 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Detecting internal disorders in fruit by CT. Part 1: Joint 2D to 3D image registration workflow for comparing multiple slice photographs and CT scans of apple fruit
Oct 03, 2023
A large percentage of apples are affected by internal disorders after long-term storage, which makes them unacceptable in the supply chain. CT imaging is a promising technique for in-line detection of these disorders. Therefore, it is crucial to understand how different disorders affect the image features that can be observed in CT scans. This paper presents a workflow for creating datasets of image pairs of photographs of apple slices and their corresponding CT slices. By having CT and photographic images of the same part of the apple, the complementary information in both images can be used to study the processes underlying internal disorders and how internal disorders can be measured in CT images. The workflow includes data acquisition, image segmentation, image registration, and validation methods. The image registration method aligns all available slices of an apple within a single optimization problem, assuming that the slices are parallel. This method outperformed optimizing the alignment separately for each slice. The workflow was applied to create a dataset of 1347 slice photographs and their corresponding CT slices. The dataset was acquired from 107 'Kanzi' apples that had been stored in controlled atmosphere (CA) storage for 8 months. In this dataset, the distance between annotations in the slice photograph and the matching CT slice was, on average, $1.47 \pm 0.40$ mm. Our workflow allows collecting large datasets of accurately aligned photo-CT image pairs, which can help distinguish internal disorders with a similar appearance on CT. With slight modifications, a similar workflow can be applied to other fruits or MRI instead of CT scans.
Elastic Interaction Energy Loss for Traffic Image Segmentation
Oct 02, 2023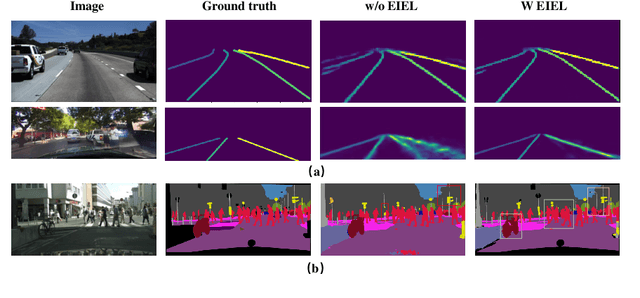
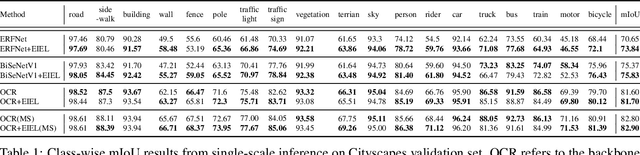

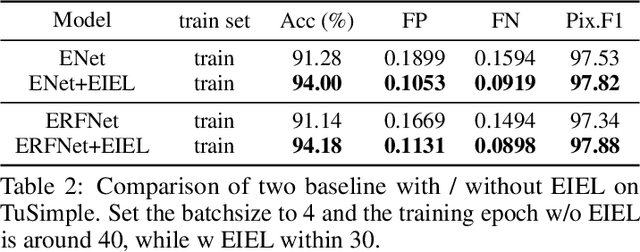
Segmentation is a pixel-level classification of images. The accuracy and fast inference speed of image segmentation are crucial for autonomous driving safety. Fine and complex geometric objects are the most difficult but important recognition targets in traffic scene, such as pedestrians, traffic signs and lanes. In this paper, a simple and efficient geometry-sensitive energy-based loss function is proposed to Convolutional Neural Network (CNN) for multi-class segmentation on real-time traffic scene understanding. To be specific, the elastic interaction energy (EIE) between two boundaries will drive the prediction moving toward the ground truth until completely overlap. The EIE loss function is incorporated into CNN to enhance accuracy on fine-scale structure segmentation. In particular, small or irregularly shaped objects can be identified more accurately, and discontinuity issues on slender objects can be improved. Our approach can be applied to different segmentation-based problems, such as urban scene segmentation and lane detection. We quantitatively and qualitatively analyze our method on three traffic datasets, including urban scene data Cityscapes, lane data TuSimple and CULane. The results show that our approach consistently improves performance, especially when using real-time, lightweight networks as the backbones, which is more suitable for autonomous driving.
Image-Text Pre-Training for Logo Recognition
Sep 18, 2023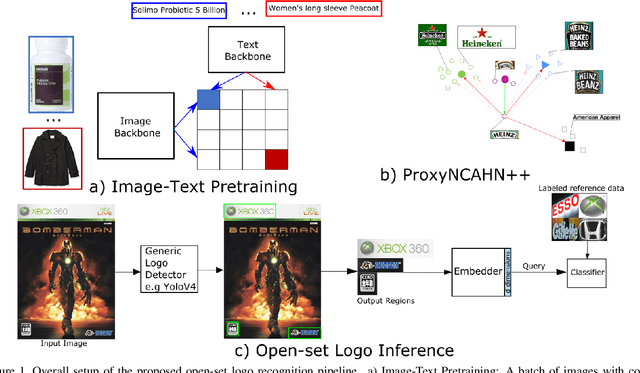
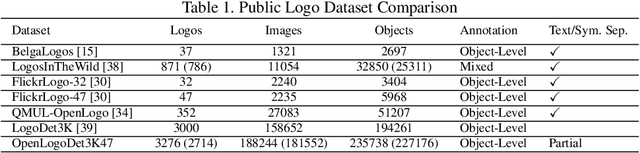


Open-set logo recognition is commonly solved by first detecting possible logo regions and then matching the detected parts against an ever-evolving dataset of cropped logo images. The matching model, a metric learning problem, is especially challenging for logo recognition due to the mixture of text and symbols in logos. We propose two novel contributions to improve the matching model's performance: (a) using image-text paired samples for pre-training, and (b) an improved metric learning loss function. A standard paradigm of fine-tuning ImageNet pre-trained models fails to discover the text sensitivity necessary to solve the matching problem effectively. This work demonstrates the importance of pre-training on image-text pairs, which significantly improves the performance of a visual embedder trained for the logo retrieval task, especially for more text-dominant classes. We construct a composite public logo dataset combining LogoDet3K, OpenLogo, and FlickrLogos-47 deemed OpenLogoDet3K47. We show that the same vision backbone pre-trained on image-text data, when fine-tuned on OpenLogoDet3K47, achieves $98.6\%$ recall@1, significantly improving performance over pre-training on Imagenet1K ($97.6\%$). We generalize the ProxyNCA++ loss function to propose ProxyNCAHN++ which incorporates class-specific hard negative images. The proposed method sets new state-of-the-art on five public logo datasets considered, with a $3.5\%$ zero-shot recall@1 improvement on LogoDet3K test, $4\%$ on OpenLogo, $6.5\%$ on FlickrLogos-47, $6.2\%$ on Logos In The Wild, and $0.6\%$ on BelgaLogo.
* 8 pages, 5 figures, 4 tables
A Bayesian optimization framework for the automatic tuning of MPC-based shared controllers
Nov 02, 2023This paper presents a Bayesian optimization framework for the automatic tuning of shared controllers which are defined as a Model Predictive Control (MPC) problem. The proposed framework includes the design of performance metrics as well as the representation of user inputs for simulation-based optimization. The framework is applied to the optimization of a shared controller for an Image Guided Therapy robot. VR-based user experiments confirm the increase in performance of the automatically tuned MPC shared controller with respect to a hand-tuned baseline version as well as its generalization ability.
Dual Relation Alignment for Composed Image Retrieval
Sep 05, 2023
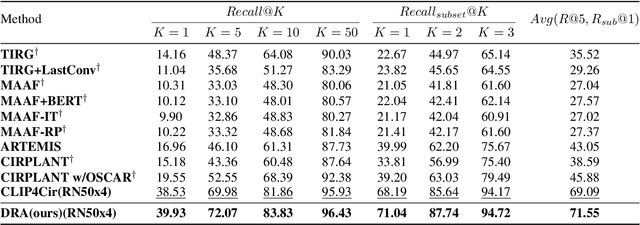
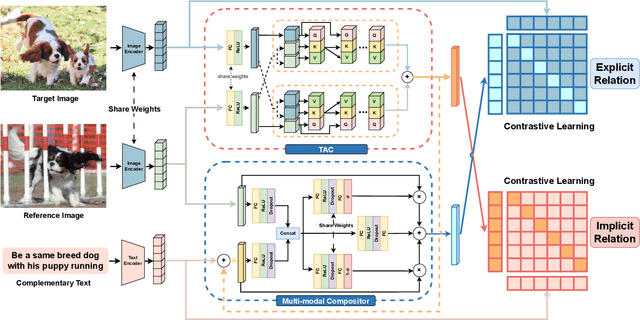
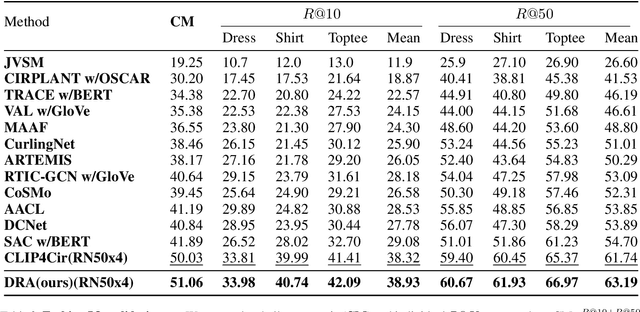
Composed image retrieval, a task involving the search for a target image using a reference image and a complementary text as the query, has witnessed significant advancements owing to the progress made in cross-modal modeling. Unlike the general image-text retrieval problem with only one alignment relation, i.e., image-text, we argue for the existence of two types of relations in composed image retrieval. The explicit relation pertains to the reference image & complementary text-target image, which is commonly exploited by existing methods. Besides this intuitive relation, the observations during our practice have uncovered another implicit yet crucial relation, i.e., reference image & target image-complementary text, since we found that the complementary text can be inferred by studying the relation between the target image and the reference image. Regrettably, existing methods largely focus on leveraging the explicit relation to learn their networks, while overlooking the implicit relation. In response to this weakness, We propose a new framework for composed image retrieval, termed dual relation alignment, which integrates both explicit and implicit relations to fully exploit the correlations among the triplets. Specifically, we design a vision compositor to fuse reference image and target image at first, then the resulted representation will serve two roles: (1) counterpart for semantic alignment with the complementary text and (2) compensation for the complementary text to boost the explicit relation modeling, thereby implant the implicit relation into the alignment learning. Our method is evaluated on two popular datasets, CIRR and FashionIQ, through extensive experiments. The results confirm the effectiveness of our dual-relation learning in substantially enhancing composed image retrieval performance.
ODM3D: Alleviating Foreground Sparsity for Semi-Supervised Monocular 3D Object Detection
Nov 07, 2023Monocular 3D object detection (M3OD) is a significant yet inherently challenging task in autonomous driving due to absence of explicit depth cues in a single RGB image. In this paper, we strive to boost currently underperforming monocular 3D object detectors by leveraging an abundance of unlabelled data via semi-supervised learning. Our proposed ODM3D framework entails cross-modal knowledge distillation at various levels to inject LiDAR-domain knowledge into a monocular detector during training. By identifying foreground sparsity as the main culprit behind existing methods' suboptimal training, we exploit the precise localisation information embedded in LiDAR points to enable more foreground-attentive and efficient distillation via the proposed BEV occupancy guidance mask, leading to notably improved knowledge transfer and M3OD performance. Besides, motivated by insights into why existing cross-modal GT-sampling techniques fail on our task at hand, we further design a novel cross-modal object-wise data augmentation strategy for effective RGB-LiDAR joint learning. Our method ranks 1st in both KITTI validation and test benchmarks, significantly surpassing all existing monocular methods, supervised or semi-supervised, on both BEV and 3D detection metrics.
SonoSAMTrack -- Segment and Track Anything on Ultrasound Images
Nov 07, 2023In this paper, we present SonoSAM - a promptable foundational model for segmenting objects of interest on ultrasound images, followed by state of the art tracking model to perform segmentations on 2D+t and 3D ultrasound datasets. Fine-tuned exclusively on a rich, diverse set of objects from $\approx200$k ultrasound image-mask pairs, SonoSAM demonstrates state-of-the-art performance on $8$ unseen ultrasound data-sets, outperforming competing methods by a significant margin on all metrics of interest. SonoSAM achieves average dice similarity score of $>90\%$ on almost all test data-sets within 2-6 clicks on an average, making it a valuable tool for annotating ultrasound images. We also extend SonoSAM to 3-D (2-D +t) applications and demonstrate superior performance making it a valuable tool for generating dense annotations from ultrasound cine-loops. Further, to increase practical utility of SonoSAM, we propose a two-step process of fine-tuning followed by knowledge distillation to a smaller footprint model without comprising the performance. We present detailed qualitative and quantitative comparisons of SonoSAM with state-of-the-art methods showcasing efficacy of SonoSAM as one of the first reliable, generic foundational model for ultrasound.
Style-Aware Radiology Report Generation with RadGraph and Few-Shot Prompting
Oct 26, 2023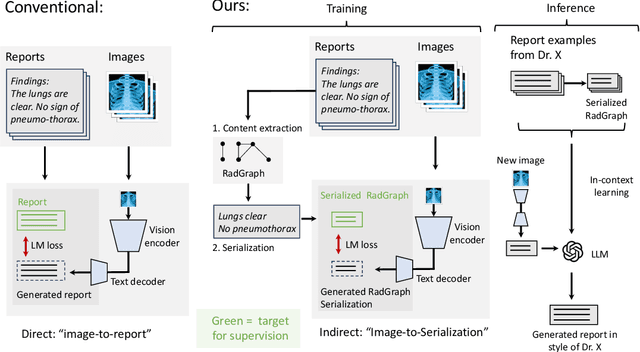

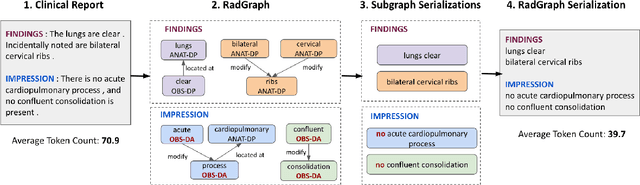

Automatically generated reports from medical images promise to improve the workflow of radiologists. Existing methods consider an image-to-report modeling task by directly generating a fully-fledged report from an image. However, this conflates the content of the report (e.g., findings and their attributes) with its style (e.g., format and choice of words), which can lead to clinically inaccurate reports. To address this, we propose a two-step approach for radiology report generation. First, we extract the content from an image; then, we verbalize the extracted content into a report that matches the style of a specific radiologist. For this, we leverage RadGraph -- a graph representation of reports -- together with large language models (LLMs). In our quantitative evaluations, we find that our approach leads to beneficial performance. Our human evaluation with clinical raters highlights that the AI-generated reports are indistinguishably tailored to the style of individual radiologist despite leveraging only a few examples as context.
SD4Match: Learning to Prompt Stable Diffusion Model for Semantic Matching
Oct 26, 2023In this paper, we address the challenge of matching semantically similar keypoints across image pairs. Existing research indicates that the intermediate output of the UNet within the Stable Diffusion (SD) can serve as robust image feature maps for such a matching task. We demonstrate that by employing a basic prompt tuning technique, the inherent potential of Stable Diffusion can be harnessed, resulting in a significant enhancement in accuracy over previous approaches. We further introduce a novel conditional prompting module that conditions the prompt on the local details of the input image pairs, leading to a further improvement in performance. We designate our approach as SD4Match, short for Stable Diffusion for Semantic Matching. Comprehensive evaluations of SD4Match on the PF-Pascal, PF-Willow, and SPair-71k datasets show that it sets new benchmarks in accuracy across all these datasets. Particularly, SD4Match outperforms the previous state-of-the-art by a margin of 12 percentage points on the challenging SPair-71k dataset.
Combining Shape Completion and Grasp Prediction for Fast and Versatile Grasping with a Multi-Fingered Hand
Oct 31, 2023Grasping objects with limited or no prior knowledge about them is a highly relevant skill in assistive robotics. Still, in this general setting, it has remained an open problem, especially when it comes to only partial observability and versatile grasping with multi-fingered hands. We present a novel, fast, and high fidelity deep learning pipeline consisting of a shape completion module that is based on a single depth image, and followed by a grasp predictor that is based on the predicted object shape. The shape completion network is based on VQDIF and predicts spatial occupancy values at arbitrary query points. As grasp predictor, we use our two-stage architecture that first generates hand poses using an autoregressive model and then regresses finger joint configurations per pose. Critical factors turn out to be sufficient data realism and augmentation, as well as special attention to difficult cases during training. Experiments on a physical robot platform demonstrate successful grasping of a wide range of household objects based on a depth image from a single viewpoint. The whole pipeline is fast, taking only about 1 s for completing the object's shape (0.7 s) and generating 1000 grasps (0.3 s).