 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
AGFSync: Leveraging AI-Generated Feedback for Preference Optimization in Text-to-Image Generation
Mar 20, 2024

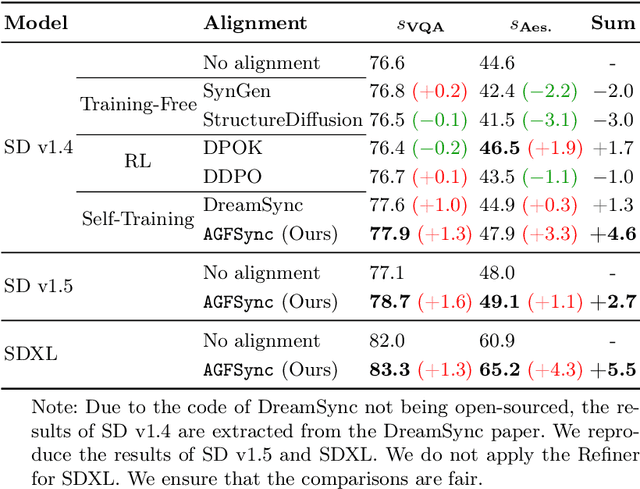
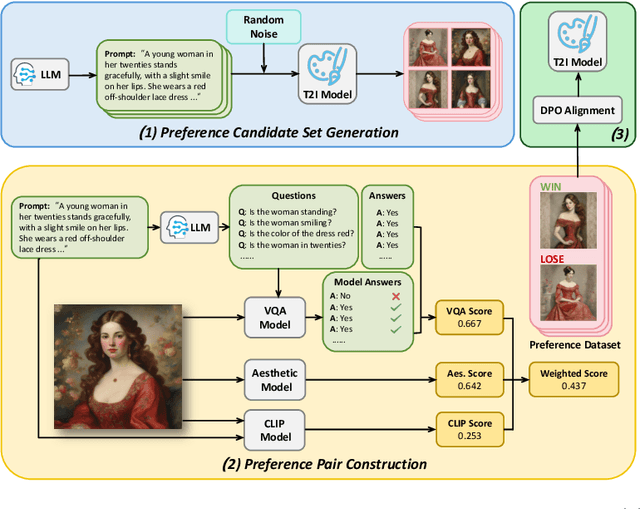
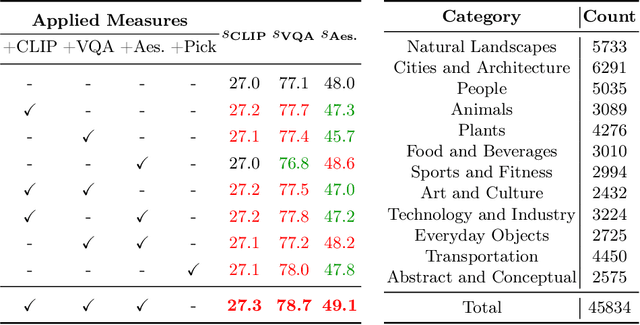
Text-to-Image (T2I) diffusion models have achieved remarkable success in image generation. Despite their progress, challenges remain in both prompt-following ability, image quality and lack of high-quality datasets, which are essential for refining these models. As acquiring labeled data is costly, we introduce AGFSync, a framework that enhances T2I diffusion models through Direct Preference Optimization (DPO) in a fully AI-driven approach. AGFSync utilizes Vision-Language Models (VLM) to assess image quality across style, coherence, and aesthetics, generating feedback data within an AI-driven loop. By applying AGFSync to leading T2I models such as SD v1.4, v1.5, and SDXL, our extensive experiments on the TIFA dataset demonstrate notable improvements in VQA scores, aesthetic evaluations, and performance on the HPSv2 benchmark, consistently outperforming the base models. AGFSync's method of refining T2I diffusion models paves the way for scalable alignment techniques.
Efficient scene text image super-resolution with semantic guidance
Mar 20, 2024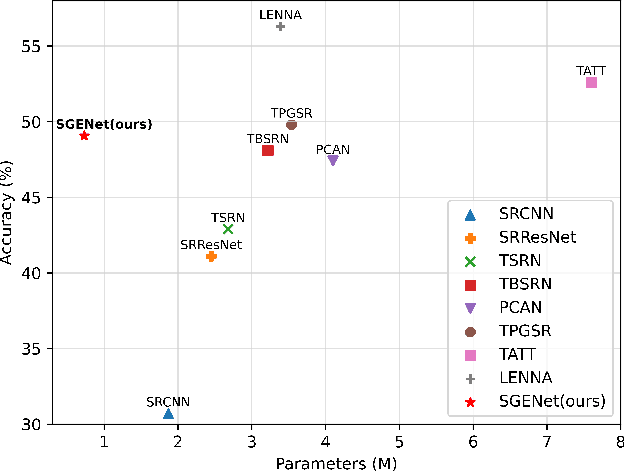
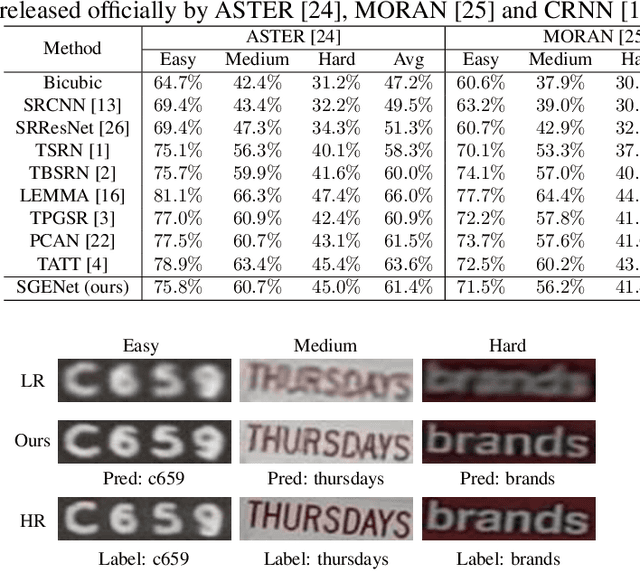
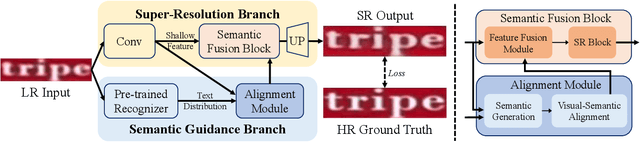
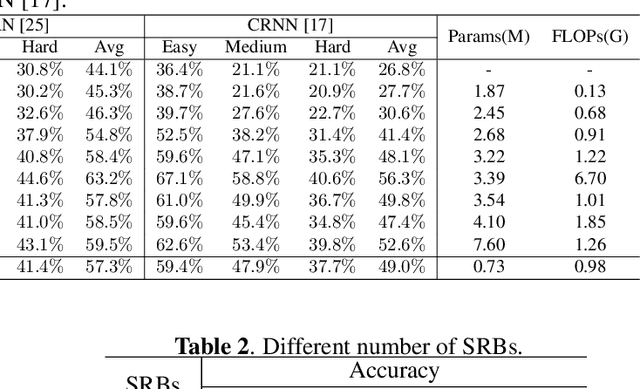
Scene text image super-resolution has significantly improved the accuracy of scene text recognition. However, many existing methods emphasize performance over efficiency and ignore the practical need for lightweight solutions in deployment scenarios. Faced with the issues, our work proposes an efficient framework called SGENet to facilitate deployment on resource-limited platforms. SGENet contains two branches: super-resolution branch and semantic guidance branch. We apply a lightweight pre-trained recognizer as a semantic extractor to enhance the understanding of text information. Meanwhile, we design the visual-semantic alignment module to achieve bidirectional alignment between image features and semantics, resulting in the generation of highquality prior guidance. We conduct extensive experiments on benchmark dataset, and the proposed SGENet achieves excellent performance with fewer computational costs. Code is available at https://github.com/SijieLiu518/SGENet
CIRP: Cross-Item Relational Pre-training for Multimodal Product Bundling
Apr 02, 2024Product bundling has been a prevailing marketing strategy that is beneficial in the online shopping scenario. Effective product bundling methods depend on high-quality item representations, which need to capture both the individual items' semantics and cross-item relations. However, previous item representation learning methods, either feature fusion or graph learning, suffer from inadequate cross-modal alignment and struggle to capture the cross-item relations for cold-start items. Multimodal pre-train models could be the potential solutions given their promising performance on various multimodal downstream tasks. However, the cross-item relations have been under-explored in the current multimodal pre-train models. To bridge this gap, we propose a novel and simple framework Cross-Item Relational Pre-training (CIRP) for item representation learning in product bundling. Specifically, we employ a multimodal encoder to generate image and text representations. Then we leverage both the cross-item contrastive loss (CIC) and individual item's image-text contrastive loss (ITC) as the pre-train objectives. Our method seeks to integrate cross-item relation modeling capability into the multimodal encoder, while preserving the in-depth aligned multimodal semantics. Therefore, even for cold-start items that have no relations, their representations are still relation-aware. Furthermore, to eliminate the potential noise and reduce the computational cost, we harness a relation pruning module to remove the noisy and redundant relations. We apply the item representations extracted by CIRP to the product bundling model ItemKNN, and experiments on three e-commerce datasets demonstrate that CIRP outperforms various leading representation learning methods.
Content-aware Masked Image Modeling Transformer for Stereo Image Compression
Mar 13, 2024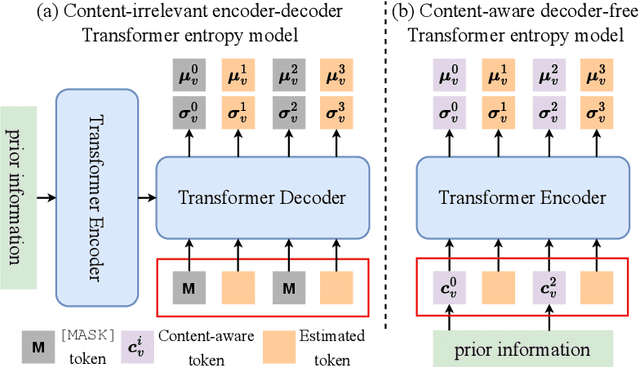
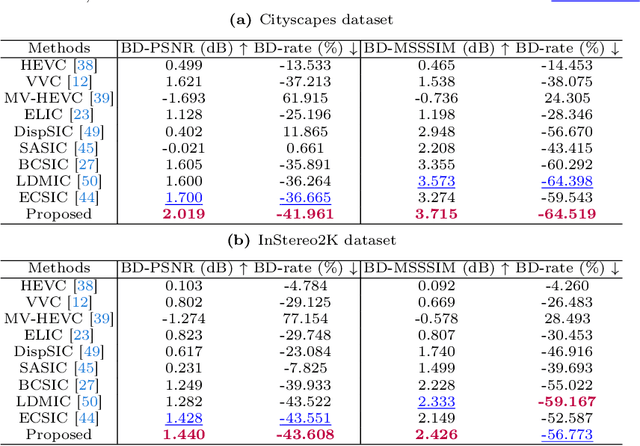
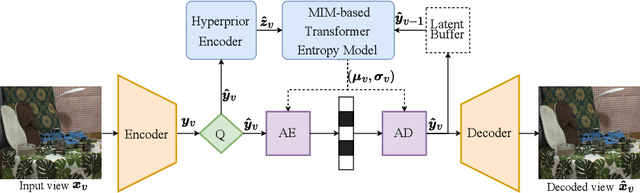
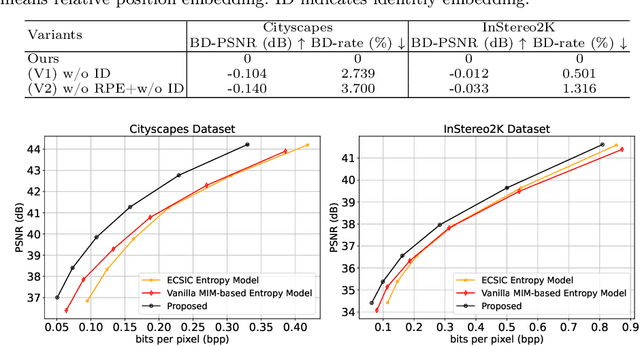
Existing learning-based stereo image codec adopt sophisticated transformation with simple entropy models derived from single image codecs to encode latent representations. However, those entropy models struggle to effectively capture the spatial-disparity characteristics inherent in stereo images, which leads to suboptimal rate-distortion results. In this paper, we propose a stereo image compression framework, named CAMSIC. CAMSIC independently transforms each image to latent representation and employs a powerful decoder-free Transformer entropy model to capture both spatial and disparity dependencies, by introducing a novel content-aware masked image modeling (MIM) technique. Our content-aware MIM facilitates efficient bidirectional interaction between prior information and estimated tokens, which naturally obviates the need for an extra Transformer decoder. Experiments show that our stereo image codec achieves state-of-the-art rate-distortion performance on two stereo image datasets Cityscapes and InStereo2K with fast encoding and decoding speed.
ZoDi: Zero-Shot Domain Adaptation with Diffusion-Based Image Transfer
Mar 20, 2024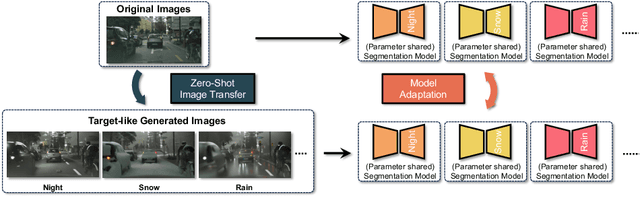
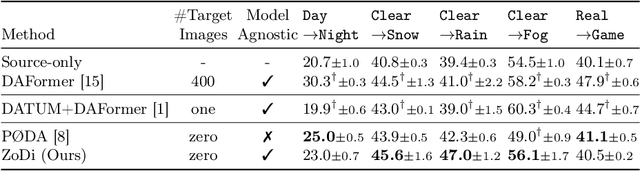
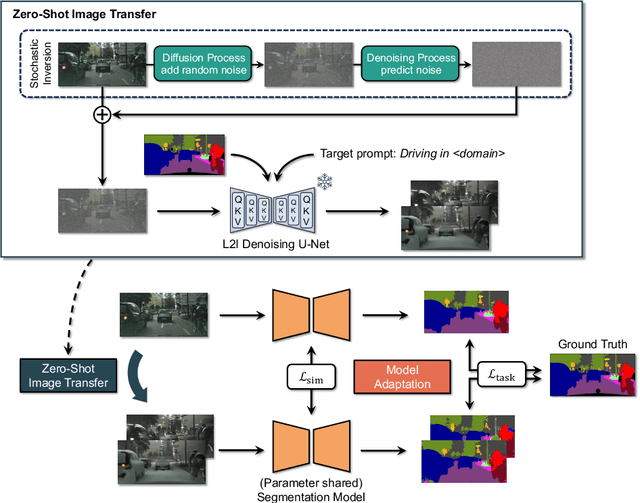
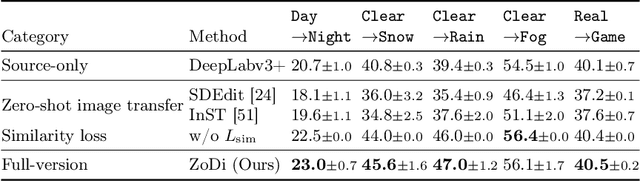
Deep learning models achieve high accuracy in segmentation tasks among others, yet domain shift often degrades the models' performance, which can be critical in real-world scenarios where no target images are available. This paper proposes a zero-shot domain adaptation method based on diffusion models, called ZoDi, which is two-fold by the design: zero-shot image transfer and model adaptation. First, we utilize an off-the-shelf diffusion model to synthesize target-like images by transferring the domain of source images to the target domain. In this we specifically try to maintain the layout and content by utilising layout-to-image diffusion models with stochastic inversion. Secondly, we train the model using both source images and synthesized images with the original segmentation maps while maximizing the feature similarity of images from the two domains to learn domain-robust representations. Through experiments we show benefits of ZoDi in the task of image segmentation over state-of-the-art methods. It is also more applicable than existing CLIP-based methods because it assumes no specific backbone or models, and it enables to estimate the model's performance without target images by inspecting generated images. Our implementation will be publicly available.
Dependability Evaluation of Stable Diffusion with Soft Errors on the Model Parameters
Mar 30, 2024Stable Diffusion is a popular Transformer-based model for image generation from text; it applies an image information creator to the input text and the visual knowledge is added in a step-by-step fashion to create an image that corresponds to the input text. However, this diffusion process can be corrupted by errors from the underlying hardware, which are especially relevant for implementations at the nanoscales. In this paper, the dependability of Stable Diffusion is studied focusing on soft errors in the memory that stores the model parameters; specifically, errors are injected into some critical layers of the Transformer in different blocks of the image information creator, to evaluate their impact on model performance. The simulations results reveal several conclusions: 1) errors on the down blocks of the creator have a larger impact on the quality of the generated images than those on the up blocks, while the errors on middle block have negligible effect; 2) errors on the self-attention (SA) layers have larger impact on the results than those on the cross-attention (CA) layers; 3) for CA layers, errors on deeper levels result in a larger impact; 4) errors on blocks at the first levels tend to introduce noise in the image, and those on deep layers tend to introduce large colored blocks. These results provide an initial understanding of the impact of errors on Stable Diffusion.
A Recommender System for NFT Collectibles with Item Feature
Apr 03, 2024Recommender systems have been actively studied and applied in various domains to deal with information overload. Although there are numerous studies on recommender systems for movies, music, and e-commerce, comparatively less attention has been paid to the recommender system for NFTs despite the continuous growth of the NFT market. This paper presents a recommender system for NFTs that utilizes a variety of data sources, from NFT transaction records to external item features, to generate precise recommendations that cater to individual preferences. We develop a data-efficient graph-based recommender system to efficiently capture the complex relationship between each item and users and generate node(item) embeddings which incorporate both node feature information and graph structure. Furthermore, we exploit inputs beyond user-item interactions, such as image feature, text feature, and price feature. Numerical experiments verify the performance of the graph-based recommender system improves significantly after utilizing all types of item features as side information, thereby outperforming all other baselines.
BCAmirs at SemEval-2024 Task 4: Beyond Words: A Multimodal and Multilingual Exploration of Persuasion in Memes
Apr 03, 2024Memes, combining text and images, frequently use metaphors to convey persuasive messages, shaping public opinion. Motivated by this, our team engaged in SemEval-2024 Task 4, a hierarchical multi-label classification task designed to identify rhetorical and psychological persuasion techniques embedded within memes. To tackle this problem, we introduced a caption generation step to assess the modality gap and the impact of additional semantic information from images, which improved our result. Our best model utilizes GPT-4 generated captions alongside meme text to fine-tune RoBERTa as the text encoder and CLIP as the image encoder. It outperforms the baseline by a large margin in all 12 subtasks. In particular, it ranked in top-3 across all languages in Subtask 2a, and top-4 in Subtask 2b, demonstrating quantitatively strong performance. The improvement achieved by the introduced intermediate step is likely attributable to the metaphorical essence of images that challenges visual encoders. This highlights the potential for improving abstract visual semantics encoding.
Model-agnostic Origin Attribution of Generated Images with Few-shot Examples
Apr 03, 2024Recent progress in visual generative models enables the generation of high-quality images. To prevent the misuse of generated images, it is important to identify the origin model that generates them. In this work, we study the origin attribution of generated images in a practical setting where only a few images generated by a source model are available and the source model cannot be accessed. The goal is to check if a given image is generated by the source model. We first formulate this problem as a few-shot one-class classification task. To solve the task, we propose OCC-CLIP, a CLIP-based framework for few-shot one-class classification, enabling the identification of an image's source model, even among multiple candidates. Extensive experiments corresponding to various generative models verify the effectiveness of our OCC-CLIP framework. Furthermore, an experiment based on the recently released DALL-E 3 API verifies the real-world applicability of our solution.
MatAtlas: Text-driven Consistent Geometry Texturing and Material Assignment
Apr 03, 2024We present MatAtlas, a method for consistent text-guided 3D model texturing. Following recent progress we leverage a large scale text-to-image generation model (e.g., Stable Diffusion) as a prior to texture a 3D model. We carefully design an RGB texturing pipeline that leverages a grid pattern diffusion, driven by depth and edges. By proposing a multi-step texture refinement process, we significantly improve the quality and 3D consistency of the texturing output. To further address the problem of baked-in lighting, we move beyond RGB colors and pursue assigning parametric materials to the assets. Given the high-quality initial RGB texture, we propose a novel material retrieval method capitalized on Large Language Models (LLM), enabling editabiliy and relightability. We evaluate our method on a wide variety of geometries and show that our method significantly outperform prior arts. We also analyze the role of each component through a detailed ablation study.