 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
CycleCL: Self-supervised Learning for Periodic Videos
Nov 05, 2023
Analyzing periodic video sequences is a key topic in applications such as automatic production systems, remote sensing, medical applications, or physical training. An example is counting repetitions of a physical exercise. Due to the distinct characteristics of periodic data, self-supervised methods designed for standard image datasets do not capture changes relevant to the progression of the cycle and fail to ignore unrelated noise. They thus do not work well on periodic data. In this paper, we propose CycleCL, a self-supervised learning method specifically designed to work with periodic data. We start from the insight that a good visual representation for periodic data should be sensitive to the phase of a cycle, but be invariant to the exact repetition, i.e. it should generate identical representations for a specific phase throughout all repetitions. We exploit the repetitions in videos to design a novel contrastive learning method based on a triplet loss that optimizes for these desired properties. Our method uses pre-trained features to sample pairs of frames from approximately the same phase and negative pairs of frames from different phases. Then, we iterate between optimizing a feature encoder and resampling triplets, until convergence. By optimizing a model this way, we are able to learn features that have the mentioned desired properties. We evaluate CycleCL on an industrial and multiple human actions datasets, where it significantly outperforms previous video-based self-supervised learning methods on all tasks.
Gradient Domain Diffusion Models for Image Synthesis
Sep 05, 2023Diffusion models are getting popular in generative image and video synthesis. However, due to the diffusion process, they require a large number of steps to converge. To tackle this issue, in this paper, we propose to perform the diffusion process in the gradient domain, where the convergence becomes faster. There are two reasons. First, thanks to the Poisson equation, the gradient domain is mathematically equivalent to the original image domain. Therefore, each diffusion step in the image domain has a unique corresponding gradient domain representation. Second, the gradient domain is much sparser than the image domain. As a result, gradient domain diffusion models converge faster. Several numerical experiments confirm that the gradient domain diffusion models are more efficient than the original diffusion models. The proposed method can be applied in a wide range of applications such as image processing, computer vision and machine learning tasks.
Large Language Models and Multimodal Retrieval for Visual Word Sense Disambiguation
Oct 21, 2023Visual Word Sense Disambiguation (VWSD) is a novel challenging task with the goal of retrieving an image among a set of candidates, which better represents the meaning of an ambiguous word within a given context. In this paper, we make a substantial step towards unveiling this interesting task by applying a varying set of approaches. Since VWSD is primarily a text-image retrieval task, we explore the latest transformer-based methods for multimodal retrieval. Additionally, we utilize Large Language Models (LLMs) as knowledge bases to enhance the given phrases and resolve ambiguity related to the target word. We also study VWSD as a unimodal problem by converting to text-to-text and image-to-image retrieval, as well as question-answering (QA), to fully explore the capabilities of relevant models. To tap into the implicit knowledge of LLMs, we experiment with Chain-of-Thought (CoT) prompting to guide explainable answer generation. On top of all, we train a learn to rank (LTR) model in order to combine our different modules, achieving competitive ranking results. Extensive experiments on VWSD demonstrate valuable insights to effectively drive future directions.
Mask Propagation for Efficient Video Semantic Segmentation
Oct 29, 2023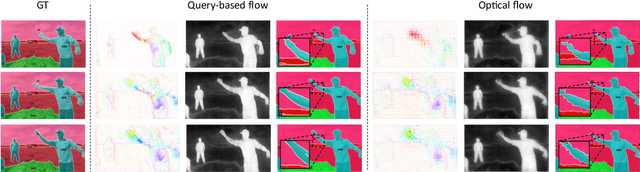
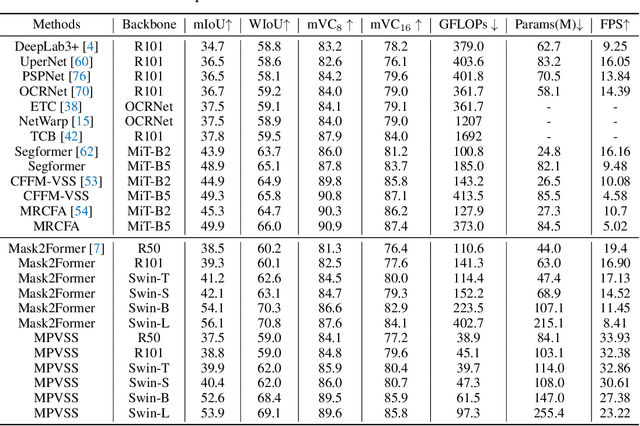
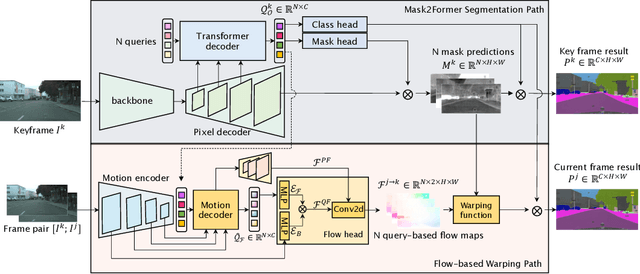
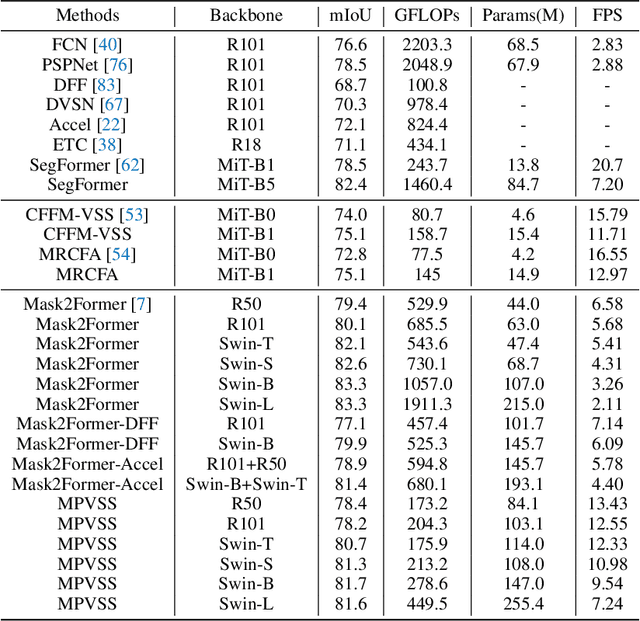
Video Semantic Segmentation (VSS) involves assigning a semantic label to each pixel in a video sequence. Prior work in this field has demonstrated promising results by extending image semantic segmentation models to exploit temporal relationships across video frames; however, these approaches often incur significant computational costs. In this paper, we propose an efficient mask propagation framework for VSS, called MPVSS. Our approach first employs a strong query-based image segmentor on sparse key frames to generate accurate binary masks and class predictions. We then design a flow estimation module utilizing the learned queries to generate a set of segment-aware flow maps, each associated with a mask prediction from the key frame. Finally, the mask-flow pairs are warped to serve as the mask predictions for the non-key frames. By reusing predictions from key frames, we circumvent the need to process a large volume of video frames individually with resource-intensive segmentors, alleviating temporal redundancy and significantly reducing computational costs. Extensive experiments on VSPW and Cityscapes demonstrate that our mask propagation framework achieves SOTA accuracy and efficiency trade-offs. For instance, our best model with Swin-L backbone outperforms the SOTA MRCFA using MiT-B5 by 4.0% mIoU, requiring only 26% FLOPs on the VSPW dataset. Moreover, our framework reduces up to 4x FLOPs compared to the per-frame Mask2Former baseline with only up to 2% mIoU degradation on the Cityscapes validation set. Code is available at https://github.com/ziplab/MPVSS.
Uncovering Prototypical Knowledge for Weakly Open-Vocabulary Semantic Segmentation
Oct 29, 2023This paper studies the problem of weakly open-vocabulary semantic segmentation (WOVSS), which learns to segment objects of arbitrary classes using mere image-text pairs. Existing works turn to enhance the vanilla vision transformer by introducing explicit grouping recognition, i.e., employing several group tokens/centroids to cluster the image tokens and perform the group-text alignment. Nevertheless, these methods suffer from a granularity inconsistency regarding the usage of group tokens, which are aligned in the all-to-one v.s. one-to-one manners during the training and inference phases, respectively. We argue that this discrepancy arises from the lack of elaborate supervision for each group token. To bridge this granularity gap, this paper explores explicit supervision for the group tokens from the prototypical knowledge. To this end, this paper proposes the non-learnable prototypical regularization (NPR) where non-learnable prototypes are estimated from source features to serve as supervision and enable contrastive matching of the group tokens. This regularization encourages the group tokens to segment objects with less redundancy and capture more comprehensive semantic regions, leading to increased compactness and richness. Based on NPR, we propose the prototypical guidance segmentation network (PGSeg) that incorporates multi-modal regularization by leveraging prototypical sources from both images and texts at different levels, progressively enhancing the segmentation capability with diverse prototypical patterns. Experimental results show that our proposed method achieves state-of-the-art performance on several benchmark datasets. The source code is available at https://github.com/Ferenas/PGSeg.
Enhancing Document Information Analysis with Multi-Task Pre-training: A Robust Approach for Information Extraction in Visually-Rich Documents
Oct 25, 2023This paper introduces a deep learning model tailored for document information analysis, emphasizing document classification, entity relation extraction, and document visual question answering. The proposed model leverages transformer-based models to encode all the information present in a document image, including textual, visual, and layout information. The model is pre-trained and subsequently fine-tuned for various document image analysis tasks. The proposed model incorporates three additional tasks during the pre-training phase, including reading order identification of different layout segments in a document image, layout segments categorization as per PubLayNet, and generation of the text sequence within a given layout segment (text block). The model also incorporates a collective pre-training scheme where losses of all the tasks under consideration, including pre-training and fine-tuning tasks with all datasets, are considered. Additional encoder and decoder blocks are added to the RoBERTa network to generate results for all tasks. The proposed model achieved impressive results across all tasks, with an accuracy of 95.87% on the RVL-CDIP dataset for document classification, F1 scores of 0.9306, 0.9804, 0.9794, and 0.8742 on the FUNSD, CORD, SROIE, and Kleister-NDA datasets respectively for entity relation extraction, and an ANLS score of 0.8468 on the DocVQA dataset for visual question answering. The results highlight the effectiveness of the proposed model in understanding and interpreting complex document layouts and content, making it a promising tool for document analysis tasks.
CommIN: Semantic Image Communications as an Inverse Problem with INN-Guided Diffusion Models
Oct 02, 2023Joint source-channel coding schemes based on deep neural networks (DeepJSCC) have recently achieved remarkable performance for wireless image transmission. However, these methods usually focus only on the distortion of the reconstructed signal at the receiver side with respect to the source at the transmitter side, rather than the perceptual quality of the reconstruction which carries more semantic information. As a result, severe perceptual distortion can be introduced under extreme conditions such as low bandwidth and low signal-to-noise ratio. In this work, we propose CommIN, which views the recovery of high-quality source images from degraded reconstructions as an inverse problem. To address this, CommIN combines Invertible Neural Networks (INN) with diffusion models, aiming for superior perceptual quality. Through experiments, we show that our CommIN significantly improves the perceptual quality compared to DeepJSCC under extreme conditions and outperforms other inverse problem approaches used in DeepJSCC.
DreamStyler: Paint by Style Inversion with Text-to-Image Diffusion Models
Sep 13, 2023
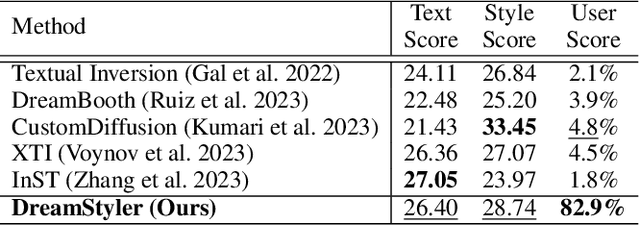
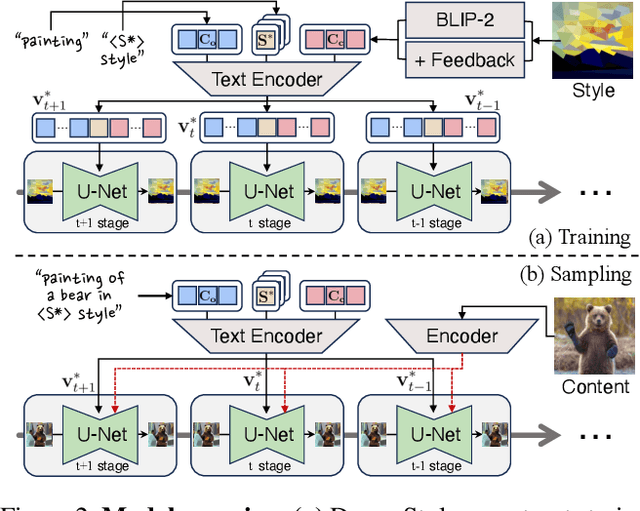
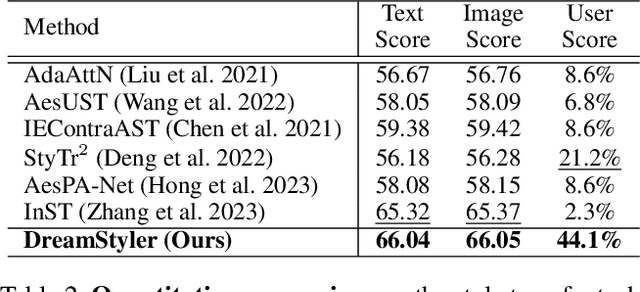
Recent progresses in large-scale text-to-image models have yielded remarkable accomplishments, finding various applications in art domain. However, expressing unique characteristics of an artwork (e.g. brushwork, colortone, or composition) with text prompts alone may encounter limitations due to the inherent constraints of verbal description. To this end, we introduce DreamStyler, a novel framework designed for artistic image synthesis, proficient in both text-to-image synthesis and style transfer. DreamStyler optimizes a multi-stage textual embedding with a context-aware text prompt, resulting in prominent image quality. In addition, with content and style guidance, DreamStyler exhibits flexibility to accommodate a range of style references. Experimental results demonstrate its superior performance across multiple scenarios, suggesting its promising potential in artistic product creation.
DiffI2I: Efficient Diffusion Model for Image-to-Image Translation
Aug 26, 2023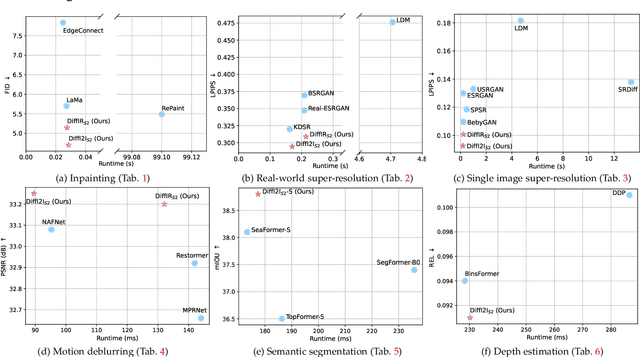
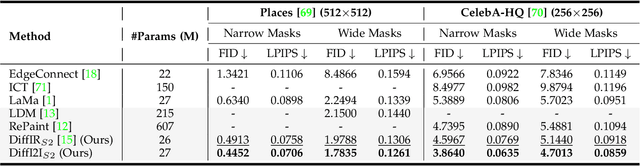
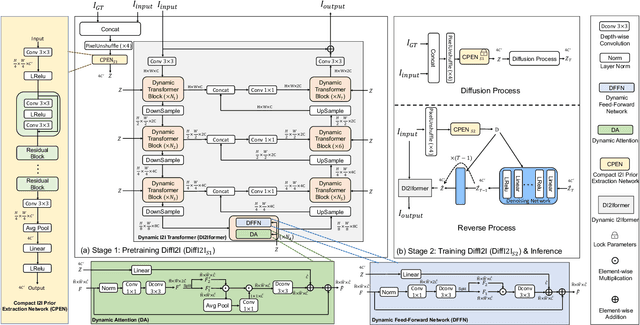

The Diffusion Model (DM) has emerged as the SOTA approach for image synthesis. However, the existing DM cannot perform well on some image-to-image translation (I2I) tasks. Different from image synthesis, some I2I tasks, such as super-resolution, require generating results in accordance with GT images. Traditional DMs for image synthesis require extensive iterations and large denoising models to estimate entire images, which gives their strong generative ability but also leads to artifacts and inefficiency for I2I. To tackle this challenge, we propose a simple, efficient, and powerful DM framework for I2I, called DiffI2I. Specifically, DiffI2I comprises three key components: a compact I2I prior extraction network (CPEN), a dynamic I2I transformer (DI2Iformer), and a denoising network. We train DiffI2I in two stages: pretraining and DM training. For pretraining, GT and input images are fed into CPEN$_{S1}$ to capture a compact I2I prior representation (IPR) guiding DI2Iformer. In the second stage, the DM is trained to only use the input images to estimate the same IRP as CPEN$_{S1}$. Compared to traditional DMs, the compact IPR enables DiffI2I to obtain more accurate outcomes and employ a lighter denoising network and fewer iterations. Through extensive experiments on various I2I tasks, we demonstrate that DiffI2I achieves SOTA performance while significantly reducing computational burdens.
NICE: CVPR 2023 Challenge on Zero-shot Image Captioning
Sep 11, 2023
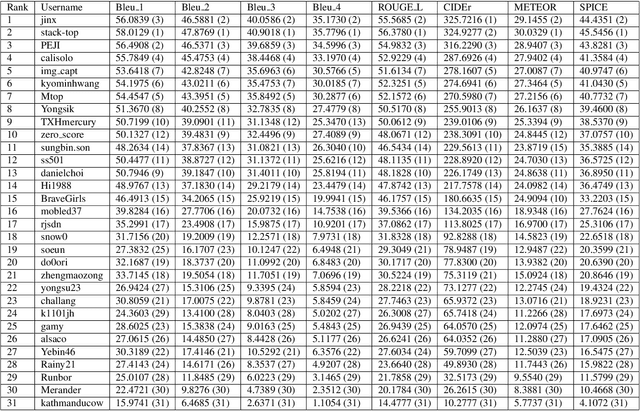
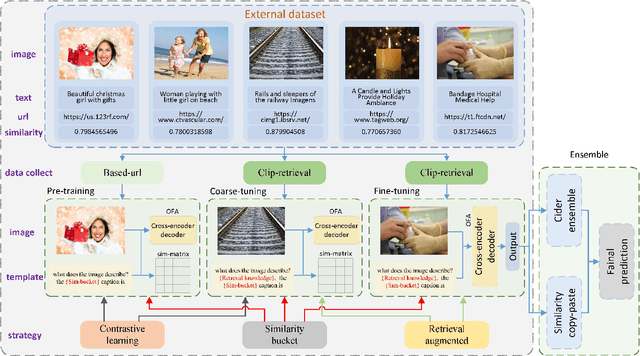
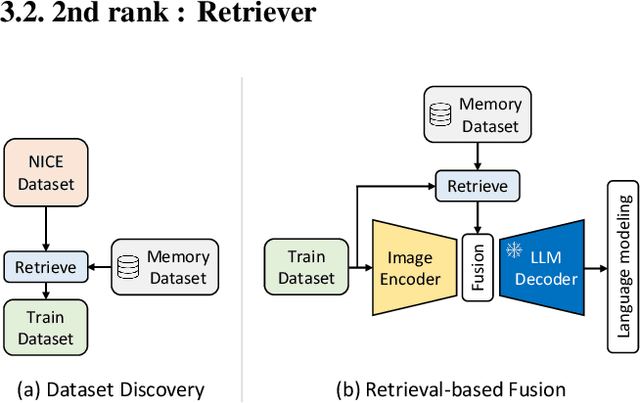
In this report, we introduce NICE (New frontiers for zero-shot Image Captioning Evaluation) project and share the results and outcomes of 2023 challenge. This project is designed to challenge the computer vision community to develop robust image captioning models that advance the state-of-the-art both in terms of accuracy and fairness. Through the challenge, the image captioning models were tested using a new evaluation dataset that includes a large variety of visual concepts from many domains. There was no specific training data provided for the challenge, and therefore the challenge entries were required to adapt to new types of image descriptions that had not been seen during training. This report includes information on the newly proposed NICE dataset, evaluation methods, challenge results, and technical details of top-ranking entries. We expect that the outcomes of the challenge will contribute to the improvement of AI models on various vision-language tasks.