 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
AudRandAug: Random Image Augmentations for Audio Classification
Sep 09, 2023
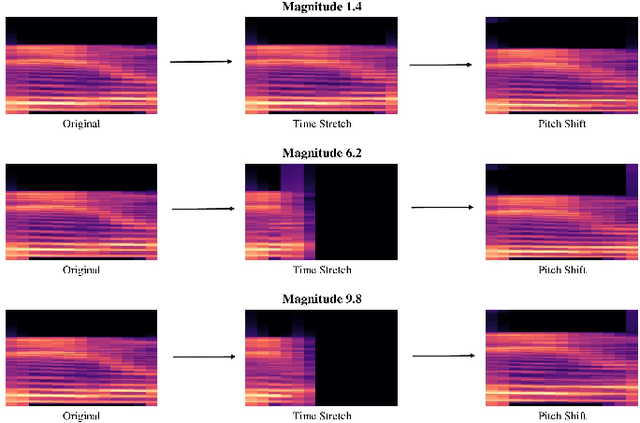

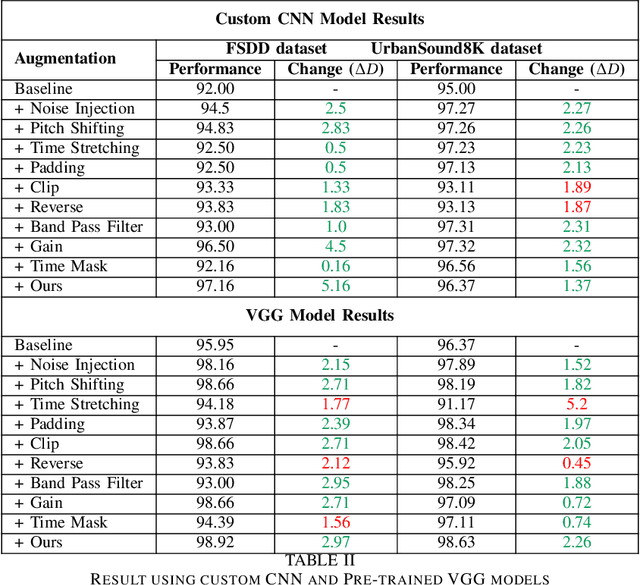
Data augmentation has proven to be effective in training neural networks. Recently, a method called RandAug was proposed, randomly selecting data augmentation techniques from a predefined search space. RandAug has demonstrated significant performance improvements for image-related tasks while imposing minimal computational overhead. However, no prior research has explored the application of RandAug specifically for audio data augmentation, which converts audio into an image-like pattern. To address this gap, we introduce AudRandAug, an adaptation of RandAug for audio data. AudRandAug selects data augmentation policies from a dedicated audio search space. To evaluate the effectiveness of AudRandAug, we conducted experiments using various models and datasets. Our findings indicate that AudRandAug outperforms other existing data augmentation methods regarding accuracy performance.
Style Generation: Image Synthesis based on Coarsely Matched Texts
Sep 08, 2023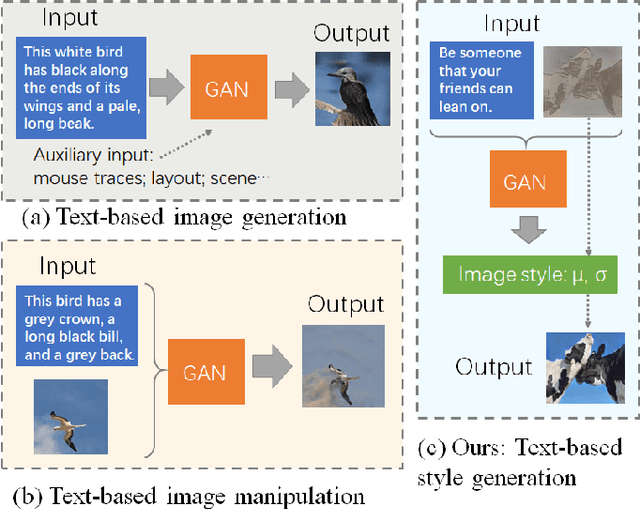


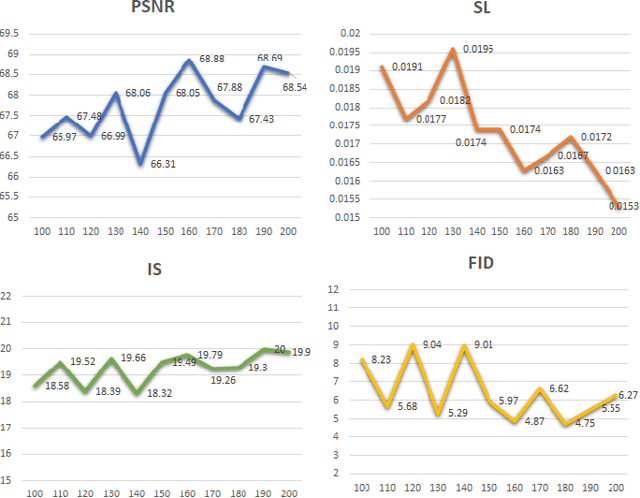
Previous text-to-image synthesis algorithms typically use explicit textual instructions to generate/manipulate images accurately, but they have difficulty adapting to guidance in the form of coarsely matched texts. In this work, we attempt to stylize an input image using such coarsely matched text as guidance. To tackle this new problem, we introduce a novel task called text-based style generation and propose a two-stage generative adversarial network: the first stage generates the overall image style with a sentence feature, and the second stage refines the generated style with a synthetic feature, which is produced by a multi-modality style synthesis module. We re-filter one existing dataset and collect a new dataset for the task. Extensive experiments and ablation studies are conducted to validate our framework. The practical potential of our work is demonstrated by various applications such as text-image alignment and story visualization. Our datasets are published at https://www.kaggle.com/datasets/mengyaocui/style-generation.
MEFLUT: Unsupervised 1D Lookup Tables for Multi-exposure Image Fusion
Sep 21, 2023In this paper, we introduce a new approach for high-quality multi-exposure image fusion (MEF). We show that the fusion weights of an exposure can be encoded into a 1D lookup table (LUT), which takes pixel intensity value as input and produces fusion weight as output. We learn one 1D LUT for each exposure, then all the pixels from different exposures can query 1D LUT of that exposure independently for high-quality and efficient fusion. Specifically, to learn these 1D LUTs, we involve attention mechanism in various dimensions including frame, channel and spatial ones into the MEF task so as to bring us significant quality improvement over the state-of-the-art (SOTA). In addition, we collect a new MEF dataset consisting of 960 samples, 155 of which are manually tuned by professionals as ground-truth for evaluation. Our network is trained by this dataset in an unsupervised manner. Extensive experiments are conducted to demonstrate the effectiveness of all the newly proposed components, and results show that our approach outperforms the SOTA in our and another representative dataset SICE, both qualitatively and quantitatively. Moreover, our 1D LUT approach takes less than 4ms to run a 4K image on a PC GPU. Given its high quality, efficiency and robustness, our method has been shipped into millions of Android mobiles across multiple brands world-wide. Code is available at: https://github.com/Hedlen/MEFLUT.
Towards Real-World Burst Image Super-Resolution: Benchmark and Method
Sep 09, 2023
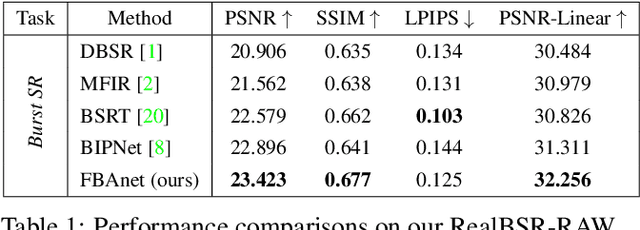
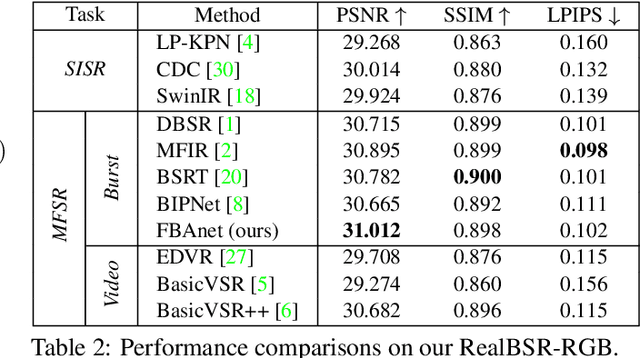
Despite substantial advances, single-image super-resolution (SISR) is always in a dilemma to reconstruct high-quality images with limited information from one input image, especially in realistic scenarios. In this paper, we establish a large-scale real-world burst super-resolution dataset, i.e., RealBSR, to explore the faithful reconstruction of image details from multiple frames. Furthermore, we introduce a Federated Burst Affinity network (FBAnet) to investigate non-trivial pixel-wise displacements among images under real-world image degradation. Specifically, rather than using pixel-wise alignment, our FBAnet employs a simple homography alignment from a structural geometry aspect and a Federated Affinity Fusion (FAF) strategy to aggregate the complementary information among frames. Those fused informative representations are fed to a Transformer-based module of burst representation decoding. Besides, we have conducted extensive experiments on two versions of our datasets, i.e., RealBSR-RAW and RealBSR-RGB. Experimental results demonstrate that our FBAnet outperforms existing state-of-the-art burst SR methods and also achieves visually-pleasant SR image predictions with model details. Our dataset, codes, and models are publicly available at https://github.com/yjsunnn/FBANet.
Dual Conditioned Diffusion Models for Out-Of-Distribution Detection: Application to Fetal Ultrasound Videos
Nov 01, 2023Out-of-distribution (OOD) detection is essential to improve the reliability of machine learning models by detecting samples that do not belong to the training distribution. Detecting OOD samples effectively in certain tasks can pose a challenge because of the substantial heterogeneity within the in-distribution (ID), and the high structural similarity between ID and OOD classes. For instance, when detecting heart views in fetal ultrasound videos there is a high structural similarity between the heart and other anatomies such as the abdomen, and large in-distribution variance as a heart has 5 distinct views and structural variations within each view. To detect OOD samples in this context, the resulting model should generalise to the intra-anatomy variations while rejecting similar OOD samples. In this paper, we introduce dual-conditioned diffusion models (DCDM) where we condition the model on in-distribution class information and latent features of the input image for reconstruction-based OOD detection. This constrains the generative manifold of the model to generate images structurally and semantically similar to those within the in-distribution. The proposed model outperforms reference methods with a 12% improvement in accuracy, 22% higher precision, and an 8% better F1 score.
fMRI-PTE: A Large-scale fMRI Pretrained Transformer Encoder for Multi-Subject Brain Activity Decoding
Nov 01, 2023The exploration of brain activity and its decoding from fMRI data has been a longstanding pursuit, driven by its potential applications in brain-computer interfaces, medical diagnostics, and virtual reality. Previous approaches have primarily focused on individual subject analysis, highlighting the need for a more universal and adaptable framework, which is the core motivation behind our work. In this work, we propose fMRI-PTE, an innovative auto-encoder approach for fMRI pre-training, with a focus on addressing the challenges of varying fMRI data dimensions due to individual brain differences. Our approach involves transforming fMRI signals into unified 2D representations, ensuring consistency in dimensions and preserving distinct brain activity patterns. We introduce a novel learning strategy tailored for pre-training 2D fMRI images, enhancing the quality of reconstruction. fMRI-PTE's adaptability with image generators enables the generation of well-represented fMRI features, facilitating various downstream tasks, including within-subject and cross-subject brain activity decoding. Our contributions encompass introducing fMRI-PTE, innovative data transformation, efficient training, a novel learning strategy, and the universal applicability of our approach. Extensive experiments validate and support our claims, offering a promising foundation for further research in this domain.
Transparent Anomaly Detection via Concept-based Explanations
Nov 01, 2023Advancements in deep learning techniques have given a boost to the performance of anomaly detection. However, real-world and safety-critical applications demand a level of transparency and reasoning beyond accuracy. The task of anomaly detection (AD) focuses on finding whether a given sample follows the learned distribution. Existing methods lack the ability to reason with clear explanations for their outcomes. Hence to overcome this challenge, we propose Transparent {A}nomaly Detection {C}oncept {E}xplanations (ACE). ACE is able to provide human interpretable explanations in the form of concepts along with anomaly prediction. To the best of our knowledge, this is the first paper that proposes interpretable by-design anomaly detection. In addition to promoting transparency in AD, it allows for effective human-model interaction. Our proposed model shows either higher or comparable results to black-box uninterpretable models. We validate the performance of ACE across three realistic datasets - bird classification on CUB-200-2011, challenging histopathology slide image classification on TIL-WSI-TCGA, and gender classification on CelebA. We further demonstrate that our concept learning paradigm can be seamlessly integrated with other classification-based AD methods.
Not Just Learning from Others but Relying on Yourself: A New Perspective on Few-Shot Segmentation in Remote Sensing
Oct 19, 2023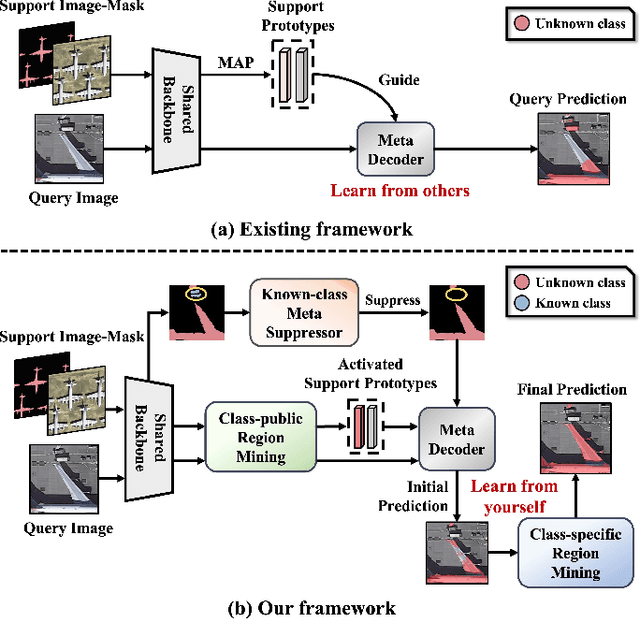


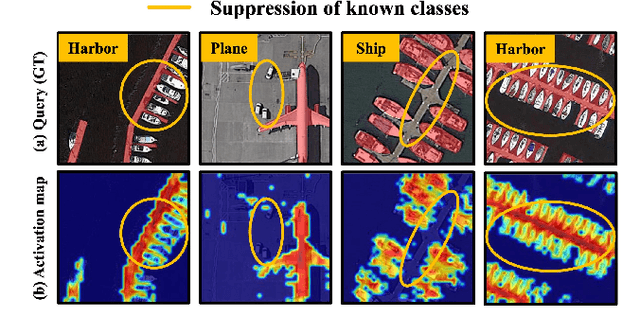
Few-shot segmentation (FSS) is proposed to segment unknown class targets with just a few annotated samples. Most current FSS methods follow the paradigm of mining the semantics from the support images to guide the query image segmentation. However, such a pattern of `learning from others' struggles to handle the extreme intra-class variation, preventing FSS from being directly generalized to remote sensing scenes. To bridge the gap of intra-class variance, we develop a Dual-Mining network named DMNet for cross-image mining and self-mining, meaning that it no longer focuses solely on support images but pays more attention to the query image itself. Specifically, we propose a Class-public Region Mining (CPRM) module to effectively suppress irrelevant feature pollution by capturing the common semantics between the support-query image pair. The Class-specific Region Mining (CSRM) module is then proposed to continuously mine the class-specific semantics of the query image itself in a `filtering' and `purifying' manner. In addition, to prevent the co-existence of multiple classes in remote sensing scenes from exacerbating the collapse of FSS generalization, we also propose a new Known-class Meta Suppressor (KMS) module to suppress the activation of known-class objects in the sample. Extensive experiments on the iSAID and LoveDA remote sensing datasets have demonstrated that our method sets the state-of-the-art with a minimum number of model parameters. Significantly, our model with the backbone of Resnet-50 achieves the mIoU of 49.58% and 51.34% on iSAID under 1-shot and 5-shot settings, outperforming the state-of-the-art method by 1.8% and 1.12%, respectively. The code is publicly available at https://github.com/HanboBizl/DMNet.
Implicit Neural Image Stitching With Enhanced and Blended Feature Reconstruction
Sep 07, 2023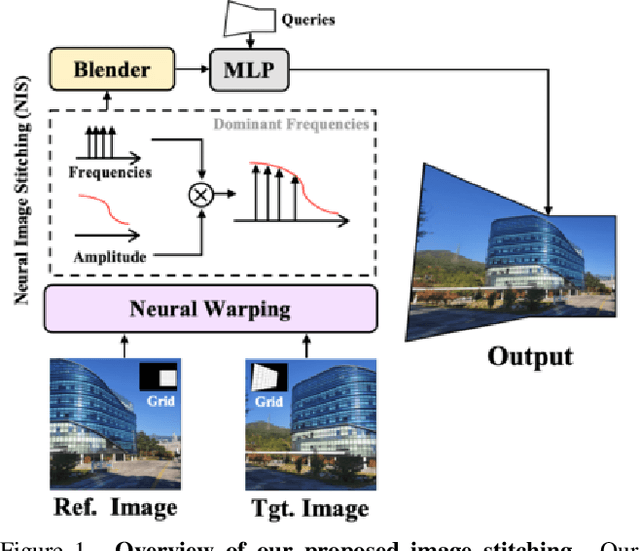
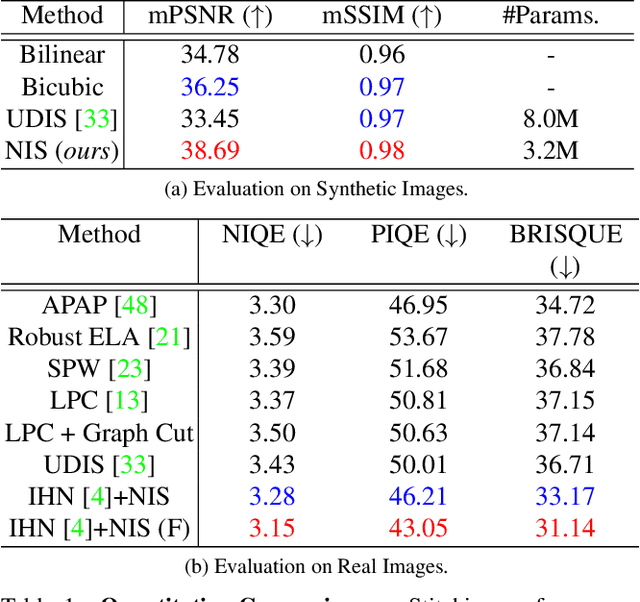

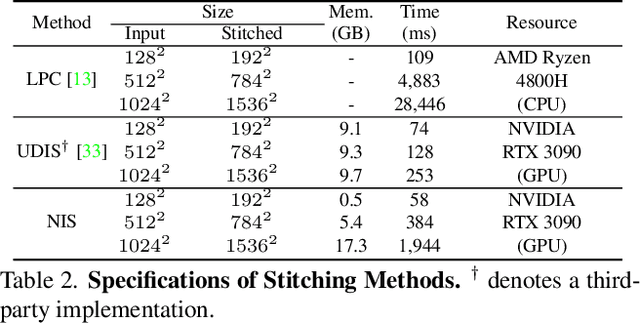
Existing frameworks for image stitching often provide visually reasonable stitchings. However, they suffer from blurry artifacts and disparities in illumination, depth level, etc. Although the recent learning-based stitchings relax such disparities, the required methods impose sacrifice of image qualities failing to capture high-frequency details for stitched images. To address the problem, we propose a novel approach, implicit Neural Image Stitching (NIS) that extends arbitrary-scale super-resolution. Our method estimates Fourier coefficients of images for quality-enhancing warps. Then, the suggested model blends color mismatches and misalignment in the latent space and decodes the features into RGB values of stitched images. Our experiments show that our approach achieves improvement in resolving the low-definition imaging of the previous deep image stitching with favorable accelerated image-enhancing methods. Our source code is available at https://github.com/minshu-kim/NIS.
Towards Few-Call Model Stealing via Active Self-Paced Knowledge Distillation and Diffusion-Based Image Generation
Sep 29, 2023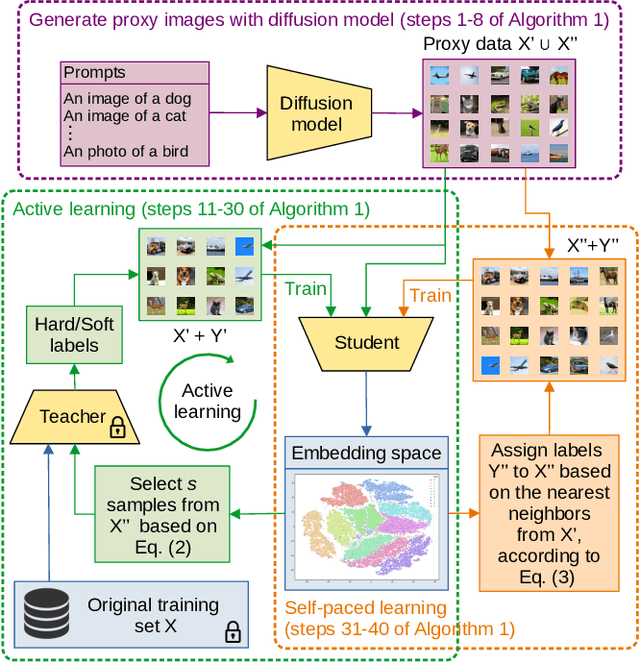
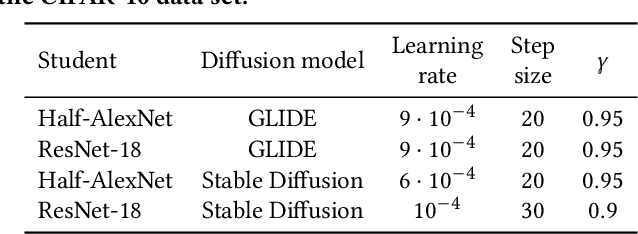


Diffusion models showcased strong capabilities in image synthesis, being used in many computer vision tasks with great success. To this end, we propose to explore a new use case, namely to copy black-box classification models without having access to the original training data, the architecture, and the weights of the model, \ie~the model is only exposed through an inference API. More specifically, we can only observe the (soft or hard) labels for some image samples passed as input to the model. Furthermore, we consider an additional constraint limiting the number of model calls, mostly focusing our research on few-call model stealing. In order to solve the model extraction task given the applied restrictions, we propose the following framework. As training data, we create a synthetic data set (called proxy data set) by leveraging the ability of diffusion models to generate realistic and diverse images. Given a maximum number of allowed API calls, we pass the respective number of samples through the black-box model to collect labels. Finally, we distill the knowledge of the black-box teacher (attacked model) into a student model (copy of the attacked model), harnessing both labeled and unlabeled data generated by the diffusion model. We employ a novel active self-paced learning framework to make the most of the proxy data during distillation. Our empirical results on two data sets confirm the superiority of our framework over two state-of-the-art methods in the few-call model extraction scenario.