 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
A Dual Attentive Generative Adversarial Network for Remote Sensing Image Change Detection
Oct 03, 2023
Remote sensing change detection between bi-temporal images receives growing concentration from researchers. However, comparing two bi-temporal images for detecting changes is challenging, as they demonstrate different appearances. In this paper, we propose a dual attentive generative adversarial network for achieving very high-resolution remote sensing image change detection tasks, which regards the detection model as a generator and attains the optimal weights of the detection model without increasing the parameters of the detection model through generative-adversarial strategy, boosting the spatial contiguity of predictions. Moreover, We design a multi-level feature extractor for effectively fusing multi-level features, which adopts the pre-trained model to extract multi-level features from bi-temporal images and introduces aggregate connections to fuse them. To strengthen the identification of multi-scale objects, we propose a multi-scale adaptive fusion module to adaptively fuse multi-scale features through various receptive fields and design a context refinement module to explore contextual dependencies. Moreover, the DAGAN framework utilizes the 4-layer convolution network as a discriminator to identify whether the synthetic image is fake or real. Extensive experiments represent that the DAGAN framework has better performance with 85.01% mean IoU and 91.48% mean F1 score than advanced methods on the LEVIR dataset.
PAUMER: Patch Pausing Transformer for Semantic Segmentation
Nov 01, 2023We study the problem of improving the efficiency of segmentation transformers by using disparate amounts of computation for different parts of the image. Our method, PAUMER, accomplishes this by pausing computation for patches that are deemed to not need any more computation before the final decoder. We use the entropy of predictions computed from intermediate activations as the pausing criterion, and find this aligns well with semantics of the image. Our method has a unique advantage that a single network trained with the proposed strategy can be effortlessly adapted at inference to various run-time requirements by modulating its pausing parameters. On two standard segmentation datasets, Cityscapes and ADE20K, we show that our method operates with about a $50\%$ higher throughput with an mIoU drop of about $0.65\%$ and $4.6\%$ respectively.
Consistent123: One Image to Highly Consistent 3D Asset Using Case-Aware Diffusion Priors
Sep 29, 2023
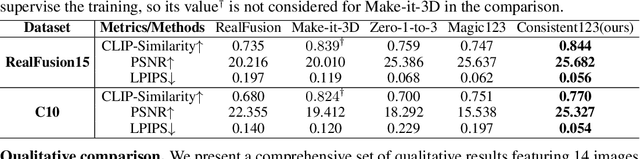

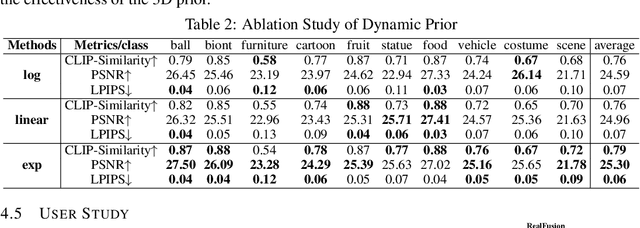
Reconstructing 3D objects from a single image guided by pretrained diffusion models has demonstrated promising outcomes. However, due to utilizing the case-agnostic rigid strategy, their generalization ability to arbitrary cases and the 3D consistency of reconstruction are still poor. In this work, we propose Consistent123, a case-aware two-stage method for highly consistent 3D asset reconstruction from one image with both 2D and 3D diffusion priors. In the first stage, Consistent123 utilizes only 3D structural priors for sufficient geometry exploitation, with a CLIP-based case-aware adaptive detection mechanism embedded within this process. In the second stage, 2D texture priors are introduced and progressively take on a dominant guiding role, delicately sculpting the details of the 3D model. Consistent123 aligns more closely with the evolving trends in guidance requirements, adaptively providing adequate 3D geometric initialization and suitable 2D texture refinement for different objects. Consistent123 can obtain highly 3D-consistent reconstruction and exhibits strong generalization ability across various objects. Qualitative and quantitative experiments show that our method significantly outperforms state-of-the-art image-to-3D methods. See https://Consistent123.github.io for a more comprehensive exploration of our generated 3D assets.
LMT: Longitudinal Mixing Training, a Framework to Predict Disease Progression from a Single Image
Oct 16, 2023Longitudinal imaging is able to capture both static anatomical structures and dynamic changes in disease progression toward earlier and better patient-specific pathology management. However, conventional approaches rarely take advantage of longitudinal information for detection and prediction purposes, especially for Diabetic Retinopathy (DR). In the past years, Mix-up training and pretext tasks with longitudinal context have effectively enhanced DR classification results and captured disease progression. In the meantime, a novel type of neural network named Neural Ordinary Differential Equation (NODE) has been proposed for solving ordinary differential equations, with a neural network treated as a black box. By definition, NODE is well suited for solving time-related problems. In this paper, we propose to combine these three aspects to detect and predict DR progression. Our framework, Longitudinal Mixing Training (LMT), can be considered both as a regularizer and as a pretext task that encodes the disease progression in the latent space. Additionally, we evaluate the trained model weights on a downstream task with a longitudinal context using standard and longitudinal pretext tasks. We introduce a new way to train time-aware models using $t_{mix}$, a weighted average time between two consecutive examinations. We compare our approach to standard mixing training on DR classification using OPHDIAT a longitudinal retinal Color Fundus Photographs (CFP) dataset. We were able to predict whether an eye would develop a severe DR in the following visit using a single image, with an AUC of 0.798 compared to baseline results of 0.641. Our results indicate that our longitudinal pretext task can learn the progression of DR disease and that introducing $t_{mix}$ augmentation is beneficial for time-aware models.
Whole-body Detection, Recognition and Identification at Altitude and Range
Nov 09, 2023In this paper, we address the challenging task of whole-body biometric detection, recognition, and identification at distances of up to 500m and large pitch angles of up to 50 degree. We propose an end-to-end system evaluated on diverse datasets, including the challenging Biometric Recognition and Identification at Range (BRIAR) dataset. Our approach involves pre-training the detector on common image datasets and fine-tuning it on BRIAR's complex videos and images. After detection, we extract body images and employ a feature extractor for recognition. We conduct thorough evaluations under various conditions, such as different ranges and angles in indoor, outdoor, and aerial scenarios. Our method achieves an average F1 score of 98.29% at IoU = 0.7 and demonstrates strong performance in recognition accuracy and true acceptance rate at low false acceptance rates compared to existing models. On a test set of 100 subjects with 444 distractors, our model achieves a rank-20 recognition accuracy of 75.13% and a TAR@1%FAR of 54.09%.
A Two-Step Framework for Multi-Material Decomposition of Dual Energy Computed Tomography from Projection Domain
Oct 31, 2023Dual-energy computed tomography (DECT) utilizes separate X-ray energy spectra to improve multi-material decomposition (MMD) for various diagnostic applications. However accurate decomposing more than two types of material remains challenging using conventional methods. Deep learning (DL) methods have shown promise to improve the MMD performance, but typical approaches of conducing DL-MMD in the image domain fail to fully utilize projection information or under iterative setup are computationally inefficient in both training and prediction. In this work, we present a clinical-applicable MMD (>2) framework rFast-MMDNet, operating with raw projection data in non-recursive setup, for breast tissue differentiation. rFast-MMDNet is a two-stage algorithm, including stage-one SinoNet to perform dual energy projection decomposition on tissue sinograms and stage-two FBP-DenoiseNet to perform domain adaptation and image post-processing. rFast-MMDNet was tested on a 2022 DL-Spectral-Challenge breast phantom dataset. The two stages of rFast-MMDNet were evaluated separately and then compared with four noniterative reference methods including a direct inversion method (AA-MMD), an image domain DL method (ID-UNet), AA-MMD/ID-UNet + DenoiseNet and a sinogram domain DL method (Triple-CBCT). Our results show that models trained from information stored in DE transmission domain can yield high-fidelity decomposition of the adipose, calcification, and fibroglandular materials with averaged RMSE, MAE, negative PSNR, and SSIM of 0.004+/-~0, 0.001+/-~0, -45.027+/-~0.542, and 0.002+/-~0 benchmarking to the ground truth, respectively. Training of entire rFast-MMDNet on a 4xRTX A6000 GPU cluster took a day with inference time <1s. All DL methods generally led to more accurate MMD than AA-MMD. rFast-MMDNet outperformed Triple-CBCT, but both are superior to the image-domain based methods.
RPCANet: Deep Unfolding RPCA Based Infrared Small Target Detection
Nov 02, 2023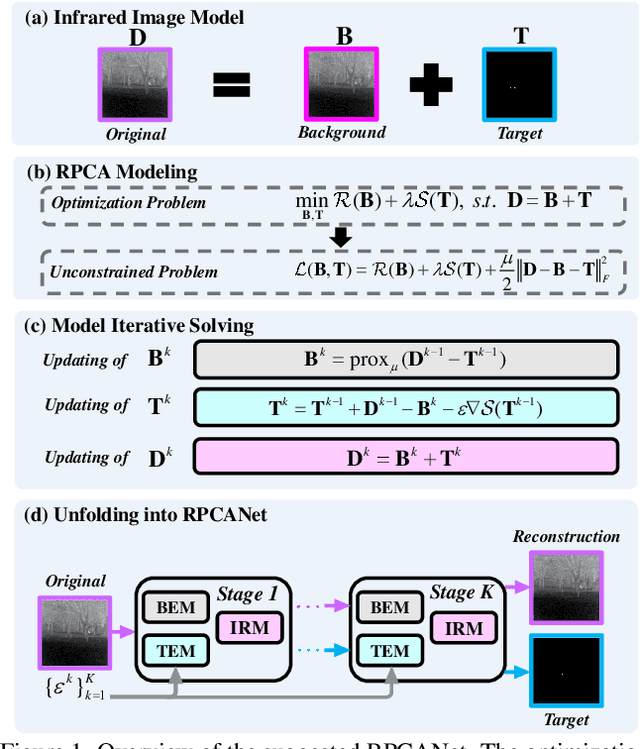
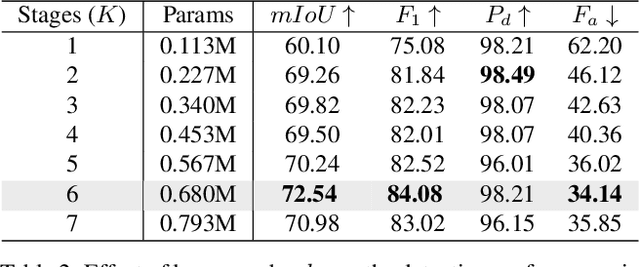
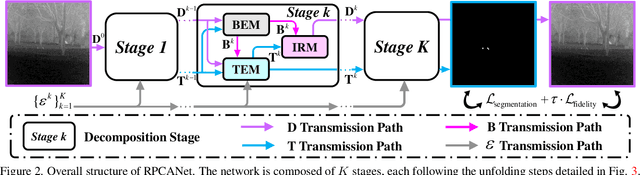
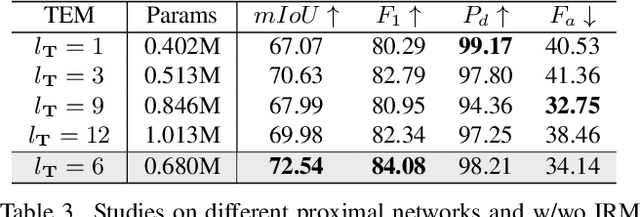
Deep learning (DL) networks have achieved remarkable performance in infrared small target detection (ISTD). However, these structures exhibit a deficiency in interpretability and are widely regarded as black boxes, as they disregard domain knowledge in ISTD. To alleviate this issue, this work proposes an interpretable deep network for detecting infrared dim targets, dubbed RPCANet. Specifically, our approach formulates the ISTD task as sparse target extraction, low-rank background estimation, and image reconstruction in a relaxed Robust Principle Component Analysis (RPCA) model. By unfolding the iterative optimization updating steps into a deep-learning framework, time-consuming and complex matrix calculations are replaced by theory-guided neural networks. RPCANet detects targets with clear interpretability and preserves the intrinsic image feature, instead of directly transforming the detection task into a matrix decomposition problem. Extensive experiments substantiate the effectiveness of our deep unfolding framework and demonstrate its trustworthy results, surpassing baseline methods in both qualitative and quantitative evaluations.
Fast, multicolour optical sectioning over extended fields of view by combining interferometric SIM with machine learning
Oct 31, 2023Structured illumination can reject out-of-focus signal from a sample, enabling high-speed and high-contrast imaging over large areas with widefield detection optics. Currently, this optical-sectioning technique is limited by image reconstruction artefacts and the need for sequential imaging of multiple colour channels. We combine multicolour interferometric pattern generation with machine-learning processing, permitting high-contrast, real-time reconstruction of image data. The method is insensitive to background noise and unevenly phase-stepped illumination patterns. We validate the method in silico and demonstrate its application on diverse specimens, ranging from fixed and live biological cells to synthetic biosystems, imaging at up to 37 Hz across a 44 x 44 $\mu m^2$ field of view.
Improving Emotional Expression and Cohesion in Image-Based Playlist Description and Music Topics: A Continuous Parameterization Approach
Oct 12, 2023Text generation in image-based platforms, particularly for music-related content, requires precise control over text styles and the incorporation of emotional expression. However, existing approaches often need help to control the proportion of external factors in generated text and rely on discrete inputs, lacking continuous control conditions for desired text generation. This study proposes Continuous Parameterization for Controlled Text Generation (CPCTG) to overcome these limitations. Our approach leverages a Language Model (LM) as a style learner, integrating Semantic Cohesion (SC) and Emotional Expression Proportion (EEP) considerations. By enhancing the reward method and manipulating the CPCTG level, our experiments on playlist description and music topic generation tasks demonstrate significant improvements in ROUGE scores, indicating enhanced relevance and coherence in the generated text.
Learning to recognize occluded and small objects with partial inputs
Oct 27, 2023Recognizing multiple objects in an image is challenging due to occlusions, and becomes even more so when the objects are small. While promising, existing multi-label image recognition models do not explicitly learn context-based representations, and hence struggle to correctly recognize small and occluded objects. Intuitively, recognizing occluded objects requires knowledge of partial input, and hence context. Motivated by this intuition, we propose Masked Supervised Learning (MSL), a single-stage, model-agnostic learning paradigm for multi-label image recognition. The key idea is to learn context-based representations using a masked branch and to model label co-occurrence using label consistency. Experimental results demonstrate the simplicity, applicability and more importantly the competitive performance of MSL against previous state-of-the-art methods on standard multi-label image recognition benchmarks. In addition, we show that MSL is robust to random masking and demonstrate its effectiveness in recognizing non-masked objects. Code and pretrained models are available on GitHub.