 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
A Bayesian optimization framework for the automatic tuning of MPC-based shared controllers
Nov 02, 2023
This paper presents a Bayesian optimization framework for the automatic tuning of shared controllers which are defined as a Model Predictive Control (MPC) problem. The proposed framework includes the design of performance metrics as well as the representation of user inputs for simulation-based optimization. The framework is applied to the optimization of a shared controller for an Image Guided Therapy robot. VR-based user experiments confirm the increase in performance of the automatically tuned MPC shared controller with respect to a hand-tuned baseline version as well as its generalization ability.
SAMCLR: Contrastive pre-training on complex scenes using SAM for view sampling
Oct 23, 2023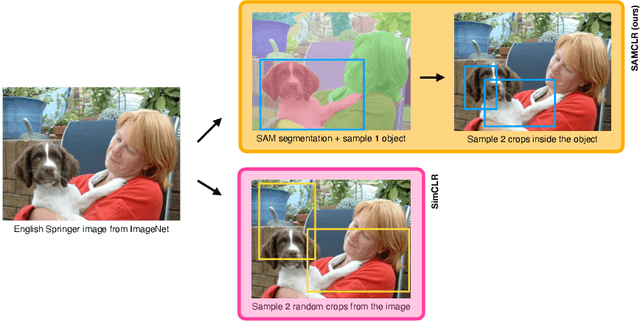
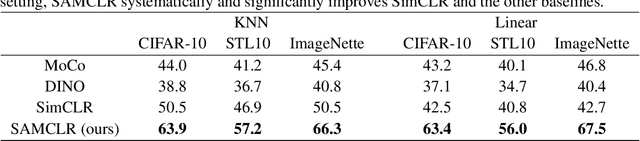
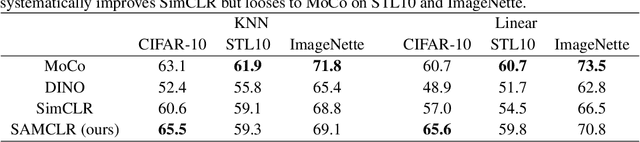
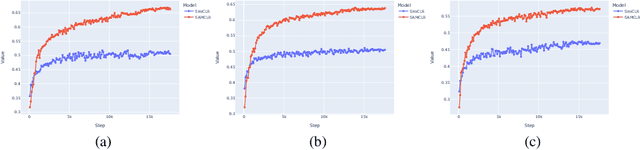
In Computer Vision, self-supervised contrastive learning enforces similar representations between different views of the same image. The pre-training is most often performed on image classification datasets, like ImageNet, where images mainly contain a single class of objects. However, when dealing with complex scenes with multiple items, it becomes very unlikely for several views of the same image to represent the same object category. In this setting, we propose SAMCLR, an add-on to SimCLR which uses SAM to segment the image into semantic regions, then sample the two views from the same region. Preliminary results show empirically that when pre-training on Cityscapes and ADE20K, then evaluating on classification on CIFAR-10, STL10 and ImageNette, SAMCLR performs at least on par with, and most often significantly outperforms not only SimCLR, but also DINO and MoCo.
Learning depth from monocular video sequences
Oct 26, 2023Learning single image depth estimation model from monocular video sequence is a very challenging problem. In this paper, we propose a novel training loss which enables us to include more images for supervision during the training process. We propose a simple yet effective model to account the frame to frame pixel motion. We also design a novel network architecture for single image estimation. When combined, our method produces state of the art results for monocular depth estimation on the KITTI dataset in the self-supervised setting.
SPADES: A Realistic Spacecraft Pose Estimation Dataset using Event Sensing
Nov 09, 2023In recent years, there has been a growing demand for improved autonomy for in-orbit operations such as rendezvous, docking, and proximity maneuvers, leading to increased interest in employing Deep Learning-based Spacecraft Pose Estimation techniques. However, due to limited access to real target datasets, algorithms are often trained using synthetic data and applied in the real domain, resulting in a performance drop due to the domain gap. State-of-the-art approaches employ Domain Adaptation techniques to mitigate this issue. In the search for viable solutions, event sensing has been explored in the past and shown to reduce the domain gap between simulations and real-world scenarios. Event sensors have made significant advancements in hardware and software in recent years. Moreover, the characteristics of the event sensor offer several advantages in space applications compared to RGB sensors. To facilitate further training and evaluation of DL-based models, we introduce a novel dataset, SPADES, comprising real event data acquired in a controlled laboratory environment and simulated event data using the same camera intrinsics. Furthermore, we propose an effective data filtering method to improve the quality of training data, thus enhancing model performance. Additionally, we introduce an image-based event representation that outperforms existing representations. A multifaceted baseline evaluation was conducted using different event representations, event filtering strategies, and algorithmic frameworks, and the results are summarized. The dataset will be made available at http://cvi2.uni.lu/spades.
Robust Retraining-free GAN Fingerprinting via Personalized Normalization
Nov 09, 2023In recent years, there has been significant growth in the commercial applications of generative models, licensed and distributed by model developers to users, who in turn use them to offer services. In this scenario, there is a need to track and identify the responsible user in the presence of a violation of the license agreement or any kind of malicious usage. Although there are methods enabling Generative Adversarial Networks (GANs) to include invisible watermarks in the images they produce, generating a model with a different watermark, referred to as a fingerprint, for each user is time- and resource-consuming due to the need to retrain the model to include the desired fingerprint. In this paper, we propose a retraining-free GAN fingerprinting method that allows model developers to easily generate model copies with the same functionality but different fingerprints. The generator is modified by inserting additional Personalized Normalization (PN) layers whose parameters (scaling and bias) are generated by two dedicated shallow networks (ParamGen Nets) taking the fingerprint as input. A watermark decoder is trained simultaneously to extract the fingerprint from the generated images. The proposed method can embed different fingerprints inside the GAN by just changing the input of the ParamGen Nets and performing a feedforward pass, without finetuning or retraining. The performance of the proposed method in terms of robustness against both model-level and image-level attacks is also superior to the state-of-the-art.
Combining Shape Completion and Grasp Prediction for Fast and Versatile Grasping with a Multi-Fingered Hand
Oct 31, 2023Grasping objects with limited or no prior knowledge about them is a highly relevant skill in assistive robotics. Still, in this general setting, it has remained an open problem, especially when it comes to only partial observability and versatile grasping with multi-fingered hands. We present a novel, fast, and high fidelity deep learning pipeline consisting of a shape completion module that is based on a single depth image, and followed by a grasp predictor that is based on the predicted object shape. The shape completion network is based on VQDIF and predicts spatial occupancy values at arbitrary query points. As grasp predictor, we use our two-stage architecture that first generates hand poses using an autoregressive model and then regresses finger joint configurations per pose. Critical factors turn out to be sufficient data realism and augmentation, as well as special attention to difficult cases during training. Experiments on a physical robot platform demonstrate successful grasping of a wide range of household objects based on a depth image from a single viewpoint. The whole pipeline is fast, taking only about 1 s for completing the object's shape (0.7 s) and generating 1000 grasps (0.3 s).
VisPercep: A Vision-Language Approach to Enhance Visual Perception for People with Blindness and Low Vision
Oct 31, 2023People with blindness and low vision (pBLV) encounter substantial challenges when it comes to comprehensive scene recognition and precise object identification in unfamiliar environments. Additionally, due to the vision loss, pBLV have difficulty in accessing and identifying potential tripping hazards on their own. In this paper, we present a pioneering approach that leverages a large vision-language model to enhance visual perception for pBLV, offering detailed and comprehensive descriptions of the surrounding environments and providing warnings about the potential risks. Our method begins by leveraging a large image tagging model (i.e., Recognize Anything (RAM)) to identify all common objects present in the captured images. The recognition results and user query are then integrated into a prompt, tailored specifically for pBLV using prompt engineering. By combining the prompt and input image, a large vision-language model (i.e., InstructBLIP) generates detailed and comprehensive descriptions of the environment and identifies potential risks in the environment by analyzing the environmental objects and scenes, relevant to the prompt. We evaluate our approach through experiments conducted on both indoor and outdoor datasets. Our results demonstrate that our method is able to recognize objects accurately and provide insightful descriptions and analysis of the environment for pBLV.
Optimization of Rank Losses for Image Retrieval
Sep 15, 2023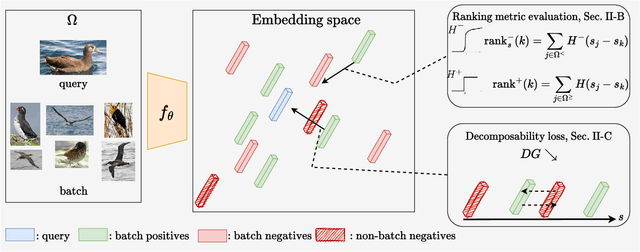
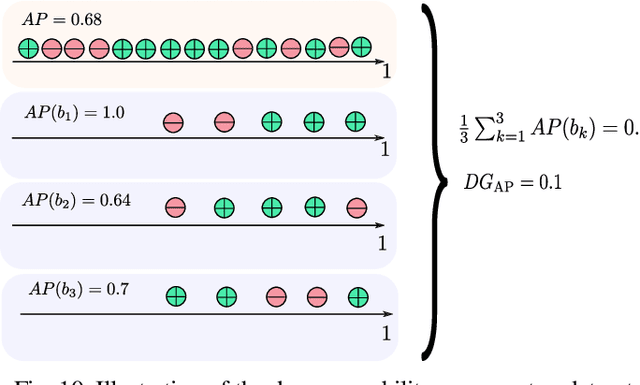
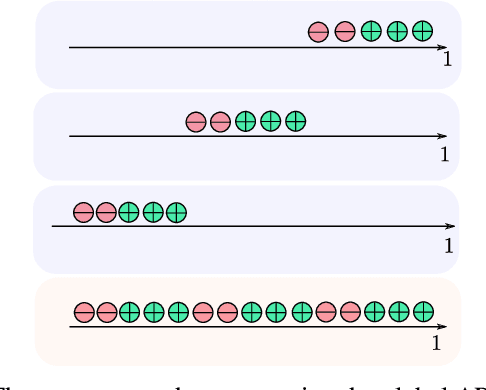
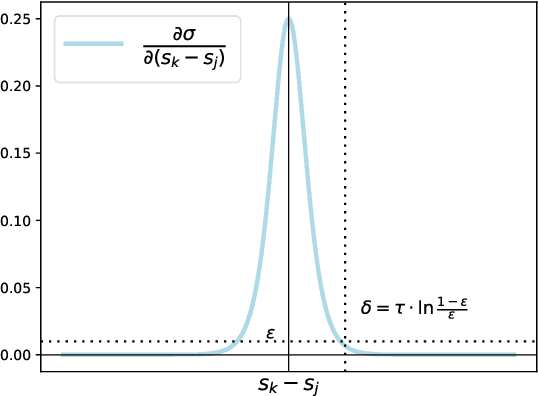
In image retrieval, standard evaluation metrics rely on score ranking, \eg average precision (AP), recall at k (R@k), normalized discounted cumulative gain (NDCG). In this work we introduce a general framework for robust and decomposable rank losses optimization. It addresses two major challenges for end-to-end training of deep neural networks with rank losses: non-differentiability and non-decomposability. Firstly we propose a general surrogate for ranking operator, SupRank, that is amenable to stochastic gradient descent. It provides an upperbound for rank losses and ensures robust training. Secondly, we use a simple yet effective loss function to reduce the decomposability gap between the averaged batch approximation of ranking losses and their values on the whole training set. We apply our framework to two standard metrics for image retrieval: AP and R@k. Additionally we apply our framework to hierarchical image retrieval. We introduce an extension of AP, the hierarchical average precision $\mathcal{H}$-AP, and optimize it as well as the NDCG. Finally we create the first hierarchical landmarks retrieval dataset. We use a semi-automatic pipeline to create hierarchical labels, extending the large scale Google Landmarks v2 dataset. The hierarchical dataset is publicly available at https://github.com/cvdfoundation/google-landmark. Code will be released at https://github.com/elias-ramzi/SupRank.
BigFUSE: Global Context-Aware Image Fusion in Dual-View Light-Sheet Fluorescence Microscopy with Image Formation Prior
Sep 05, 2023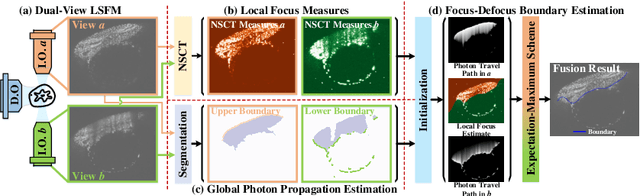
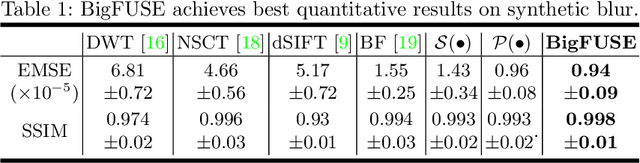


Light-sheet fluorescence microscopy (LSFM), a planar illumination technique that enables high-resolution imaging of samples, experiences defocused image quality caused by light scattering when photons propagate through thick tissues. To circumvent this issue, dualview imaging is helpful. It allows various sections of the specimen to be scanned ideally by viewing the sample from opposing orientations. Recent image fusion approaches can then be applied to determine in-focus pixels by comparing image qualities of two views locally and thus yield spatially inconsistent focus measures due to their limited field-of-view. Here, we propose BigFUSE, a global context-aware image fuser that stabilizes image fusion in LSFM by considering the global impact of photon propagation in the specimen while determining focus-defocus based on local image qualities. Inspired by the image formation prior in dual-view LSFM, image fusion is considered as estimating a focus-defocus boundary using Bayes Theorem, where (i) the effect of light scattering onto focus measures is included within Likelihood; and (ii) the spatial consistency regarding focus-defocus is imposed in Prior. The expectation-maximum algorithm is then adopted to estimate the focus-defocus boundary. Competitive experimental results show that BigFUSE is the first dual-view LSFM fuser that is able to exclude structured artifacts when fusing information, highlighting its abilities of automatic image fusion.
An Image Dataset for Benchmarking Recommender Systems with Raw Pixels
Sep 13, 2023

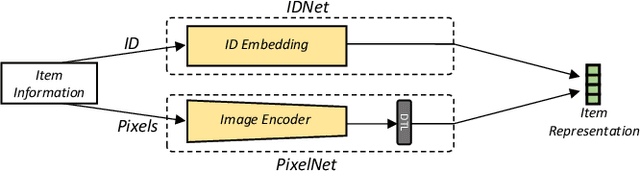
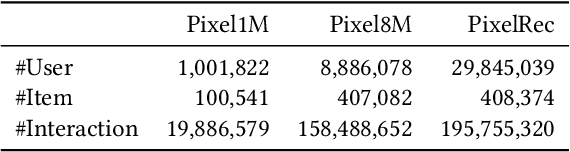
Recommender systems (RS) have achieved significant success by leveraging explicit identification (ID) features. However, the full potential of content features, especially the pure image pixel features, remains relatively unexplored. The limited availability of large, diverse, and content-driven image recommendation datasets has hindered the use of raw images as item representations. In this regard, we present PixelRec, a massive image-centric recommendation dataset that includes approximately 200 million user-image interactions, 30 million users, and 400,000 high-quality cover images. By providing direct access to raw image pixels, PixelRec enables recommendation models to learn item representation directly from them. To demonstrate its utility, we begin by presenting the results of several classical pure ID-based baseline models, termed IDNet, trained on PixelRec. Then, to show the effectiveness of the dataset's image features, we substitute the itemID embeddings (from IDNet) with a powerful vision encoder that represents items using their raw image pixels. This new model is dubbed PixelNet.Our findings indicate that even in standard, non-cold start recommendation settings where IDNet is recognized as highly effective, PixelNet can already perform equally well or even better than IDNet. Moreover, PixelNet has several other notable advantages over IDNet, such as being more effective in cold-start and cross-domain recommendation scenarios. These results underscore the importance of visual features in PixelRec. We believe that PixelRec can serve as a critical resource and testing ground for research on recommendation models that emphasize image pixel content. The dataset, code, and leaderboard will be available at https://github.com/website-pixelrec/PixelRec.