 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Nucleus-aware Self-supervised Pretraining Using Unpaired Image-to-image Translation for Histopathology Images
Sep 14, 2023

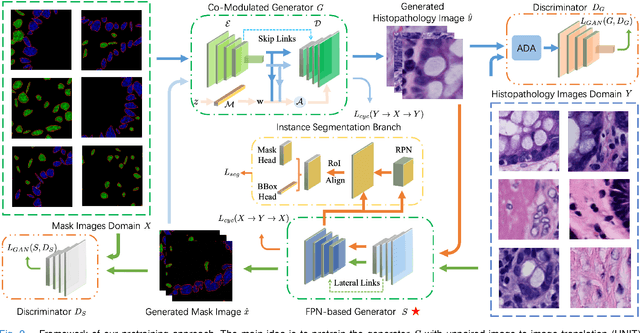
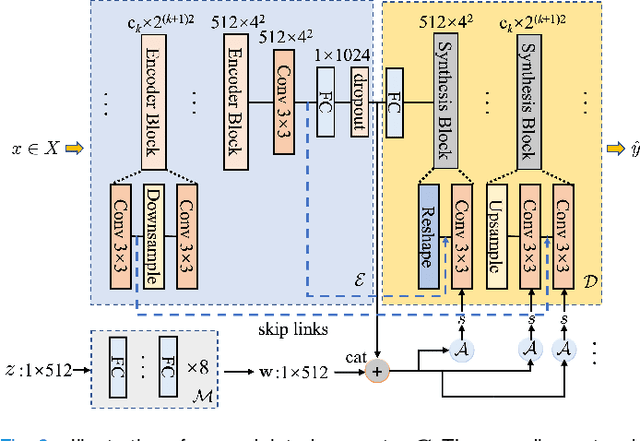
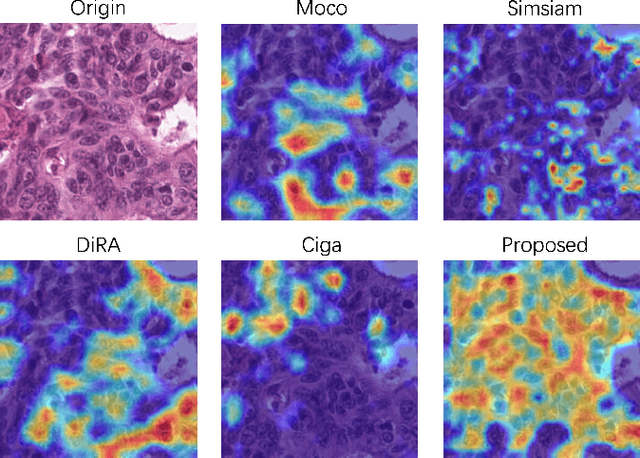
Self-supervised pretraining attempts to enhance model performance by obtaining effective features from unlabeled data, and has demonstrated its effectiveness in the field of histopathology images. Despite its success, few works concentrate on the extraction of nucleus-level information, which is essential for pathologic analysis. In this work, we propose a novel nucleus-aware self-supervised pretraining framework for histopathology images. The framework aims to capture the nuclear morphology and distribution information through unpaired image-to-image translation between histopathology images and pseudo mask images. The generation process is modulated by both conditional and stochastic style representations, ensuring the reality and diversity of the generated histopathology images for pretraining. Further, an instance segmentation guided strategy is employed to capture instance-level information. The experiments on 7 datasets show that the proposed pretraining method outperforms supervised ones on Kather classification, multiple instance learning, and 5 dense-prediction tasks with the transfer learning protocol, and yields superior results than other self-supervised approaches on 8 semi-supervised tasks. Our project is publicly available at https://github.com/zhiyuns/UNITPathSSL.
H-NeXt: The next step towards roto-translation invariant networks
Nov 02, 2023The widespread popularity of equivariant networks underscores the significance of parameter efficient models and effective use of training data. At a time when robustness to unseen deformations is becoming increasingly important, we present H-NeXt, which bridges the gap between equivariance and invariance. H-NeXt is a parameter-efficient roto-translation invariant network that is trained without a single augmented image in the training set. Our network comprises three components: an equivariant backbone for learning roto-translation independent features, an invariant pooling layer for discarding roto-translation information, and a classification layer. H-NeXt outperforms the state of the art in classification on unaugmented training sets and augmented test sets of MNIST and CIFAR-10.
SILC: Improving Vision Language Pretraining with Self-Distillation
Oct 20, 2023Image-Text pretraining on web-scale image caption dataset has become the default recipe for open vocabulary classification and retrieval models thanks to the success of CLIP and its variants. Several works have also used CLIP features for dense prediction tasks and have shown the emergence of open-set abilities. However, the contrastive objective only focuses on image-text alignment and does not incentivise image feature learning for dense prediction tasks. In this work, we propose the simple addition of local-to-global correspondence learning by self-distillation as an additional objective for contrastive pre-training to propose SILC. We show that distilling local image features from an exponential moving average (EMA) teacher model significantly improves model performance on several computer vision tasks including classification, retrieval, and especially segmentation. We further show that SILC scales better with the same training duration compared to the baselines. Our model SILC sets a new state of the art for zero-shot classification, few shot classification, image and text retrieval, zero-shot segmentation, and open vocabulary segmentation.
Boosting High Resolution Image Classification with Scaling-up Transformers
Sep 26, 2023
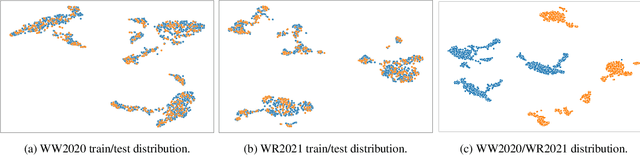
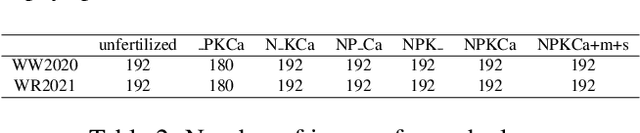
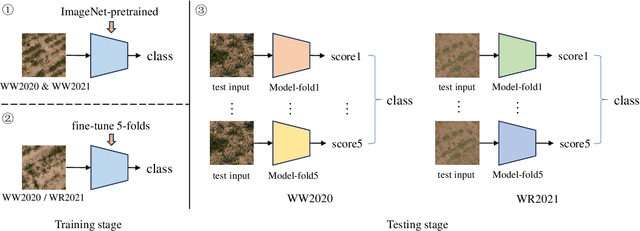
We present a holistic approach for high resolution image classification that won second place in the ICCV/CVPPA2023 Deep Nutrient Deficiency Challenge. The approach consists of a full pipeline of: 1) data distribution analysis to check potential domain shift, 2) backbone selection for a strong baseline model that scales up for high resolution input, 3) transfer learning that utilizes published pretrained models and continuous fine-tuning on small sub-datasets, 4) data augmentation for the diversity of training data and to prevent overfitting, 5) test-time augmentation to improve the prediction's robustness, and 6) "data soups" that conducts cross-fold model prediction average for smoothened final test results.
PHD: Pixel-Based Language Modeling of Historical Documents
Nov 04, 2023The digitisation of historical documents has provided historians with unprecedented research opportunities. Yet, the conventional approach to analysing historical documents involves converting them from images to text using OCR, a process that overlooks the potential benefits of treating them as images and introduces high levels of noise. To bridge this gap, we take advantage of recent advancements in pixel-based language models trained to reconstruct masked patches of pixels instead of predicting token distributions. Due to the scarcity of real historical scans, we propose a novel method for generating synthetic scans to resemble real historical documents. We then pre-train our model, PHD, on a combination of synthetic scans and real historical newspapers from the 1700-1900 period. Through our experiments, we demonstrate that PHD exhibits high proficiency in reconstructing masked image patches and provide evidence of our model's noteworthy language understanding capabilities. Notably, we successfully apply our model to a historical QA task, highlighting its usefulness in this domain.
Tracking and fast imaging of a translational object via Fourier modulation
Oct 28, 2023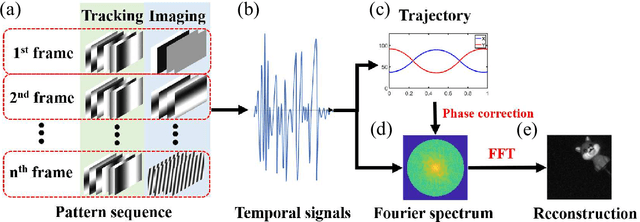
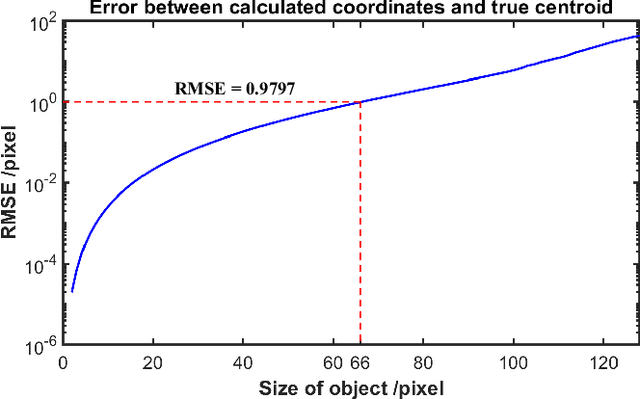
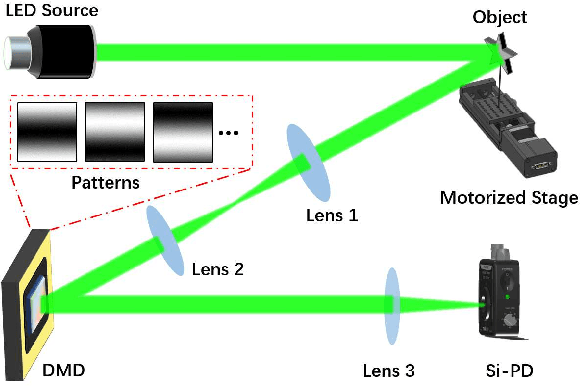

The tracking and imaging of high-speed moving objects hold significant promise for application in various fields. Single-pixel imaging enables the progressive capture of a fast-moving translational object through motion compensation. However, achieving a balance between a short reconstruction time and a good image quality is challenging. In this study, we present a approach that simultaneously incorporates position encoding and spatial information encoding through the Fourier patterns. The utilization of Fourier patterns with specific spatial frequencies ensures robust and accurate object localization. By exploiting the properties of the Fourier transform, our method achieves a remarkable reduction in time complexity and memory consumption while significantly enhancing image quality. Furthermore, we introduce an optimized sampling strategy specifically tailored for small moving objects, significantly reducing the required dwell time for imaging. The proposed method provides a practical solution for the real-time tracking, imaging and edge detection of translational objects, underscoring its considerable potential for diverse applications.
Leveraging Large-Scale Pretrained Vision Foundation Models for Label-Efficient 3D Point Cloud Segmentation
Nov 06, 2023Recently, large-scale pre-trained models such as Segment-Anything Model (SAM) and Contrastive Language-Image Pre-training (CLIP) have demonstrated remarkable success and revolutionized the field of computer vision. These foundation vision models effectively capture knowledge from a large-scale broad data with their vast model parameters, enabling them to perform zero-shot segmentation on previously unseen data without additional training. While they showcase competence in 2D tasks, their potential for enhancing 3D scene understanding remains relatively unexplored. To this end, we present a novel framework that adapts various foundational models for the 3D point cloud segmentation task. Our approach involves making initial predictions of 2D semantic masks using different large vision models. We then project these mask predictions from various frames of RGB-D video sequences into 3D space. To generate robust 3D semantic pseudo labels, we introduce a semantic label fusion strategy that effectively combines all the results via voting. We examine diverse scenarios, like zero-shot learning and limited guidance from sparse 2D point labels, to assess the pros and cons of different vision foundation models. Our approach is experimented on ScanNet dataset for 3D indoor scenes, and the results demonstrate the effectiveness of adopting general 2D foundation models on solving 3D point cloud segmentation tasks.
SEINE: Short-to-Long Video Diffusion Model for Generative Transition and Prediction
Nov 06, 2023Recently video generation has achieved substantial progress with realistic results. Nevertheless, existing AI-generated videos are usually very short clips ("shot-level") depicting a single scene. To deliver a coherent long video ("story-level"), it is desirable to have creative transition and prediction effects across different clips. This paper presents a short-to-long video diffusion model, SEINE, that focuses on generative transition and prediction. The goal is to generate high-quality long videos with smooth and creative transitions between scenes and varying lengths of shot-level videos. Specifically, we propose a random-mask video diffusion model to automatically generate transitions based on textual descriptions. By providing the images of different scenes as inputs, combined with text-based control, our model generates transition videos that ensure coherence and visual quality. Furthermore, the model can be readily extended to various tasks such as image-to-video animation and autoregressive video prediction. To conduct a comprehensive evaluation of this new generative task, we propose three assessing criteria for smooth and creative transition: temporal consistency, semantic similarity, and video-text semantic alignment. Extensive experiments validate the effectiveness of our approach over existing methods for generative transition and prediction, enabling the creation of story-level long videos. Project page: https://vchitect.github.io/SEINE-project/ .
A Comprehensive Study of GPT-4V's Multimodal Capabilities in Medical Imaging
Nov 06, 2023This paper presents a comprehensive evaluation of GPT-4V's capabilities across diverse medical imaging tasks, including Radiology Report Generation, Medical Visual Question Answering (VQA), and Visual Grounding. While prior efforts have explored GPT-4V's performance in medical image analysis, to the best of our knowledge, our study represents the first quantitative evaluation on publicly available benchmarks. Our findings highlight GPT-4V's potential in generating descriptive reports for chest X-ray images, particularly when guided by well-structured prompts. Meanwhile, its performance on the MIMIC-CXR dataset benchmark reveals areas for improvement in certain evaluation metrics, such as CIDEr. In the domain of Medical VQA, GPT-4V demonstrates proficiency in distinguishing between question types but falls short of the VQA-RAD benchmark in terms of accuracy. Furthermore, our analysis finds the limitations of conventional evaluation metrics like the BLEU scores, advocating for the development of more semantically robust assessment methods. In the field of Visual Grounding, GPT-4V exhibits preliminary promise in recognizing bounding boxes, but its precision is lacking, especially in identifying specific medical organs and signs. Our evaluation underscores the significant potential of GPT-4V in the medical imaging domain, while also emphasizing the need for targeted refinements to fully unlock its capabilities.
Pelvic floor MRI segmentation based on semi-supervised deep learning
Nov 06, 2023The semantic segmentation of pelvic organs via MRI has important clinical significance. Recently, deep learning-enabled semantic segmentation has facilitated the three-dimensional geometric reconstruction of pelvic floor organs, providing clinicians with accurate and intuitive diagnostic results. However, the task of labeling pelvic floor MRI segmentation, typically performed by clinicians, is labor-intensive and costly, leading to a scarcity of labels. Insufficient segmentation labels limit the precise segmentation and reconstruction of pelvic floor organs. To address these issues, we propose a semi-supervised framework for pelvic organ segmentation. The implementation of this framework comprises two stages. In the first stage, it performs self-supervised pre-training using image restoration tasks. Subsequently, fine-tuning of the self-supervised model is performed, using labeled data to train the segmentation model. In the second stage, the self-supervised segmentation model is used to generate pseudo labels for unlabeled data. Ultimately, both labeled and unlabeled data are utilized in semi-supervised training. Upon evaluation, our method significantly enhances the performance in the semantic segmentation and geometric reconstruction of pelvic organs, Dice coefficient can increase by 2.65% averagely. Especially for organs that are difficult to segment, such as the uterus, the accuracy of semantic segmentation can be improved by up to 3.70%.