 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
fMRI-PTE: A Large-scale fMRI Pretrained Transformer Encoder for Multi-Subject Brain Activity Decoding
Nov 01, 2023
The exploration of brain activity and its decoding from fMRI data has been a longstanding pursuit, driven by its potential applications in brain-computer interfaces, medical diagnostics, and virtual reality. Previous approaches have primarily focused on individual subject analysis, highlighting the need for a more universal and adaptable framework, which is the core motivation behind our work. In this work, we propose fMRI-PTE, an innovative auto-encoder approach for fMRI pre-training, with a focus on addressing the challenges of varying fMRI data dimensions due to individual brain differences. Our approach involves transforming fMRI signals into unified 2D representations, ensuring consistency in dimensions and preserving distinct brain activity patterns. We introduce a novel learning strategy tailored for pre-training 2D fMRI images, enhancing the quality of reconstruction. fMRI-PTE's adaptability with image generators enables the generation of well-represented fMRI features, facilitating various downstream tasks, including within-subject and cross-subject brain activity decoding. Our contributions encompass introducing fMRI-PTE, innovative data transformation, efficient training, a novel learning strategy, and the universal applicability of our approach. Extensive experiments validate and support our claims, offering a promising foundation for further research in this domain.
Dual Conditioned Diffusion Models for Out-Of-Distribution Detection: Application to Fetal Ultrasound Videos
Nov 01, 2023Out-of-distribution (OOD) detection is essential to improve the reliability of machine learning models by detecting samples that do not belong to the training distribution. Detecting OOD samples effectively in certain tasks can pose a challenge because of the substantial heterogeneity within the in-distribution (ID), and the high structural similarity between ID and OOD classes. For instance, when detecting heart views in fetal ultrasound videos there is a high structural similarity between the heart and other anatomies such as the abdomen, and large in-distribution variance as a heart has 5 distinct views and structural variations within each view. To detect OOD samples in this context, the resulting model should generalise to the intra-anatomy variations while rejecting similar OOD samples. In this paper, we introduce dual-conditioned diffusion models (DCDM) where we condition the model on in-distribution class information and latent features of the input image for reconstruction-based OOD detection. This constrains the generative manifold of the model to generate images structurally and semantically similar to those within the in-distribution. The proposed model outperforms reference methods with a 12% improvement in accuracy, 22% higher precision, and an 8% better F1 score.
Deep learning in medical image registration: introduction and survey
Sep 01, 2023

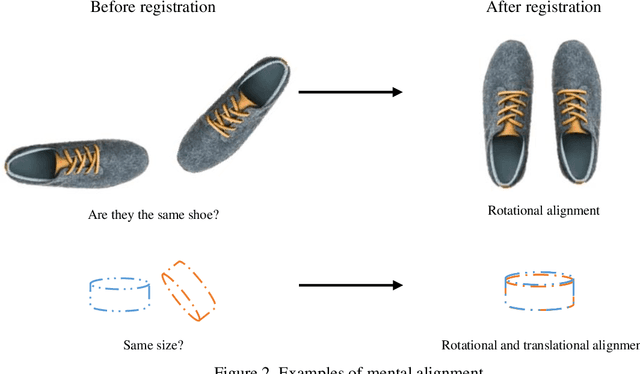
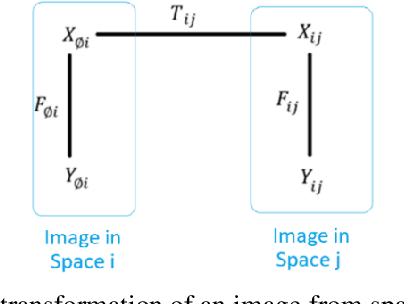
Image registration (IR) is a process that deforms images to align them with respect to a reference space, making it easier for medical practitioners to examine various medical images in a standardized reference frame, such as having the same rotation and scale. This document introduces image registration using a simple numeric example. It provides a definition of image registration along with a space-oriented symbolic representation. This review covers various aspects of image transformations, including affine, deformable, invertible, and bidirectional transformations, as well as medical image registration algorithms such as Voxelmorph, Demons, SyN, Iterative Closest Point, and SynthMorph. It also explores atlas-based registration and multistage image registration techniques, including coarse-fine and pyramid approaches. Furthermore, this survey paper discusses medical image registration taxonomies, datasets, evaluation measures, such as correlation-based metrics, segmentation-based metrics, processing time, and model size. It also explores applications in image-guided surgery, motion tracking, and tumor diagnosis. Finally, the document addresses future research directions, including the further development of transformers.
Adaptive Input-image Normalization for Solving Mode Collapse Problem in GAN-based X-ray Images
Sep 21, 2023Biomedical image datasets can be imbalanced due to the rarity of targeted diseases. Generative Adversarial Networks play a key role in addressing this imbalance by enabling the generation of synthetic images to augment datasets. It is important to generate synthetic images that incorporate a diverse range of features to accurately represent the distribution of features present in the training imagery. Furthermore, the absence of diverse features in synthetic images can degrade the performance of machine learning classifiers. The mode collapse problem impacts Generative Adversarial Networks' capacity to generate diversified images. Mode collapse comes in two varieties: intra-class and inter-class. In this paper, both varieties of the mode collapse problem are investigated, and their subsequent impact on the diversity of synthetic X-ray images is evaluated. This work contributes an empirical demonstration of the benefits of integrating the adaptive input-image normalization with the Deep Convolutional GAN and Auxiliary Classifier GAN to alleviate the mode collapse problems. Synthetically generated images are utilized for data augmentation and training a Vision Transformer model. The classification performance of the model is evaluated using accuracy, recall, and precision scores. Results demonstrate that the DCGAN and the ACGAN with adaptive input-image normalization outperform the DCGAN and ACGAN with un-normalized X-ray images as evidenced by the superior diversity scores and classification scores.
LinFlo-Net: A two-stage deep learning method to generate simulation ready meshes of the heart
Oct 30, 2023We present a deep learning model to automatically generate computer models of the human heart from patient imaging data with an emphasis on its capability to generate thin-walled cardiac structures. Our method works by deforming a template mesh to fit the cardiac structures to the given image. Compared with prior deep learning methods that adopted this approach, our framework is designed to minimize mesh self-penetration, which typically arises when deforming surface meshes separated by small distances. We achieve this by using a two-stage diffeomorphic deformation process along with a novel loss function derived from the kinematics of motion that penalizes surface contact and interpenetration. Our model demonstrates comparable accuracy with state-of-the-art methods while additionally producing meshes free of self-intersections. The resultant meshes are readily usable in physics based simulation, minimizing the need for post-processing and cleanup.
Image-level supervision and self-training for transformer-based cross-modality tumor segmentation
Sep 17, 2023Deep neural networks are commonly used for automated medical image segmentation, but models will frequently struggle to generalize well across different imaging modalities. This issue is particularly problematic due to the limited availability of annotated data, making it difficult to deploy these models on a larger scale. To overcome these challenges, we propose a new semi-supervised training strategy called MoDATTS. Our approach is designed for accurate cross-modality 3D tumor segmentation on unpaired bi-modal datasets. An image-to-image translation strategy between imaging modalities is used to produce annotated pseudo-target volumes and improve generalization to the unannotated target modality. We also use powerful vision transformer architectures and introduce an iterative self-training procedure to further close the domain gap between modalities. MoDATTS additionally allows the possibility to extend the training to unannotated target data by exploiting image-level labels with an unsupervised objective that encourages the model to perform 3D diseased-to-healthy translation by disentangling tumors from the background. The proposed model achieves superior performance compared to other methods from participating teams in the CrossMoDA 2022 challenge, as evidenced by its reported top Dice score of 0.87+/-0.04 for the VS segmentation. MoDATTS also yields consistent improvements in Dice scores over baselines on a cross-modality brain tumor segmentation task composed of four different contrasts from the BraTS 2020 challenge dataset, where 95% of a target supervised model performance is reached. We report that 99% and 100% of this maximum performance can be attained if 20% and 50% of the target data is additionally annotated, which further demonstrates that MoDATTS can be leveraged to reduce the annotation burden.
Learning Using Generated Privileged Information by Text-to-Image Diffusion Models
Sep 26, 2023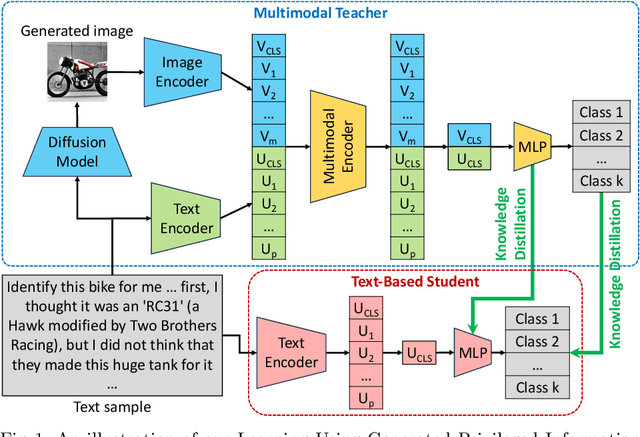
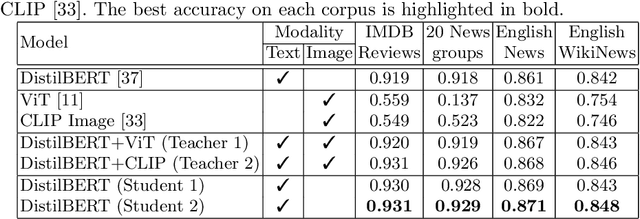

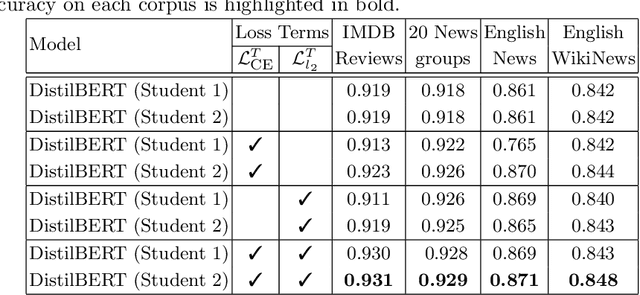
Learning Using Privileged Information is a particular type of knowledge distillation where the teacher model benefits from an additional data representation during training, called privileged information, improving the student model, which does not see the extra representation. However, privileged information is rarely available in practice. To this end, we propose a text classification framework that harnesses text-to-image diffusion models to generate artificial privileged information. The generated images and the original text samples are further used to train multimodal teacher models based on state-of-the-art transformer-based architectures. Finally, the knowledge from multimodal teachers is distilled into a text-based (unimodal) student. Hence, by employing a generative model to produce synthetic data as privileged information, we guide the training of the student model. Our framework, called Learning Using Generated Privileged Information (LUGPI), yields noticeable performance gains on four text classification data sets, demonstrating its potential in text classification without any additional cost during inference.
Navigating Text-To-Image Customization:From LyCORIS Fine-Tuning to Model Evaluation
Sep 26, 2023Text-to-image generative models have garnered immense attention for their ability to produce high-fidelity images from text prompts. Among these, Stable Diffusion distinguishes itself as a leading open-source model in this fast-growing field. However, the intricacies of fine-tuning these models pose multiple challenges from new methodology integration to systematic evaluation. Addressing these issues, this paper introduces LyCORIS (Lora beYond Conventional methods, Other Rank adaptation Implementations for Stable diffusion) [https://github.com/KohakuBlueleaf/LyCORIS], an open-source library that offers a wide selection of fine-tuning methodologies for Stable Diffusion. Furthermore, we present a thorough framework for the systematic assessment of varied fine-tuning techniques. This framework employs a diverse suite of metrics and delves into multiple facets of fine-tuning, including hyperparameter adjustments and the evaluation with different prompt types across various concept categories. Through this comprehensive approach, our work provides essential insights into the nuanced effects of fine-tuning parameters, bridging the gap between state-of-the-art research and practical application.
SADIR: Shape-Aware Diffusion Models for 3D Image Reconstruction
Sep 06, 20233D image reconstruction from a limited number of 2D images has been a long-standing challenge in computer vision and image analysis. While deep learning-based approaches have achieved impressive performance in this area, existing deep networks often fail to effectively utilize the shape structures of objects presented in images. As a result, the topology of reconstructed objects may not be well preserved, leading to the presence of artifacts such as discontinuities, holes, or mismatched connections between different parts. In this paper, we propose a shape-aware network based on diffusion models for 3D image reconstruction, named SADIR, to address these issues. In contrast to previous methods that primarily rely on spatial correlations of image intensities for 3D reconstruction, our model leverages shape priors learned from the training data to guide the reconstruction process. To achieve this, we develop a joint learning network that simultaneously learns a mean shape under deformation models. Each reconstructed image is then considered as a deformed variant of the mean shape. We validate our model, SADIR, on both brain and cardiac magnetic resonance images (MRIs). Experimental results show that our method outperforms the baselines with lower reconstruction error and better preservation of the shape structure of objects within the images.
PERF: Panoramic Neural Radiance Field from a Single Panorama
Oct 28, 2023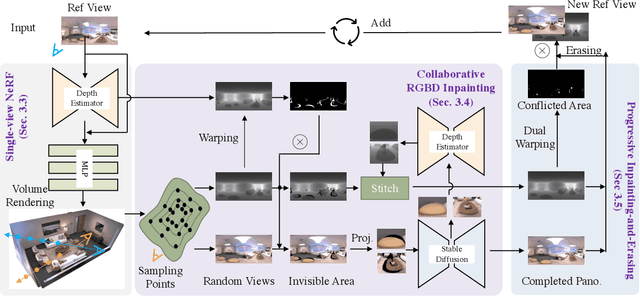
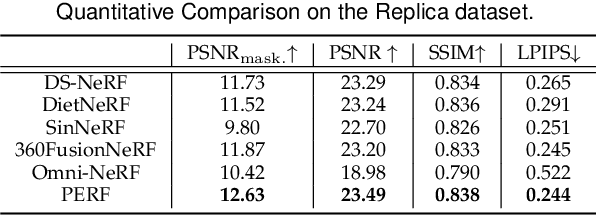
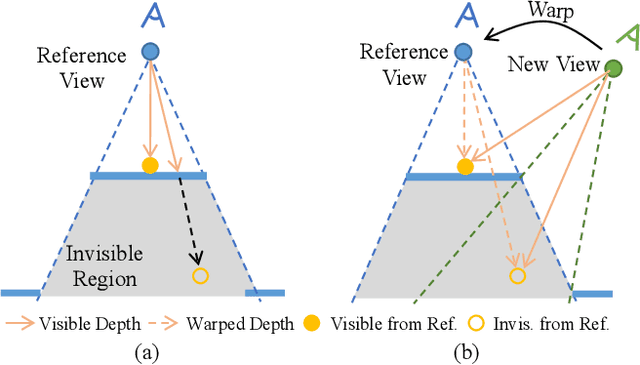

Neural Radiance Field (NeRF) has achieved substantial progress in novel view synthesis given multi-view images. Recently, some works have attempted to train a NeRF from a single image with 3D priors. They mainly focus on a limited field of view with a few occlusions, which greatly limits their scalability to real-world 360-degree panoramic scenarios with large-size occlusions. In this paper, we present PERF, a 360-degree novel view synthesis framework that trains a panoramic neural radiance field from a single panorama. Notably, PERF allows 3D roaming in a complex scene without expensive and tedious image collection. To achieve this goal, we propose a novel collaborative RGBD inpainting method and a progressive inpainting-and-erasing method to lift up a 360-degree 2D scene to a 3D scene. Specifically, we first predict a panoramic depth map as initialization given a single panorama and reconstruct visible 3D regions with volume rendering. Then we introduce a collaborative RGBD inpainting approach into a NeRF for completing RGB images and depth maps from random views, which is derived from an RGB Stable Diffusion model and a monocular depth estimator. Finally, we introduce an inpainting-and-erasing strategy to avoid inconsistent geometry between a newly-sampled view and reference views. The two components are integrated into the learning of NeRFs in a unified optimization framework and achieve promising results. Extensive experiments on Replica and a new dataset PERF-in-the-wild demonstrate the superiority of our PERF over state-of-the-art methods. Our PERF can be widely used for real-world applications, such as panorama-to-3D, text-to-3D, and 3D scene stylization applications. Project page and code are available at https://perf-project.github.io/ and https://github.com/perf-project/PeRF.