 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
SAMCLR: Contrastive pre-training on complex scenes using SAM for view sampling
Oct 29, 2023
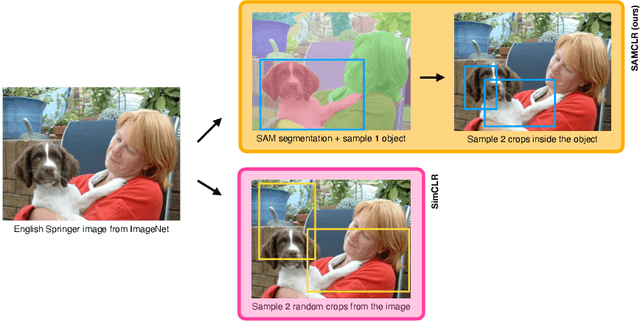
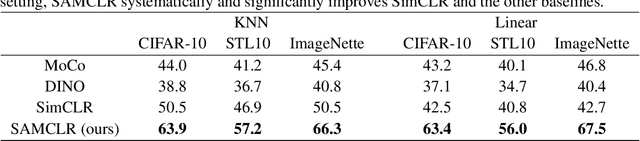
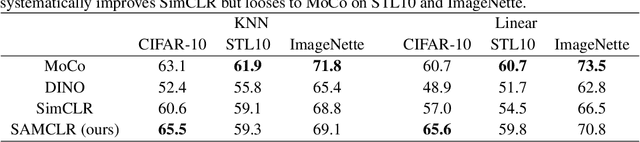
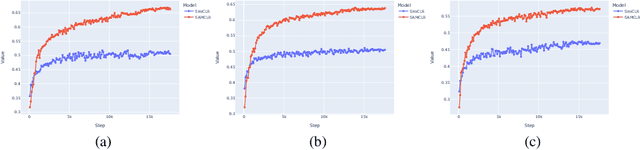
In Computer Vision, self-supervised contrastive learning enforces similar representations between different views of the same image. The pre-training is most often performed on image classification datasets, like ImageNet, where images mainly contain a single class of objects. However, when dealing with complex scenes with multiple items, it becomes very unlikely for several views of the same image to represent the same object category. In this setting, we propose SAMCLR, an add-on to SimCLR which uses SAM to segment the image into semantic regions, then sample the two views from the same region. Preliminary results show empirically that when pre-training on Cityscapes and ADE20K, then evaluating on classification on CIFAR-10, STL10 and ImageNette, SAMCLR performs at least on par with, and most often significantly outperforms not only SimCLR, but also DINO and MoCo.
Enriching Phrases with Coupled Pixel and Object Contexts for Panoptic Narrative Grounding
Nov 02, 2023Panoptic narrative grounding (PNG) aims to segment things and stuff objects in an image described by noun phrases of a narrative caption. As a multimodal task, an essential aspect of PNG is the visual-linguistic interaction between image and caption. The previous two-stage method aggregates visual contexts from offline-generated mask proposals to phrase features, which tend to be noisy and fragmentary. The recent one-stage method aggregates only pixel contexts from image features to phrase features, which may incur semantic misalignment due to lacking object priors. To realize more comprehensive visual-linguistic interaction, we propose to enrich phrases with coupled pixel and object contexts by designing a Phrase-Pixel-Object Transformer Decoder (PPO-TD), where both fine-grained part details and coarse-grained entity clues are aggregated to phrase features. In addition, we also propose a PhraseObject Contrastive Loss (POCL) to pull closer the matched phrase-object pairs and push away unmatched ones for aggregating more precise object contexts from more phrase-relevant object tokens. Extensive experiments on the PNG benchmark show our method achieves new state-of-the-art performance with large margins.
TextCLIP: Text-Guided Face Image Generation And Manipulation Without Adversarial Training
Sep 21, 2023


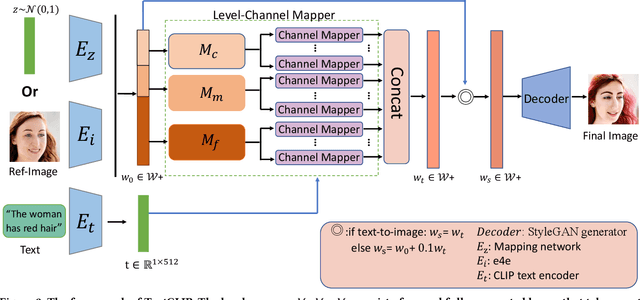
Text-guided image generation aimed to generate desired images conditioned on given texts, while text-guided image manipulation refers to semantically edit parts of a given image based on specified texts. For these two similar tasks, the key point is to ensure image fidelity as well as semantic consistency. Many previous approaches require complex multi-stage generation and adversarial training, while struggling to provide a unified framework for both tasks. In this work, we propose TextCLIP, a unified framework for text-guided image generation and manipulation without adversarial training. The proposed method accepts input from images or random noise corresponding to these two different tasks, and under the condition of the specific texts, a carefully designed mapping network that exploits the powerful generative capabilities of StyleGAN and the text image representation capabilities of Contrastive Language-Image Pre-training (CLIP) generates images of up to $1024\times1024$ resolution that can currently be generated. Extensive experiments on the Multi-modal CelebA-HQ dataset have demonstrated that our proposed method outperforms existing state-of-the-art methods, both on text-guided generation tasks and manipulation tasks.
Dynamic Task and Weight Prioritization Curriculum Learning for Multimodal Imagery
Nov 07, 2023This paper explores post-disaster analytics using multimodal deep learning models trained with curriculum learning method. Studying post-disaster analytics is important as it plays a crucial role in mitigating the impact of disasters by providing timely and accurate insights into the extent of damage and the allocation of resources. We propose a curriculum learning strategy to enhance the performance of multimodal deep learning models. Curriculum learning emulates the progressive learning sequence in human education by training deep learning models on increasingly complex data. Our primary objective is to develop a curriculum-trained multimodal deep learning model, with a particular focus on visual question answering (VQA) capable of jointly processing image and text data, in conjunction with semantic segmentation for disaster analytics using the FloodNet\footnote{https://github.com/BinaLab/FloodNet-Challenge-EARTHVISION2021} dataset. To achieve this, U-Net model is used for semantic segmentation and image encoding. A custom built text classifier is used for visual question answering. Existing curriculum learning methods rely on manually defined difficulty functions. We introduce a novel curriculum learning approach termed Dynamic Task and Weight Prioritization (DATWEP), which leverages a gradient-based method to automatically decide task difficulty during curriculum learning training, thereby eliminating the need for explicit difficulty computation. The integration of DATWEP into our multimodal model shows improvement on VQA performance. Source code is available at https://github.com/fualsan/DATWEP.
TWIST: Teacher-Student World Model Distillation for Efficient Sim-to-Real Transfer
Nov 07, 2023Model-based RL is a promising approach for real-world robotics due to its improved sample efficiency and generalization capabilities compared to model-free RL. However, effective model-based RL solutions for vision-based real-world applications require bridging the sim-to-real gap for any world model learnt. Due to its significant computational cost, standard domain randomisation does not provide an effective solution to this problem. This paper proposes TWIST (Teacher-Student World Model Distillation for Sim-to-Real Transfer) to achieve efficient sim-to-real transfer of vision-based model-based RL using distillation. Specifically, TWIST leverages state observations as readily accessible, privileged information commonly garnered from a simulator to significantly accelerate sim-to-real transfer. Specifically, a teacher world model is trained efficiently on state information. At the same time, a matching dataset is collected of domain-randomised image observations. The teacher world model then supervises a student world model that takes the domain-randomised image observations as input. By distilling the learned latent dynamics model from the teacher to the student model, TWIST achieves efficient and effective sim-to-real transfer for vision-based model-based RL tasks. Experiments in simulated and real robotics tasks demonstrate that our approach outperforms naive domain randomisation and model-free methods in terms of sample efficiency and task performance of sim-to-real transfer.
Unsupervised convolutional neural network fusion approach for change detection in remote sensing images
Nov 07, 2023With the rapid development of deep learning, a variety of change detection methods based on deep learning have emerged in recent years. However, these methods usually require a large number of training samples to train the network model, so it is very expensive. In this paper, we introduce a completely unsupervised shallow convolutional neural network (USCNN) fusion approach for change detection. Firstly, the bi-temporal images are transformed into different feature spaces by using convolution kernels of different sizes to extract multi-scale information of the images. Secondly, the output features of bi-temporal images at the same convolution kernels are subtracted to obtain the corresponding difference images, and the difference feature images at the same scale are fused into one feature image by using 1 * 1 convolution layer. Finally, the output features of different scales are concatenated and a 1 * 1 convolution layer is used to fuse the multi-scale information of the image. The model parameters are obtained by a redesigned sparse function. Our model has three features: the entire training process is conducted in an unsupervised manner, the network architecture is shallow, and the objective function is sparse. Thus, it can be seen as a kind of lightweight network model. Experimental results on four real remote sensing datasets indicate the feasibility and effectiveness of the proposed approach.
FusionViT: Hierarchical 3D Object Detection via LiDAR-Camera Vision Transformer Fusion
Nov 07, 2023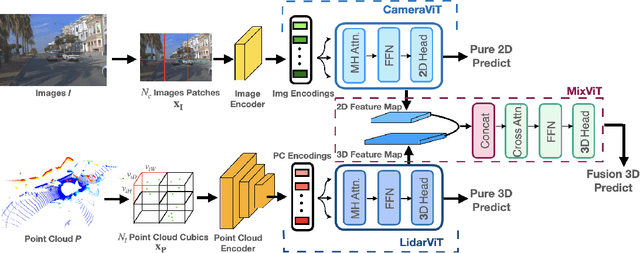
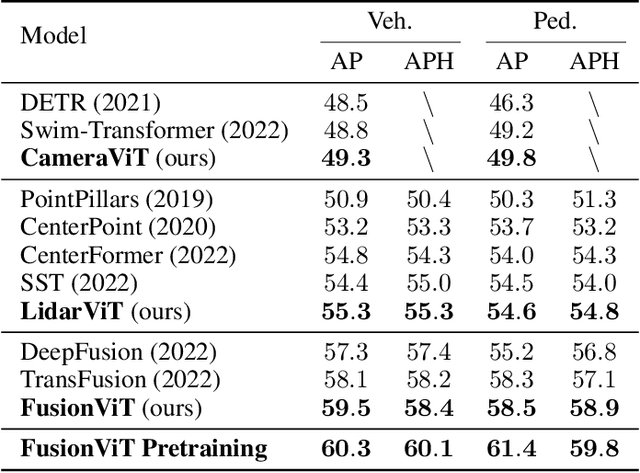
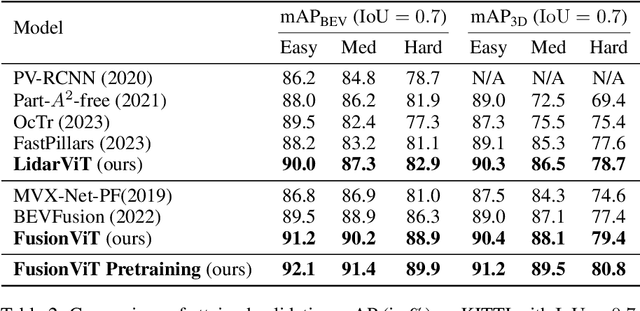

For 3D object detection, both camera and lidar have been demonstrated to be useful sensory devices for providing complementary information about the same scenery with data representations in different modalities, e.g., 2D RGB image vs 3D point cloud. An effective representation learning and fusion of such multi-modal sensor data is necessary and critical for better 3D object detection performance. To solve the problem, in this paper, we will introduce a novel vision transformer-based 3D object detection model, namely FusionViT. Different from the existing 3D object detection approaches, FusionViT is a pure-ViT based framework, which adopts a hierarchical architecture by extending the transformer model to embed both images and point clouds for effective representation learning. Such multi-modal data embedding representations will be further fused together via a fusion vision transformer model prior to feeding the learned features to the object detection head for both detection and localization of the 3D objects in the input scenery. To demonstrate the effectiveness of FusionViT, extensive experiments have been done on real-world traffic object detection benchmark datasets KITTI and Waymo Open. Notably, our FusionViT model can achieve state-of-the-art performance and outperforms not only the existing baseline methods that merely rely on camera images or lidar point clouds, but also the latest multi-modal image-point cloud deep fusion approaches.
Robust deformable image registration using cycle-consistent implicit representations
Oct 03, 2023Recent works in medical image registration have proposed the use of Implicit Neural Representations, demonstrating performance that rivals state-of-the-art learning-based methods. However, these implicit representations need to be optimized for each new image pair, which is a stochastic process that may fail to converge to a global minimum. To improve robustness, we propose a deformable registration method using pairs of cycle-consistent Implicit Neural Representations: each implicit representation is linked to a second implicit representation that estimates the opposite transformation, causing each network to act as a regularizer for its paired opposite. During inference, we generate multiple deformation estimates by numerically inverting the paired backward transformation and evaluating the consensus of the optimized pair. This consensus improves registration accuracy over using a single representation and results in a robust uncertainty metric that can be used for automatic quality control. We evaluate our method with a 4D lung CT dataset. The proposed cycle-consistent optimization method reduces the optimization failure rate from 2.4% to 0.0% compared to the current state-of-the-art. The proposed inference method improves landmark accuracy by 4.5% and the proposed uncertainty metric detects all instances where the registration method fails to converge to a correct solution. We verify the generalizability of these results to other data using a centerline propagation task in abdominal 4D MRI, where our method achieves a 46% improvement in propagation consistency compared with single-INR registration and demonstrates a strong correlation between the proposed uncertainty metric and registration accuracy.
An Evaluation of Forensic Facial Recognition
Nov 10, 2023

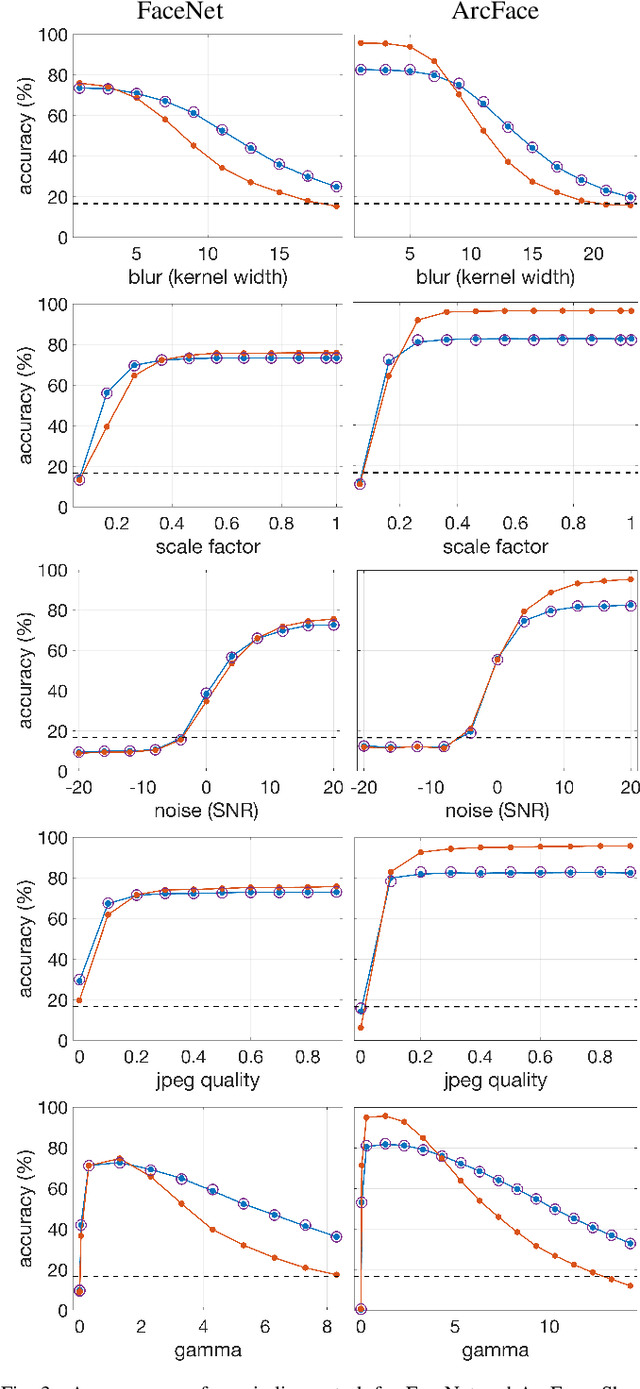
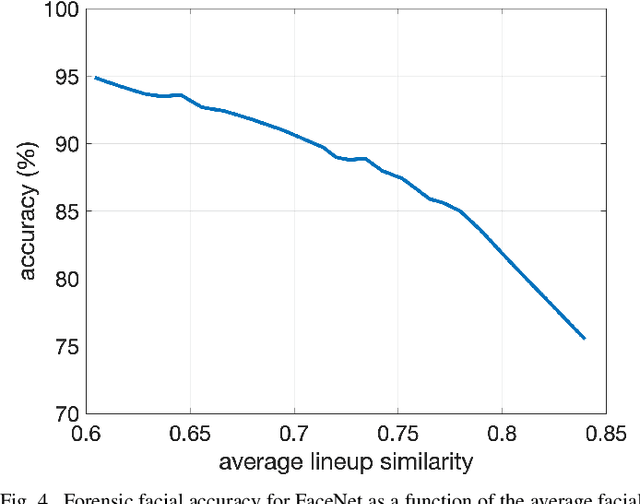
Recent advances in machine learning and computer vision have led to reported facial recognition accuracies surpassing human performance. We question if these systems will translate to real-world forensic scenarios in which a potentially low-resolution, low-quality, partially-occluded image is compared against a standard facial database. We describe the construction of a large-scale synthetic facial dataset along with a controlled facial forensic lineup, the combination of which allows for a controlled evaluation of facial recognition under a range of real-world conditions. Using this synthetic dataset, and a popular dataset of real faces, we evaluate the accuracy of two popular neural-based recognition systems. We find that previously reported face recognition accuracies of more than 95% drop to as low as 65% in this more challenging forensic scenario.
VideoCrafter1: Open Diffusion Models for High-Quality Video Generation
Oct 30, 2023Video generation has increasingly gained interest in both academia and industry. Although commercial tools can generate plausible videos, there is a limited number of open-source models available for researchers and engineers. In this work, we introduce two diffusion models for high-quality video generation, namely text-to-video (T2V) and image-to-video (I2V) models. T2V models synthesize a video based on a given text input, while I2V models incorporate an additional image input. Our proposed T2V model can generate realistic and cinematic-quality videos with a resolution of $1024 \times 576$, outperforming other open-source T2V models in terms of quality. The I2V model is designed to produce videos that strictly adhere to the content of the provided reference image, preserving its content, structure, and style. This model is the first open-source I2V foundation model capable of transforming a given image into a video clip while maintaining content preservation constraints. We believe that these open-source video generation models will contribute significantly to the technological advancements within the community.