 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Apollo: Zero-shot MultiModal Reasoning with Multiple Experts
Oct 25, 2023
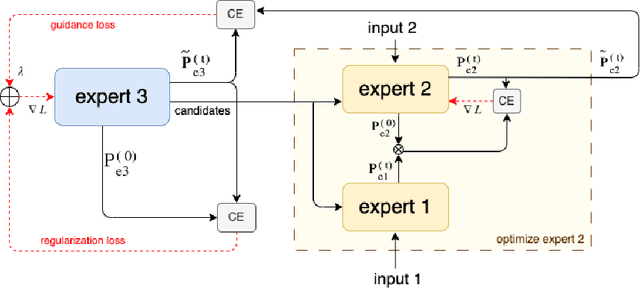
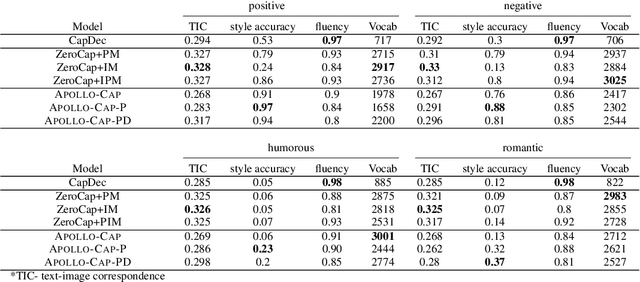


We propose a modular framework that leverages the expertise of different foundation models over different modalities and domains in order to perform a single, complex, multi-modal task, without relying on prompt engineering or otherwise tailor-made multi-modal training. Our approach enables decentralized command execution and allows each model to both contribute and benefit from the expertise of the other models. Our method can be extended to a variety of foundation models (including audio and vision), above and beyond only language models, as it does not depend on prompts. We demonstrate our approach on two tasks. On the well-known task of stylized image captioning, our experiments show that our approach outperforms semi-supervised state-of-the-art models, while being zero-shot and avoiding costly training, data collection, and prompt engineering. We further demonstrate this method on a novel task, audio-aware image captioning, in which an image and audio are given and the task is to generate text that describes the image within the context of the provided audio. Our code is available on GitHub.
CoFiI2P: Coarse-to-Fine Correspondences for Image-to-Point Cloud Registration
Sep 26, 2023Image-to-point cloud (I2P) registration is a fundamental task in the fields of robot navigation and mobile mapping. Existing I2P registration works estimate correspondences at the point-to-pixel level, neglecting the global alignment. However, I2P matching without high-level guidance from global constraints may converge to the local optimum easily. To solve the problem, this paper proposes CoFiI2P, a novel I2P registration network that extracts correspondences in a coarse-to-fine manner for the global optimal solution. First, the image and point cloud are fed into a Siamese encoder-decoder network for hierarchical feature extraction. Then, a coarse-to-fine matching module is designed to exploit features and establish resilient feature correspondences. Specifically, in the coarse matching block, a novel I2P transformer module is employed to capture the homogeneous and heterogeneous global information from image and point cloud. With the discriminate descriptors, coarse super-point-to-super-pixel matching pairs are estimated. In the fine matching module, point-to-pixel pairs are established with the super-point-to-super-pixel correspondence supervision. Finally, based on matching pairs, the transform matrix is estimated with the EPnP-RANSAC algorithm. Extensive experiments conducted on the KITTI dataset have demonstrated that CoFiI2P achieves a relative rotation error (RRE) of 2.25 degrees and a relative translation error (RTE) of 0.61 meters. These results represent a significant improvement of 14% in RRE and 52% in RTE compared to the current state-of-the-art (SOTA) method. The demo video for the experiments is available at https://youtu.be/TG2GBrJTuW4. The source code will be public at https://github.com/kang-1-2-3/CoFiI2P.
Joint Correcting and Refinement for Balanced Low-Light Image Enhancement
Sep 28, 2023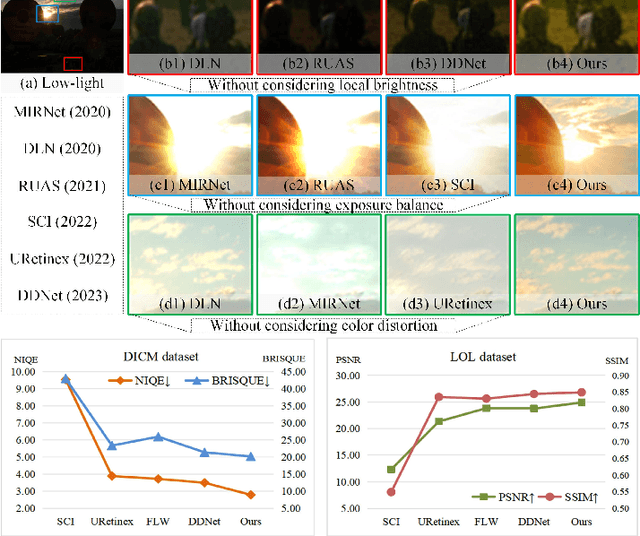

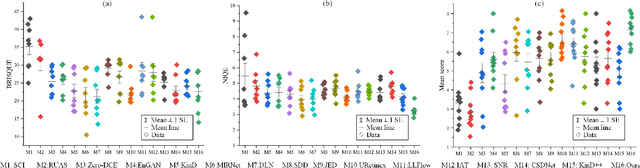

Low-light image enhancement tasks demand an appropriate balance among brightness, color, and illumination. While existing methods often focus on one aspect of the image without considering how to pay attention to this balance, which will cause problems of color distortion and overexposure etc. This seriously affects both human visual perception and the performance of high-level visual models. In this work, a novel synergistic structure is proposed which can balance brightness, color, and illumination more effectively. Specifically, the proposed method, so-called Joint Correcting and Refinement Network (JCRNet), which mainly consists of three stages to balance brightness, color, and illumination of enhancement. Stage 1: we utilize a basic encoder-decoder and local supervision mechanism to extract local information and more comprehensive details for enhancement. Stage 2: cross-stage feature transmission and spatial feature transformation further facilitate color correction and feature refinement. Stage 3: we employ a dynamic illumination adjustment approach to embed residuals between predicted and ground truth images into the model, adaptively adjusting illumination balance. Extensive experiments demonstrate that the proposed method exhibits comprehensive performance advantages over 21 state-of-the-art methods on 9 benchmark datasets. Furthermore, a more persuasive experiment has been conducted to validate our approach the effectiveness in downstream visual tasks (e.g., saliency detection). Compared to several enhancement models, the proposed method effectively improves the segmentation results and quantitative metrics of saliency detection. The source code will be available at https://github.com/woshiyll/JCRNet.
Prompt-Enhanced Self-supervised Representation Learning for Remote Sensing Image Understanding
Sep 28, 2023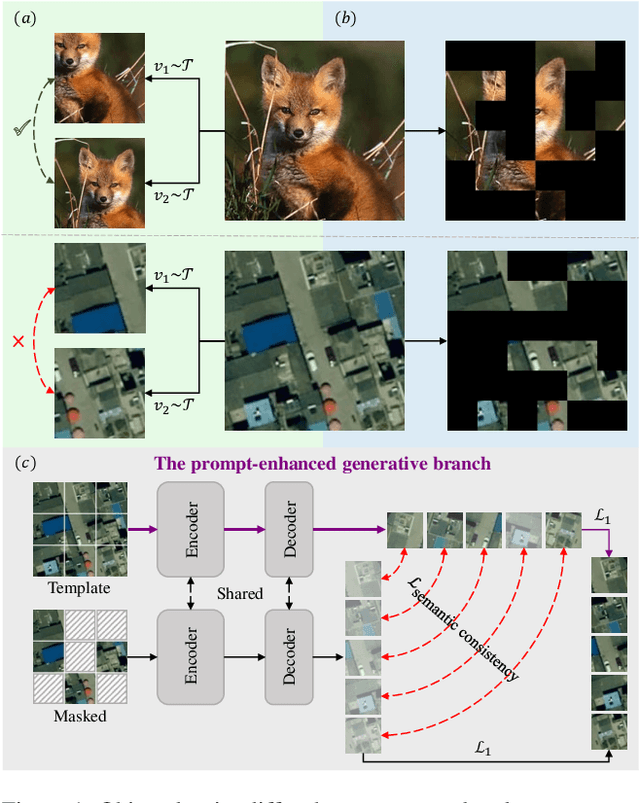
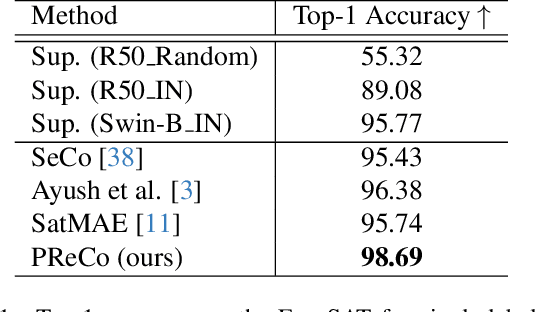
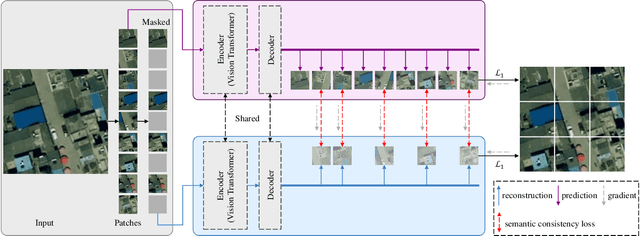
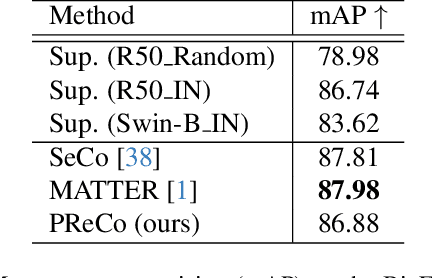
Learning representations through self-supervision on a large-scale, unlabeled dataset has proven to be highly effective for understanding diverse images, such as those used in remote sensing image analysis. However, remote sensing images often have complex and densely populated scenes, with multiple land objects and no clear foreground objects. This intrinsic property can lead to false positive pairs in contrastive learning, or missing contextual information in reconstructive learning, which can limit the effectiveness of existing self-supervised learning methods. To address these problems, we propose a prompt-enhanced self-supervised representation learning method that uses a simple yet efficient pre-training pipeline. Our approach involves utilizing original image patches as a reconstructive prompt template, and designing a prompt-enhanced generative branch that provides contextual information through semantic consistency constraints. We collected a dataset of over 1.28 million remote sensing images that is comparable to the popular ImageNet dataset, but without specific temporal or geographical constraints. Our experiments show that our method outperforms fully supervised learning models and state-of-the-art self-supervised learning methods on various downstream tasks, including land cover classification, semantic segmentation, object detection, and instance segmentation. These results demonstrate that our approach learns impressive remote sensing representations with high generalization and transferability.
TransReg: Cross-transformer as auto-registration module for multi-view mammogram mass detection
Nov 09, 2023Screening mammography is the most widely used method for early breast cancer detection, significantly reducing mortality rates. The integration of information from multi-view mammograms enhances radiologists' confidence and diminishes false-positive rates since they can examine on dual-view of the same breast to cross-reference the existence and location of the lesion. Inspired by this, we present TransReg, a Computer-Aided Detection (CAD) system designed to exploit the relationship between craniocaudal (CC), and mediolateral oblique (MLO) views. The system includes cross-transformer to model the relationship between the region of interest (RoIs) extracted by siamese Faster RCNN network for mass detection problems. Our work is the first time cross-transformer has been integrated into an object detection framework to model the relation between ipsilateral views. Our experimental evaluation on DDSM and VinDr-Mammo datasets shows that our TransReg, equipped with SwinT as a feature extractor achieves state-of-the-art performance. Specifically, at the false positive rate per image at 0.5, TransReg using SwinT gets a recall at 83.3% for DDSM dataset and 79.7% for VinDr-Mammo dataset. Furthermore, we conduct a comprehensive analysis to demonstrate that cross-transformer can function as an auto-registration module, aligning the masses in dual-view and utilizing this information to inform final predictions. It is a replication diagnostic workflow of expert radiologists
Chain of Images for Intuitively Reasoning
Nov 09, 2023The human brain is naturally equipped to comprehend and interpret visual information rapidly. When confronted with complex problems or concepts, we use flowcharts, sketches, and diagrams to aid our thought process. Leveraging this inherent ability can significantly enhance logical reasoning. However, current Large Language Models (LLMs) do not utilize such visual intuition to help their thinking. Even the most advanced version language models (e.g., GPT-4V and LLaVA) merely align images into textual space, which means their reasoning processes remain purely verbal. To mitigate such limitations, we present a Chain of Images (CoI) approach, which can convert complex language reasoning problems to simple pattern recognition by generating a series of images as intermediate representations. Furthermore, we have developed a CoI evaluation dataset encompassing 15 distinct domains where images can intuitively aid problem-solving. Based on this dataset, we aim to construct a benchmark to assess the capability of future multimodal large-scale models to leverage images for reasoning. In supporting our CoI reasoning, we introduce a symbolic multimodal large language model (SyMLLM) that generates images strictly based on language instructions and accepts both text and image as input. Experiments on Geometry, Chess and Common Sense tasks sourced from the CoI evaluation dataset show that CoI improves performance significantly over the pure-language Chain of Thoughts (CoT) baselines. The code is available at https://github.com/GraphPKU/CoI.
Deep learning-based image super-resolution of a novel end-expandable optical fiber probe for application in esophageal cancer diagnostics
Oct 03, 2023
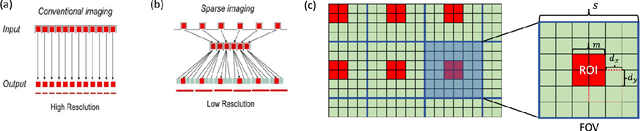
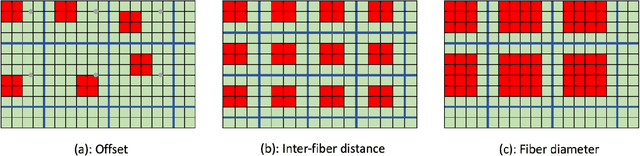

Significance: Endoscopic screening for esophageal cancer may enable early cancer diagnosis and treatment. While optical microendoscopic technology has shown promise in improving specificity, the limited field of view (<1 mm) significantly reduces the ability to survey large areas efficiently in esophageal cancer screening. Aim: To improve the efficiency of endoscopic screening, we proposed a novel end-expandable endoscopic optical fiber probe for larger field of visualization and employed a deep learning-based image super-resolution (DL-SR) method to overcome the issue of limited sampling capability. Approach: To demonstrate feasibility of the end-expandable optical fiber probe, DL-SR was applied on simulated low-resolution (LR) microendoscopic images to generate super-resolved (SR) ones. Varying the degradation model of image data acquisition, we identified the optimal parameters for optical fiber probe prototyping. The proposed screening method was validated with a human pathology reading study. Results: For various degradation parameters considered, the DL-SR method demonstrated different levels of improvement of traditional measures of image quality. The endoscopist interpretations of the SR images were comparable to those performed on the high-resolution ones. Conclusions: This work suggests avenues for development of DL-SR-enabled end-expandable optical fiber probes to improve high-yield esophageal cancer screening.
Tree-GPT: Modular Large Language Model Expert System for Forest Remote Sensing Image Understanding and Interactive Analysis
Oct 07, 2023This paper introduces a novel framework, Tree-GPT, which incorporates Large Language Models (LLMs) into the forestry remote sensing data workflow, thereby enhancing the efficiency of data analysis. Currently, LLMs are unable to extract or comprehend information from images and may generate inaccurate text due to a lack of domain knowledge, limiting their use in forestry data analysis. To address this issue, we propose a modular LLM expert system, Tree-GPT, that integrates image understanding modules, domain knowledge bases, and toolchains. This empowers LLMs with the ability to comprehend images, acquire accurate knowledge, generate code, and perform data analysis in a local environment. Specifically, the image understanding module extracts structured information from forest remote sensing images by utilizing automatic or interactive generation of prompts to guide the Segment Anything Model (SAM) in generating and selecting optimal tree segmentation results. The system then calculates tree structural parameters based on these results and stores them in a database. Upon receiving a specific natural language instruction, the LLM generates code based on a thought chain to accomplish the analysis task. The code is then executed by an LLM agent in a local environment and . For ecological parameter calculations, the system retrieves the corresponding knowledge from the knowledge base and inputs it into the LLM to guide the generation of accurate code. We tested this system on several tasks, including Search, Visualization, and Machine Learning Analysis. The prototype system performed well, demonstrating the potential for dynamic usage of LLMs in forestry research and environmental sciences.
AnomalyCLIP: Object-agnostic Prompt Learning for Zero-shot Anomaly Detection
Nov 03, 2023
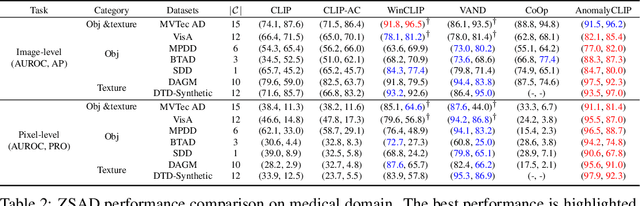
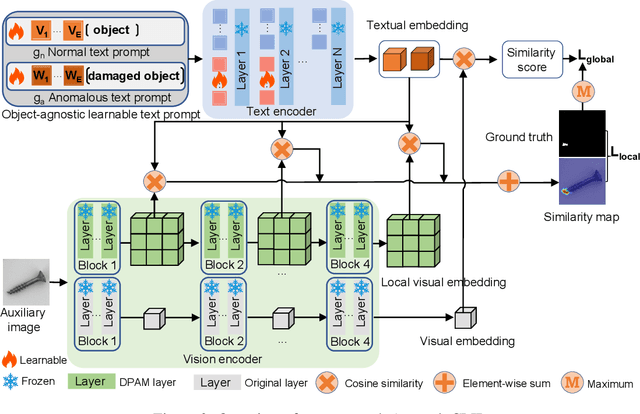
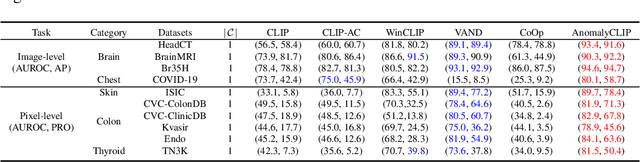
Zero-shot anomaly detection (ZSAD) requires detection models trained using auxiliary data to detect anomalies without any training sample in a target dataset. It is a crucial task when training data is not accessible due to various concerns, \eg, data privacy, yet it is challenging since the models need to generalize to anomalies across different domains where the appearance of foreground objects, abnormal regions, and background features, such as defects/tumors on different products/organs, can vary significantly. Recently large pre-trained vision-language models (VLMs), such as CLIP, have demonstrated strong zero-shot recognition ability in various vision tasks, including anomaly detection. However, their ZSAD performance is weak since the VLMs focus more on modeling the class semantics of the foreground objects rather than the abnormality/normality in the images. In this paper we introduce a novel approach, namely AnomalyCLIP, to adapt CLIP for accurate ZSAD across different domains. The key insight of AnomalyCLIP is to learn object-agnostic text prompts that capture generic normality and abnormality in an image regardless of its foreground objects. This allows our model to focus on the abnormal image regions rather than the object semantics, enabling generalized normality and abnormality recognition on diverse types of objects. Large-scale experiments on 17 real-world anomaly detection datasets show that AnomalyCLIP achieves superior zero-shot performance of detecting and segmenting anomalies in datasets of highly diverse class semantics from various defect inspection and medical imaging domains. Code will be made available at https://github.com/zqhang/AnomalyCLIP.
Multi-View Causal Representation Learning with Partial Observability
Nov 07, 2023We present a unified framework for studying the identifiability of representations learned from simultaneously observed views, such as different data modalities. We allow a partially observed setting in which each view constitutes a nonlinear mixture of a subset of underlying latent variables, which can be causally related. We prove that the information shared across all subsets of any number of views can be learned up to a smooth bijection using contrastive learning and a single encoder per view. We also provide graphical criteria indicating which latent variables can be identified through a simple set of rules, which we refer to as identifiability algebra. Our general framework and theoretical results unify and extend several previous works on multi-view nonlinear ICA, disentanglement, and causal representation learning. We experimentally validate our claims on numerical, image, and multi-modal data sets. Further, we demonstrate that the performance of prior methods is recovered in different special cases of our setup. Overall, we find that access to multiple partial views enables us to identify a more fine-grained representation, under the generally milder assumption of partial observability.