 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
PET Synthesis via Self-supervised Adaptive Residual Estimation Generative Adversarial Network
Oct 24, 2023
Positron emission tomography (PET) is a widely used, highly sensitive molecular imaging in clinical diagnosis. There is interest in reducing the radiation exposure from PET but also maintaining adequate image quality. Recent methods using convolutional neural networks (CNNs) to generate synthesized high-quality PET images from low-dose counterparts have been reported to be state-of-the-art for low-to-high image recovery methods. However, these methods are prone to exhibiting discrepancies in texture and structure between synthesized and real images. Furthermore, the distribution shift between low-dose PET and standard PET has not been fully investigated. To address these issues, we developed a self-supervised adaptive residual estimation generative adversarial network (SS-AEGAN). We introduce (1) An adaptive residual estimation mapping mechanism, AE-Net, designed to dynamically rectify the preliminary synthesized PET images by taking the residual map between the low-dose PET and synthesized output as the input, and (2) A self-supervised pre-training strategy to enhance the feature representation of the coarse generator. Our experiments with a public benchmark dataset of total-body PET images show that SS-AEGAN consistently outperformed the state-of-the-art synthesis methods with various dose reduction factors.
Learning Using Generated Privileged Information by Text-to-Image Diffusion Models
Sep 26, 2023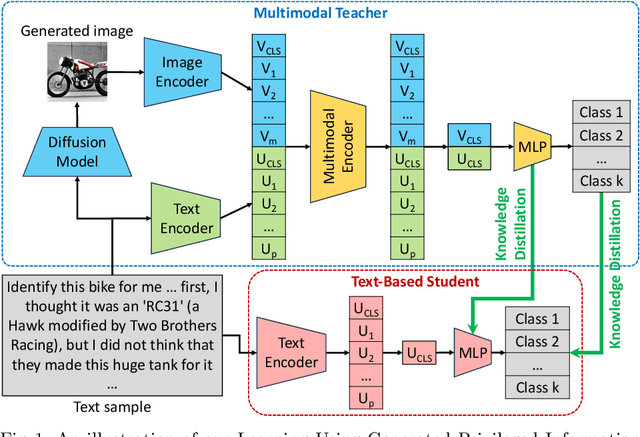
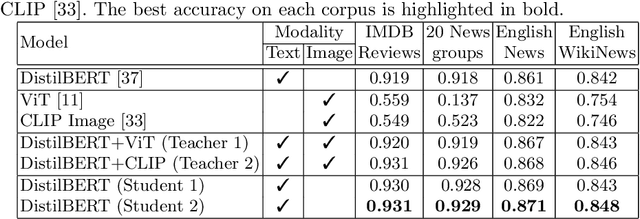

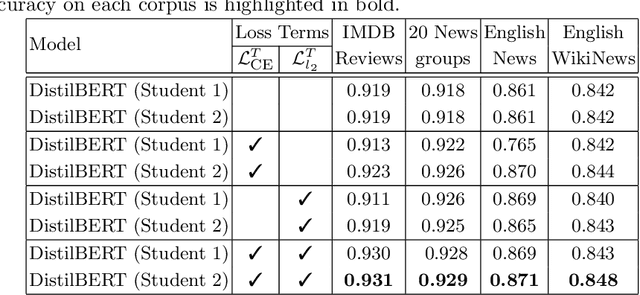
Learning Using Privileged Information is a particular type of knowledge distillation where the teacher model benefits from an additional data representation during training, called privileged information, improving the student model, which does not see the extra representation. However, privileged information is rarely available in practice. To this end, we propose a text classification framework that harnesses text-to-image diffusion models to generate artificial privileged information. The generated images and the original text samples are further used to train multimodal teacher models based on state-of-the-art transformer-based architectures. Finally, the knowledge from multimodal teachers is distilled into a text-based (unimodal) student. Hence, by employing a generative model to produce synthetic data as privileged information, we guide the training of the student model. Our framework, called Learning Using Generated Privileged Information (LUGPI), yields noticeable performance gains on four text classification data sets, demonstrating its potential in text classification without any additional cost during inference.
Navigating Text-To-Image Customization:From LyCORIS Fine-Tuning to Model Evaluation
Sep 26, 2023Text-to-image generative models have garnered immense attention for their ability to produce high-fidelity images from text prompts. Among these, Stable Diffusion distinguishes itself as a leading open-source model in this fast-growing field. However, the intricacies of fine-tuning these models pose multiple challenges from new methodology integration to systematic evaluation. Addressing these issues, this paper introduces LyCORIS (Lora beYond Conventional methods, Other Rank adaptation Implementations for Stable diffusion) [https://github.com/KohakuBlueleaf/LyCORIS], an open-source library that offers a wide selection of fine-tuning methodologies for Stable Diffusion. Furthermore, we present a thorough framework for the systematic assessment of varied fine-tuning techniques. This framework employs a diverse suite of metrics and delves into multiple facets of fine-tuning, including hyperparameter adjustments and the evaluation with different prompt types across various concept categories. Through this comprehensive approach, our work provides essential insights into the nuanced effects of fine-tuning parameters, bridging the gap between state-of-the-art research and practical application.
Adaptive Input-image Normalization for Solving Mode Collapse Problem in GAN-based X-ray Images
Sep 21, 2023Biomedical image datasets can be imbalanced due to the rarity of targeted diseases. Generative Adversarial Networks play a key role in addressing this imbalance by enabling the generation of synthetic images to augment datasets. It is important to generate synthetic images that incorporate a diverse range of features to accurately represent the distribution of features present in the training imagery. Furthermore, the absence of diverse features in synthetic images can degrade the performance of machine learning classifiers. The mode collapse problem impacts Generative Adversarial Networks' capacity to generate diversified images. Mode collapse comes in two varieties: intra-class and inter-class. In this paper, both varieties of the mode collapse problem are investigated, and their subsequent impact on the diversity of synthetic X-ray images is evaluated. This work contributes an empirical demonstration of the benefits of integrating the adaptive input-image normalization with the Deep Convolutional GAN and Auxiliary Classifier GAN to alleviate the mode collapse problems. Synthetically generated images are utilized for data augmentation and training a Vision Transformer model. The classification performance of the model is evaluated using accuracy, recall, and precision scores. Results demonstrate that the DCGAN and the ACGAN with adaptive input-image normalization outperform the DCGAN and ACGAN with un-normalized X-ray images as evidenced by the superior diversity scores and classification scores.
MAD: Modality Agnostic Distance Measure for Image Registration
Sep 06, 2023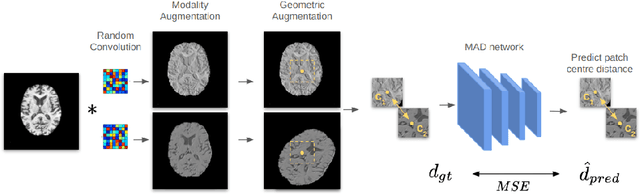
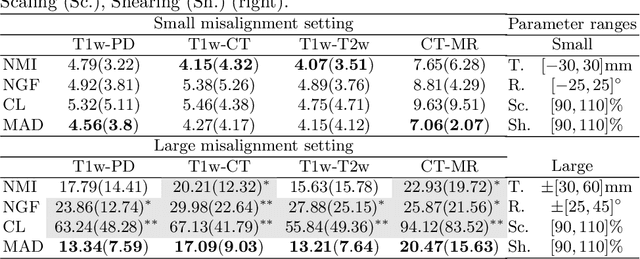
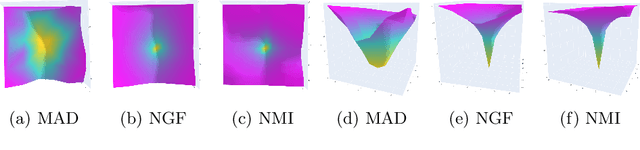

Multi-modal image registration is a crucial pre-processing step in many medical applications. However, it is a challenging task due to the complex intensity relationships between different imaging modalities, which can result in large discrepancy in image appearance. The success of multi-modal image registration, whether it is conventional or learning based, is predicated upon the choice of an appropriate distance (or similarity) measure. Particularly, deep learning registration algorithms lack in accuracy or even fail completely when attempting to register data from an "unseen" modality. In this work, we present Modality Agnostic Distance (MAD), a deep image distance}] measure that utilises random convolutions to learn the inherent geometry of the images while being robust to large appearance changes. Random convolutions are geometry-preserving modules which we use to simulate an infinite number of synthetic modalities alleviating the need for aligned paired data during training. We can therefore train MAD on a mono-modal dataset and successfully apply it to a multi-modal dataset. We demonstrate that not only can MAD affinely register multi-modal images successfully, but it has also a larger capture range than traditional measures such as Mutual Information and Normalised Gradient Fields.
Towards Increasing the Robustness of Predictive Steering-Control Autonomous Navigation Systems Against Dash Cam Image Angle Perturbations Due to Pothole Encounters
Oct 06, 2023

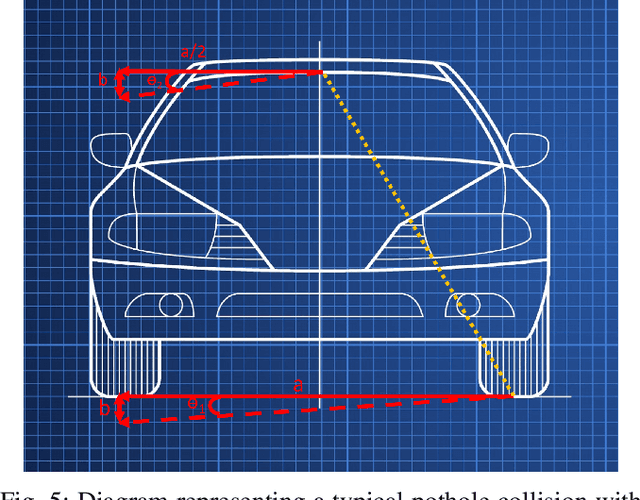
Vehicle manufacturers are racing to create autonomous navigation and steering control algorithms for their vehicles. These software are made to handle various real-life scenarios such as obstacle avoidance and lane maneuvering. There is some ongoing research to incorporate pothole avoidance into these autonomous systems. However, there is very little research on the effect of hitting a pothole on the autonomous navigation software that uses cameras to make driving decisions. Perturbations in the camera angle when hitting a pothole can cause errors in the predicted steering angle. In this paper, we present a new model to compensate for such angle perturbations and reduce any errors in steering control prediction algorithms. We evaluate our model on perturbations of publicly available datasets and show our model can reduce the errors in the estimated steering angle from perturbed images to 2.3%, making autonomous steering control robust against the dash cam image angle perturbations induced when one wheel of a car goes over a pothole.
Enhancing High-Resolution 3D Generation through Pixel-wise Gradient Clipping
Oct 19, 2023High-resolution 3D object generation remains a challenging task primarily due to the limited availability of comprehensive annotated training data. Recent advancements have aimed to overcome this constraint by harnessing image generative models, pretrained on extensive curated web datasets, using knowledge transfer techniques like Score Distillation Sampling (SDS). Efficiently addressing the requirements of high-resolution rendering often necessitates the adoption of latent representation-based models, such as the Latent Diffusion Model (LDM). In this framework, a significant challenge arises: To compute gradients for individual image pixels, it is necessary to backpropagate gradients from the designated latent space through the frozen components of the image model, such as the VAE encoder used within LDM. However, this gradient propagation pathway has never been optimized, remaining uncontrolled during training. We find that the unregulated gradients adversely affect the 3D model's capacity in acquiring texture-related information from the image generative model, leading to poor quality appearance synthesis. To address this overarching challenge, we propose an innovative operation termed Pixel-wise Gradient Clipping (PGC) designed for seamless integration into existing 3D generative models, thereby enhancing their synthesis quality. Specifically, we control the magnitude of stochastic gradients by clipping the pixel-wise gradients efficiently, while preserving crucial texture-related gradient directions. Despite this simplicity and minimal extra cost, extensive experiments demonstrate the efficacy of our PGC in enhancing the performance of existing 3D generative models for high-resolution object rendering.
Towards Generic Semi-Supervised Framework for Volumetric Medical Image Segmentation
Oct 17, 2023Volume-wise labeling in 3D medical images is a time-consuming task that requires expertise. As a result, there is growing interest in using semi-supervised learning (SSL) techniques to train models with limited labeled data. However, the challenges and practical applications extend beyond SSL to settings such as unsupervised domain adaptation (UDA) and semi-supervised domain generalization (SemiDG). This work aims to develop a generic SSL framework that can handle all three settings. We identify two main obstacles to achieving this goal in the existing SSL framework: 1) the weakness of capturing distribution-invariant features; and 2) the tendency for unlabeled data to be overwhelmed by labeled data, leading to over-fitting to the labeled data during training. To address these issues, we propose an Aggregating & Decoupling framework. The aggregating part consists of a Diffusion encoder that constructs a common knowledge set by extracting distribution-invariant features from aggregated information from multiple distributions/domains. The decoupling part consists of three decoders that decouple the training process with labeled and unlabeled data, thus avoiding over-fitting to labeled data, specific domains and classes. We evaluate our proposed framework on four benchmark datasets for SSL, Class-imbalanced SSL, UDA and SemiDG. The results showcase notable improvements compared to state-of-the-art methods across all four settings, indicating the potential of our framework to tackle more challenging SSL scenarios. Code and models are available at: https://github.com/xmed-lab/GenericSSL.
Handwritten image augmentation
Aug 26, 2023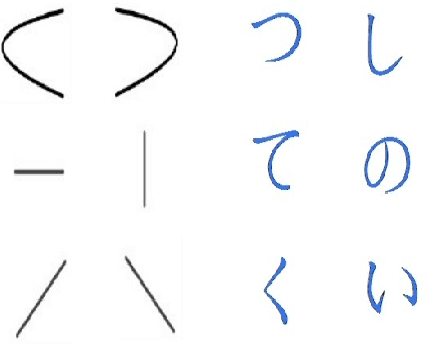
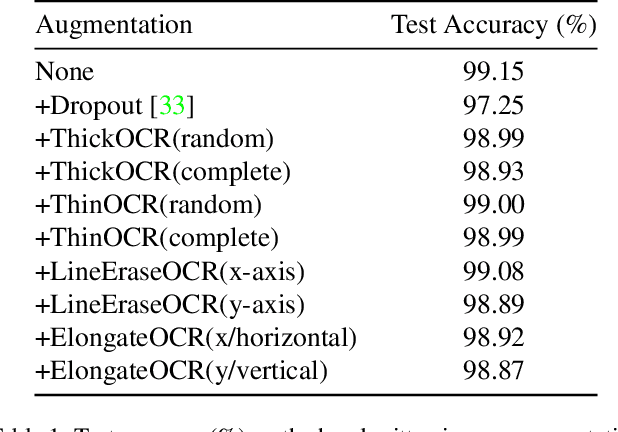
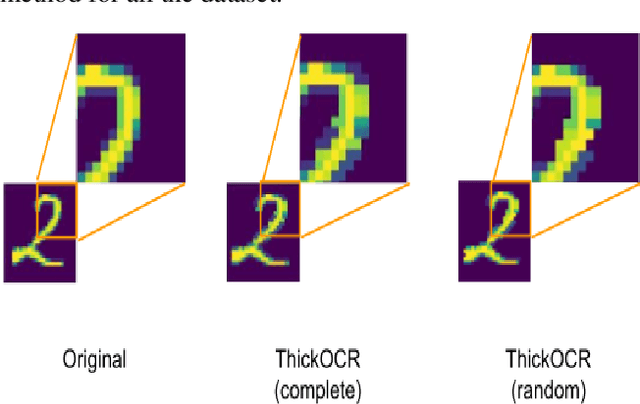
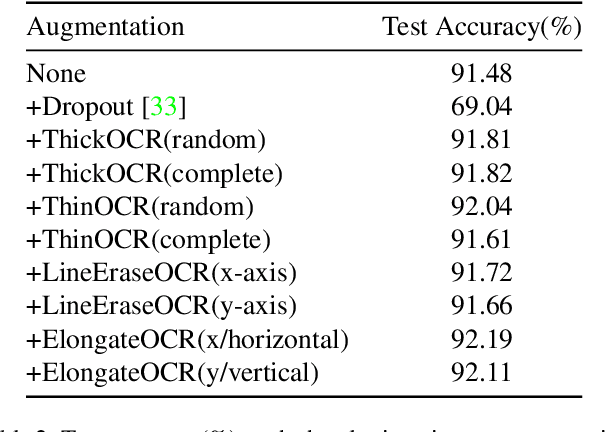
In this paper, we introduce Handwritten augmentation, a new data augmentation for handwritten character images. This method focuses on augmenting handwritten image data by altering the shape of input characters in training. The proposed handwritten augmentation is similar to position augmentation, color augmentation for images but a deeper focus on handwritten characters. Handwritten augmentation is data-driven, easy to implement, and can be integrated with CNN-based optical character recognition models. Handwritten augmentation can be implemented along with commonly used data augmentation techniques such as cropping, rotating, and yields better performance of models for handwritten image datasets developed using optical character recognition methods.
A Portable Ultrasound Imaging Pipeline Implementation with GPU Acceleration on Nvidia CLARA AGX
Oct 31, 2023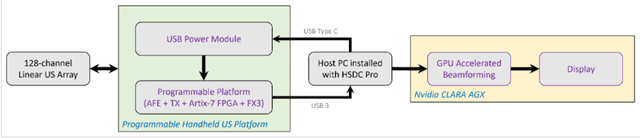
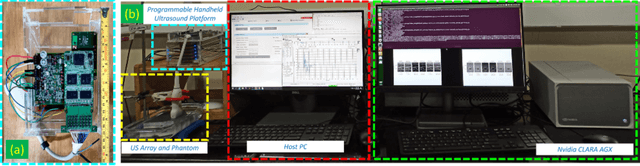
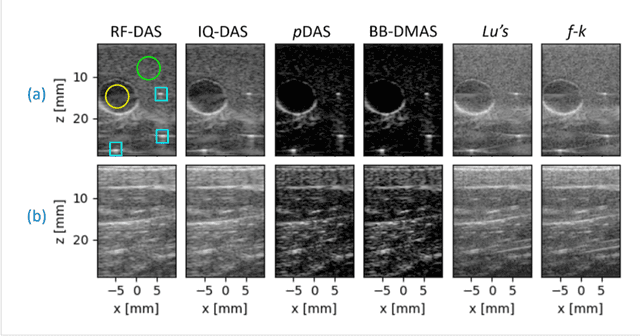
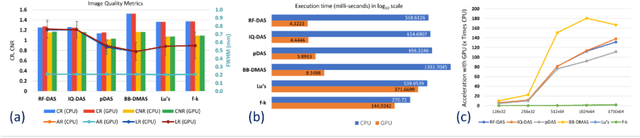
In this paper, we present a GPU-accelerated prototype implementation of a portable ultrasound imaging pipeline on an Nvidia CLARA AGX development kit. The raw data is acquired with nonsteered plane wave transmit using a programmable handheld open platform that supports 128-channel transmit and 64-channel receive. The received signals are transferred to the Nvidia CLARA AGX developer platform through a host system for accelerated imaging. GPU-accelerated implementation of the conventional delay and sum (DAS) beamformer along with two adaptive nonlinear beamformers and two Fourier-based techniques was performed. The feasibility of the complete pipeline and its imaging performance was evaluated with in-vitro phantom imaging experiments and the efficacy is demonstrated with preliminary in-vivo scans. The image quality quantified by the standard contrast and resolution metrics was comparable with that of the CPU implementation. The execution speed of the implemented beamformers was also investigated for different sizes of imaging grids and a significant speedup as high as 180 times that of the CPU implementation was observed. Since the proposed pipeline involves Nvidia CLARA AGX, there is always the potential for easy incorporation of online/active learning approaches.