 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
You Only Scan Once: A Dynamic Scene Reconstruction Pipeline for 6-DoF Robotic Grasping of Novel Objects
Apr 04, 2024
In the realm of robotic grasping, achieving accurate and reliable interactions with the environment is a pivotal challenge. Traditional methods of grasp planning methods utilizing partial point clouds derived from depth image often suffer from reduced scene understanding due to occlusion, ultimately impeding their grasping accuracy. Furthermore, scene reconstruction methods have primarily relied upon static techniques, which are susceptible to environment change during manipulation process limits their efficacy in real-time grasping tasks. To address these limitations, this paper introduces a novel two-stage pipeline for dynamic scene reconstruction. In the first stage, our approach takes scene scanning as input to register each target object with mesh reconstruction and novel object pose tracking. In the second stage, pose tracking is still performed to provide object poses in real-time, enabling our approach to transform the reconstructed object point clouds back into the scene. Unlike conventional methodologies, which rely on static scene snapshots, our method continuously captures the evolving scene geometry, resulting in a comprehensive and up-to-date point cloud representation. By circumventing the constraints posed by occlusion, our method enhances the overall grasp planning process and empowers state-of-the-art 6-DoF robotic grasping algorithms to exhibit markedly improved accuracy.
Sparse Concept Bottleneck Models: Gumbel Tricks in Contrastive Learning
Apr 04, 2024We propose a novel architecture and method of explainable classification with Concept Bottleneck Models (CBMs). While SOTA approaches to Image Classification task work as a black box, there is a growing demand for models that would provide interpreted results. Such a models often learn to predict the distribution over class labels using additional description of this target instances, called concepts. However, existing Bottleneck methods have a number of limitations: their accuracy is lower than that of a standard model and CBMs require an additional set of concepts to leverage. We provide a framework for creating Concept Bottleneck Model from pre-trained multi-modal encoder and new CLIP-like architectures. By introducing a new type of layers known as Concept Bottleneck Layers, we outline three methods for training them: with $\ell_1$-loss, contrastive loss and loss function based on Gumbel-Softmax distribution (Sparse-CBM), while final FC layer is still trained with Cross-Entropy. We show a significant increase in accuracy using sparse hidden layers in CLIP-based bottleneck models. Which means that sparse representation of concepts activation vector is meaningful in Concept Bottleneck Models. Moreover, with our Concept Matrix Search algorithm we can improve CLIP predictions on complex datasets without any additional training or fine-tuning. The code is available at: https://github.com/Andron00e/SparseCBM.
Vestibular schwannoma growth prediction from longitudinal MRI by time conditioned neural fields
Apr 04, 2024Vestibular schwannomas (VS) are benign tumors that are generally managed by active surveillance with MRI examination. To further assist clinical decision-making and avoid overtreatment, an accurate prediction of tumor growth based on longitudinal imaging is highly desirable. In this paper, we introduce DeepGrowth, a deep learning method that incorporates neural fields and recurrent neural networks for prospective tumor growth prediction. In the proposed method, each tumor is represented as a signed distance function (SDF) conditioned on a low-dimensional latent code. Unlike previous studies that perform tumor shape prediction directly in the image space, we predict the latent codes instead and then reconstruct future shapes from it. To deal with irregular time intervals, we introduce a time-conditioned recurrent module based on a ConvLSTM and a novel temporal encoding strategy, which enables the proposed model to output varying tumor shapes over time. The experiments on an in-house longitudinal VS dataset showed that the proposed model significantly improved the performance ($\ge 1.6\%$ Dice score and $\ge0.20$ mm 95\% Hausdorff distance), in particular for top 20\% tumors that grow or shrink the most ($\ge 4.6\%$ Dice score and $\ge 0.73$ mm 95\% Hausdorff distance). Our code is available at ~\burl{https://github.com/cyjdswx/DeepGrowth}
Boosting Image Restoration via Priors from Pre-trained Models
Mar 19, 2024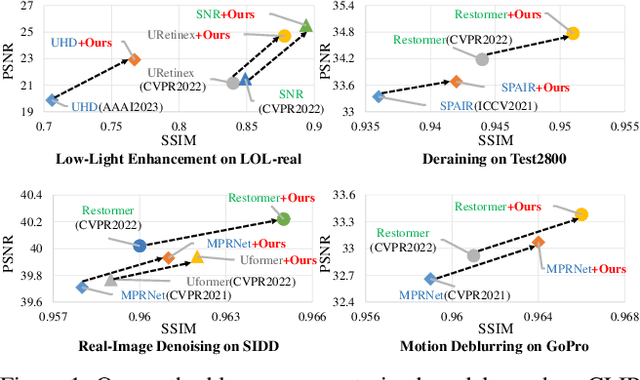

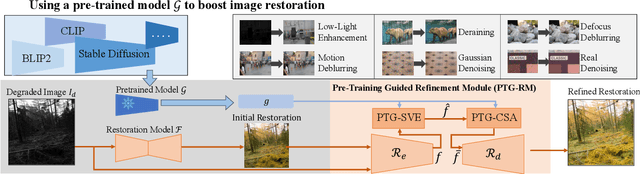
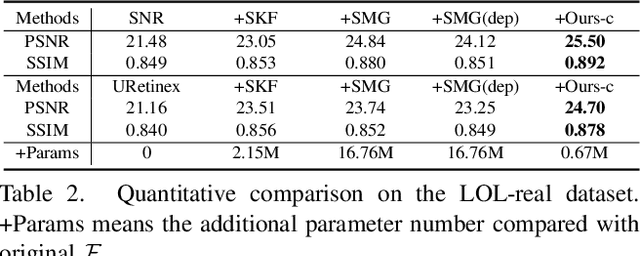
Pre-trained models with large-scale training data, such as CLIP and Stable Diffusion, have demonstrated remarkable performance in various high-level computer vision tasks such as image understanding and generation from language descriptions. Yet, their potential for low-level tasks such as image restoration remains relatively unexplored. In this paper, we explore such models to enhance image restoration. As off-the-shelf features (OSF) from pre-trained models do not directly serve image restoration, we propose to learn an additional lightweight module called Pre-Train-Guided Refinement Module (PTG-RM) to refine restoration results of a target restoration network with OSF. PTG-RM consists of two components, Pre-Train-Guided Spatial-Varying Enhancement (PTG-SVE), and Pre-Train-Guided Channel-Spatial Attention (PTG-CSA). PTG-SVE enables optimal short- and long-range neural operations, while PTG-CSA enhances spatial-channel attention for restoration-related learning. Extensive experiments demonstrate that PTG-RM, with its compact size ($<$1M parameters), effectively enhances restoration performance of various models across different tasks, including low-light enhancement, deraining, deblurring, and denoising.
Moderating Illicit Online Image Promotion for Unsafe User-Generated Content Games Using Large Vision-Language Models
Mar 27, 2024Online user-generated content games (UGCGs) are increasingly popular among children and adolescents for social interaction and more creative online entertainment. However, they pose a heightened risk of exposure to explicit content, raising growing concerns for the online safety of children and adolescents. Despite these concerns, few studies have addressed the issue of illicit image-based promotions of unsafe UGCGs on social media, which can inadvertently attract young users. This challenge arises from the difficulty of obtaining comprehensive training data for UGCG images and the unique nature of these images, which differ from traditional unsafe content. In this work, we take the first step towards studying the threat of illicit promotions of unsafe UGCGs. We collect a real-world dataset comprising 2,924 images that display diverse sexually explicit and violent content used to promote UGCGs by their game creators. Our in-depth studies reveal a new understanding of this problem and the urgent need for automatically flagging illicit UGCG promotions. We additionally create a cutting-edge system, UGCG-Guard, designed to aid social media platforms in effectively identifying images used for illicit UGCG promotions. This system leverages recently introduced large vision-language models (VLMs) and employs a novel conditional prompting strategy for zero-shot domain adaptation, along with chain-of-thought (CoT) reasoning for contextual identification. UGCG-Guard achieves outstanding results, with an accuracy rate of 94% in detecting these images used for the illicit promotion of such games in real-world scenarios.
Text-to-Image Diffusion Models are Great Sketch-Photo Matchmakers
Mar 20, 2024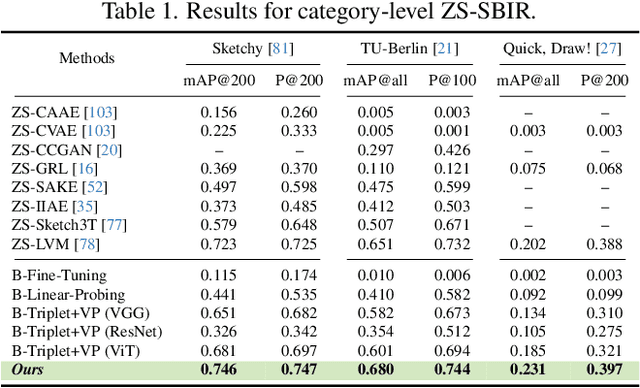
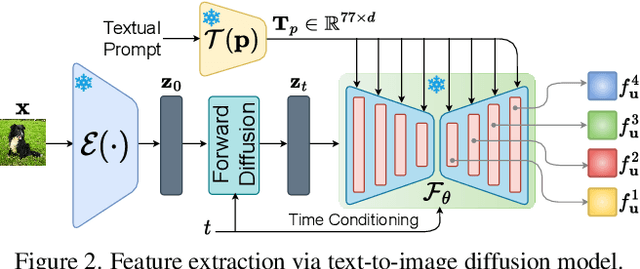


This paper, for the first time, explores text-to-image diffusion models for Zero-Shot Sketch-based Image Retrieval (ZS-SBIR). We highlight a pivotal discovery: the capacity of text-to-image diffusion models to seamlessly bridge the gap between sketches and photos. This proficiency is underpinned by their robust cross-modal capabilities and shape bias, findings that are substantiated through our pilot studies. In order to harness pre-trained diffusion models effectively, we introduce a straightforward yet powerful strategy focused on two key aspects: selecting optimal feature layers and utilising visual and textual prompts. For the former, we identify which layers are most enriched with information and are best suited for the specific retrieval requirements (category-level or fine-grained). Then we employ visual and textual prompts to guide the model's feature extraction process, enabling it to generate more discriminative and contextually relevant cross-modal representations. Extensive experiments on several benchmark datasets validate significant performance improvements.
VXP: Voxel-Cross-Pixel Large-scale Image-LiDAR Place Recognition
Mar 21, 2024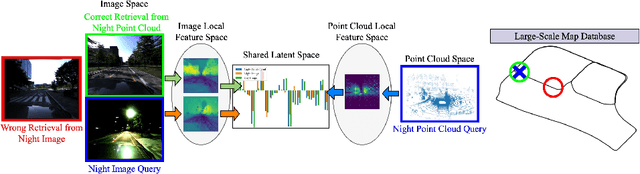

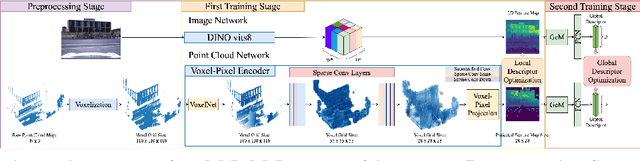
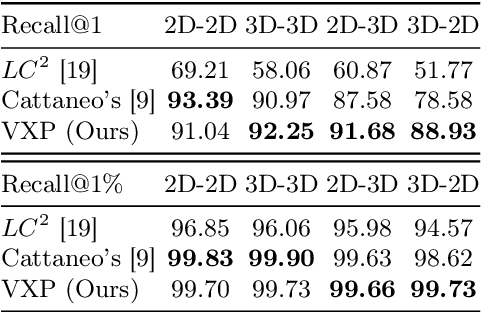
Recent works on the global place recognition treat the task as a retrieval problem, where an off-the-shelf global descriptor is commonly designed in image-based and LiDAR-based modalities. However, it is non-trivial to perform accurate image-LiDAR global place recognition since extracting consistent and robust global descriptors from different domains (2D images and 3D point clouds) is challenging. To address this issue, we propose a novel Voxel-Cross-Pixel (VXP) approach, which establishes voxel and pixel correspondences in a self-supervised manner and brings them into a shared feature space. Specifically, VXP is trained in a two-stage manner that first explicitly exploits local feature correspondences and enforces similarity of global descriptors. Extensive experiments on the three benchmarks (Oxford RobotCar, ViViD++ and KITTI) demonstrate our method surpasses the state-of-the-art cross-modal retrieval by a large margin.
Generative Active Learning for Image Synthesis Personalization
Mar 22, 2024This paper presents a pilot study that explores the application of active learning, traditionally studied in the context of discriminative models, to generative models. We specifically focus on image synthesis personalization tasks. The primary challenge in conducting active learning on generative models lies in the open-ended nature of querying, which differs from the closed form of querying in discriminative models that typically target a single concept. We introduce the concept of anchor directions to transform the querying process into a semi-open problem. We propose a direction-based uncertainty sampling strategy to enable generative active learning and tackle the exploitation-exploration dilemma. Extensive experiments are conducted to validate the effectiveness of our approach, demonstrating that an open-source model can achieve superior performance compared to closed-source models developed by large companies, such as Google's StyleDrop. The source code is available at https://github.com/zhangxulu1996/GAL4Personalization.
AIGCOIQA2024: Perceptual Quality Assessment of AI Generated Omnidirectional Images
Apr 01, 2024In recent years, the rapid advancement of Artificial Intelligence Generated Content (AIGC) has attracted widespread attention. Among the AIGC, AI generated omnidirectional images hold significant potential for Virtual Reality (VR) and Augmented Reality (AR) applications, hence omnidirectional AIGC techniques have also been widely studied. AI-generated omnidirectional images exhibit unique distortions compared to natural omnidirectional images, however, there is no dedicated Image Quality Assessment (IQA) criteria for assessing them. This study addresses this gap by establishing a large-scale AI generated omnidirectional image IQA database named AIGCOIQA2024 and constructing a comprehensive benchmark. We first generate 300 omnidirectional images based on 5 AIGC models utilizing 25 text prompts. A subjective IQA experiment is conducted subsequently to assess human visual preferences from three perspectives including quality, comfortability, and correspondence. Finally, we conduct a benchmark experiment to evaluate the performance of state-of-the-art IQA models on our database. The database will be released to facilitate future research.
LP++: A Surprisingly Strong Linear Probe for Few-Shot CLIP
Apr 02, 2024In a recent, strongly emergent literature on few-shot CLIP adaptation, Linear Probe (LP) has been often reported as a weak baseline. This has motivated intensive research building convoluted prompt learning or feature adaptation strategies. In this work, we propose and examine from convex-optimization perspectives a generalization of the standard LP baseline, in which the linear classifier weights are learnable functions of the text embedding, with class-wise multipliers blending image and text knowledge. As our objective function depends on two types of variables, i.e., the class visual prototypes and the learnable blending parameters, we propose a computationally efficient block coordinate Majorize-Minimize (MM) descent algorithm. In our full-batch MM optimizer, which we coin LP++, step sizes are implicit, unlike standard gradient descent practices where learning rates are intensively searched over validation sets. By examining the mathematical properties of our loss (e.g., Lipschitz gradient continuity), we build majorizing functions yielding data-driven learning rates and derive approximations of the loss's minima, which provide data-informed initialization of the variables. Our image-language objective function, along with these non-trivial optimization insights and ingredients, yields, surprisingly, highly competitive few-shot CLIP performances. Furthermore, LP++ operates in black-box, relaxes intensive validation searches for the optimization hyper-parameters, and runs orders-of-magnitudes faster than state-of-the-art few-shot CLIP adaptation methods. Our code is available at: \url{https://github.com/FereshteShakeri/FewShot-CLIP-Strong-Baseline.git}.