 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Inter-object Discriminative Graph Modeling for Indoor Scene Recognition
Nov 10, 2023
Variable scene layouts and coexisting objects across scenes make indoor scene recognition still a challenging task. Leveraging object information within scenes to enhance the distinguishability of feature representations has emerged as a key approach in this domain. Currently, most object-assisted methods use a separate branch to process object information, combining object and scene features heuristically. However, few of them pay attention to interpretably handle the hidden discriminative knowledge within object information. In this paper, we propose to leverage discriminative object knowledge to enhance scene feature representations. Initially, we capture the object-scene discriminative relationships from a probabilistic perspective, which are transformed into an Inter-Object Discriminative Prototype (IODP). Given the abundant prior knowledge from IODP, we subsequently construct a Discriminative Graph Network (DGN), in which pixel-level scene features are defined as nodes and the discriminative relationships between node features are encoded as edges. DGN aims to incorporate inter-object discriminative knowledge into the image representation through graph convolution. With the proposed IODP and DGN, we obtain state-of-the-art results on several widely used scene datasets, demonstrating the effectiveness of the proposed approach.
Cartoondiff: Training-free Cartoon Image Generation with Diffusion Transformer Models
Sep 15, 2023Image cartoonization has attracted significant interest in the field of image generation. However, most of the existing image cartoonization techniques require re-training models using images of cartoon style. In this paper, we present CartoonDiff, a novel training-free sampling approach which generates image cartoonization using diffusion transformer models. Specifically, we decompose the reverse process of diffusion models into the semantic generation phase and the detail generation phase. Furthermore, we implement the image cartoonization process by normalizing high-frequency signal of the noisy image in specific denoising steps. CartoonDiff doesn't require any additional reference images, complex model designs, or the tedious adjustment of multiple parameters. Extensive experimental results show the powerful ability of our CartoonDiff. The project page is available at: https://cartoondiff.github.io/
UNIQA: A Unified Framework for Both Full-Reference and No-Reference Image Quality Assessment
Oct 14, 2023The human visual system (HVS) is effective at distinguishing low-quality images due to its ability to sense the distortion level and the resulting semantic impact. Prior research focuses on developing dedicated networks based on the presence and absence of pristine images, respectively, and this results in limited application scope and potential performance inconsistency when switching from NR to FR IQA. In addition, most methods heavily rely on spatial distortion modeling through difference maps or weighted features, and this may not be able to well capture the correlations between distortion and the semantic impact it causes. To this end, we aim to design a unified network for both Full-Reference (FR) and No-Reference (NR) IQA via semantic impact modeling. Specifically, we employ an encoder to extract multi-level features from input images. Then a Hierarchical Self-Attention (HSA) module is proposed as a universal adapter for both FR and NR inputs to model the spatial distortion level at each encoder stage. Furthermore, considering that distortions contaminate encoder stages and damage image semantic meaning differently, a Cross-Scale Cross-Attention (CSCA) module is proposed to examine correlations between distortion at shallow stages and deep ones. By adopting HSA and CSCA, the proposed network can effectively perform both FR and NR IQA. Extensive experiments demonstrate that the proposed simple network is effective and outperforms the relevant state-of-the-art FR and NR methods on four synthetic-distorted datasets and three authentic-distorted datasets.
Anonymizing medical case-based explanations through disentanglement
Nov 08, 2023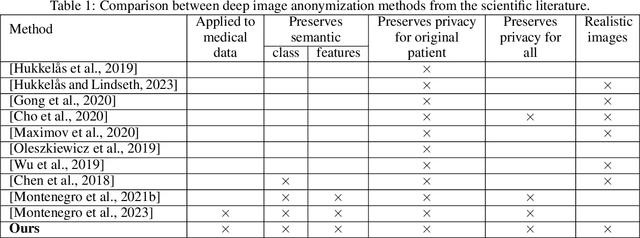
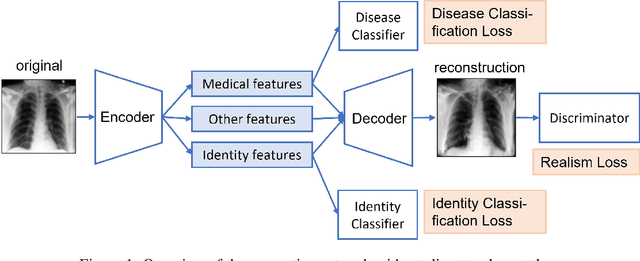
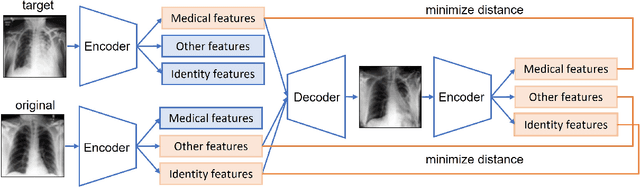
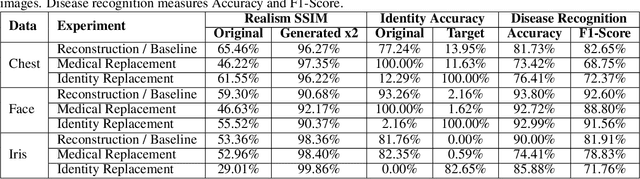
Case-based explanations are an intuitive method to gain insight into the decision-making process of deep learning models in clinical contexts. However, medical images cannot be shared as explanations due to privacy concerns. To address this problem, we propose a novel method for disentangling identity and medical characteristics of images and apply it to anonymize medical images. The disentanglement mechanism replaces some feature vectors in an image while ensuring that the remaining features are preserved, obtaining independent feature vectors that encode the images' identity and medical characteristics. We also propose a model to manufacture synthetic privacy-preserving identities to replace the original image's identity and achieve anonymization. The models are applied to medical and biometric datasets, demonstrating their capacity to generate realistic-looking anonymized images that preserve their original medical content. Additionally, the experiments show the network's inherent capacity to generate counterfactual images through the replacement of medical features.
Hierarchically Gated Recurrent Neural Network for Sequence Modeling
Nov 08, 2023Transformers have surpassed RNNs in popularity due to their superior abilities in parallel training and long-term dependency modeling. Recently, there has been a renewed interest in using linear RNNs for efficient sequence modeling. These linear RNNs often employ gating mechanisms in the output of the linear recurrence layer while ignoring the significance of using forget gates within the recurrence. In this paper, we propose a gated linear RNN model dubbed Hierarchically Gated Recurrent Neural Network (HGRN), which includes forget gates that are lower bounded by a learnable value. The lower bound increases monotonically when moving up layers. This allows the upper layers to model long-term dependencies and the lower layers to model more local, short-term dependencies. Experiments on language modeling, image classification, and long-range arena benchmarks showcase the efficiency and effectiveness of our proposed model. The source code is available at https://github.com/OpenNLPLab/HGRN.
Beyond Still Images: Robust Multi-Stream Spatiotemporal Networks
Nov 01, 2023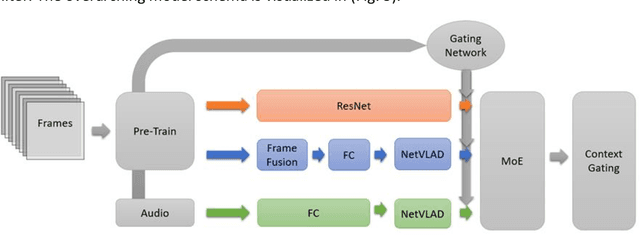
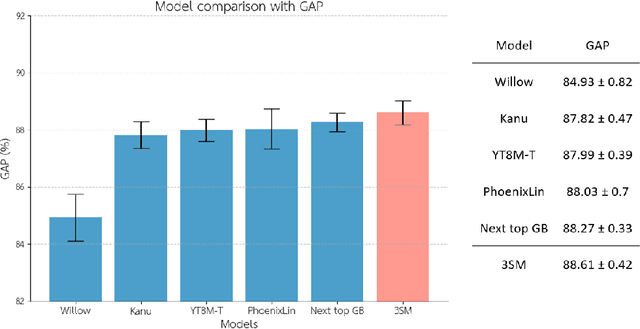

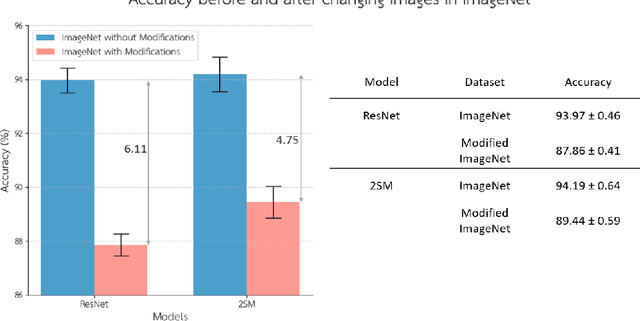
A defining characteristic of natural vision is its ability to withstand a variety of input alterations, resulting in the creation of an invariant representation of the surroundings. While convolutional neural networks exhibit resilience to certain forms of spatial input variation, modifications in the spatial and temporal aspects can significantly affect the representations of video content in deep neural networks. Inspired by the resilience of natural vision to input variations, we employ a simple multi-stream model to explore its potential to address spatiotemporal changes by including temporal features. Our primary goal is to introduce a video-trained model and evaluate its robustness to diverse image and video inputs, with a particular focus on exploring the role of temporal features in invariant recognition. Results show that including videos and the temporal stream during training mitigates the decline in accuracy and mAP in image and video understanding tasks by 1.36% and 3.14%, respectively.
Learning to See Physical Properties with Active Sensing Motor Policies
Nov 02, 2023Knowledge of terrain's physical properties inferred from color images can aid in making efficient robotic locomotion plans. However, unlike image classification, it is unintuitive for humans to label image patches with physical properties. Without labeled data, building a vision system that takes as input the observed terrain and predicts physical properties remains challenging. We present a method that overcomes this challenge by self-supervised labeling of images captured by robots during real-world traversal with physical property estimators trained in simulation. To ensure accurate labeling, we introduce Active Sensing Motor Policies (ASMP), which are trained to explore locomotion behaviors that increase the accuracy of estimating physical parameters. For instance, the quadruped robot learns to swipe its foot against the ground to estimate the friction coefficient accurately. We show that the visual system trained with a small amount of real-world traversal data accurately predicts physical parameters. The trained system is robust and works even with overhead images captured by a drone despite being trained on data collected by cameras attached to a quadruped robot walking on the ground.
Robust Identity Perceptual Watermark Against Deepfake Face Swapping
Nov 02, 2023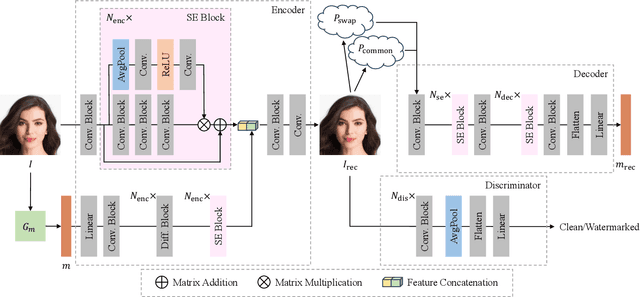
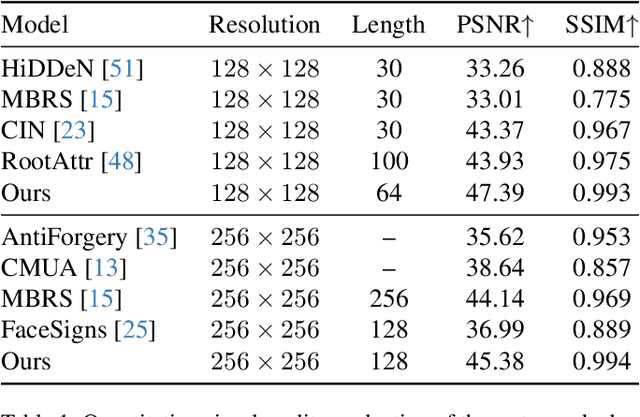

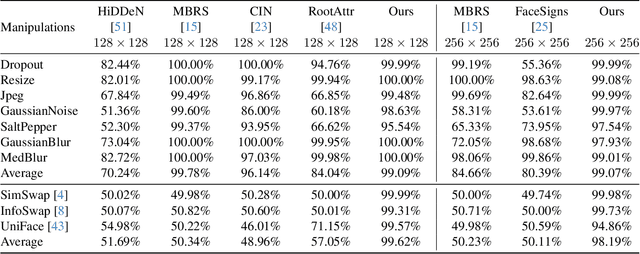
Notwithstanding offering convenience and entertainment to society, Deepfake face swapping has caused critical privacy issues with the rapid development of deep generative models. Due to imperceptible artifacts in high-quality synthetic images, passive detection models against face swapping in recent years usually suffer performance damping regarding the generalizability issue. Therefore, several studies have been attempted to proactively protect the original images against malicious manipulations by inserting invisible signals in advance. However, the existing proactive defense approaches demonstrate unsatisfactory results with respect to visual quality, detection accuracy, and source tracing ability. In this study, we propose the first robust identity perceptual watermarking framework that concurrently performs detection and source tracing against Deepfake face swapping proactively. We assign identity semantics regarding the image contents to the watermarks and devise an unpredictable and unreversible chaotic encryption system to ensure watermark confidentiality. The watermarks are encoded and recovered by jointly training an encoder-decoder framework along with adversarial image manipulations. Extensive experiments demonstrate state-of-the-art performance against Deepfake face swapping under both cross-dataset and cross-manipulation settings.
Multi-Context Dual Hyper-Prior Neural Image Compression
Sep 19, 2023Transform and entropy models are the two core components in deep image compression neural networks. Most existing learning-based image compression methods utilize convolutional-based transform, which lacks the ability to model long-range dependencies, primarily due to the limited receptive field of the convolution operation. To address this limitation, we propose a Transformer-based nonlinear transform. This transform has the remarkable ability to efficiently capture both local and global information from the input image, leading to a more decorrelated latent representation. In addition, we introduce a novel entropy model that incorporates two different hyperpriors to model cross-channel and spatial dependencies of the latent representation. To further improve the entropy model, we add a global context that leverages distant relationships to predict the current latent more accurately. This global context employs a causal attention mechanism to extract long-range information in a content-dependent manner. Our experiments show that our proposed framework performs better than the state-of-the-art methods in terms of rate-distortion performance.
Prompt-based test-time real image dehazing: a novel pipeline
Oct 08, 2023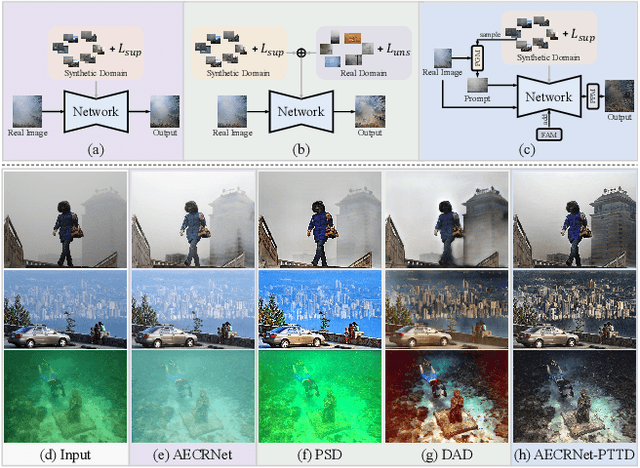
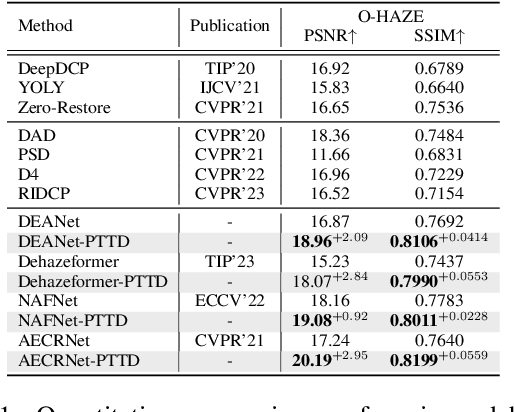

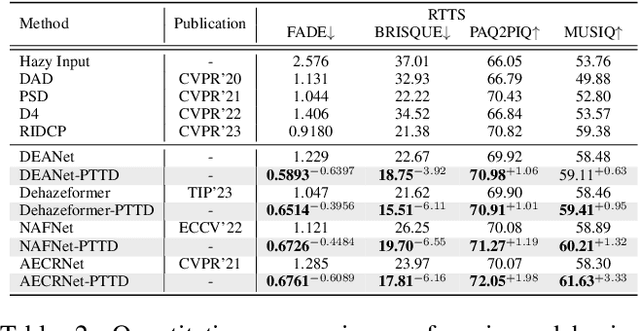
Existing methods attempt to improve models' generalization ability on real-world hazy images by exploring well-designed training schemes (e.g., cycleGAN, prior loss). However, most of them need very complicated training procedures to achieve satisfactory results. In this work, we present a totally novel testing pipeline called Prompt-based Test-Time Dehazing (PTTD) to help generate visually pleasing results of real-captured hazy images during the inference phase. We experimentally find that given a dehazing model trained on synthetic data, by fine-tuning the statistics (i.e., mean and standard deviation) of encoding features, PTTD is able to narrow the domain gap, boosting the performance of real image dehazing. Accordingly, we first apply a prompt generation module (PGM) to generate a visual prompt, which is the source of appropriate statistical perturbations for mean and standard deviation. And then, we employ the feature adaptation module (FAM) into the existing dehazing models for adjusting the original statistics with the guidance of the generated prompt. Note that, PTTD is model-agnostic and can be equipped with various state-of-the-art dehazing models trained on synthetic hazy-clean pairs. Extensive experimental results demonstrate that our PTTD is flexible meanwhile achieves superior performance against state-of-the-art dehazing methods in real-world scenarios. The source code of our PTTD will be made available at https://github.com/cecret3350/PTTD-Dehazing.