 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Architecture of Data Anomaly Detection-Enhanced Decentralized Expert System for Early-Stage Alzheimer's Disease Prediction
Nov 01, 2023
Alzheimer's Disease is a global health challenge that requires early and accurate detection to improve patient outcomes. Magnetic Resonance Imaging (MRI) holds significant diagnostic potential, but its effective analysis remains a formidable task. This study introduces a groundbreaking decentralized expert system that cleverly combines blockchain technology with Artificial Intelligence (AI) to integrate robust anomaly detection for patient-submitted data. Traditional diagnostic methods often lead to delayed and imprecise predictions, especially in the early stages of the disease. Centralized data repositories struggle to manage the immense volumes of MRI data, and persistent privacy concerns hinder collaborative efforts. Our innovative solution harnesses decentralization to protect data integrity and patient privacy, facilitated by blockchain technology. It not only emphasizes AI-driven MRI analysis but also incorporates a sophisticated data anomaly detection architecture. These mechanisms scrutinize patient-contributed data for various issues, including data quality problems and atypical findings within MRI images. Conducting an exhaustive check of MRI image correctness and quality directly on the blockchain is impractical due to computational complexity and cost constraints. Typically, such checks are performed off-chain, and the blockchain securely records the results. This comprehensive approach empowers our decentralized app to provide more precise early-stage Alzheimer's Disease predictions. By merging the strengths of blockchain, AI, and anomaly detection, our system represents a pioneering step towards revolutionizing disease diagnostics.
Introducing Shape Prior Module in Diffusion Model for Medical Image Segmentation
Sep 12, 2023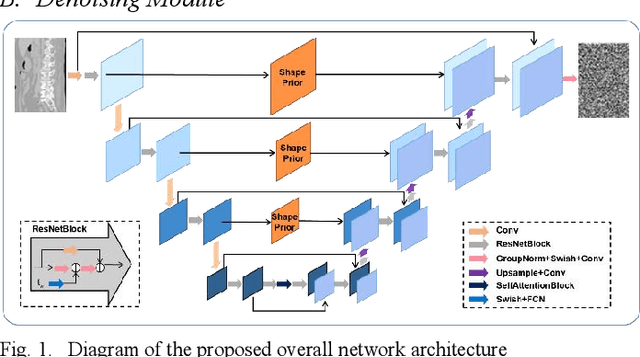
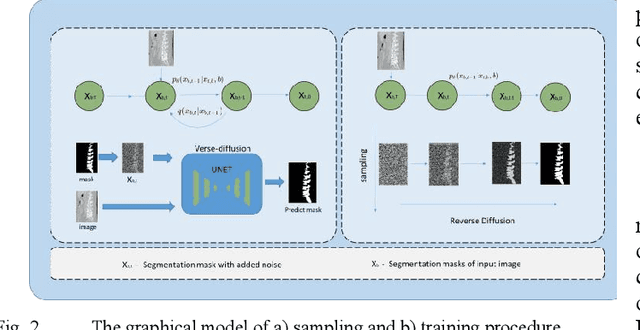

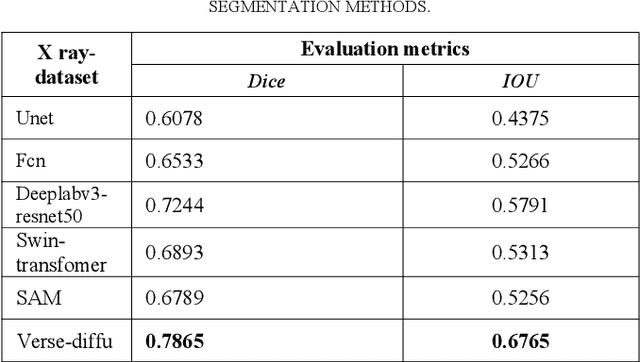
Medical image segmentation is critical for diagnosing and treating spinal disorders. However, the presence of high noise, ambiguity, and uncertainty makes this task highly challenging. Factors such as unclear anatomical boundaries, inter-class similarities, and irrational annotations contribute to this challenge. Achieving both accurate and diverse segmentation templates is essential to support radiologists in clinical practice. In recent years, denoising diffusion probabilistic modeling (DDPM) has emerged as a prominent research topic in computer vision. It has demonstrated effectiveness in various vision tasks, including image deblurring, super-resolution, anomaly detection, and even semantic representation generation at the pixel level. Despite the robustness of existing diffusion models in visual generation tasks, they still struggle with discrete masks and their various effects. To address the need for accurate and diverse spine medical image segmentation templates, we propose an end-to-end framework called VerseDiff-UNet, which leverages the denoising diffusion probabilistic model (DDPM). Our approach integrates the diffusion model into a standard U-shaped architecture. At each step, we combine the noise-added image with the labeled mask to guide the diffusion direction accurately towards the target region. Furthermore, to capture specific anatomical a priori information in medical images, we incorporate a shape a priori module. This module efficiently extracts structural semantic information from the input spine images. We evaluate our method on a single dataset of spine images acquired through X-ray imaging. Our results demonstrate that VerseDiff-UNet significantly outperforms other state-of-the-art methods in terms of accuracy while preserving the natural features and variations of anatomy.
Learning In-between Imagery Dynamics via Physical Latent Spaces
Oct 14, 2023
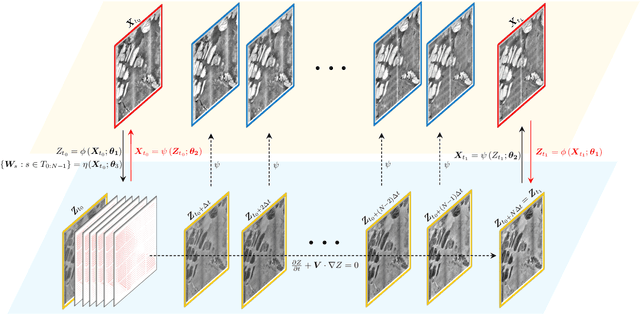

We present a framework designed to learn the underlying dynamics between two images observed at consecutive time steps. The complex nature of image data and the lack of temporal information pose significant challenges in capturing the unique evolving patterns. Our proposed method focuses on estimating the intermediary stages of image evolution, allowing for interpretability through latent dynamics while preserving spatial correlations with the image. By incorporating a latent variable that follows a physical model expressed in partial differential equations (PDEs), our approach ensures the interpretability of the learned model and provides insight into corresponding image dynamics. We demonstrate the robustness and effectiveness of our learning framework through a series of numerical tests using geoscientific imagery data.
Empowering Low-Light Image Enhancer through Customized Learnable Priors
Sep 05, 2023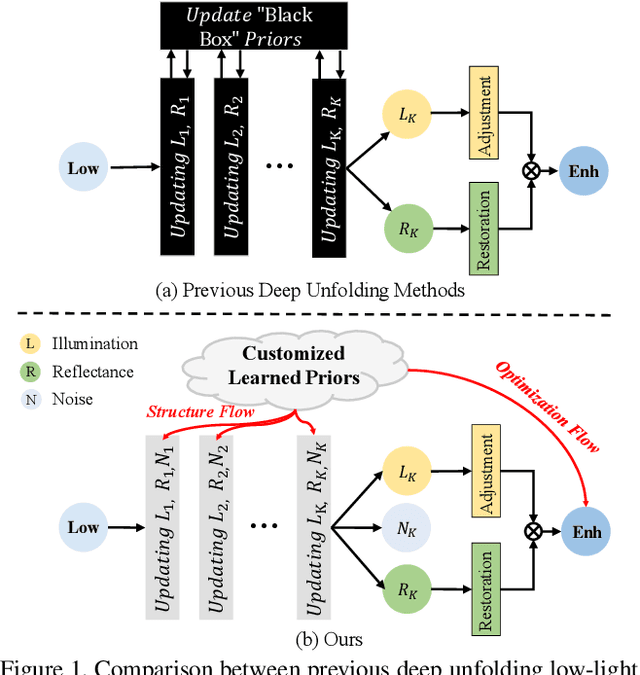
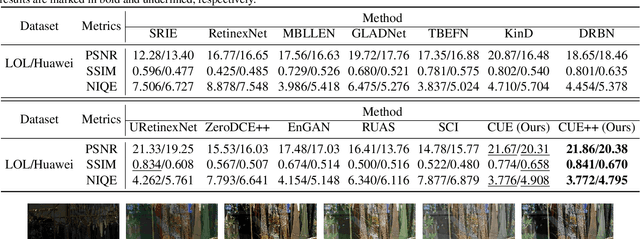
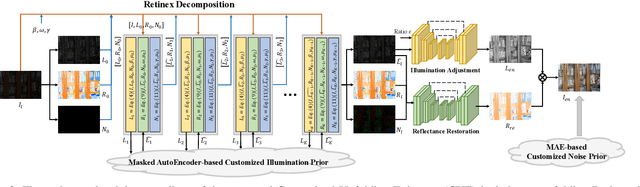

Deep neural networks have achieved remarkable progress in enhancing low-light images by improving their brightness and eliminating noise. However, most existing methods construct end-to-end mapping networks heuristically, neglecting the intrinsic prior of image enhancement task and lacking transparency and interpretability. Although some unfolding solutions have been proposed to relieve these issues, they rely on proximal operator networks that deliver ambiguous and implicit priors. In this work, we propose a paradigm for low-light image enhancement that explores the potential of customized learnable priors to improve the transparency of the deep unfolding paradigm. Motivated by the powerful feature representation capability of Masked Autoencoder (MAE), we customize MAE-based illumination and noise priors and redevelop them from two perspectives: 1) \textbf{structure flow}: we train the MAE from a normal-light image to its illumination properties and then embed it into the proximal operator design of the unfolding architecture; and m2) \textbf{optimization flow}: we train MAE from a normal-light image to its gradient representation and then employ it as a regularization term to constrain noise in the model output. These designs improve the interpretability and representation capability of the model.Extensive experiments on multiple low-light image enhancement datasets demonstrate the superiority of our proposed paradigm over state-of-the-art methods. Code is available at https://github.com/zheng980629/CUE.
UnitModule: A Lightweight Joint Image Enhancement Module for Underwater Object Detection
Sep 09, 2023

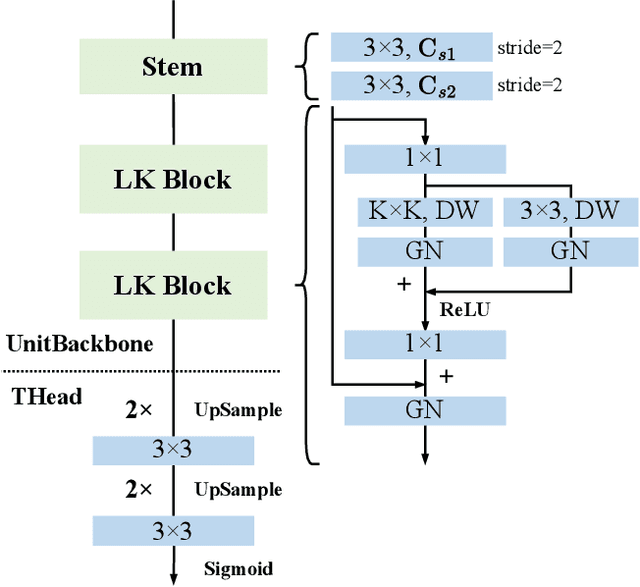
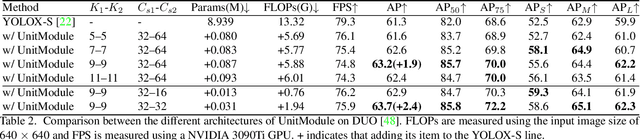
Underwater object detection faces the problem of underwater image degradation, which affects the performance of the detector. Underwater object detection methods based on noise reduction and image enhancement usually do not provide images preferred by the detector or require additional datasets. In this paper, we propose a plug-and-play Underwater joint image enhancement Module (UnitModule) that provides the input image preferred by the detector. We design an unsupervised learning loss for the joint training of UnitModule with the detector without additional datasets to improve the interaction between UnitModule and the detector. Furthermore, a color cast predictor with the assisting color cast loss and a data augmentation called Underwater Color Random Transfer (UCRT) are designed to improve the performance of UnitModule on underwater images with different color casts. Extensive experiments are conducted on DUO for different object detection models, where UnitModule achieves the highest performance improvement of 2.6 AP for YOLOv5-S and gains the improvement of 3.3 AP on the brand-new test set (URPCtest). And UnitModule significantly improves the performance of all object detection models we test, especially for models with a small number of parameters. In addition, UnitModule with a small number of parameters of 31K has little effect on the inference speed of the original object detection model. Our quantitative and visual analysis also demonstrates the effectiveness of UnitModule in enhancing the input image and improving the perception ability of the detector for object features.
Exploring Semantic Consistency in Unpaired Image Translation to Generate Data for Surgical Applications
Sep 11, 2023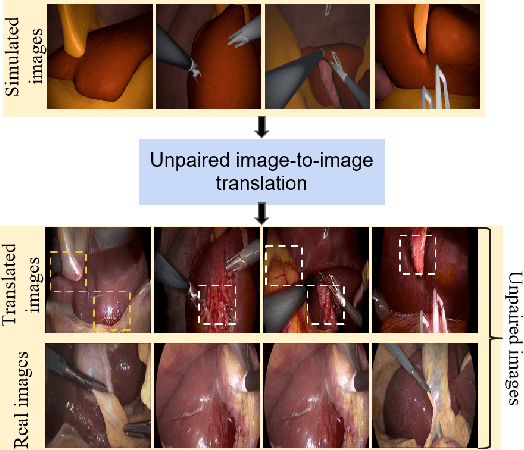
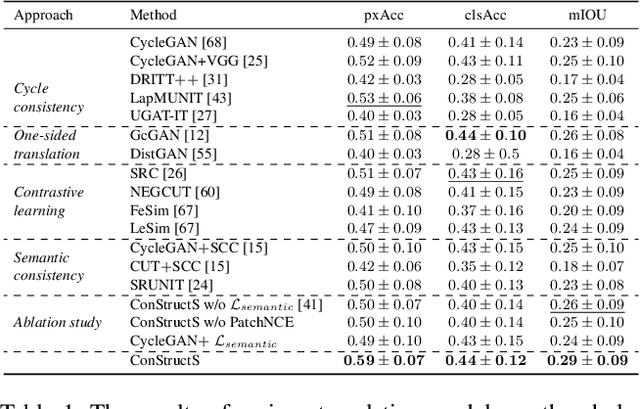
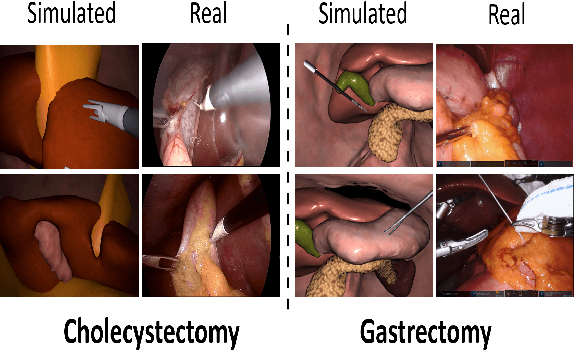
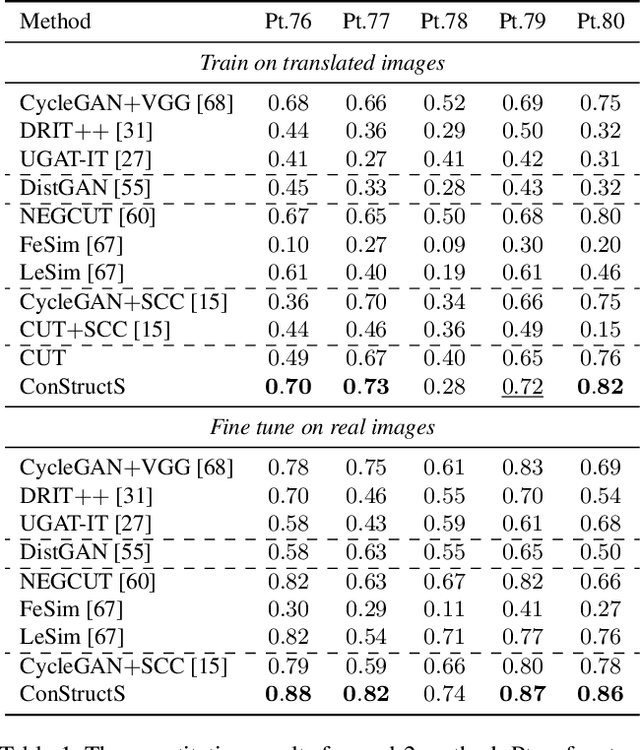
In surgical computer vision applications, obtaining labeled training data is challenging due to data-privacy concerns and the need for expert annotation. Unpaired image-to-image translation techniques have been explored to automatically generate large annotated datasets by translating synthetic images to the realistic domain. However, preserving the structure and semantic consistency between the input and translated images presents significant challenges, mainly when there is a distributional mismatch in the semantic characteristics of the domains. This study empirically investigates unpaired image translation methods for generating suitable data in surgical applications, explicitly focusing on semantic consistency. We extensively evaluate various state-of-the-art image translation models on two challenging surgical datasets and downstream semantic segmentation tasks. We find that a simple combination of structural-similarity loss and contrastive learning yields the most promising results. Quantitatively, we show that the data generated with this approach yields higher semantic consistency and can be used more effectively as training data.
AiluRus: A Scalable ViT Framework for Dense Prediction
Nov 02, 2023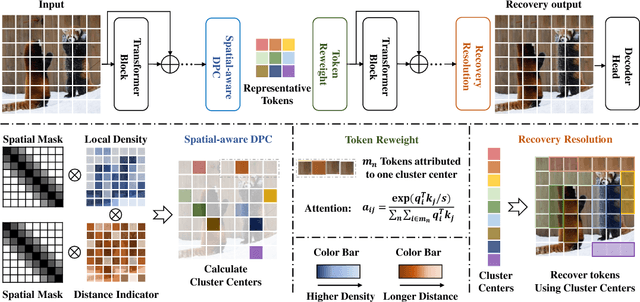
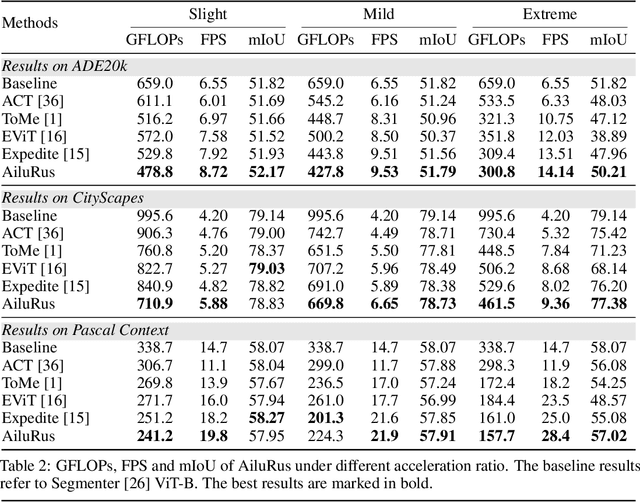
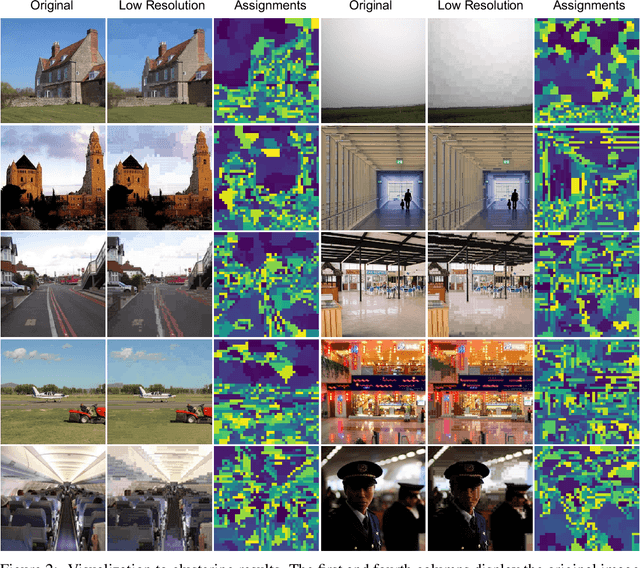
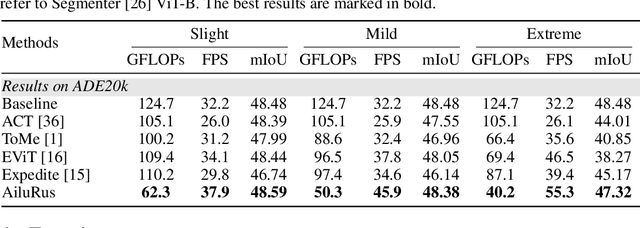
Vision transformers (ViTs) have emerged as a prevalent architecture for vision tasks owing to their impressive performance. However, when it comes to handling long token sequences, especially in dense prediction tasks that require high-resolution input, the complexity of ViTs increases significantly. Notably, dense prediction tasks, such as semantic segmentation or object detection, emphasize more on the contours or shapes of objects, while the texture inside objects is less informative. Motivated by this observation, we propose to apply adaptive resolution for different regions in the image according to their importance. Specifically, at the intermediate layer of the ViT, we utilize a spatial-aware density-based clustering algorithm to select representative tokens from the token sequence. Once the representative tokens are determined, we proceed to merge other tokens into their closest representative token. Consequently, semantic similar tokens are merged together to form low-resolution regions, while semantic irrelevant tokens are preserved independently as high-resolution regions. This strategy effectively reduces the number of tokens, allowing subsequent layers to handle a reduced token sequence and achieve acceleration. We evaluate our proposed method on three different datasets and observe promising performance. For example, the "Segmenter ViT-L" model can be accelerated by 48% FPS without fine-tuning, while maintaining the performance. Additionally, our method can be applied to accelerate fine-tuning as well. Experimental results demonstrate that we can save 52% training time while accelerating 2.46 times FPS with only a 0.09% performance drop. The code is available at https://github.com/caddyless/ailurus/tree/main.
From LAION-5B to LAION-EO: Filtering Billions of Images Using Anchor Datasets for Satellite Image Extraction
Sep 27, 2023Large datasets, such as LAION-5B, contain a diverse distribution of images shared online. However, extraction of domain-specific subsets of large image corpora is challenging. The extraction approach based on an anchor dataset, combined with further filtering, is proposed here and demonstrated for the domain of satellite imagery. This results in the release of LAION-EO, a dataset sourced from the web containing pairs of text and satellite images in high (pixel-wise) resolution. The paper outlines the acquisition procedure as well as some of the features of the dataset.
Leveraging Image-Text Similarity and Caption Modification for the DataComp Challenge: Filtering Track and BYOD Track
Oct 23, 2023Large web crawl datasets have already played an important role in learning multimodal features with high generalization capabilities. However, there are still very limited studies investigating the details or improvements of data design. Recently, a DataComp challenge has been designed to propose the best training data with the fixed models. This paper presents our solution to both filtering track and BYOD track of the DataComp challenge. Our solution adopts large multimodal models CLIP and BLIP-2 to filter and modify web crawl data, and utilize external datasets along with a bag of tricks to improve the data quality. Experiments show our solution significantly outperforms DataComp baselines (filtering track: 6.6% improvement, BYOD track: 48.5% improvement).
DeformUX-Net: Exploring a 3D Foundation Backbone for Medical Image Segmentation with Depthwise Deformable Convolution
Oct 04, 2023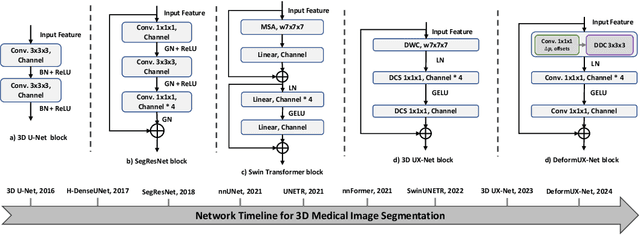
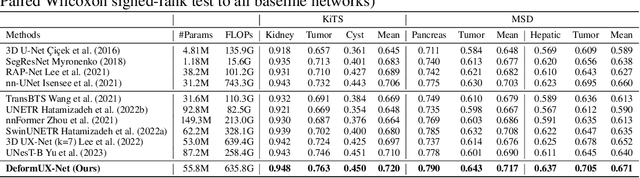
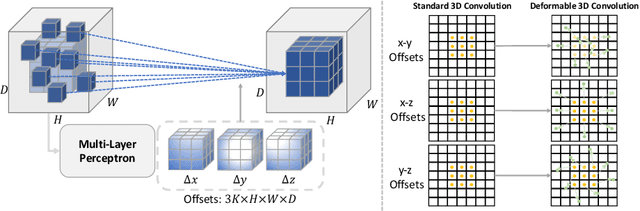
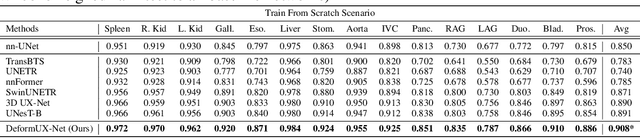
The application of 3D ViTs to medical image segmentation has seen remarkable strides, somewhat overshadowing the budding advancements in Convolutional Neural Network (CNN)-based models. Large kernel depthwise convolution has emerged as a promising technique, showcasing capabilities akin to hierarchical transformers and facilitating an expansive effective receptive field (ERF) vital for dense predictions. Despite this, existing core operators, ranging from global-local attention to large kernel convolution, exhibit inherent trade-offs and limitations (e.g., global-local range trade-off, aggregating attentional features). We hypothesize that deformable convolution can be an exploratory alternative to combine all advantages from the previous operators, providing long-range dependency, adaptive spatial aggregation and computational efficiency as a foundation backbone. In this work, we introduce 3D DeformUX-Net, a pioneering volumetric CNN model that adeptly navigates the shortcomings traditionally associated with ViTs and large kernel convolution. Specifically, we revisit volumetric deformable convolution in depth-wise setting to adapt long-range dependency with computational efficiency. Inspired by the concepts of structural re-parameterization for convolution kernel weights, we further generate the deformable tri-planar offsets by adapting a parallel branch (starting from $1\times1\times1$ convolution), providing adaptive spatial aggregation across all channels. Our empirical evaluations reveal that the 3D DeformUX-Net consistently outperforms existing state-of-the-art ViTs and large kernel convolution models across four challenging public datasets, spanning various scales from organs (KiTS: 0.680 to 0.720, MSD Pancreas: 0.676 to 0.717, AMOS: 0.871 to 0.902) to vessels (e.g., MSD hepatic vessels: 0.635 to 0.671) in mean Dice.