 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Recognize Any Regions
Nov 02, 2023
Understanding the semantics of individual regions or patches within unconstrained images, such as in open-world object detection, represents a critical yet challenging task in computer vision. Building on the success of powerful image-level vision-language (ViL) foundation models like CLIP, recent efforts have sought to harness their capabilities by either training a contrastive model from scratch with an extensive collection of region-label pairs or aligning the outputs of a detection model with image-level representations of region proposals. Despite notable progress, these approaches are plagued by computationally intensive training requirements, susceptibility to data noise, and deficiency in contextual information. To address these limitations, we explore the synergistic potential of off-the-shelf foundation models, leveraging their respective strengths in localization and semantics. We introduce a novel, generic, and efficient region recognition architecture, named RegionSpot, designed to integrate position-aware localization knowledge from a localization foundation model (e.g., SAM) with semantic information extracted from a ViL model (e.g., CLIP). To fully exploit pretrained knowledge while minimizing training overhead, we keep both foundation models frozen, focusing optimization efforts solely on a lightweight attention-based knowledge integration module. Through extensive experiments in the context of open-world object recognition, our RegionSpot demonstrates significant performance improvements over prior alternatives, while also providing substantial computational savings. For instance, training our model with 3 million data in a single day using 8 V100 GPUs. Our model outperforms GLIP by 6.5 % in mean average precision (mAP), with an even larger margin by 14.8 % for more challenging and rare categories.
Unlock Multi-Modal Capability of Dense Retrieval via Visual Module Plugin
Oct 21, 2023This paper proposes Multi-modAl Retrieval model via Visual modulE pLugin (MARVEL) to learn an embedding space for queries and multi-modal documents to conduct retrieval. MARVEL encodes queries and multi-modal documents with a unified encoder model, which helps to alleviate the modality gap between images and texts. Specifically, we enable the image understanding ability of a well-trained dense retriever, T5-ANCE, by incorporating the image features encoded by the visual module as its inputs. To facilitate the multi-modal retrieval tasks, we build the ClueWeb22-MM dataset based on the ClueWeb22 dataset, which regards anchor texts as queries, and exact the related texts and image documents from anchor linked web pages. Our experiments show that MARVEL significantly outperforms the state-of-the-art methods on the multi-modal retrieval dataset WebQA and ClueWeb22-MM. Our further analyses show that the visual module plugin method is tailored to enable the image understanding ability for an existing dense retrieval model. Besides, we also show that the language model has the ability to extract image semantics from image encoders and adapt the image features in the input space of language models. All codes are available at https://github.com/OpenMatch/MARVEL.
Degradation-Aware Self-Attention Based Transformer for Blind Image Super-Resolution
Oct 06, 2023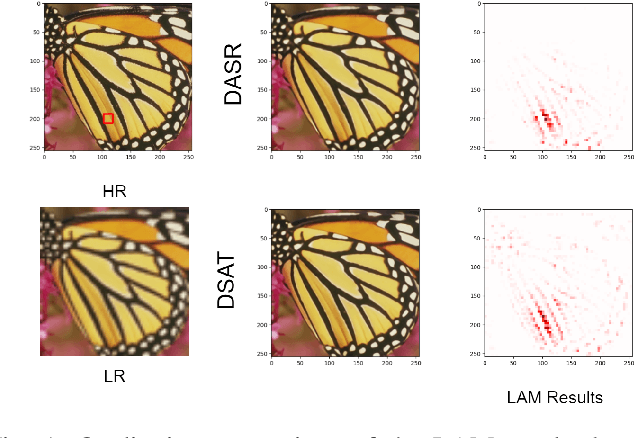

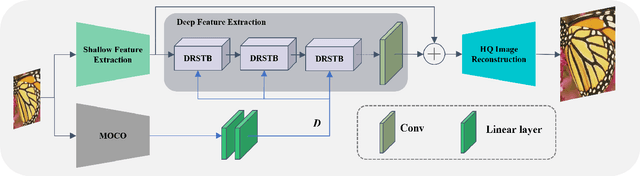
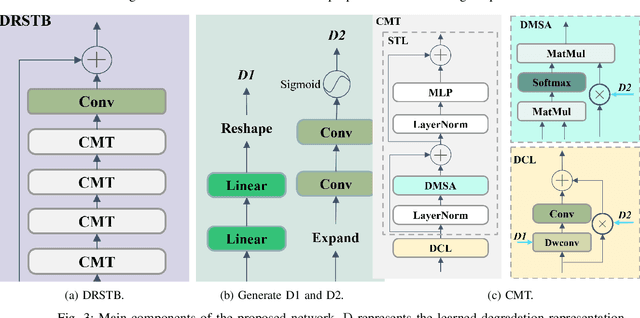
Compared to CNN-based methods, Transformer-based methods achieve impressive image restoration outcomes due to their abilities to model remote dependencies. However, how to apply Transformer-based methods to the field of blind super-resolution (SR) and further make an SR network adaptive to degradation information is still an open problem. In this paper, we propose a new degradation-aware self-attention-based Transformer model, where we incorporate contrastive learning into the Transformer network for learning the degradation representations of input images with unknown noise. In particular, we integrate both CNN and Transformer components into the SR network, where we first use the CNN modulated by the degradation information to extract local features, and then employ the degradation-aware Transformer to extract global semantic features. We apply our proposed model to several popular large-scale benchmark datasets for testing, and achieve the state-of-the-art performance compared to existing methods. In particular, our method yields a PSNR of 32.43 dB on the Urban100 dataset at $\times$2 scale, 0.94 dB higher than DASR, and 26.62 dB on the Urban100 dataset at $\times$4 scale, 0.26 dB improvement over KDSR, setting a new benchmark in this area. Source code is available at: https://github.com/I2-Multimedia-Lab/DSAT/tree/main.
Interpretable Medical Image Classification using Prototype Learning and Privileged Information
Oct 24, 2023Interpretability is often an essential requirement in medical imaging. Advanced deep learning methods are required to address this need for explainability and high performance. In this work, we investigate whether additional information available during the training process can be used to create an understandable and powerful model. We propose an innovative solution called Proto-Caps that leverages the benefits of capsule networks, prototype learning and the use of privileged information. Evaluating the proposed solution on the LIDC-IDRI dataset shows that it combines increased interpretability with above state-of-the-art prediction performance. Compared to the explainable baseline model, our method achieves more than 6 % higher accuracy in predicting both malignancy (93.0 %) and mean characteristic features of lung nodules. Simultaneously, the model provides case-based reasoning with prototype representations that allow visual validation of radiologist-defined attributes.
* MICCAI 2023 Medical Image Computing and Computer Assisted Intervention
SideGAN: 3D-Aware Generative Model for Improved Side-View Image Synthesis
Sep 19, 2023
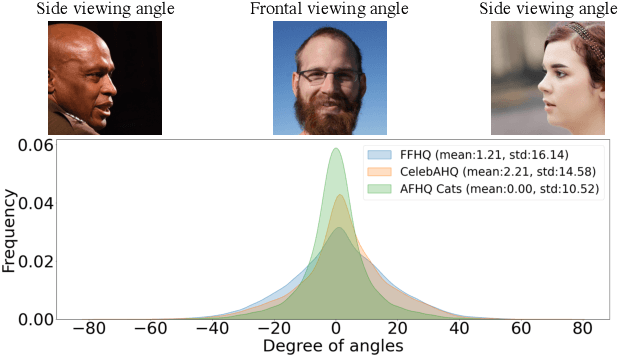

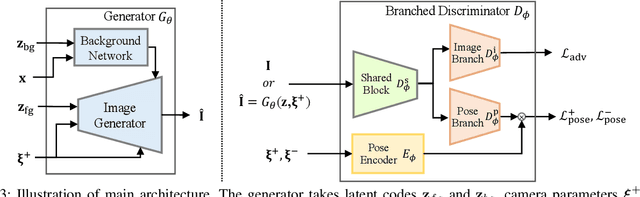
While recent 3D-aware generative models have shown photo-realistic image synthesis with multi-view consistency, the synthesized image quality degrades depending on the camera pose (e.g., a face with a blurry and noisy boundary at a side viewpoint). Such degradation is mainly caused by the difficulty of learning both pose consistency and photo-realism simultaneously from a dataset with heavily imbalanced poses. In this paper, we propose SideGAN, a novel 3D GAN training method to generate photo-realistic images irrespective of the camera pose, especially for faces of side-view angles. To ease the challenging problem of learning photo-realistic and pose-consistent image synthesis, we split the problem into two subproblems, each of which can be solved more easily. Specifically, we formulate the problem as a combination of two simple discrimination problems, one of which learns to discriminate whether a synthesized image looks real or not, and the other learns to discriminate whether a synthesized image agrees with the camera pose. Based on this, we propose a dual-branched discriminator with two discrimination branches. We also propose a pose-matching loss to learn the pose consistency of 3D GANs. In addition, we present a pose sampling strategy to increase learning opportunities for steep angles in a pose-imbalanced dataset. With extensive validation, we demonstrate that our approach enables 3D GANs to generate high-quality geometries and photo-realistic images irrespective of the camera pose.
SEMPART: Self-supervised Multi-resolution Partitioning of Image Semantics
Sep 20, 2023Accurately determining salient regions of an image is challenging when labeled data is scarce. DINO-based self-supervised approaches have recently leveraged meaningful image semantics captured by patch-wise features for locating foreground objects. Recent methods have also incorporated intuitive priors and demonstrated value in unsupervised methods for object partitioning. In this paper, we propose SEMPART, which jointly infers coarse and fine bi-partitions over an image's DINO-based semantic graph. Furthermore, SEMPART preserves fine boundary details using graph-driven regularization and successfully distills the coarse mask semantics into the fine mask. Our salient object detection and single object localization findings suggest that SEMPART produces high-quality masks rapidly without additional post-processing and benefits from co-optimizing the coarse and fine branches.
Multi-Agent 3D Map Reconstruction and Change Detection in Microgravity with Free-Flying Robots
Nov 05, 2023Assistive free-flyer robots autonomously caring for future crewed outposts -- such as NASA's Astrobee robots on the International Space Station (ISS) -- must be able to detect day-to-day interior changes to track inventory, detect and diagnose faults, and monitor the outpost status. This work presents a framework for multi-agent cooperative mapping and change detection to enable robotic maintenance of space outposts. One agent is used to reconstruct a 3D model of the environment from sequences of images and corresponding depth information. Another agent is used to periodically scan the environment for inconsistencies against the 3D model. Change detection is validated after completing the surveys using real image and pose data collected by Astrobee robots in a ground testing environment and from microgravity aboard the ISS. This work outlines the objectives, requirements, and algorithmic modules for the multi-agent reconstruction system, including recommendations for its use by assistive free-flyers aboard future microgravity outposts.
PotholeGuard: A Pothole Detection Approach by Point Cloud Semantic Segmentation
Nov 05, 2023Pothole detection is crucial for road safety and maintenance, traditionally relying on 2D image segmentation. However, existing 3D Semantic Pothole Segmentation research often overlooks point cloud sparsity, leading to suboptimal local feature capture and segmentation accuracy. Our research presents an innovative point cloud-based pothole segmentation architecture. Our model efficiently identifies hidden features and uses a feedback mechanism to enhance local characteristics, improving feature presentation. We introduce a local relationship learning module to understand local shape relationships, enhancing structural insights. Additionally, we propose a lightweight adaptive structure for refining local point features using the K nearest neighbor algorithm, addressing point cloud density differences and domain selection. Shared MLP Pooling is integrated to learn deep aggregation features, facilitating semantic data exploration and segmentation guidance. Extensive experiments on three public datasets confirm PotholeGuard's superior performance over state-of-the-art methods. Our approach offers a promising solution for robust and accurate 3D pothole segmentation, with applications in road maintenance and safety.
Masked Image Residual Learning for Scaling Deeper Vision Transformers
Sep 25, 2023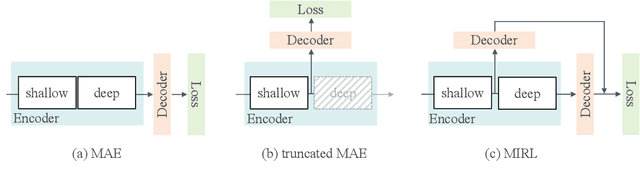

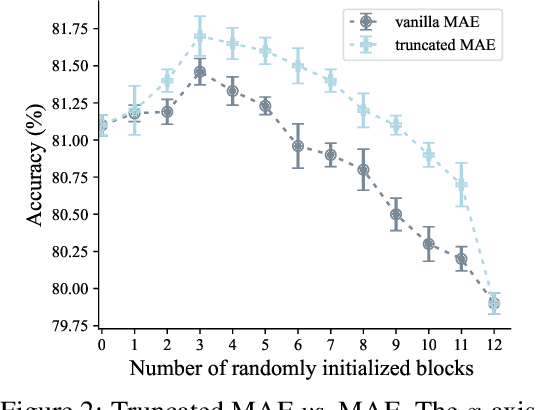
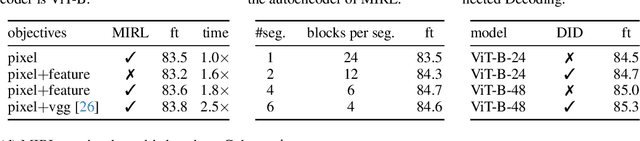
Deeper Vision Transformers (ViTs) are more challenging to train. We expose a degradation problem in deeper layers of ViT when using masked image modeling (MIM) for pre-training. To ease the training of deeper ViTs, we introduce a self-supervised learning framework called \textbf{M}asked \textbf{I}mage \textbf{R}esidual \textbf{L}earning (\textbf{MIRL}), which significantly alleviates the degradation problem, making scaling ViT along depth a promising direction for performance upgrade. We reformulate the pre-training objective for deeper layers of ViT as learning to recover the residual of the masked image. We provide extensive empirical evidence showing that deeper ViTs can be effectively optimized using MIRL and easily gain accuracy from increased depth. With the same level of computational complexity as ViT-Base and ViT-Large, we instantiate 4.5{$\times$} and 2{$\times$} deeper ViTs, dubbed ViT-S-54 and ViT-B-48. The deeper ViT-S-54, costing 3{$\times$} less than ViT-Large, achieves performance on par with ViT-Large. ViT-B-48 achieves 86.2\% top-1 accuracy on ImageNet. On one hand, deeper ViTs pre-trained with MIRL exhibit excellent generalization capabilities on downstream tasks, such as object detection and semantic segmentation. On the other hand, MIRL demonstrates high pre-training efficiency. With less pre-training time, MIRL yields competitive performance compared to other approaches.
Exploring the Potential of Generative AI for the World Wide Web
Oct 26, 2023Generative Artificial Intelligence (AI) is a cutting-edge technology capable of producing text, images, and various media content leveraging generative models and user prompts. Between 2022 and 2023, generative AI surged in popularity with a plethora of applications spanning from AI-powered movies to chatbots. In this paper, we delve into the potential of generative AI within the realm of the World Wide Web, specifically focusing on image generation. Web developers already harness generative AI to help crafting text and images, while Web browsers might use it in the future to locally generate images for tasks like repairing broken webpages, conserving bandwidth, and enhancing privacy. To explore this research area, we have developed WebDiffusion, a tool that allows to simulate a Web powered by stable diffusion, a popular text-to-image model, from both a client and server perspective. WebDiffusion further supports crowdsourcing of user opinions, which we use to evaluate the quality and accuracy of 409 AI-generated images sourced from 60 webpages. Our findings suggest that generative AI is already capable of producing pertinent and high-quality Web images, even without requiring Web designers to manually input prompts, just by leveraging contextual information available within the webpages. However, we acknowledge that direct in-browser image generation remains a challenge, as only highly powerful GPUs, such as the A40 and A100, can (partially) compete with classic image downloads. Nevertheless, this approach could be valuable for a subset of the images, for example when fixing broken webpages or handling highly private content.