 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Handshape recognition for Argentinian Sign Language using ProbSom
Oct 26, 2023
Automatic sign language recognition is an important topic within the areas of human-computer interaction and machine learning. On the one hand, it poses a complex challenge that requires the intervention of various knowledge areas, such as video processing, image processing, intelligent systems and linguistics. On the other hand, robust recognition of sign language could assist in the translation process and the integration of hearing-impaired people. This paper offers two main contributions: first, the creation of a database of handshapes for the Argentinian Sign Language (LSA), which is a topic that has barely been discussed so far. Secondly, a technique for image processing, descriptor extraction and subsequent handshape classification using a supervised adaptation of self-organizing maps that is called ProbSom. This technique is compared to others in the state of the art, such as Support Vector Machines (SVM), Random Forests, and Neural Networks. The database that was built contains 800 images with 16 LSA handshapes, and is a first step towards building a comprehensive database of Argentinian signs. The ProbSom-based neural classifier, using the proposed descriptor, achieved an accuracy rate above 90%.
Viewpoint Integration and Registration with Vision Language Foundation Model for Image Change Understanding
Sep 15, 2023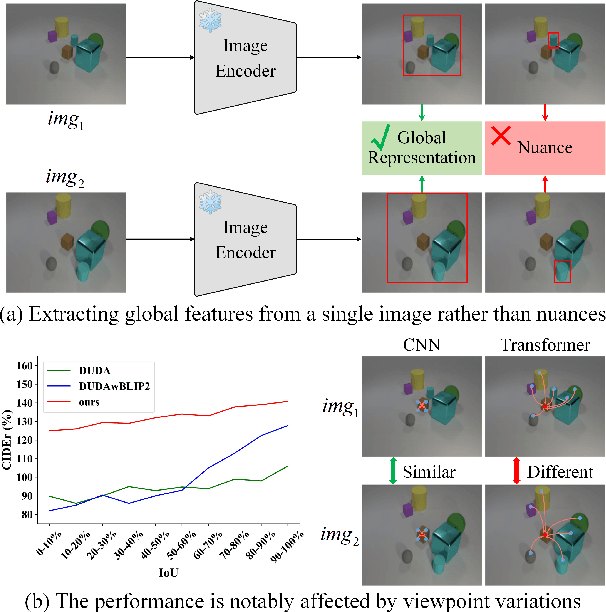
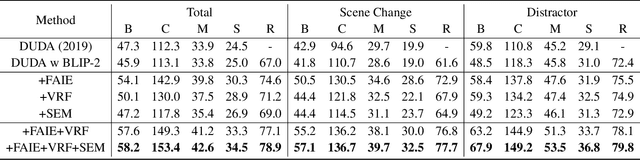

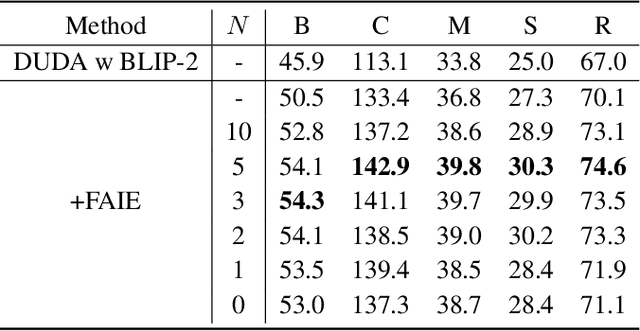
Recently, the development of pre-trained vision language foundation models (VLFMs) has led to remarkable performance in many tasks. However, these models tend to have strong single-image understanding capability but lack the ability to understand multiple images. Therefore, they cannot be directly applied to cope with image change understanding (ICU), which requires models to capture actual changes between multiple images and describe them in language. In this paper, we discover that existing VLFMs perform poorly when applied directly to ICU because of the following problems: (1) VLFMs generally learn the global representation of a single image, while ICU requires capturing nuances between multiple images. (2) The ICU performance of VLFMs is significantly affected by viewpoint variations, which is caused by the altered relationships between objects when viewpoint changes. To address these problems, we propose a Viewpoint Integration and Registration method. Concretely, we introduce a fused adapter image encoder that fine-tunes pre-trained encoders by inserting designed trainable adapters and fused adapters, to effectively capture nuances between image pairs. Additionally, a viewpoint registration flow and a semantic emphasizing module are designed to reduce the performance degradation caused by viewpoint variations in the visual and semantic space, respectively. Experimental results on CLEVR-Change and Spot-the-Diff demonstrate that our method achieves state-of-the-art performance in all metrics.
Leveraging Language Models to Detect Greenwashing
Oct 30, 2023In recent years, climate change repercussions have increasingly captured public interest. Consequently, corporations are emphasizing their environmental efforts in sustainability reports to bolster their public image. Yet, the absence of stringent regulations in review of such reports allows potential greenwashing. In this study, we introduce a novel methodology to train a language model on generated labels for greenwashing risk. Our primary contributions encompass: developing a mathematical formulation to quantify greenwashing risk, a fine-tuned ClimateBERT model for this problem, and a comparative analysis of results. On a test set comprising of sustainability reports, our best model achieved an average accuracy score of 86.34% and F1 score of 0.67, demonstrating that our methods show a promising direction of exploration for this task.
AudRandAug: Random Image Augmentations for Audio Classification
Sep 09, 2023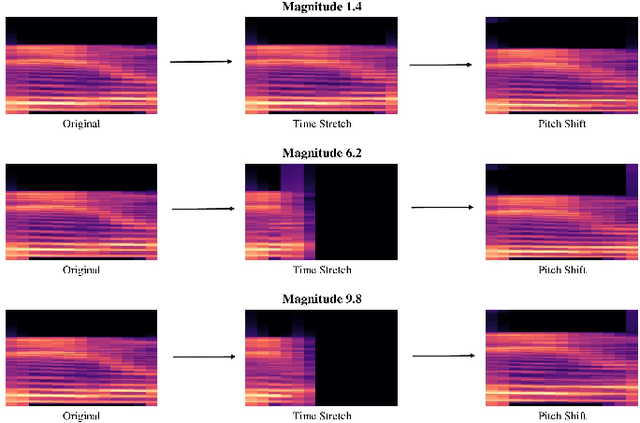

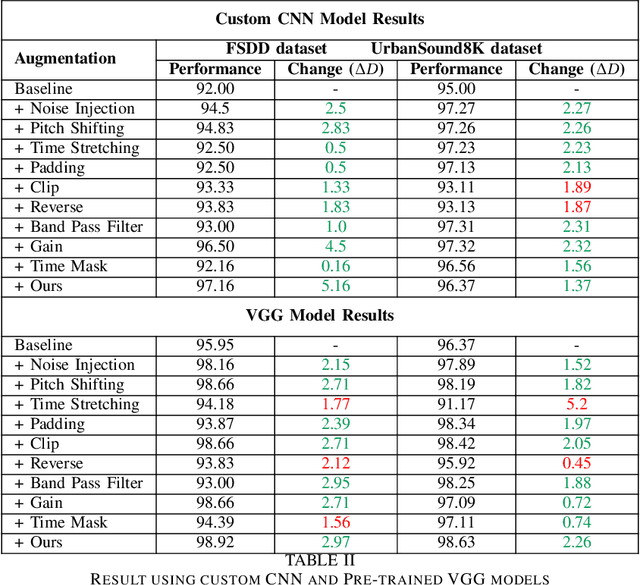
Data augmentation has proven to be effective in training neural networks. Recently, a method called RandAug was proposed, randomly selecting data augmentation techniques from a predefined search space. RandAug has demonstrated significant performance improvements for image-related tasks while imposing minimal computational overhead. However, no prior research has explored the application of RandAug specifically for audio data augmentation, which converts audio into an image-like pattern. To address this gap, we introduce AudRandAug, an adaptation of RandAug for audio data. AudRandAug selects data augmentation policies from a dedicated audio search space. To evaluate the effectiveness of AudRandAug, we conducted experiments using various models and datasets. Our findings indicate that AudRandAug outperforms other existing data augmentation methods regarding accuracy performance.
Style Generation: Image Synthesis based on Coarsely Matched Texts
Sep 08, 2023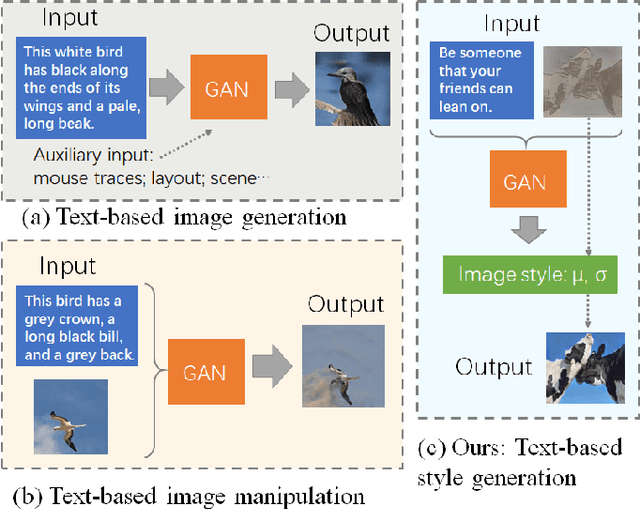


Previous text-to-image synthesis algorithms typically use explicit textual instructions to generate/manipulate images accurately, but they have difficulty adapting to guidance in the form of coarsely matched texts. In this work, we attempt to stylize an input image using such coarsely matched text as guidance. To tackle this new problem, we introduce a novel task called text-based style generation and propose a two-stage generative adversarial network: the first stage generates the overall image style with a sentence feature, and the second stage refines the generated style with a synthetic feature, which is produced by a multi-modality style synthesis module. We re-filter one existing dataset and collect a new dataset for the task. Extensive experiments and ablation studies are conducted to validate our framework. The practical potential of our work is demonstrated by various applications such as text-image alignment and story visualization. Our datasets are published at https://www.kaggle.com/datasets/mengyaocui/style-generation.
DEsignBench: Exploring and Benchmarking DALL-E 3 for Imagining Visual Design
Oct 23, 2023We introduce DEsignBench, a text-to-image (T2I) generation benchmark tailored for visual design scenarios. Recent T2I models like DALL-E 3 and others, have demonstrated remarkable capabilities in generating photorealistic images that align closely with textual inputs. While the allure of creating visually captivating images is undeniable, our emphasis extends beyond mere aesthetic pleasure. We aim to investigate the potential of using these powerful models in authentic design contexts. In pursuit of this goal, we develop DEsignBench, which incorporates test samples designed to assess T2I models on both "design technical capability" and "design application scenario." Each of these two dimensions is supported by a diverse set of specific design categories. We explore DALL-E 3 together with other leading T2I models on DEsignBench, resulting in a comprehensive visual gallery for side-by-side comparisons. For DEsignBench benchmarking, we perform human evaluations on generated images in DEsignBench gallery, against the criteria of image-text alignment, visual aesthetic, and design creativity. Our evaluation also considers other specialized design capabilities, including text rendering, layout composition, color harmony, 3D design, and medium style. In addition to human evaluations, we introduce the first automatic image generation evaluator powered by GPT-4V. This evaluator provides ratings that align well with human judgments, while being easily replicable and cost-efficient. A high-resolution version is available at https://github.com/design-bench/design-bench.github.io/raw/main/designbench.pdf?download=
ESVAE: An Efficient Spiking Variational Autoencoder with Reparameterizable Poisson Spiking Sampling
Oct 23, 2023In recent years, studies on image generation models of spiking neural networks (SNNs) have gained the attention of many researchers. Variational autoencoders (VAEs), as one of the most popular image generation models, have attracted a lot of work exploring their SNN implementation. Due to the constrained binary representation in SNNs, existing SNN VAE methods implicitly construct the latent space by an elaborated autoregressive network and use the network outputs as the sampling variables. However, this unspecified implicit representation of the latent space will increase the difficulty of generating high-quality images and introduces additional network parameters. In this paper, we propose an efficient spiking variational autoencoder (ESVAE) that constructs an interpretable latent space distribution and design a reparameterizable spiking sampling method. Specifically, we construct the prior and posterior of the latent space as a Poisson distribution using the firing rate of the spiking neurons. Subsequently, we propose a reparameterizable Poisson spiking sampling method, which is free from the additional network. Comprehensive experiments have been conducted, and the experimental results show that the proposed ESVAE outperforms previous SNN VAE methods in reconstructed & generated images quality. In addition, experiments demonstrate that ESVAE's encoder is able to retain the original image information more efficiently, and the decoder is more robust. The source code is available at https://github.com/QgZhan/ESVAE.
Understanding Calibration of Deep Neural Networks for Medical Image Classification
Sep 22, 2023In the field of medical image analysis, achieving high accuracy is not enough; ensuring well-calibrated predictions is also crucial. Confidence scores of a deep neural network play a pivotal role in explainability by providing insights into the model's certainty, identifying cases that require attention, and establishing trust in its predictions. Consequently, the significance of a well-calibrated model becomes paramount in the medical imaging domain, where accurate and reliable predictions are of utmost importance. While there has been a significant effort towards training modern deep neural networks to achieve high accuracy on medical imaging tasks, model calibration and factors that affect it remain under-explored. To address this, we conducted a comprehensive empirical study that explores model performance and calibration under different training regimes. We considered fully supervised training, which is the prevailing approach in the community, as well as rotation-based self-supervised method with and without transfer learning, across various datasets and architecture sizes. Multiple calibration metrics were employed to gain a holistic understanding of model calibration. Our study reveals that factors such as weight distributions and the similarity of learned representations correlate with the calibration trends observed in the models. Notably, models trained using rotation-based self-supervised pretrained regime exhibit significantly better calibration while achieving comparable or even superior performance compared to fully supervised models across different medical imaging datasets. These findings shed light on the importance of model calibration in medical image analysis and highlight the benefits of incorporating self-supervised learning approach to improve both performance and calibration.
Towards Real-World Burst Image Super-Resolution: Benchmark and Method
Sep 09, 2023
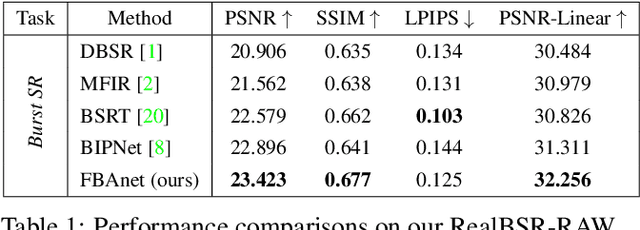
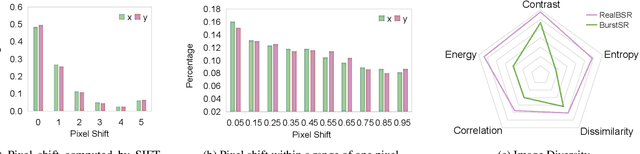
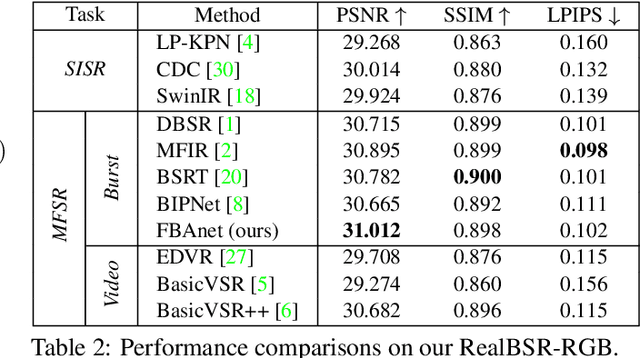
Despite substantial advances, single-image super-resolution (SISR) is always in a dilemma to reconstruct high-quality images with limited information from one input image, especially in realistic scenarios. In this paper, we establish a large-scale real-world burst super-resolution dataset, i.e., RealBSR, to explore the faithful reconstruction of image details from multiple frames. Furthermore, we introduce a Federated Burst Affinity network (FBAnet) to investigate non-trivial pixel-wise displacements among images under real-world image degradation. Specifically, rather than using pixel-wise alignment, our FBAnet employs a simple homography alignment from a structural geometry aspect and a Federated Affinity Fusion (FAF) strategy to aggregate the complementary information among frames. Those fused informative representations are fed to a Transformer-based module of burst representation decoding. Besides, we have conducted extensive experiments on two versions of our datasets, i.e., RealBSR-RAW and RealBSR-RGB. Experimental results demonstrate that our FBAnet outperforms existing state-of-the-art burst SR methods and also achieves visually-pleasant SR image predictions with model details. Our dataset, codes, and models are publicly available at https://github.com/yjsunnn/FBANet.
Brain decoding: toward real-time reconstruction of visual perception
Oct 18, 2023In the past five years, the use of generative and foundational AI systems has greatly improved the decoding of brain activity. Visual perception, in particular, can now be decoded from functional Magnetic Resonance Imaging (fMRI) with remarkable fidelity. This neuroimaging technique, however, suffers from a limited temporal resolution ($\approx$0.5 Hz) and thus fundamentally constrains its real-time usage. Here, we propose an alternative approach based on magnetoencephalography (MEG), a neuroimaging device capable of measuring brain activity with high temporal resolution ($\approx$5,000 Hz). For this, we develop an MEG decoding model trained with both contrastive and regression objectives and consisting of three modules: i) pretrained embeddings obtained from the image, ii) an MEG module trained end-to-end and iii) a pretrained image generator. Our results are threefold: Firstly, our MEG decoder shows a 7X improvement of image-retrieval over classic linear decoders. Second, late brain responses to images are best decoded with DINOv2, a recent foundational image model. Third, image retrievals and generations both suggest that MEG signals primarily contain high-level visual features, whereas the same approach applied to 7T fMRI also recovers low-level features. Overall, these results provide an important step towards the decoding - in real time - of the visual processes continuously unfolding within the human brain.