 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
ODM3D: Alleviating Foreground Sparsity for Semi-Supervised Monocular 3D Object Detection
Nov 07, 2023
Monocular 3D object detection (M3OD) is a significant yet inherently challenging task in autonomous driving due to absence of explicit depth cues in a single RGB image. In this paper, we strive to boost currently underperforming monocular 3D object detectors by leveraging an abundance of unlabelled data via semi-supervised learning. Our proposed ODM3D framework entails cross-modal knowledge distillation at various levels to inject LiDAR-domain knowledge into a monocular detector during training. By identifying foreground sparsity as the main culprit behind existing methods' suboptimal training, we exploit the precise localisation information embedded in LiDAR points to enable more foreground-attentive and efficient distillation via the proposed BEV occupancy guidance mask, leading to notably improved knowledge transfer and M3OD performance. Besides, motivated by insights into why existing cross-modal GT-sampling techniques fail on our task at hand, we further design a novel cross-modal object-wise data augmentation strategy for effective RGB-LiDAR joint learning. Our method ranks 1st in both KITTI validation and test benchmarks, significantly surpassing all existing monocular methods, supervised or semi-supervised, on both BEV and 3D detection metrics.
SonoSAMTrack -- Segment and Track Anything on Ultrasound Images
Nov 07, 2023In this paper, we present SonoSAM - a promptable foundational model for segmenting objects of interest on ultrasound images, followed by state of the art tracking model to perform segmentations on 2D+t and 3D ultrasound datasets. Fine-tuned exclusively on a rich, diverse set of objects from $\approx200$k ultrasound image-mask pairs, SonoSAM demonstrates state-of-the-art performance on $8$ unseen ultrasound data-sets, outperforming competing methods by a significant margin on all metrics of interest. SonoSAM achieves average dice similarity score of $>90\%$ on almost all test data-sets within 2-6 clicks on an average, making it a valuable tool for annotating ultrasound images. We also extend SonoSAM to 3-D (2-D +t) applications and demonstrate superior performance making it a valuable tool for generating dense annotations from ultrasound cine-loops. Further, to increase practical utility of SonoSAM, we propose a two-step process of fine-tuning followed by knowledge distillation to a smaller footprint model without comprising the performance. We present detailed qualitative and quantitative comparisons of SonoSAM with state-of-the-art methods showcasing efficacy of SonoSAM as one of the first reliable, generic foundational model for ultrasound.
Spatiotemporal Image Reconstruction to Enable High-Frame Rate Dynamic Photoacoustic Tomography with Rotating-Gantry Volumetric Imagers
Oct 01, 2023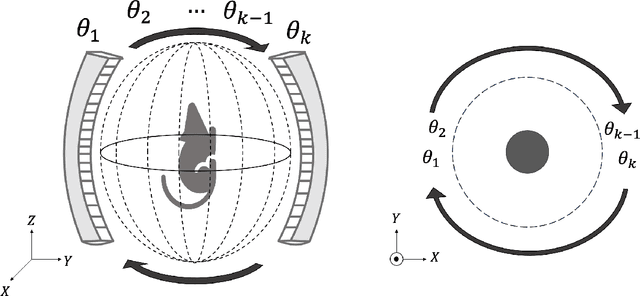
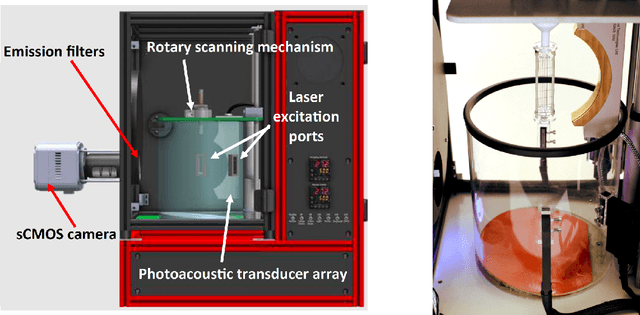
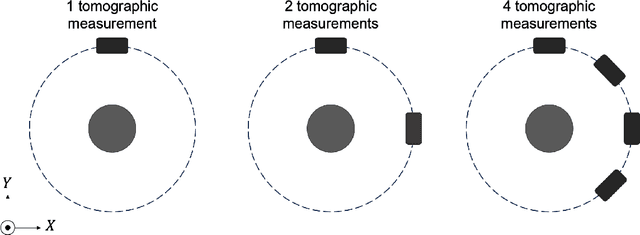
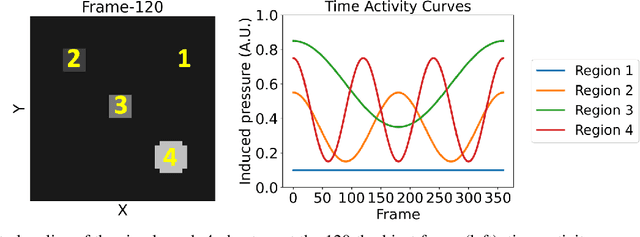
Significance: Dynamic photoacoustic computed tomography (PACT) is a valuable technique for monitoring physiological processes. However, current dynamic PACT techniques are often limited to 2D spatial imaging. While volumetric PACT imagers are commercially available, these systems typically employ a rotating gantry in which the tomographic data are sequentially acquired. Because the object varies during the data-acquisition process, the sequential data-acquisition poses challenges to image reconstruction associated with data incompleteness. The proposed method is highly significant in that it will address these challenges and enable volumetric dynamic PACT imaging with existing imagers. Aim: The aim of this study is to develop a spatiotemporal image reconstruction (STIR) method for dynamic PACT that can be applied to commercially available volumetric PACT imagers that employ a sequential scanning strategy. The proposed method aims to overcome the challenges caused by the limited number of tomographic measurements acquired per frame. Approach: A low-rank matrix estimation-based STIR method (LRME-STIR) is proposed to enable dynamic volumetric PACT. The LRME-STIR method leverages the spatiotemporal redundancies to accurately reconstruct a 4D spatiotemporal image. Results: The numerical studies substantiate the LRME-STIR method's efficacy in reconstructing 4D dynamic images from measurements acquired with a rotating gantry. The experimental study demonstrates the method's ability to faithfully recover the flow of a contrast agent at a frame rate of 0.1 s even when only a single tomographic measurement per frame is available. Conclusions: The LRME-STIR method offers a promising solution to the challenges faced by enabling 4D dynamic imaging using commercially available volumetric imagers. By enabling accurate 4D reconstruction, this method has the potential to advance preclinical research.
Interferometric Neural Networks
Oct 25, 2023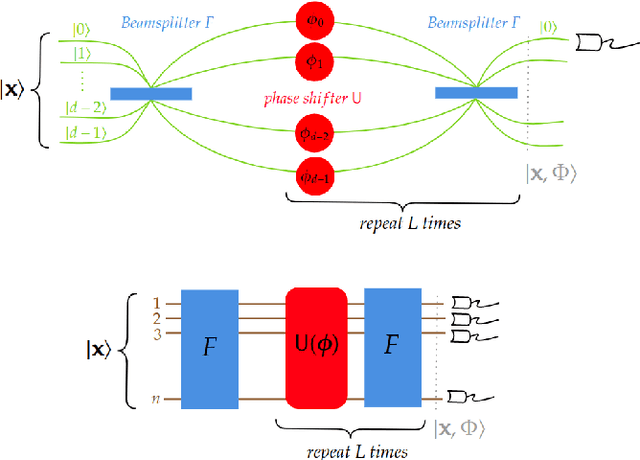
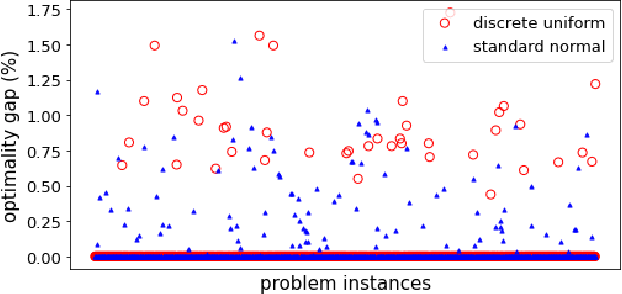
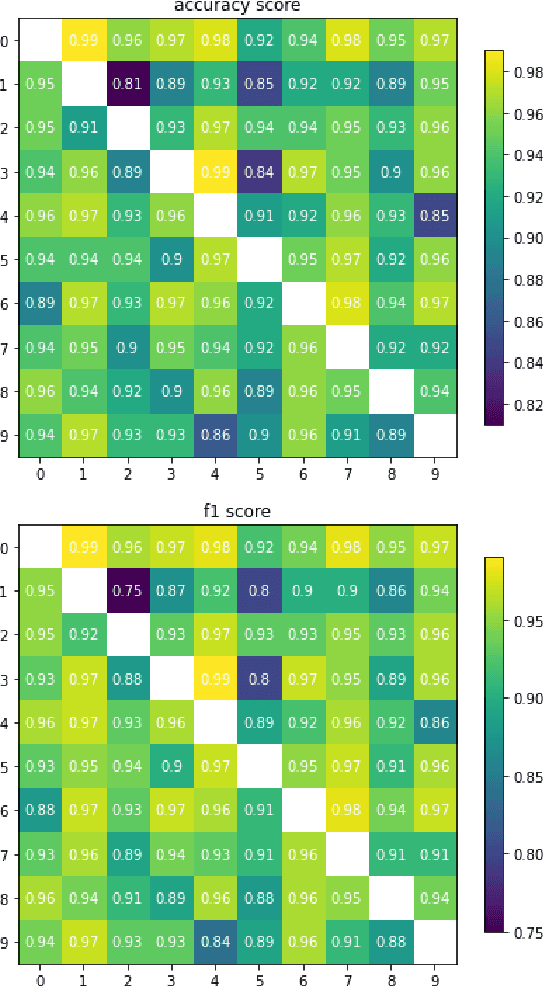
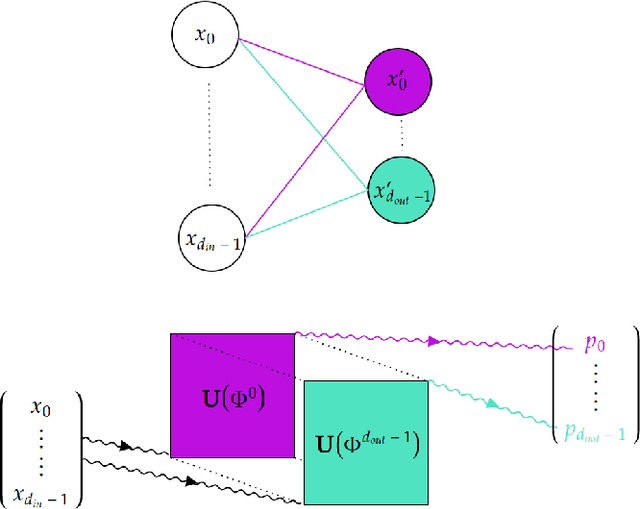
On the one hand, artificial neural networks have many successful applications in the field of machine learning and optimization. On the other hand, interferometers are integral parts of any field that deals with waves such as optics, astronomy, and quantum physics. Here, we introduce neural networks composed of interferometers and then build generative adversarial networks from them. Our networks do not have any classical layer and can be realized on quantum computers or photonic chips. We demonstrate their applicability for combinatorial optimization, image classification, and image generation. For combinatorial optimization, our network consistently converges to the global optimum or remains within a narrow range of it. In multi-class image classification tasks, our networks achieve accuracies of 93% and 83%. Lastly, we show their capability to generate images of digits from 0 to 9 as well as human faces.
BigFUSE: Global Context-Aware Image Fusion in Dual-View Light-Sheet Fluorescence Microscopy with Image Formation Prior
Sep 05, 2023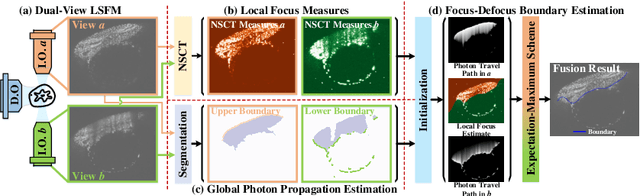
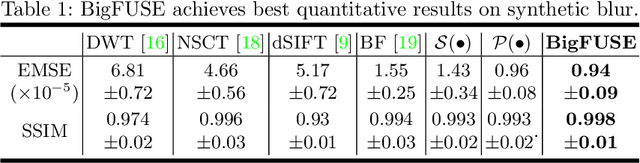


Light-sheet fluorescence microscopy (LSFM), a planar illumination technique that enables high-resolution imaging of samples, experiences defocused image quality caused by light scattering when photons propagate through thick tissues. To circumvent this issue, dualview imaging is helpful. It allows various sections of the specimen to be scanned ideally by viewing the sample from opposing orientations. Recent image fusion approaches can then be applied to determine in-focus pixels by comparing image qualities of two views locally and thus yield spatially inconsistent focus measures due to their limited field-of-view. Here, we propose BigFUSE, a global context-aware image fuser that stabilizes image fusion in LSFM by considering the global impact of photon propagation in the specimen while determining focus-defocus based on local image qualities. Inspired by the image formation prior in dual-view LSFM, image fusion is considered as estimating a focus-defocus boundary using Bayes Theorem, where (i) the effect of light scattering onto focus measures is included within Likelihood; and (ii) the spatial consistency regarding focus-defocus is imposed in Prior. The expectation-maximum algorithm is then adopted to estimate the focus-defocus boundary. Competitive experimental results show that BigFUSE is the first dual-view LSFM fuser that is able to exclude structured artifacts when fusing information, highlighting its abilities of automatic image fusion.
An Image Dataset for Benchmarking Recommender Systems with Raw Pixels
Sep 13, 2023

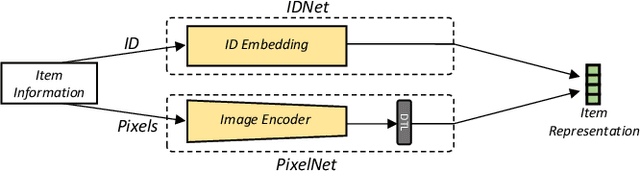
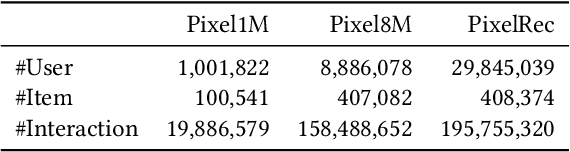
Recommender systems (RS) have achieved significant success by leveraging explicit identification (ID) features. However, the full potential of content features, especially the pure image pixel features, remains relatively unexplored. The limited availability of large, diverse, and content-driven image recommendation datasets has hindered the use of raw images as item representations. In this regard, we present PixelRec, a massive image-centric recommendation dataset that includes approximately 200 million user-image interactions, 30 million users, and 400,000 high-quality cover images. By providing direct access to raw image pixels, PixelRec enables recommendation models to learn item representation directly from them. To demonstrate its utility, we begin by presenting the results of several classical pure ID-based baseline models, termed IDNet, trained on PixelRec. Then, to show the effectiveness of the dataset's image features, we substitute the itemID embeddings (from IDNet) with a powerful vision encoder that represents items using their raw image pixels. This new model is dubbed PixelNet.Our findings indicate that even in standard, non-cold start recommendation settings where IDNet is recognized as highly effective, PixelNet can already perform equally well or even better than IDNet. Moreover, PixelNet has several other notable advantages over IDNet, such as being more effective in cold-start and cross-domain recommendation scenarios. These results underscore the importance of visual features in PixelRec. We believe that PixelRec can serve as a critical resource and testing ground for research on recommendation models that emphasize image pixel content. The dataset, code, and leaderboard will be available at https://github.com/website-pixelrec/PixelRec.
Interpretable Medical Image Classification using Prototype Learning and Privileged Information
Oct 24, 2023Interpretability is often an essential requirement in medical imaging. Advanced deep learning methods are required to address this need for explainability and high performance. In this work, we investigate whether additional information available during the training process can be used to create an understandable and powerful model. We propose an innovative solution called Proto-Caps that leverages the benefits of capsule networks, prototype learning and the use of privileged information. Evaluating the proposed solution on the LIDC-IDRI dataset shows that it combines increased interpretability with above state-of-the-art prediction performance. Compared to the explainable baseline model, our method achieves more than 6 % higher accuracy in predicting both malignancy (93.0 %) and mean characteristic features of lung nodules. Simultaneously, the model provides case-based reasoning with prototype representations that allow visual validation of radiologist-defined attributes.
* MICCAI 2023 Medical Image Computing and Computer Assisted Intervention
Nucleus-aware Self-supervised Pretraining Using Unpaired Image-to-image Translation for Histopathology Images
Sep 14, 2023
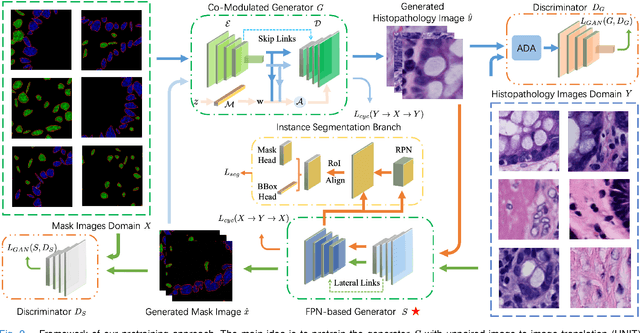
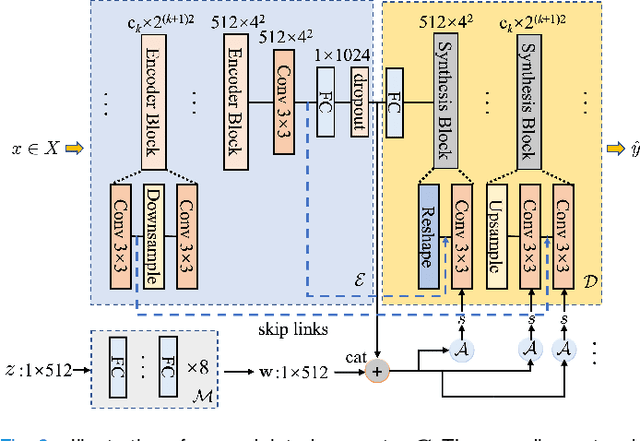
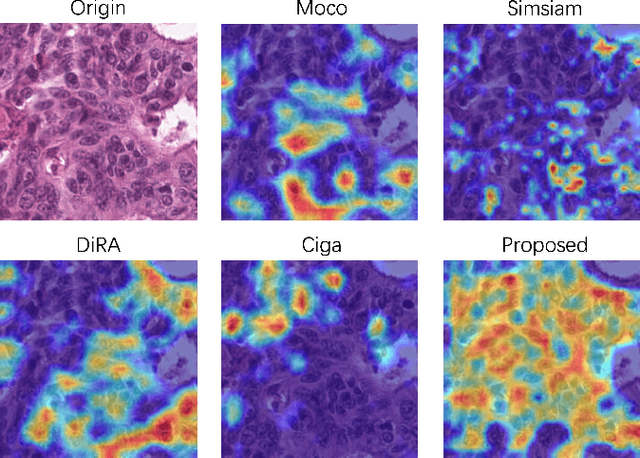
Self-supervised pretraining attempts to enhance model performance by obtaining effective features from unlabeled data, and has demonstrated its effectiveness in the field of histopathology images. Despite its success, few works concentrate on the extraction of nucleus-level information, which is essential for pathologic analysis. In this work, we propose a novel nucleus-aware self-supervised pretraining framework for histopathology images. The framework aims to capture the nuclear morphology and distribution information through unpaired image-to-image translation between histopathology images and pseudo mask images. The generation process is modulated by both conditional and stochastic style representations, ensuring the reality and diversity of the generated histopathology images for pretraining. Further, an instance segmentation guided strategy is employed to capture instance-level information. The experiments on 7 datasets show that the proposed pretraining method outperforms supervised ones on Kather classification, multiple instance learning, and 5 dense-prediction tasks with the transfer learning protocol, and yields superior results than other self-supervised approaches on 8 semi-supervised tasks. Our project is publicly available at https://github.com/zhiyuns/UNITPathSSL.
Text-image guided Diffusion Model for generating Deepfake celebrity interactions
Sep 26, 2023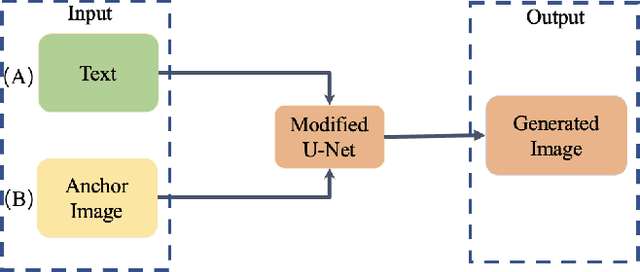
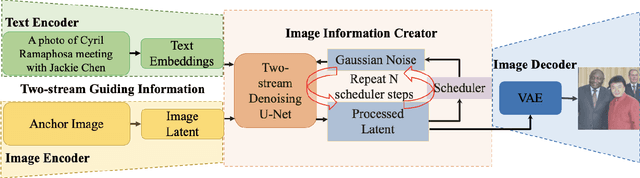
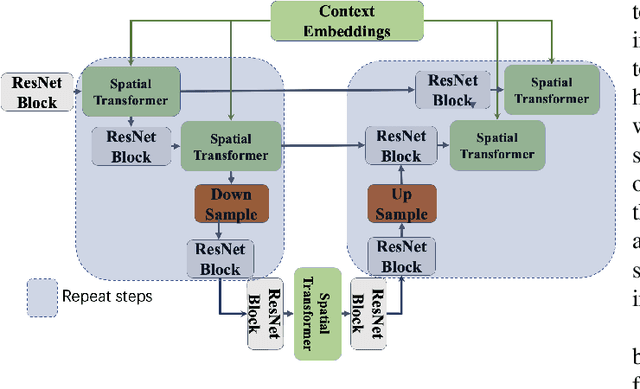
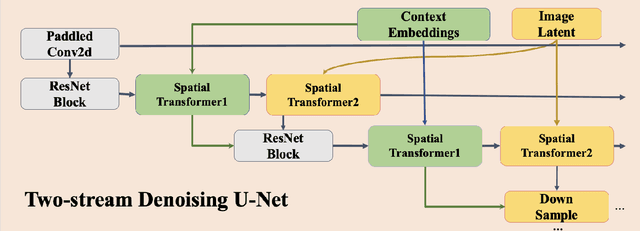
Deepfake images are fast becoming a serious concern due to their realism. Diffusion models have recently demonstrated highly realistic visual content generation, which makes them an excellent potential tool for Deepfake generation. To curb their exploitation for Deepfakes, it is imperative to first explore the extent to which diffusion models can be used to generate realistic content that is controllable with convenient prompts. This paper devises and explores a novel method in that regard. Our technique alters the popular stable diffusion model to generate a controllable high-quality Deepfake image with text and image prompts. In addition, the original stable model lacks severely in generating quality images that contain multiple persons. The modified diffusion model is able to address this problem, it add input anchor image's latent at the beginning of inferencing rather than Gaussian random latent as input. Hence, we focus on generating forged content for celebrity interactions, which may be used to spread rumors. We also apply Dreambooth to enhance the realism of our fake images. Dreambooth trains the pairing of center words and specific features to produce more refined and personalized output images. Our results show that with the devised scheme, it is possible to create fake visual content with alarming realism, such that the content can serve as believable evidence of meetings between powerful political figures.
PersonMAE: Person Re-Identification Pre-Training with Masked AutoEncoders
Nov 08, 2023Pre-training is playing an increasingly important role in learning generic feature representation for Person Re-identification (ReID). We argue that a high-quality ReID representation should have three properties, namely, multi-level awareness, occlusion robustness, and cross-region invariance. To this end, we propose a simple yet effective pre-training framework, namely PersonMAE, which involves two core designs into masked autoencoders to better serve the task of Person Re-ID. 1) PersonMAE generates two regions from the given image with RegionA as the input and \textit{RegionB} as the prediction target. RegionA is corrupted with block-wise masking to mimic common occlusion in ReID and its remaining visible parts are fed into the encoder. 2) Then PersonMAE aims to predict the whole RegionB at both pixel level and semantic feature level. It encourages its pre-trained feature representations with the three properties mentioned above. These properties make PersonMAE compatible with downstream Person ReID tasks, leading to state-of-the-art performance on four downstream ReID tasks, i.e., supervised (holistic and occluded setting), and unsupervised (UDA and USL setting). Notably, on the commonly adopted supervised setting, PersonMAE with ViT-B backbone achieves 79.8% and 69.5% mAP on the MSMT17 and OccDuke datasets, surpassing the previous state-of-the-art by a large margin of +8.0 mAP, and +5.3 mAP, respectively.