 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
NICE 2023 Zero-shot Image Captioning Challenge
Sep 06, 2023

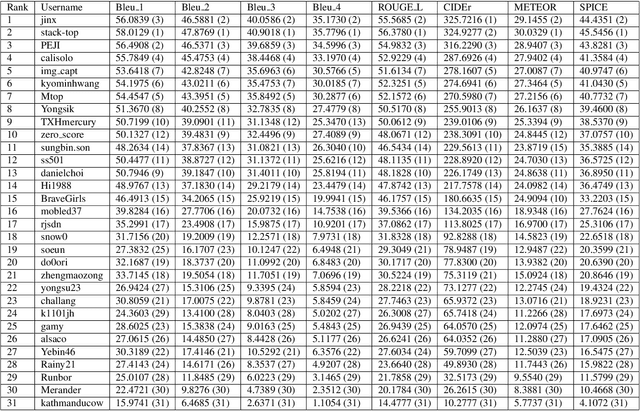
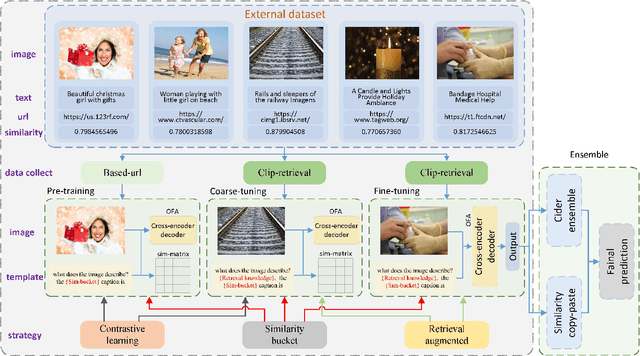
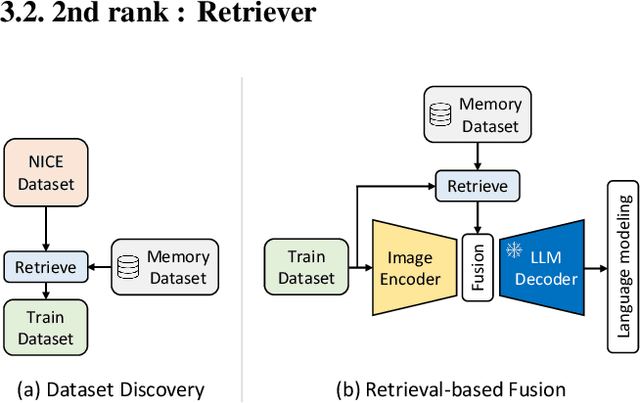
In this report, we introduce NICE project\footnote{\url{https://nice.lgresearch.ai/}} and share the results and outcomes of NICE challenge 2023. This project is designed to challenge the computer vision community to develop robust image captioning models that advance the state-of-the-art both in terms of accuracy and fairness. Through the challenge, the image captioning models were tested using a new evaluation dataset that includes a large variety of visual concepts from many domains. There was no specific training data provided for the challenge, and therefore the challenge entries were required to adapt to new types of image descriptions that had not been seen during training. This report includes information on the newly proposed NICE dataset, evaluation methods, challenge results, and technical details of top-ranking entries. We expect that the outcomes of the challenge will contribute to the improvement of AI models on various vision-language tasks.
GNeSF: Generalizable Neural Semantic Fields
Oct 26, 20233D scene segmentation based on neural implicit representation has emerged recently with the advantage of training only on 2D supervision. However, existing approaches still requires expensive per-scene optimization that prohibits generalization to novel scenes during inference. To circumvent this problem, we introduce a generalizable 3D segmentation framework based on implicit representation. Specifically, our framework takes in multi-view image features and semantic maps as the inputs instead of only spatial information to avoid overfitting to scene-specific geometric and semantic information. We propose a novel soft voting mechanism to aggregate the 2D semantic information from different views for each 3D point. In addition to the image features, view difference information is also encoded in our framework to predict the voting scores. Intuitively, this allows the semantic information from nearby views to contribute more compared to distant ones. Furthermore, a visibility module is also designed to detect and filter out detrimental information from occluded views. Due to the generalizability of our proposed method, we can synthesize semantic maps or conduct 3D semantic segmentation for novel scenes with solely 2D semantic supervision. Experimental results show that our approach achieves comparable performance with scene-specific approaches. More importantly, our approach can even outperform existing strong supervision-based approaches with only 2D annotations. Our source code is available at: https://github.com/HLinChen/GNeSF.
Feature Extraction and Classification from Planetary Science Datasets enabled by Machine Learning
Oct 26, 2023In this paper we present two examples of recent investigations that we have undertaken, applying Machine Learning (ML) neural networks (NN) to image datasets from outer planet missions to achieve feature recognition. Our first investigation was to recognize ice blocks (also known as rafts, plates, polygons) in the chaos regions of fractured ice on Europa. We used a transfer learning approach, adding and training new layers to an industry-standard Mask R-CNN (Region-based Convolutional Neural Network) to recognize labeled blocks in a training dataset. Subsequently, the updated model was tested against a new dataset, achieving 68% precision. In a different application, we applied the Mask R-CNN to recognize clouds on Titan, again through updated training followed by testing against new data, with a precision of 95% over 369 images. We evaluate the relative successes of our techniques and suggest how training and recognition could be further improved. The new approaches we have used for planetary datasets can further be applied to similar recognition tasks on other planets, including Earth. For imagery of outer planets in particular, the technique holds the possibility of greatly reducing the volume of returned data, via onboard identification of the most interesting image subsets, or by returning only differential data (images where changes have occurred) greatly enhancing the information content of the final data stream.
LinFlo-Net: A two-stage deep learning method to generate simulation ready meshes of the heart
Oct 30, 2023We present a deep learning model to automatically generate computer models of the human heart from patient imaging data with an emphasis on its capability to generate thin-walled cardiac structures. Our method works by deforming a template mesh to fit the cardiac structures to the given image. Compared with prior deep learning methods that adopted this approach, our framework is designed to minimize mesh self-penetration, which typically arises when deforming surface meshes separated by small distances. We achieve this by using a two-stage diffeomorphic deformation process along with a novel loss function derived from the kinematics of motion that penalizes surface contact and interpenetration. Our model demonstrates comparable accuracy with state-of-the-art methods while additionally producing meshes free of self-intersections. The resultant meshes are readily usable in physics based simulation, minimizing the need for post-processing and cleanup.
Soil Image Segmentation Based on Mask R-CNN
Sep 02, 2023
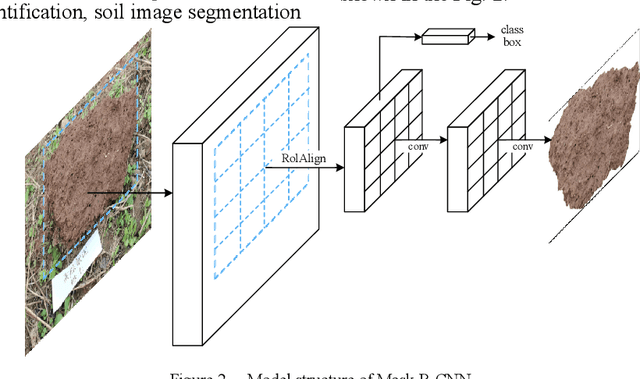
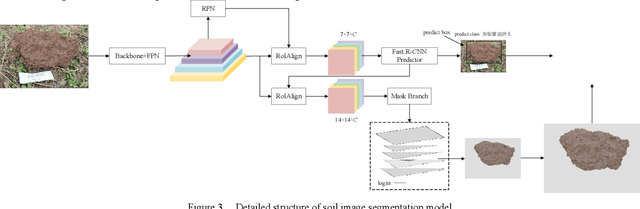
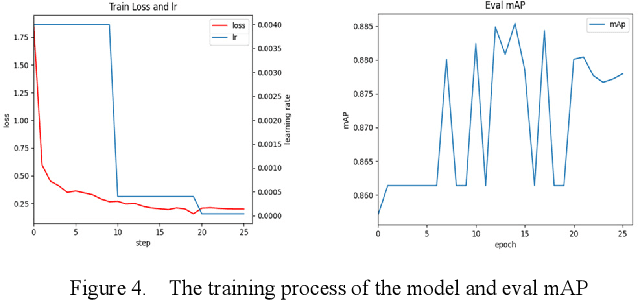
The complex background in the soil image collected in the field natural environment will affect the subsequent soil image recognition based on machine vision. Segmenting the soil center area from the soil image can eliminate the influence of the complex background, which is an important preprocessing work for subsequent soil image recognition. For the first time, the deep learning method was applied to soil image segmentation, and the Mask R-CNN model was selected to complete the positioning and segmentation of soil images. Construct a soil image dataset based on the collected soil images, use the EISeg annotation tool to mark the soil area as soil, and save the annotation information; train the Mask R-CNN soil image instance segmentation model. The trained model can obtain accurate segmentation results for soil images, and can show good performance on soil images collected in different environments; the trained instance segmentation model has a loss value of 0.1999 in the training set, and the mAP of the validation set segmentation (IoU=0.5) is 0.8804, and it takes only 0.06s to complete image segmentation based on GPU acceleration, which can meet the real-time segmentation and detection of soil images in the field under natural conditions. You can get our code in the Conclusions. The homepage is https://github.com/YidaMyth.
* 4 pages, 5 figures, Published in 2023 3rd International Conference on Consumer Electronics and Computer Engineering
360$^\circ$ Reconstruction From a Single Image Using Space Carved Outpainting
Sep 19, 2023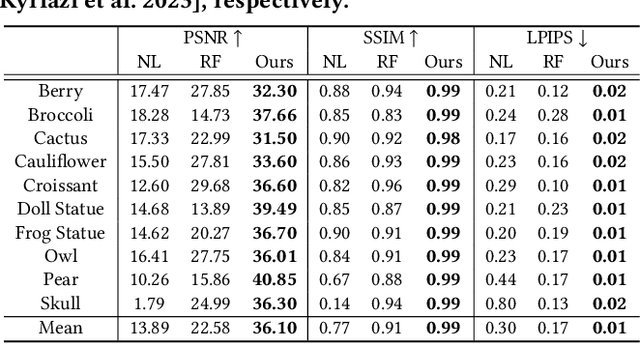
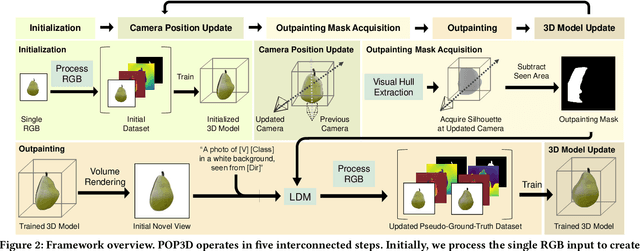
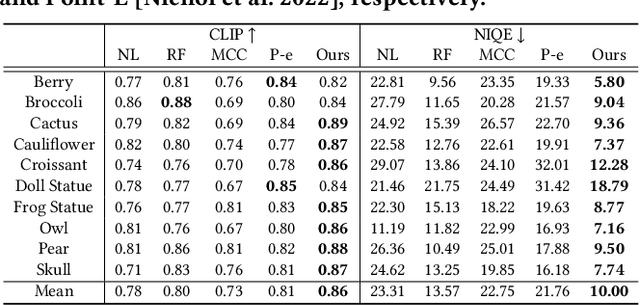
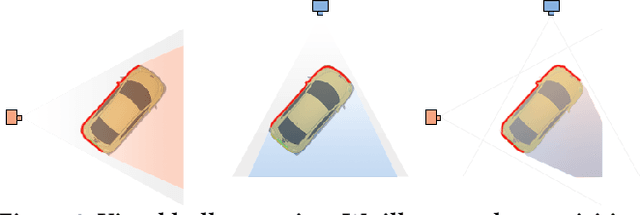
We introduce POP3D, a novel framework that creates a full $360^\circ$-view 3D model from a single image. POP3D resolves two prominent issues that limit the single-view reconstruction. Firstly, POP3D offers substantial generalizability to arbitrary categories, a trait that previous methods struggle to achieve. Secondly, POP3D further improves reconstruction fidelity and naturalness, a crucial aspect that concurrent works fall short of. Our approach marries the strengths of four primary components: (1) a monocular depth and normal predictor that serves to predict crucial geometric cues, (2) a space carving method capable of demarcating the potentially unseen portions of the target object, (3) a generative model pre-trained on a large-scale image dataset that can complete unseen regions of the target, and (4) a neural implicit surface reconstruction method tailored in reconstructing objects using RGB images along with monocular geometric cues. The combination of these components enables POP3D to readily generalize across various in-the-wild images and generate state-of-the-art reconstructions, outperforming similar works by a significant margin. Project page: \url{http://cg.postech.ac.kr/research/POP3D}
PERF: Panoramic Neural Radiance Field from a Single Panorama
Oct 28, 2023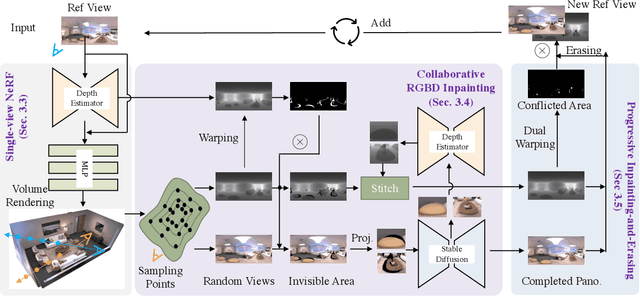
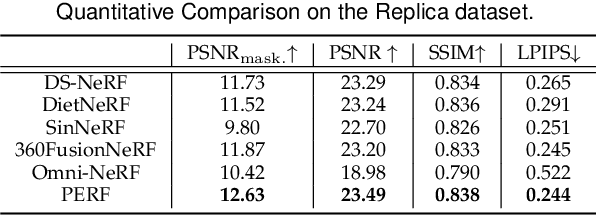
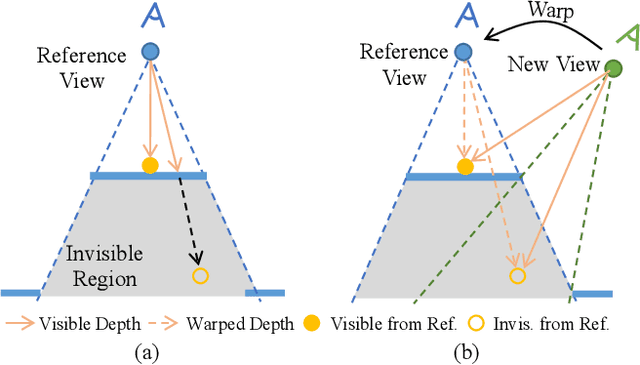

Neural Radiance Field (NeRF) has achieved substantial progress in novel view synthesis given multi-view images. Recently, some works have attempted to train a NeRF from a single image with 3D priors. They mainly focus on a limited field of view with a few occlusions, which greatly limits their scalability to real-world 360-degree panoramic scenarios with large-size occlusions. In this paper, we present PERF, a 360-degree novel view synthesis framework that trains a panoramic neural radiance field from a single panorama. Notably, PERF allows 3D roaming in a complex scene without expensive and tedious image collection. To achieve this goal, we propose a novel collaborative RGBD inpainting method and a progressive inpainting-and-erasing method to lift up a 360-degree 2D scene to a 3D scene. Specifically, we first predict a panoramic depth map as initialization given a single panorama and reconstruct visible 3D regions with volume rendering. Then we introduce a collaborative RGBD inpainting approach into a NeRF for completing RGB images and depth maps from random views, which is derived from an RGB Stable Diffusion model and a monocular depth estimator. Finally, we introduce an inpainting-and-erasing strategy to avoid inconsistent geometry between a newly-sampled view and reference views. The two components are integrated into the learning of NeRFs in a unified optimization framework and achieve promising results. Extensive experiments on Replica and a new dataset PERF-in-the-wild demonstrate the superiority of our PERF over state-of-the-art methods. Our PERF can be widely used for real-world applications, such as panorama-to-3D, text-to-3D, and 3D scene stylization applications. Project page and code are available at https://perf-project.github.io/ and https://github.com/perf-project/PeRF.
YOLOv8-Based Visual Detection of Road Hazards: Potholes, Sewer Covers, and Manholes
Oct 31, 2023Effective detection of road hazards plays a pivotal role in road infrastructure maintenance and ensuring road safety. This research paper provides a comprehensive evaluation of YOLOv8, an object detection model, in the context of detecting road hazards such as potholes, Sewer Covers, and Man Holes. A comparative analysis with previous iterations, YOLOv5 and YOLOv7, is conducted, emphasizing the importance of computational efficiency in various applications. The paper delves into the architecture of YOLOv8 and explores image preprocessing techniques aimed at enhancing detection accuracy across diverse conditions, including variations in lighting, road types, hazard sizes, and types. Furthermore, hyperparameter tuning experiments are performed to optimize model performance through adjustments in learning rates, batch sizes, anchor box sizes, and augmentation strategies. Model evaluation is based on Mean Average Precision (mAP), a widely accepted metric for object detection performance. The research assesses the robustness and generalization capabilities of the models through mAP scores calculated across the diverse test scenarios, underlining the significance of YOLOv8 in road hazard detection and infrastructure maintenance.
View Classification and Object Detection in Cardiac Ultrasound to Localize Valves via Deep Learning
Oct 31, 2023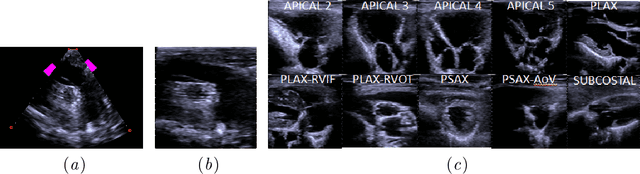

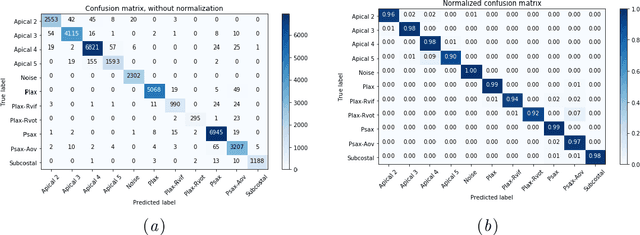
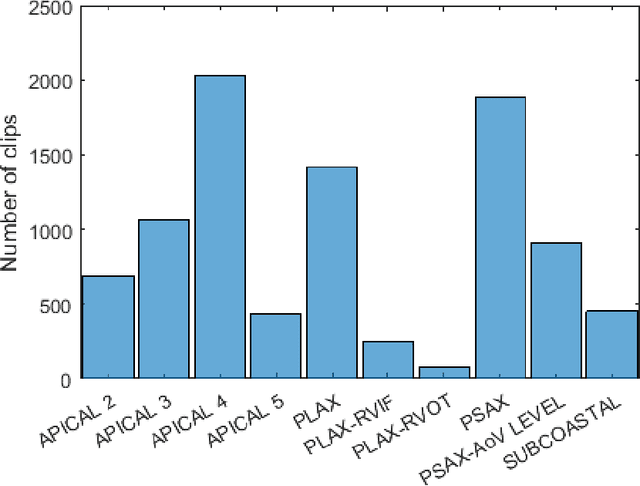
Echocardiography provides an important tool for clinicians to observe the function of the heart in real time, at low cost, and without harmful radiation. Automated localization and classification of heart valves enables automatic extraction of quantities associated with heart mechanical function and related blood flow measurements. We propose a machine learning pipeline that uses deep neural networks for separate classification and localization steps. As the first step in the pipeline, we apply view classification to echocardiograms with ten unique anatomic views of the heart. In the second step, we apply deep learning-based object detection to both localize and identify the valves. Image segmentation based object detection in echocardiography has been shown in many earlier studies but, to the best of our knowledge, this is the first study that predicts the bounding boxes around the valves along with classification from 2D ultrasound images with the help of deep neural networks. Our object detection experiments applied to the Apical views suggest that it is possible to localize and identify multiple valves precisely.
Contrast-agent-induced deterministic component of CT-density in the abdominal aorta during routine angiography: proof of concept study
Nov 03, 2023Background and objective: CTA is a gold standard of preoperative diagnosis of abdominal aorta and typically used for geometric-only characteristic extraction. We assume that a model describing the dynamic behavior of the contrast agent in the vessel can be developed from the data of routine CTA studies, allowing the procedure to be investigated and optimized without the need for additional perfusion CT studies. Obtained spatial distribution of CA can be valuable for both increasing the diagnostic value of a particular study and improving the CT data processing tools. Methods: In accordance with the Beer-Lambert law and the absence of chemical interaction between blood and CA, we postulated the existence of a deterministic CA-induced component in the CT signal density. The proposed model, having a double-sigmoid structure, contains six coefficients relevant to the properties of hemodynamics. To validate the model, expert segmentation was performed using the 3D Slicer application for the CTA data obtained from publicly available source. The model was fitted to the data using the non-linear least square method with Levenberg-Marquardt optimization. Results: We analyzed 594 CTA images (4 studies with median size of 144 slices, IQR [134; 158.5]; 1:1 normal:pathology balance). Goodness-of-fit was proved by Wilcox test (p-value > 0.05 for all cases). The proposed model correctly simulated normal blood flow and hemodynamics disturbances caused by local abnormalities (aneurysm, thrombus and arterial branching). Conclusions: Proposed approach can be useful for personalized CA modeling of vessels, improvement of CTA image processing and preparation of synthetic CT training data for artificial intelligence.