNav and the Instance-ImageNav variant, where camera intrinsics and height differ between observation and goal.
Fast Machine Learning Method with Vector Embedding on Orthonormal Basis and Spectral Transform
Oct 27, 2023This paper presents a novel fast machine learning method that leverages two techniques: Vector Embedding on Orthonormal Basis (VEOB) and Spectral Transform (ST). The VEOB converts the original data encoding into a vector embedding with coordinates projected onto orthonormal bases. The Singular Value Decomposition (SVD) technique is used to calculate the vector basis and projection coordinates, leading to an enhanced distance measurement in the embedding space and facilitating data compression by preserving the projection vectors associated with the largest singular values. On the other hand, ST transforms sequence of vector data into spectral space. By applying the Discrete Cosine Transform (DCT) and selecting the most significant components, it streamlines the handling of lengthy vector sequences. The paper provides examples of word embedding, text chunk embedding, and image embedding, implemented in Julia language with a vector database. It also investigates unsupervised learning and supervised learning using this method, along with strategies for handling large data volumes.
Sample based Explanations via Generalized Representers
Oct 27, 2023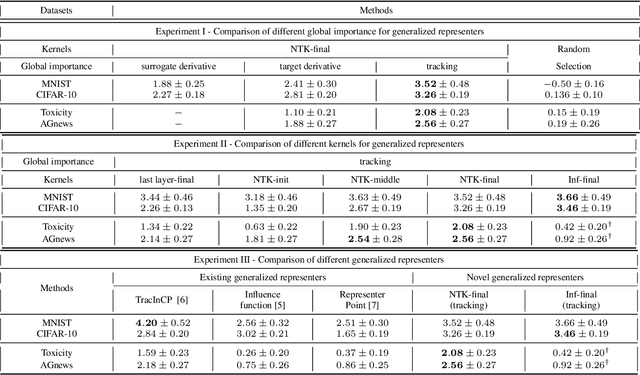
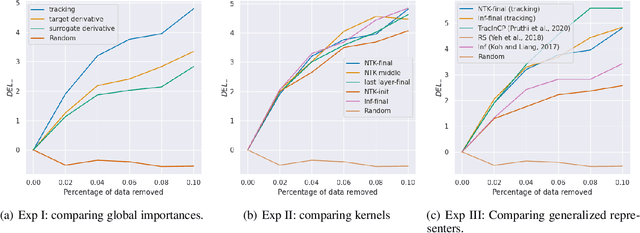
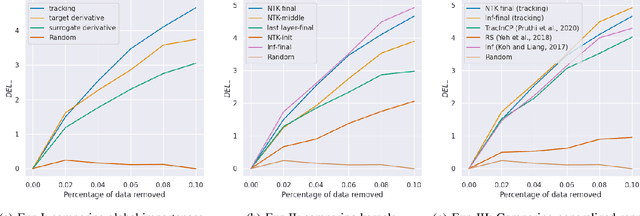
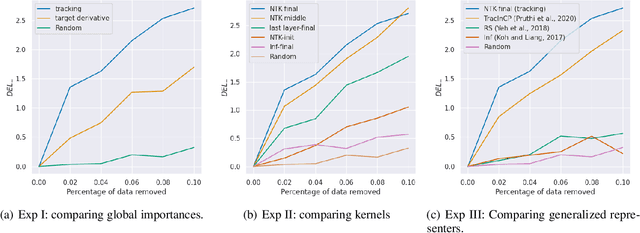
We propose a general class of sample based explanations of machine learning models, which we term generalized representers. To measure the effect of a training sample on a model's test prediction, generalized representers use two components: a global sample importance that quantifies the importance of the training point to the model and is invariant to test samples, and a local sample importance that measures similarity between the training sample and the test point with a kernel. A key contribution of the paper is to show that generalized representers are the only class of sample based explanations satisfying a natural set of axiomatic properties. We discuss approaches to extract global importances given a kernel, and also natural choices of kernels given modern non-linear models. As we show, many popular existing sample based explanations could be cast as generalized representers with particular choices of kernels and approaches to extract global importances. Additionally, we conduct empirical comparisons of different generalized representers on two image and two text classification datasets.
RigNet++: Efficient Repetitive Image Guided Network for Depth Completion
Sep 01, 2023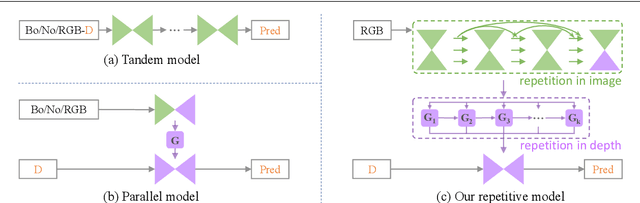
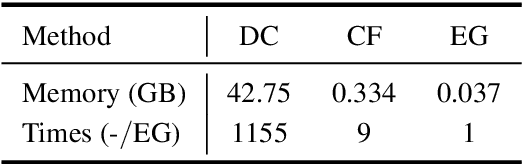
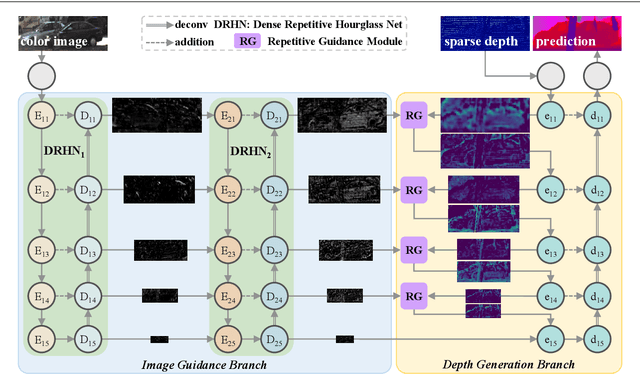

Depth completion aims to recover dense depth maps from sparse ones, where color images are often used to facilitate this task. Recent depth methods primarily focus on image guided learning frameworks. However, blurry guidance in the image and unclear structure in the depth still impede their performance. To tackle these challenges, we explore an efficient repetitive design in our image guided network to gradually and sufficiently recover depth values. Specifically, the efficient repetition is embodied in both the image guidance branch and depth generation branch. In the former branch, we design a dense repetitive hourglass network to extract discriminative image features of complex environments, which can provide powerful contextual instruction for depth prediction. In the latter branch, we introduce a repetitive guidance module based on dynamic convolution, in which an efficient convolution factorization is proposed to reduce the complexity while modeling high-frequency structures progressively. Extensive experiments indicate that our approach achieves superior or competitive results on KITTI, VKITTI, NYUv2, 3D60, and Matterport3D datasets.
Identifiable Contrastive Learning with Automatic Feature Importance Discovery
Oct 29, 2023

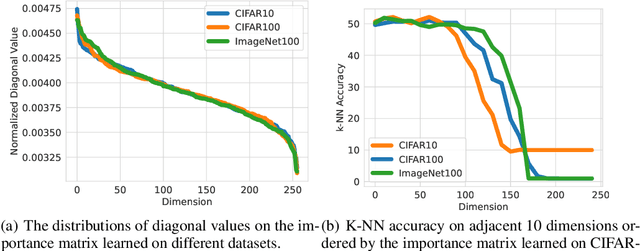
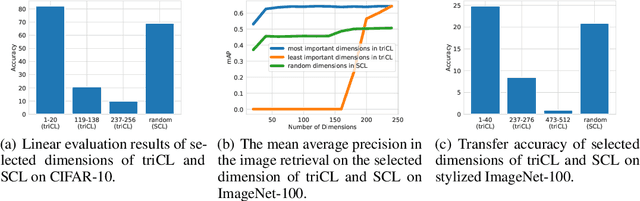
Existing contrastive learning methods rely on pairwise sample contrast $z_x^\top z_{x'}$ to learn data representations, but the learned features often lack clear interpretability from a human perspective. Theoretically, it lacks feature identifiability and different initialization may lead to totally different features. In this paper, we study a new method named tri-factor contrastive learning (triCL) that involves a 3-factor contrast in the form of $z_x^\top S z_{x'}$, where $S=\text{diag}(s_1,\dots,s_k)$ is a learnable diagonal matrix that automatically captures the importance of each feature. We show that by this simple extension, triCL can not only obtain identifiable features that eliminate randomness but also obtain more interpretable features that are ordered according to the importance matrix $S$. We show that features with high importance have nice interpretability by capturing common classwise features, and obtain superior performance when evaluated for image retrieval using a few features. The proposed triCL objective is general and can be applied to different contrastive learning methods like SimCLR and CLIP. We believe that it is a better alternative to existing 2-factor contrastive learning by improving its identifiability and interpretability with minimal overhead. Code is available at https://github.com/PKU-ML/Tri-factor-Contrastive-Learning.
Boosting Decision-Based Black-Box Adversarial Attack with Gradient Priors
Oct 29, 2023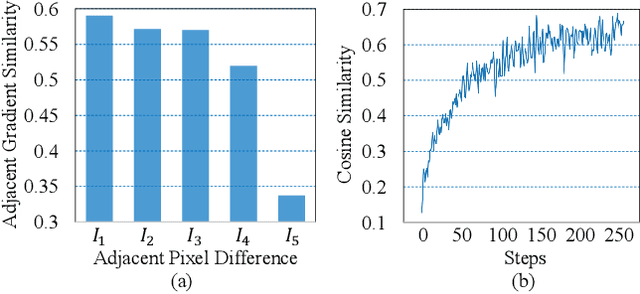
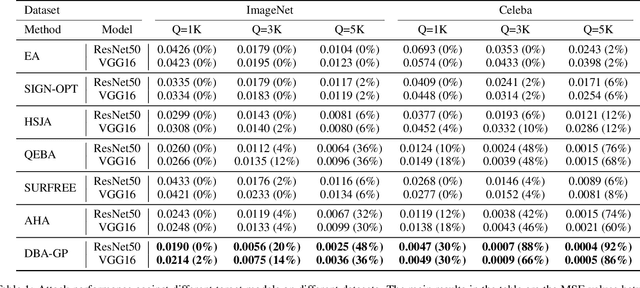
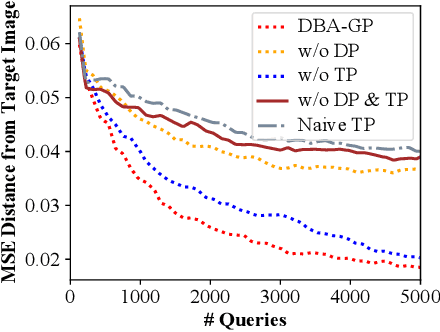
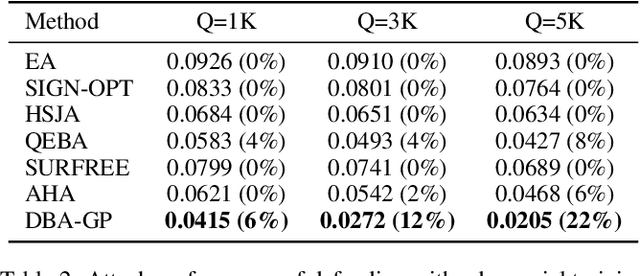
Decision-based methods have shown to be effective in black-box adversarial attacks, as they can obtain satisfactory performance and only require to access the final model prediction. Gradient estimation is a critical step in black-box adversarial attacks, as it will directly affect the query efficiency. Recent works have attempted to utilize gradient priors to facilitate score-based methods to obtain better results. However, these gradient priors still suffer from the edge gradient discrepancy issue and the successive iteration gradient direction issue, thus are difficult to simply extend to decision-based methods. In this paper, we propose a novel Decision-based Black-box Attack framework with Gradient Priors (DBA-GP), which seamlessly integrates the data-dependent gradient prior and time-dependent prior into the gradient estimation procedure. First, by leveraging the joint bilateral filter to deal with each random perturbation, DBA-GP can guarantee that the generated perturbations in edge locations are hardly smoothed, i.e., alleviating the edge gradient discrepancy, thus remaining the characteristics of the original image as much as possible. Second, by utilizing a new gradient updating strategy to automatically adjust the successive iteration gradient direction, DBA-GP can accelerate the convergence speed, thus improving the query efficiency. Extensive experiments have demonstrated that the proposed method outperforms other strong baselines significantly.
Adversarial Examples Are Not Real Features
Oct 29, 2023


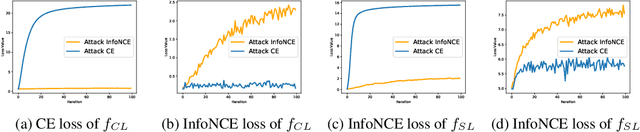
The existence of adversarial examples has been a mystery for years and attracted much interest. A well-known theory by \citet{ilyas2019adversarial} explains adversarial vulnerability from a data perspective by showing that one can extract non-robust features from adversarial examples and these features alone are useful for classification. However, the explanation remains quite counter-intuitive since non-robust features are mostly noise features to humans. In this paper, we re-examine the theory from a larger context by incorporating multiple learning paradigms. Notably, we find that contrary to their good usefulness under supervised learning, non-robust features attain poor usefulness when transferred to other self-supervised learning paradigms, such as contrastive learning, masked image modeling, and diffusion models. It reveals that non-robust features are not really as useful as robust or natural features that enjoy good transferability between these paradigms. Meanwhile, for robustness, we also show that naturally trained encoders from robust features are largely non-robust under AutoAttack. Our cross-paradigm examination suggests that the non-robust features are not really useful but more like paradigm-wise shortcuts, and robust features alone might be insufficient to attain reliable model robustness. Code is available at \url{https://github.com/PKU-ML/AdvNotRealFeatures}.