 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
A Multi-scale Generalized Shrinkage Threshold Network for Image Blind Deblurring in Remote Sensing
Sep 14, 2023
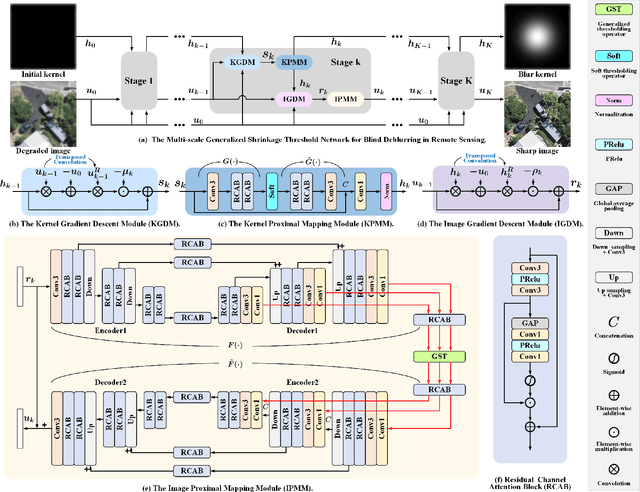
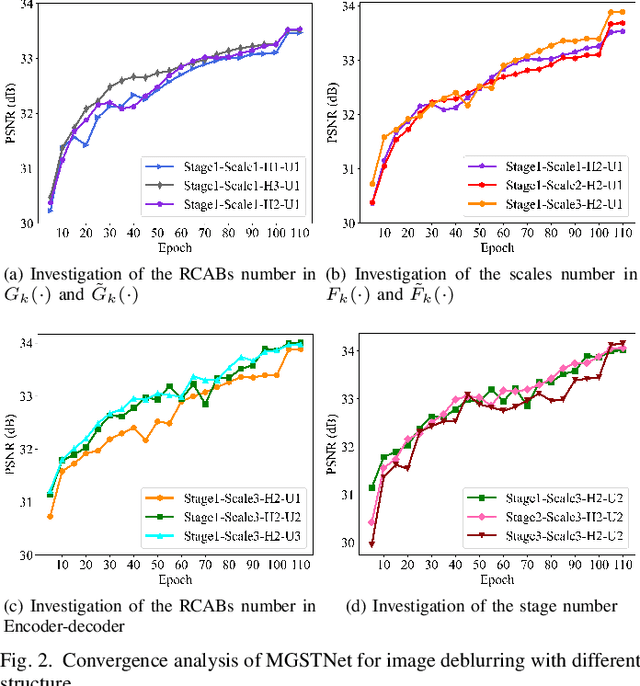


Remote sensing images are essential for many earth science applications, but their quality can be degraded due to limitations in sensor technology and complex imaging environments. To address this, various remote sensing image deblurring methods have been developed to restore sharp, high-quality images from degraded observational data. However, most traditional model-based deblurring methods usually require predefined hand-craft prior assumptions, which are difficult to handle in complex applications, and most deep learning-based deblurring methods are designed as a black box, lacking transparency and interpretability. In this work, we propose a novel blind deblurring learning framework based on alternating iterations of shrinkage thresholds, alternately updating blurring kernels and images, with the theoretical foundation of network design. Additionally, we propose a learnable blur kernel proximal mapping module to improve the blur kernel evaluation in the kernel domain. Then, we proposed a deep proximal mapping module in the image domain, which combines a generalized shrinkage threshold operator and a multi-scale prior feature extraction block. This module also introduces an attention mechanism to adaptively adjust the prior importance, thus avoiding the drawbacks of hand-crafted image prior terms. Thus, a novel multi-scale generalized shrinkage threshold network (MGSTNet) is designed to specifically focus on learning deep geometric prior features to enhance image restoration. Experiments demonstrate the superiority of our MGSTNet framework on remote sensing image datasets compared to existing deblurring methods.
YOLOv8-Based Visual Detection of Road Hazards: Potholes, Sewer Covers, and Manholes
Oct 31, 2023Effective detection of road hazards plays a pivotal role in road infrastructure maintenance and ensuring road safety. This research paper provides a comprehensive evaluation of YOLOv8, an object detection model, in the context of detecting road hazards such as potholes, Sewer Covers, and Man Holes. A comparative analysis with previous iterations, YOLOv5 and YOLOv7, is conducted, emphasizing the importance of computational efficiency in various applications. The paper delves into the architecture of YOLOv8 and explores image preprocessing techniques aimed at enhancing detection accuracy across diverse conditions, including variations in lighting, road types, hazard sizes, and types. Furthermore, hyperparameter tuning experiments are performed to optimize model performance through adjustments in learning rates, batch sizes, anchor box sizes, and augmentation strategies. Model evaluation is based on Mean Average Precision (mAP), a widely accepted metric for object detection performance. The research assesses the robustness and generalization capabilities of the models through mAP scores calculated across the diverse test scenarios, underlining the significance of YOLOv8 in road hazard detection and infrastructure maintenance.
View Classification and Object Detection in Cardiac Ultrasound to Localize Valves via Deep Learning
Oct 31, 2023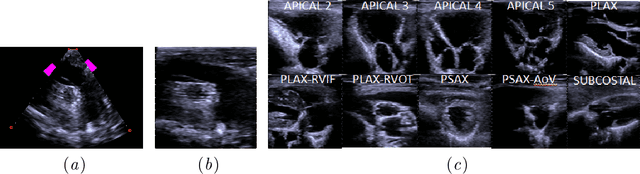

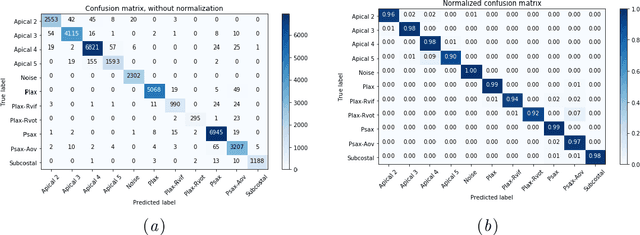
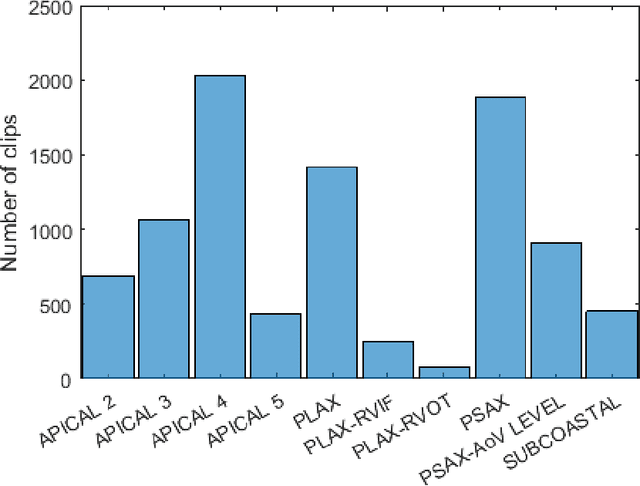
Echocardiography provides an important tool for clinicians to observe the function of the heart in real time, at low cost, and without harmful radiation. Automated localization and classification of heart valves enables automatic extraction of quantities associated with heart mechanical function and related blood flow measurements. We propose a machine learning pipeline that uses deep neural networks for separate classification and localization steps. As the first step in the pipeline, we apply view classification to echocardiograms with ten unique anatomic views of the heart. In the second step, we apply deep learning-based object detection to both localize and identify the valves. Image segmentation based object detection in echocardiography has been shown in many earlier studies but, to the best of our knowledge, this is the first study that predicts the bounding boxes around the valves along with classification from 2D ultrasound images with the help of deep neural networks. Our object detection experiments applied to the Apical views suggest that it is possible to localize and identify multiple valves precisely.
Efficient Large Scale Medical Image Dataset Preparation for Machine Learning Applications
Sep 29, 2023In the rapidly evolving field of medical imaging, machine learning algorithms have become indispensable for enhancing diagnostic accuracy. However, the effectiveness of these algorithms is contingent upon the availability and organization of high-quality medical imaging datasets. Traditional Digital Imaging and Communications in Medicine (DICOM) data management systems are inadequate for handling the scale and complexity of data required to be facilitated in machine learning algorithms. This paper introduces an innovative data curation tool, developed as part of the Kaapana open-source toolkit, aimed at streamlining the organization, management, and processing of large-scale medical imaging datasets. The tool is specifically tailored to meet the needs of radiologists and machine learning researchers. It incorporates advanced search, auto-annotation and efficient tagging functionalities for improved data curation. Additionally, the tool facilitates quality control and review, enabling researchers to validate image and segmentation quality in large datasets. It also plays a critical role in uncovering potential biases in datasets by aggregating and visualizing metadata, which is essential for developing robust machine learning models. Furthermore, Kaapana is integrated within the Radiological Cooperative Network (RACOON), a pioneering initiative aimed at creating a comprehensive national infrastructure for the aggregation, transmission, and consolidation of radiological data across all university clinics throughout Germany. A supplementary video showcasing the tool's functionalities can be accessed at https://bit.ly/MICCAI-DEMI2023.
Scene Graph Conditioning in Latent Diffusion
Oct 16, 2023Diffusion models excel in image generation but lack detailed semantic control using text prompts. Additional techniques have been developed to address this limitation. However, conditioning diffusion models solely on text-based descriptions is challenging due to ambiguity and lack of structure. In contrast, scene graphs offer a more precise representation of image content, making them superior for fine-grained control and accurate synthesis in image generation models. The amount of image and scene-graph data is sparse, which makes fine-tuning large diffusion models challenging. We propose multiple approaches to tackle this problem using ControlNet and Gated Self-Attention. We were able to show that using out proposed methods it is possible to generate images from scene graphs with much higher quality, outperforming previous methods. Our source code is publicly available on https://github.com/FrankFundel/SGCond
ManifoldNeRF: View-dependent Image Feature Supervision for Few-shot Neural Radiance Fields
Oct 20, 2023Novel view synthesis has recently made significant progress with the advent of Neural Radiance Fields (NeRF). DietNeRF is an extension of NeRF that aims to achieve this task from only a few images by introducing a new loss function for unknown viewpoints with no input images. The loss function assumes that a pre-trained feature extractor should output the same feature even if input images are captured at different viewpoints since the images contain the same object. However, while that assumption is ideal, in reality, it is known that as viewpoints continuously change, also feature vectors continuously change. Thus, the assumption can harm training. To avoid this harmful training, we propose ManifoldNeRF, a method for supervising feature vectors at unknown viewpoints using interpolated features from neighboring known viewpoints. Since the method provides appropriate supervision for each unknown viewpoint by the interpolated features, the volume representation is learned better than DietNeRF. Experimental results show that the proposed method performs better than others in a complex scene. We also experimented with several subsets of viewpoints from a set of viewpoints and identified an effective set of viewpoints for real environments. This provided a basic policy of viewpoint patterns for real-world application. The code is available at https://github.com/haganelego/ManifoldNeRF_BMVC2023
Towards Increasing the Robustness of Predictive Steering-Control Autonomous Navigation Systems Against Dash Cam Image Angle Perturbations Due to Pothole Encounters
Oct 06, 2023

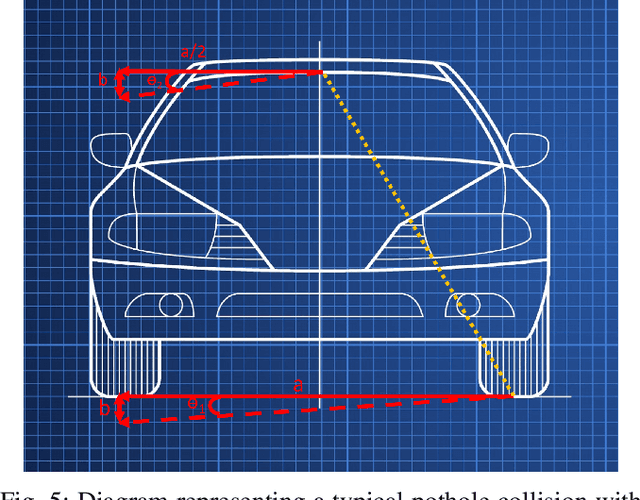
Vehicle manufacturers are racing to create autonomous navigation and steering control algorithms for their vehicles. These software are made to handle various real-life scenarios such as obstacle avoidance and lane maneuvering. There is some ongoing research to incorporate pothole avoidance into these autonomous systems. However, there is very little research on the effect of hitting a pothole on the autonomous navigation software that uses cameras to make driving decisions. Perturbations in the camera angle when hitting a pothole can cause errors in the predicted steering angle. In this paper, we present a new model to compensate for such angle perturbations and reduce any errors in steering control prediction algorithms. We evaluate our model on perturbations of publicly available datasets and show our model can reduce the errors in the estimated steering angle from perturbed images to 2.3%, making autonomous steering control robust against the dash cam image angle perturbations induced when one wheel of a car goes over a pothole.
Robust Depth Linear Error Decomposition with Double Total Variation and Nuclear Norm for Dynamic MRI Reconstruction
Oct 23, 2023Compressed Sensing (CS) significantly speeds up Magnetic Resonance Image (MRI) processing and achieves accurate MRI reconstruction from under-sampled k-space data. According to the current research, there are still several problems with dynamic MRI k-space reconstruction based on CS. 1) There are differences between the Fourier domain and the Image domain, and the differences between MRI processing of different domains need to be considered. 2) As three-dimensional data, dynamic MRI has its spatial-temporal characteristics, which need to calculate the difference and consistency of surface textures while preserving structural integrity and uniqueness. 3) Dynamic MRI reconstruction is time-consuming and computationally resource-dependent. In this paper, we propose a novel robust low-rank dynamic MRI reconstruction optimization model via highly under-sampled and Discrete Fourier Transform (DFT) called the Robust Depth Linear Error Decomposition Model (RDLEDM). Our method mainly includes linear decomposition, double Total Variation (TV), and double Nuclear Norm (NN) regularizations. By adding linear image domain error analysis, the noise is reduced after under-sampled and DFT processing, and the anti-interference ability of the algorithm is enhanced. Double TV and NN regularizations can utilize both spatial-temporal characteristics and explore the complementary relationship between different dimensions in dynamic MRI sequences. In addition, Due to the non-smoothness and non-convexity of TV and NN terms, it is difficult to optimize the unified objective model. To address this issue, we utilize a fast algorithm by solving a primal-dual form of the original problem. Compared with five state-of-the-art methods, extensive experiments on dynamic MRI data demonstrate the superior performance of the proposed method in terms of both reconstruction accuracy and time complexity.
Contrast-agent-induced deterministic component of CT-density in the abdominal aorta during routine angiography: proof of concept study
Nov 03, 2023Background and objective: CTA is a gold standard of preoperative diagnosis of abdominal aorta and typically used for geometric-only characteristic extraction. We assume that a model describing the dynamic behavior of the contrast agent in the vessel can be developed from the data of routine CTA studies, allowing the procedure to be investigated and optimized without the need for additional perfusion CT studies. Obtained spatial distribution of CA can be valuable for both increasing the diagnostic value of a particular study and improving the CT data processing tools. Methods: In accordance with the Beer-Lambert law and the absence of chemical interaction between blood and CA, we postulated the existence of a deterministic CA-induced component in the CT signal density. The proposed model, having a double-sigmoid structure, contains six coefficients relevant to the properties of hemodynamics. To validate the model, expert segmentation was performed using the 3D Slicer application for the CTA data obtained from publicly available source. The model was fitted to the data using the non-linear least square method with Levenberg-Marquardt optimization. Results: We analyzed 594 CTA images (4 studies with median size of 144 slices, IQR [134; 158.5]; 1:1 normal:pathology balance). Goodness-of-fit was proved by Wilcox test (p-value > 0.05 for all cases). The proposed model correctly simulated normal blood flow and hemodynamics disturbances caused by local abnormalities (aneurysm, thrombus and arterial branching). Conclusions: Proposed approach can be useful for personalized CA modeling of vessels, improvement of CTA image processing and preparation of synthetic CT training data for artificial intelligence.
Towards Machine Unlearning Benchmarks: Forgetting the Personal Identities in Facial Recognition Systems
Nov 03, 2023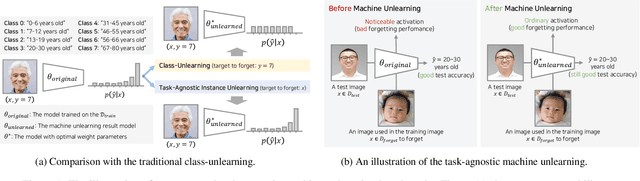

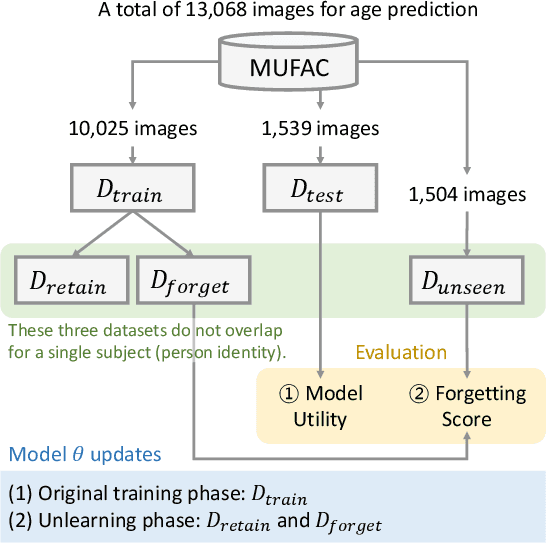

Machine unlearning is a crucial tool for enabling a classification model to forget specific data that are used in the training time. Recently, various studies have presented machine unlearning algorithms and evaluated their methods on several datasets. However, most of the current machine unlearning algorithms have been evaluated solely on traditional computer vision datasets such as CIFAR-10, MNIST, and SVHN. Furthermore, previous studies generally evaluate the unlearning methods in the class-unlearning setup. Most previous work first trains the classification models and then evaluates the machine unlearning performance of machine unlearning algorithms by forgetting selected image classes (categories) in the experiments. Unfortunately, these class-unlearning settings might not generalize to real-world scenarios. In this work, we propose a machine unlearning setting that aims to unlearn specific instance that contains personal privacy (identity) while maintaining the original task of a given model. Specifically, we propose two machine unlearning benchmark datasets, MUFAC and MUCAC, that are greatly useful to evaluate the performance and robustness of a machine unlearning algorithm. In our benchmark datasets, the original model performs facial feature recognition tasks: face age estimation (multi-class classification) and facial attribute classification (binary class classification), where a class does not depend on any single target subject (personal identity), which can be a realistic setting. Moreover, we also report the performance of the state-of-the-art machine unlearning methods on our proposed benchmark datasets. All the datasets, source codes, and trained models are publicly available at https://github.com/ndb796/MachineUnlearning.