 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Label Poisoning is All You Need
Oct 29, 2023
In a backdoor attack, an adversary injects corrupted data into a model's training dataset in order to gain control over its predictions on images with a specific attacker-defined trigger. A typical corrupted training example requires altering both the image, by applying the trigger, and the label. Models trained on clean images, therefore, were considered safe from backdoor attacks. However, in some common machine learning scenarios, the training labels are provided by potentially malicious third-parties. This includes crowd-sourced annotation and knowledge distillation. We, hence, investigate a fundamental question: can we launch a successful backdoor attack by only corrupting labels? We introduce a novel approach to design label-only backdoor attacks, which we call FLIP, and demonstrate its strengths on three datasets (CIFAR-10, CIFAR-100, and Tiny-ImageNet) and four architectures (ResNet-32, ResNet-18, VGG-19, and Vision Transformer). With only 2% of CIFAR-10 labels corrupted, FLIP achieves a near-perfect attack success rate of 99.4% while suffering only a 1.8% drop in the clean test accuracy. Our approach builds upon the recent advances in trajectory matching, originally introduced for dataset distillation.
LCReg: Long-Tailed Image Classification with Latent Categories based Recognition
Sep 13, 2023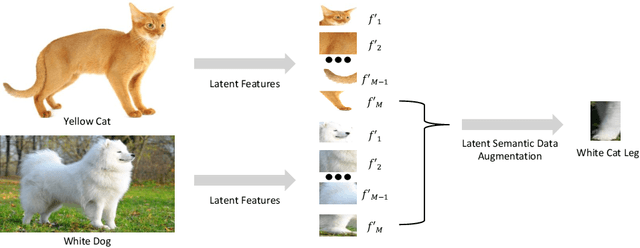
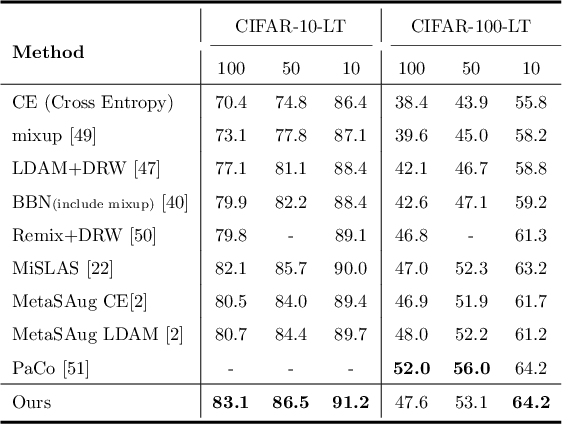
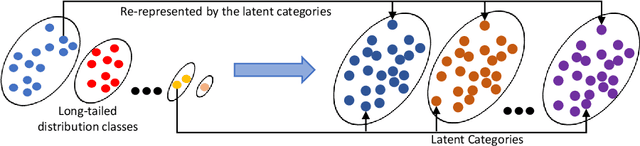
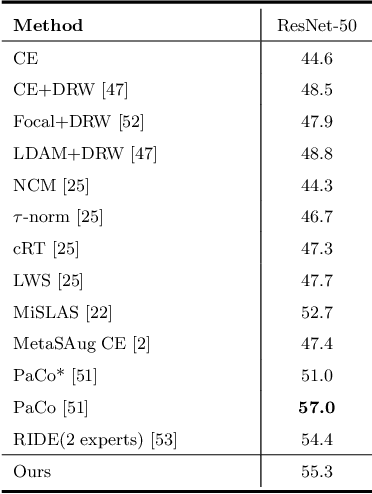
In this work, we tackle the challenging problem of long-tailed image recognition. Previous long-tailed recognition approaches mainly focus on data augmentation or re-balancing strategies for the tail classes to give them more attention during model training. However, these methods are limited by the small number of training images for the tail classes, which results in poor feature representations. To address this issue, we propose the Latent Categories based long-tail Recognition (LCReg) method. Our hypothesis is that common latent features shared by head and tail classes can be used to improve feature representation. Specifically, we learn a set of class-agnostic latent features shared by both head and tail classes, and then use semantic data augmentation on the latent features to implicitly increase the diversity of the training sample. We conduct extensive experiments on five long-tailed image recognition datasets, and the results show that our proposed method significantly improves the baselines.
Competitive Ensembling Teacher-Student Framework for Semi-Supervised Left Atrium MRI Segmentation
Oct 21, 2023Semi-supervised learning has greatly advanced medical image segmentation since it effectively alleviates the need of acquiring abundant annotations from experts and utilizes unlabeled data which is much easier to acquire. Among existing perturbed consistency learning methods, mean-teacher model serves as a standard baseline for semi-supervised medical image segmentation. In this paper, we present a simple yet efficient competitive ensembling teacher student framework for semi-supervised for left atrium segmentation from 3D MR images, in which two student models with different task-level disturbances are introduced to learn mutually, while a competitive ensembling strategy is performed to ensemble more reliable information to teacher model. Different from the one-way transfer between teacher and student models, our framework facilitates the collaborative learning procedure of different student models with the guidance of teacher model and motivates different training networks for a competitive learning and ensembling procedure to achieve better performance. We evaluate our proposed method on the public Left Atrium (LA) dataset and it obtains impressive performance gains by exploiting the unlabeled data effectively and outperforms several existing semi-supervised methods.
Towards Control-Centric Representations in Reinforcement Learning from Images
Oct 27, 2023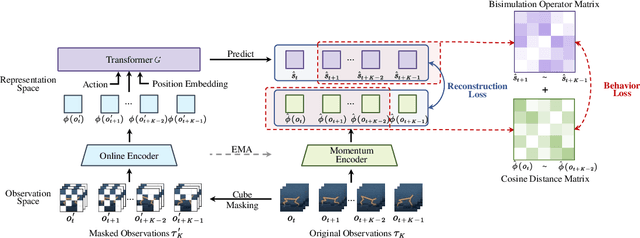
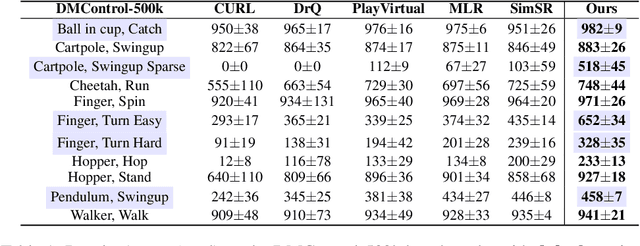

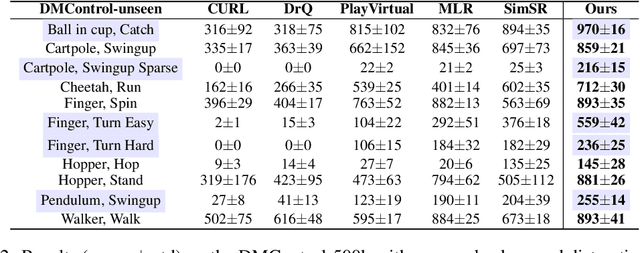
Image-based Reinforcement Learning is a practical yet challenging task. A major hurdle lies in extracting control-centric representations while disregarding irrelevant information. While approaches that follow the bisimulation principle exhibit the potential in learning state representations to address this issue, they still grapple with the limited expressive capacity of latent dynamics and the inadaptability to sparse reward environments. To address these limitations, we introduce ReBis, which aims to capture control-centric information by integrating reward-free control information alongside reward-specific knowledge. ReBis utilizes a transformer architecture to implicitly model the dynamics and incorporates block-wise masking to eliminate spatiotemporal redundancy. Moreover, ReBis combines bisimulation-based loss with asymmetric reconstruction loss to prevent feature collapse in environments with sparse rewards. Empirical studies on two large benchmarks, including Atari games and DeepMind Control Suit, demonstrate that ReBis has superior performance compared to existing methods, proving its effectiveness.
Qilin-Med-VL: Towards Chinese Large Vision-Language Model for General Healthcare
Oct 27, 2023Large Language Models (LLMs) have introduced a new era of proficiency in comprehending complex healthcare and biomedical topics. However, there is a noticeable lack of models in languages other than English and models that can interpret multi-modal input, which is crucial for global healthcare accessibility. In response, this study introduces Qilin-Med-VL, the first Chinese large vision-language model designed to integrate the analysis of textual and visual data. Qilin-Med-VL combines a pre-trained Vision Transformer (ViT) with a foundational LLM. It undergoes a thorough two-stage curriculum training process that includes feature alignment and instruction tuning. This method enhances the model's ability to generate medical captions and answer complex medical queries. We also release ChiMed-VL, a dataset consisting of more than 1M image-text pairs. This dataset has been carefully curated to enable detailed and comprehensive interpretation of medical data using various types of images.
SSHNN: Semi-Supervised Hybrid NAS Network for Echocardiographic Image Segmentation
Sep 09, 2023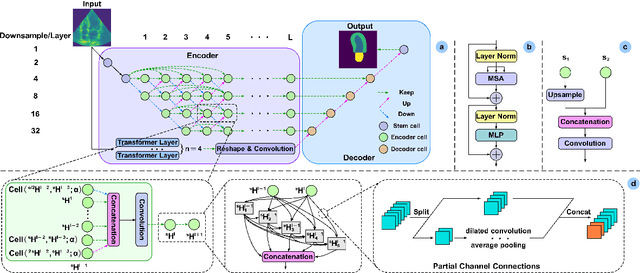
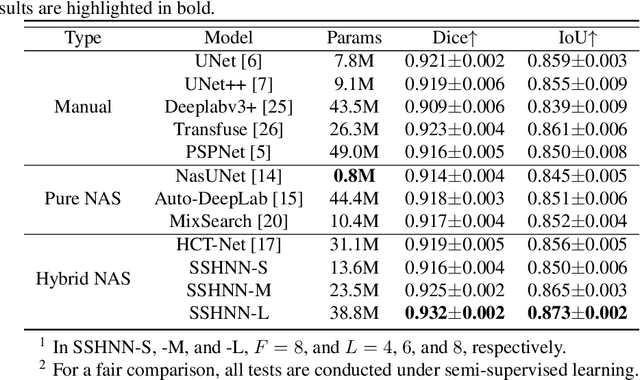

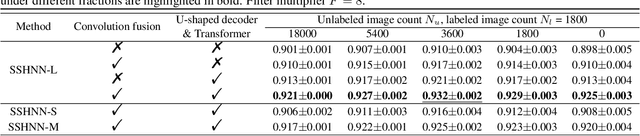
Accurate medical image segmentation especially for echocardiographic images with unmissable noise requires elaborate network design. Compared with manual design, Neural Architecture Search (NAS) realizes better segmentation results due to larger search space and automatic optimization, but most of the existing methods are weak in layer-wise feature aggregation and adopt a ``strong encoder, weak decoder" structure, insufficient to handle global relationships and local details. To resolve these issues, we propose a novel semi-supervised hybrid NAS network for accurate medical image segmentation termed SSHNN. In SSHNN, we creatively use convolution operation in layer-wise feature fusion instead of normalized scalars to avoid losing details, making NAS a stronger encoder. Moreover, Transformers are introduced for the compensation of global context and U-shaped decoder is designed to efficiently connect global context with local features. Specifically, we implement a semi-supervised algorithm Mean-Teacher to overcome the limited volume problem of labeled medical image dataset. Extensive experiments on CAMUS echocardiography dataset demonstrate that SSHNN outperforms state-of-the-art approaches and realizes accurate segmentation. Code will be made publicly available.
Learning Residual Elastic Warps for Image Stitching under Dirichlet Boundary Condition
Sep 07, 2023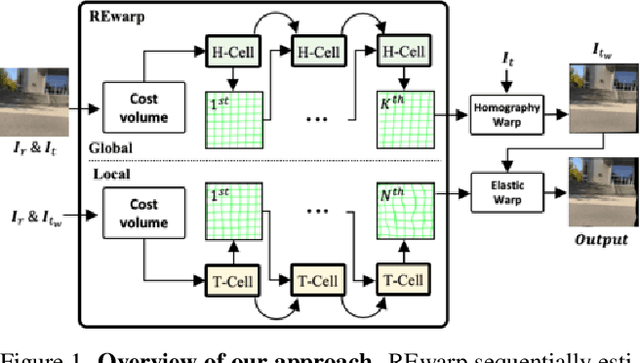
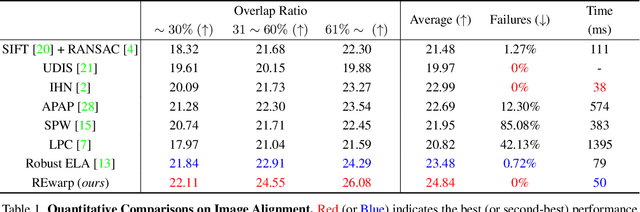

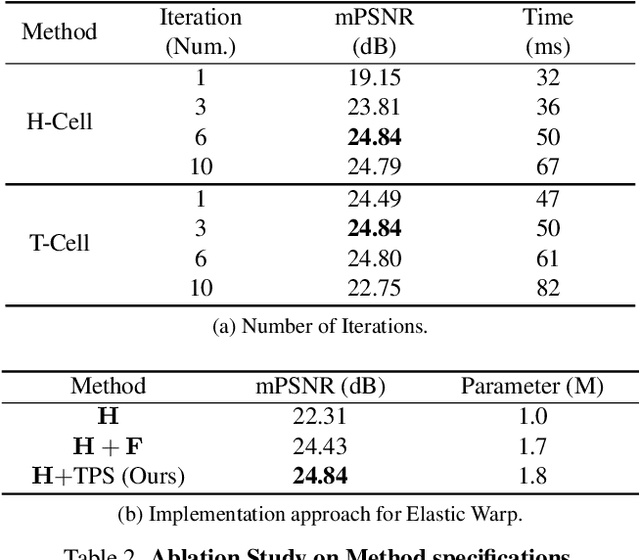
Trendy suggestions for learning-based elastic warps enable the deep image stitchings to align images exposed to large parallax errors. Despite the remarkable alignments, the methods struggle with occasional holes or discontinuity between overlapping and non-overlapping regions of a target image as the applied training strategy mostly focuses on overlap region alignment. As a result, they require additional modules such as seam finder and image inpainting for hiding discontinuity and filling holes, respectively. In this work, we suggest Recurrent Elastic Warps (REwarp) that address the problem with Dirichlet boundary condition and boost performances by residual learning for recurrent misalign correction. Specifically, REwarp predicts a homography and a Thin-plate Spline (TPS) under the boundary constraint for discontinuity and hole-free image stitching. Our experiments show the favorable aligns and the competitive computational costs of REwarp compared to the existing stitching methods. Our source code is available at https://github.com/minshu-kim/REwarp.
Image Coding for Machines with Object Region Learning
Aug 27, 2023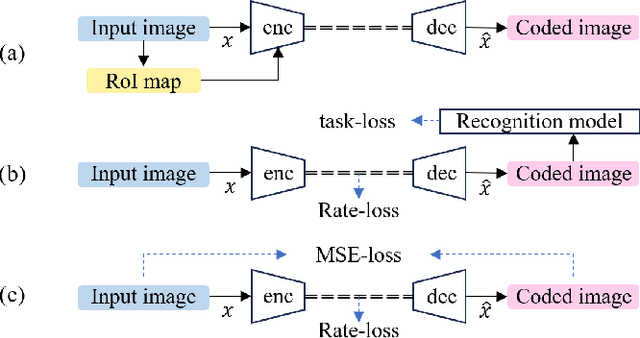
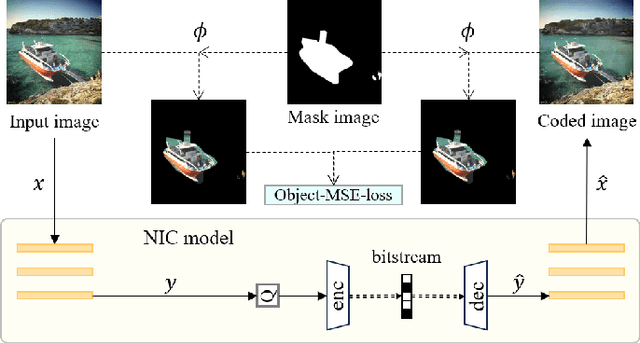


Compression technology is essential for efficient image transmission and storage. With the rapid advances in deep learning, images are beginning to be used for image recognition as well as for human vision. For this reason, research has been conducted on image coding for image recognition, and this field is called Image Coding for Machines (ICM). There are two main approaches in ICM: the ROI-based approach and the task-loss-based approach. The former approach has the problem of requiring an ROI-map as input in addition to the input image. The latter approach has the problems of difficulty in learning the task-loss, and lack of robustness because the specific image recognition model is used to compute the loss function. To solve these problems, we propose an image compression model that learns object regions. Our model does not require additional information as input, such as an ROI-map, and does not use task-loss. Therefore, it is possible to compress images for various image recognition models. In the experiments, we demonstrate the versatility of the proposed method by using three different image recognition models and three different datasets. In addition, we verify the effectiveness of our model by comparing it with previous methods.
PERF: Panoramic Neural Radiance Field from a Single Panorama
Oct 25, 2023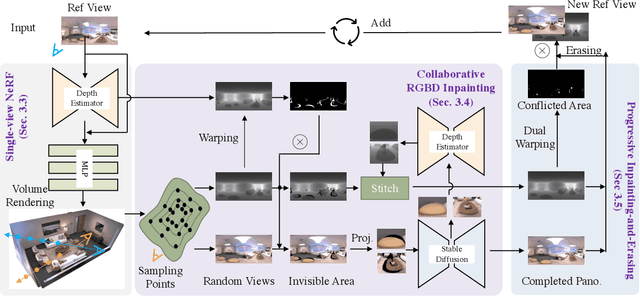
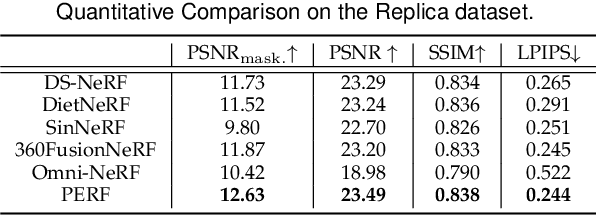
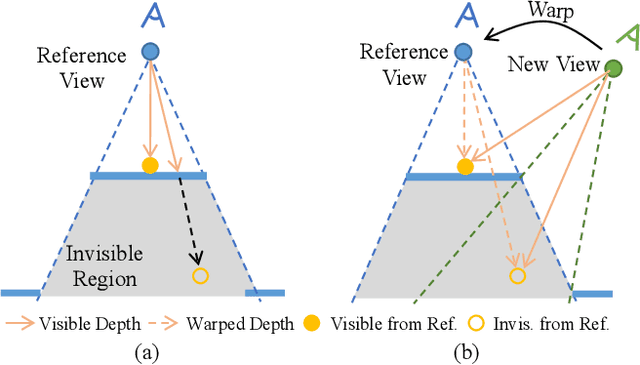

Neural Radiance Field (NeRF) has achieved substantial progress in novel view synthesis given multi-view images. Recently, some works have attempted to train a NeRF from a single image with 3D priors. They mainly focus on a limited field of view and there are few invisible occlusions, which greatly limits their scalability to real-world 360-degree panoramic scenarios with large-size occlusions. In this paper, we present PERF, a 360-degree novel view synthesis framework that trains a panoramic neural radiance field from a single panorama. Notably, PERF allows 3D roaming in a complex scene without expensive and tedious image collection. To achieve this goal, we propose a novel collaborative RGBD inpainting method and a progressive inpainting-and-erasing method to lift up a 360-degree 2D scene to a 3D scene. Specifically, we first predict a panoramic depth map as initialization given a single panorama, and reconstruct visible 3D regions with volume rendering. Then we introduce a collaborative RGBD inpainting approach into a NeRF for completing RGB images and depth maps from random views, which is derived from an RGB Stable Diffusion model and a monocular depth estimator. Finally, we introduce an inpainting-and-erasing strategy to avoid inconsistent geometry between a newly-sampled view and reference views. The two components are integrated into the learning of NeRFs in a unified optimization framework and achieve promising results. Extensive experiments on Replica and a new dataset PERF-in-the-wild demonstrate the superiority of our PERF over state-of-the-art methods. Our PERF can be widely used for real-world applications, such as panorama-to-3D, text-to-3D, and 3D scene stylization applications. Project page and code are available at https://perf-project.github.io/.
SAMUS: Adapting Segment Anything Model for Clinically-Friendly and Generalizable Ultrasound Image Segmentation
Sep 13, 2023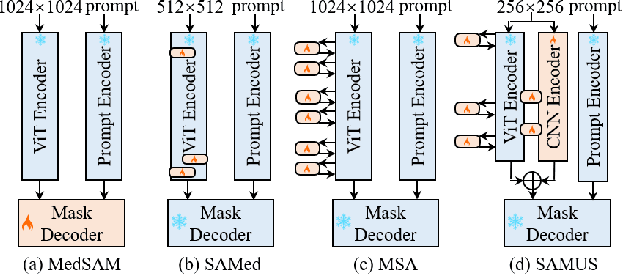
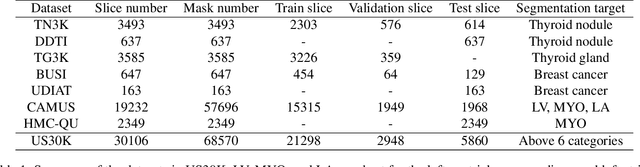
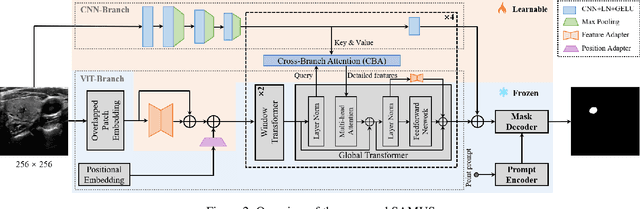
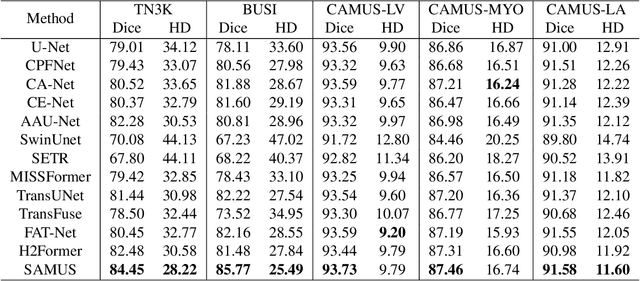
Segment anything model (SAM), an eminent universal image segmentation model, has recently gathered considerable attention within the domain of medical image segmentation. Despite the remarkable performance of SAM on natural images, it grapples with significant performance degradation and limited generalization when confronted with medical images, particularly with those involving objects of low contrast, faint boundaries, intricate shapes, and diminutive sizes. In this paper, we propose SAMUS, a universal model tailored for ultrasound image segmentation. In contrast to previous SAM-based universal models, SAMUS pursues not only better generalization but also lower deployment cost, rendering it more suitable for clinical applications. Specifically, based on SAM, a parallel CNN branch is introduced to inject local features into the ViT encoder through cross-branch attention for better medical image segmentation. Then, a position adapter and a feature adapter are developed to adapt SAM from natural to medical domains and from requiring large-size inputs (1024x1024) to small-size inputs (256x256) for more clinical-friendly deployment. A comprehensive ultrasound dataset, comprising about 30k images and 69k masks and covering six object categories, is collected for verification. Extensive comparison experiments demonstrate SAMUS's superiority against the state-of-the-art task-specific models and universal foundation models under both task-specific evaluation and generalization evaluation. Moreover, SAMUS is deployable on entry-level GPUs, as it has been liberated from the constraints of long sequence encoding. The code, data, and models will be released at https://github.com/xianlin7/SAMUS.