 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
SAMCLR: Contrastive pre-training on complex scenes using SAM for view sampling
Oct 23, 2023
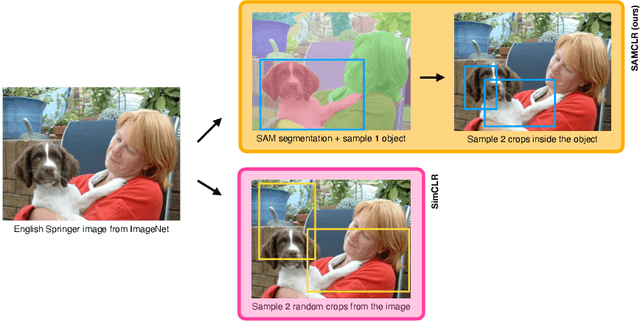
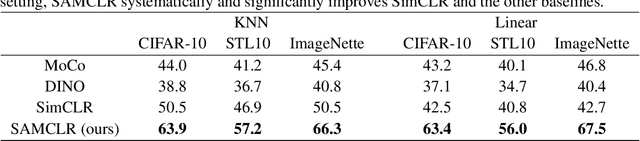
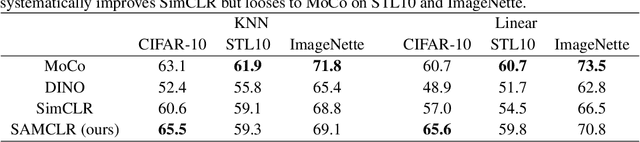
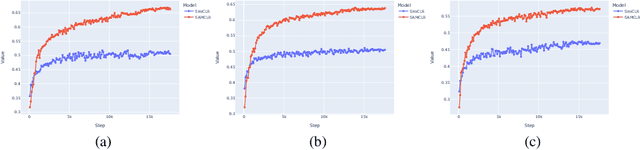
In Computer Vision, self-supervised contrastive learning enforces similar representations between different views of the same image. The pre-training is most often performed on image classification datasets, like ImageNet, where images mainly contain a single class of objects. However, when dealing with complex scenes with multiple items, it becomes very unlikely for several views of the same image to represent the same object category. In this setting, we propose SAMCLR, an add-on to SimCLR which uses SAM to segment the image into semantic regions, then sample the two views from the same region. Preliminary results show empirically that when pre-training on Cityscapes and ADE20K, then evaluating on classification on CIFAR-10, STL10 and ImageNette, SAMCLR performs at least on par with, and most often significantly outperforms not only SimCLR, but also DINO and MoCo.
Support or Refute: Analyzing the Stance of Evidence to Detect Out-of-Context Mis- and Disinformation
Nov 06, 2023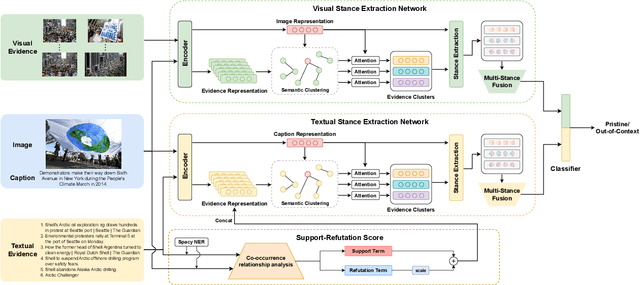
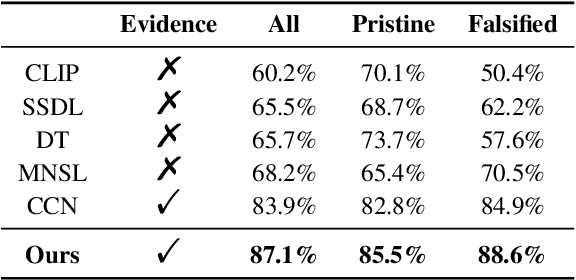
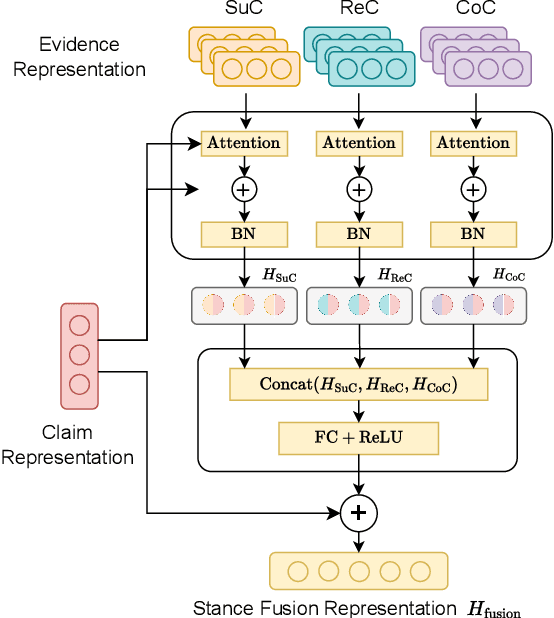
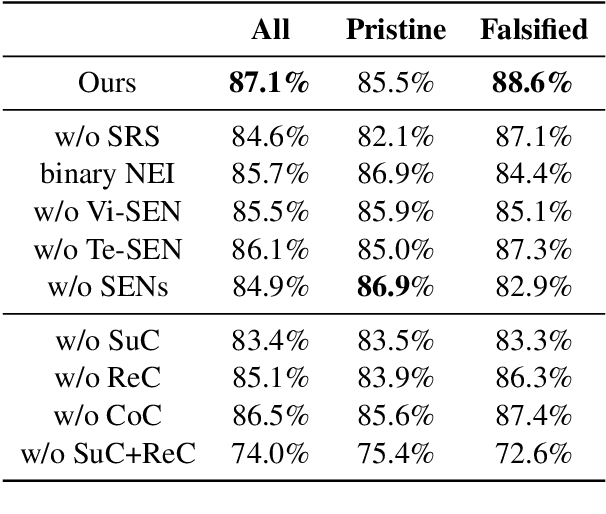
Mis- and disinformation online have become a major societal problem as major sources of online harms of different kinds. One common form of mis- and disinformation is out-of-context (OOC) information, where different pieces of information are falsely associated, e.g., a real image combined with a false textual caption or a misleading textual description. Although some past studies have attempted to defend against OOC mis- and disinformation through external evidence, they tend to disregard the role of different pieces of evidence with different stances. Motivated by the intuition that the stance of evidence represents a bias towards different detection results, we propose a stance extraction network (SEN) that can extract the stances of different pieces of multi-modal evidence in a unified framework. Moreover, we introduce a support-refutation score calculated based on the co-occurrence relations of named entities into the textual SEN. Extensive experiments on a public large-scale dataset demonstrated that our proposed method outperformed the state-of-the-art baselines, with the best model achieving a performance gain of 3.2% in accuracy.
Consistent4D: Consistent 360° Dynamic Object Generation from Monocular Video
Nov 06, 2023In this paper, we present Consistent4D, a novel approach for generating 4D dynamic objects from uncalibrated monocular videos. Uniquely, we cast the 360-degree dynamic object reconstruction as a 4D generation problem, eliminating the need for tedious multi-view data collection and camera calibration. This is achieved by leveraging the object-level 3D-aware image diffusion model as the primary supervision signal for training Dynamic Neural Radiance Fields (DyNeRF). Specifically, we propose a Cascade DyNeRF to facilitate stable convergence and temporal continuity under the supervision signal which is discrete along the time axis. To achieve spatial and temporal consistency, we further introduce an Interpolation-driven Consistency Loss. It is optimized by minimizing the discrepancy between rendered frames from DyNeRF and interpolated frames from a pre-trained video interpolation model. Extensive experiments show that our Consistent4D can perform competitively to prior art alternatives, opening up new possibilities for 4D dynamic object generation from monocular videos, whilst also demonstrating advantage for conventional text-to-3D generation tasks. Our project page is https://consistent4d.github.io/.
Efficient, Self-Supervised Human Pose Estimation with Inductive Prior Tuning
Nov 06, 2023The goal of 2D human pose estimation (HPE) is to localize anatomical landmarks, given an image of a person in a pose. SOTA techniques make use of thousands of labeled figures (finetuning transformers or training deep CNNs), acquired using labor-intensive crowdsourcing. On the other hand, self-supervised methods re-frame the HPE task as a reconstruction problem, enabling them to leverage the vast amount of unlabeled visual data, though at the present cost of accuracy. In this work, we explore ways to improve self-supervised HPE. We (1) analyze the relationship between reconstruction quality and pose estimation accuracy, (2) develop a model pipeline that outperforms the baseline which inspired our work, using less than one-third the amount of training data, and (3) offer a new metric suitable for self-supervised settings that measures the consistency of predicted body part length proportions. We show that a combination of well-engineered reconstruction losses and inductive priors can help coordinate pose learning alongside reconstruction in a self-supervised paradigm.
Efficient and Low-Footprint Object Classification using Spatial Contrast
Nov 06, 2023Event-based vision sensors traditionally compute temporal contrast that offers potential for low-power and low-latency sensing and computing. In this research, an alternative paradigm for event-based sensors using localized spatial contrast (SC) under two different thresholding techniques, relative and absolute, is investigated. Given the slow maturity of spatial contrast in comparison to temporal-based sensors, a theoretical simulated output of such a hardware sensor is explored. Furthermore, we evaluate traffic sign classification using the German Traffic Sign dataset (GTSRB) with well-known Deep Neural Networks (DNNs). This study shows that spatial contrast can effectively capture salient image features needed for classification using a Binarized DNN with significant reduction in input data usage (at least 12X) and memory resources (17.5X), compared to high precision RGB images and DNN, with only a small loss (~2%) in macro F1-score. Binarized MicronNet achieves an F1-score of 94.4% using spatial contrast, compared to only 56.3% when using RGB input images. Thus, SC offers great promise for deployment in power and resource constrained edge computing environments.
p-Laplacian Transformer
Nov 06, 2023$p$-Laplacian regularization, rooted in graph and image signal processing, introduces a parameter $p$ to control the regularization effect on these data. Smaller values of $p$ promote sparsity and interpretability, while larger values encourage smoother solutions. In this paper, we first show that the self-attention mechanism obtains the minimal Laplacian regularization ($p=2$) and encourages the smoothness in the architecture. However, the smoothness is not suitable for the heterophilic structure of self-attention in transformers where attention weights between tokens that are in close proximity and non-close ones are assigned indistinguishably. From that insight, we then propose a novel class of transformers, namely the $p$-Laplacian Transformer (p-LaT), which leverages $p$-Laplacian regularization framework to harness the heterophilic features within self-attention layers. In particular, low $p$ values will effectively assign higher attention weights to tokens that are in close proximity to the current token being processed. We empirically demonstrate the advantages of p-LaT over the baseline transformers on a wide range of benchmark datasets.
Scattering Vision Transformer: Spectral Mixing Matters
Nov 02, 2023Vision transformers have gained significant attention and achieved state-of-the-art performance in various computer vision tasks, including image classification, instance segmentation, and object detection. However, challenges remain in addressing attention complexity and effectively capturing fine-grained information within images. Existing solutions often resort to down-sampling operations, such as pooling, to reduce computational cost. Unfortunately, such operations are non-invertible and can result in information loss. In this paper, we present a novel approach called Scattering Vision Transformer (SVT) to tackle these challenges. SVT incorporates a spectrally scattering network that enables the capture of intricate image details. SVT overcomes the invertibility issue associated with down-sampling operations by separating low-frequency and high-frequency components. Furthermore, SVT introduces a unique spectral gating network utilizing Einstein multiplication for token and channel mixing, effectively reducing complexity. We show that SVT achieves state-of-the-art performance on the ImageNet dataset with a significant reduction in a number of parameters and FLOPS. SVT shows 2\% improvement over LiTv2 and iFormer. SVT-H-S reaches 84.2\% top-1 accuracy, while SVT-H-B reaches 85.2\% (state-of-art for base versions) and SVT-H-L reaches 85.7\% (again state-of-art for large versions). SVT also shows comparable results in other vision tasks such as instance segmentation. SVT also outperforms other transformers in transfer learning on standard datasets such as CIFAR10, CIFAR100, Oxford Flower, and Stanford Car datasets. The project page is available on this webpage.\url{https://badripatro.github.io/svt/}.
Recognize Any Regions
Nov 02, 2023Understanding the semantics of individual regions or patches within unconstrained images, such as in open-world object detection, represents a critical yet challenging task in computer vision. Building on the success of powerful image-level vision-language (ViL) foundation models like CLIP, recent efforts have sought to harness their capabilities by either training a contrastive model from scratch with an extensive collection of region-label pairs or aligning the outputs of a detection model with image-level representations of region proposals. Despite notable progress, these approaches are plagued by computationally intensive training requirements, susceptibility to data noise, and deficiency in contextual information. To address these limitations, we explore the synergistic potential of off-the-shelf foundation models, leveraging their respective strengths in localization and semantics. We introduce a novel, generic, and efficient region recognition architecture, named RegionSpot, designed to integrate position-aware localization knowledge from a localization foundation model (e.g., SAM) with semantic information extracted from a ViL model (e.g., CLIP). To fully exploit pretrained knowledge while minimizing training overhead, we keep both foundation models frozen, focusing optimization efforts solely on a lightweight attention-based knowledge integration module. Through extensive experiments in the context of open-world object recognition, our RegionSpot demonstrates significant performance improvements over prior alternatives, while also providing substantial computational savings. For instance, training our model with 3 million data in a single day using 8 V100 GPUs. Our model outperforms GLIP by 6.5 % in mean average precision (mAP), with an even larger margin by 14.8 % for more challenging and rare categories.
Personalized Food Image Classification: Benchmark Datasets and New Baseline
Sep 15, 2023Food image classification is a fundamental step of image-based dietary assessment, enabling automated nutrient analysis from food images. Many current methods employ deep neural networks to train on generic food image datasets that do not reflect the dynamism of real-life food consumption patterns, in which food images appear sequentially over time, reflecting the progression of what an individual consumes. Personalized food classification aims to address this problem by training a deep neural network using food images that reflect the consumption pattern of each individual. However, this problem is under-explored and there is a lack of benchmark datasets with individualized food consumption patterns due to the difficulty in data collection. In this work, we first introduce two benchmark personalized datasets including the Food101-Personal, which is created based on surveys of daily dietary patterns from participants in the real world, and the VFNPersonal, which is developed based on a dietary study. In addition, we propose a new framework for personalized food image classification by leveraging self-supervised learning and temporal image feature information. Our method is evaluated on both benchmark datasets and shows improved performance compared to existing works. The dataset has been made available at: https://skynet.ecn.purdue.edu/~pan161/dataset_personal.html
Interferometric Neural Networks
Oct 25, 2023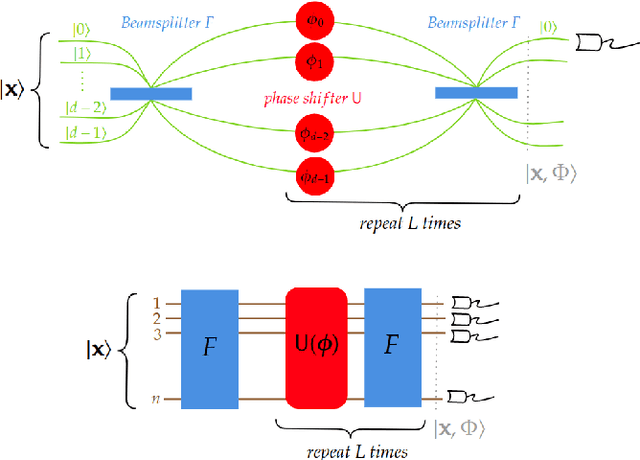
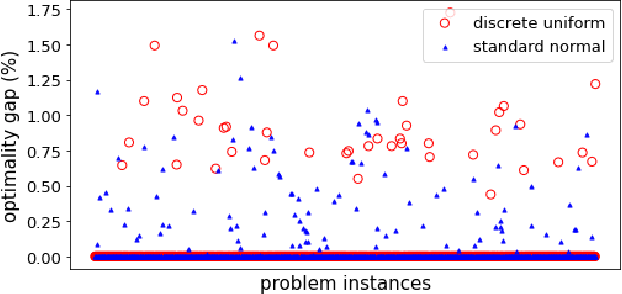
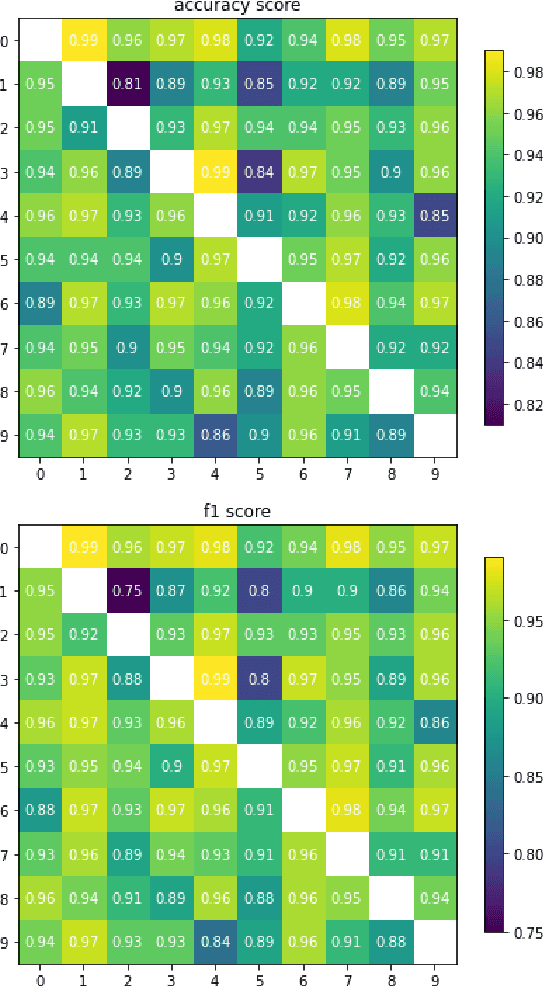
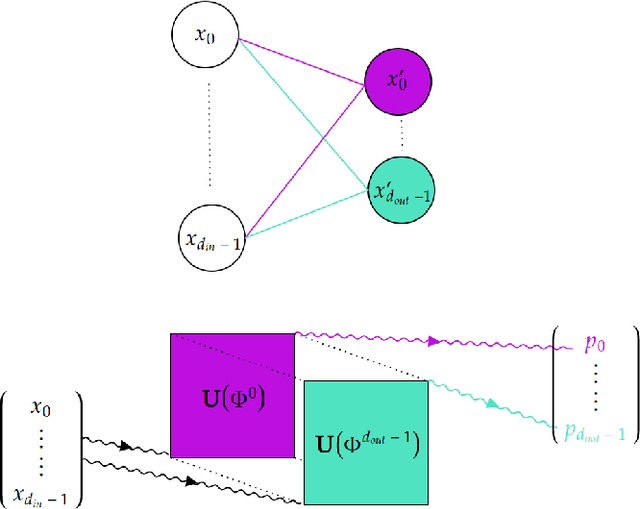
On the one hand, artificial neural networks have many successful applications in the field of machine learning and optimization. On the other hand, interferometers are integral parts of any field that deals with waves such as optics, astronomy, and quantum physics. Here, we introduce neural networks composed of interferometers and then build generative adversarial networks from them. Our networks do not have any classical layer and can be realized on quantum computers or photonic chips. We demonstrate their applicability for combinatorial optimization, image classification, and image generation. For combinatorial optimization, our network consistently converges to the global optimum or remains within a narrow range of it. In multi-class image classification tasks, our networks achieve accuracies of 93% and 83%. Lastly, we show their capability to generate images of digits from 0 to 9 as well as human faces.