 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
HAT: Hybrid Attention Transformer for Image Restoration
Sep 11, 2023
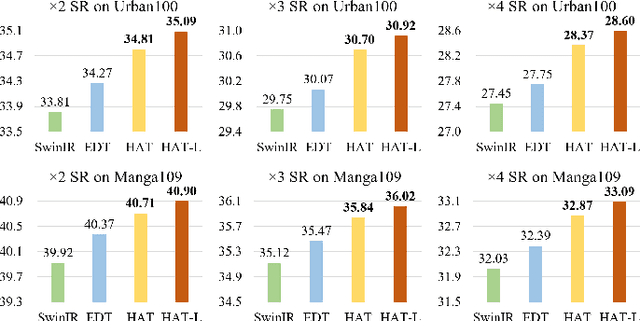
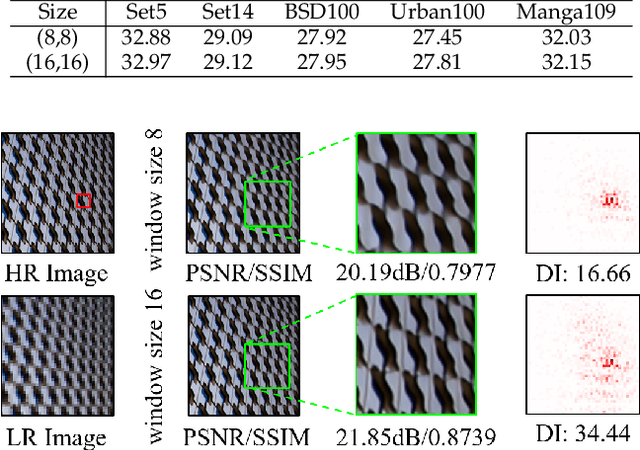
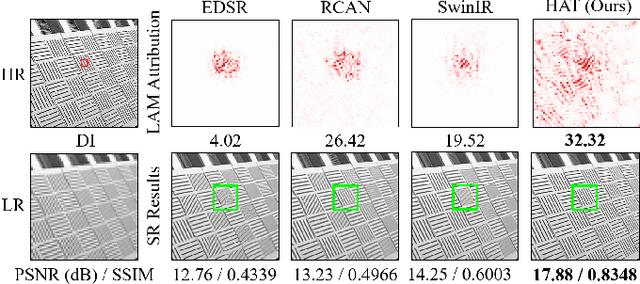
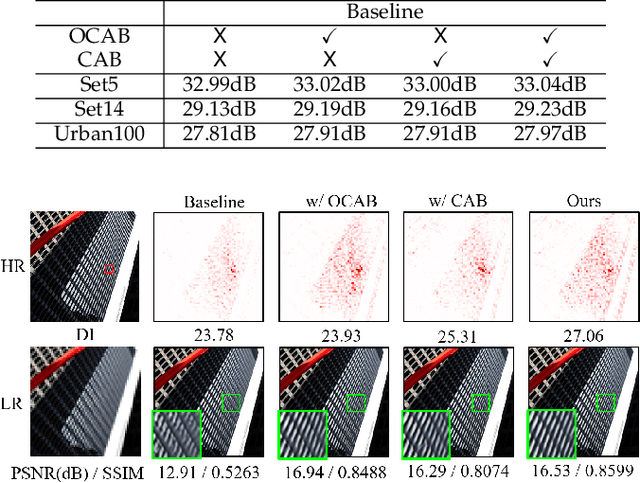
Transformer-based methods have shown impressive performance in image restoration tasks, such as image super-resolution and denoising. However, we find that these networks can only utilize a limited spatial range of input information through attribution analysis. This implies that the potential of Transformer is still not fully exploited in existing networks. In order to activate more input pixels for better restoration, we propose a new Hybrid Attention Transformer (HAT). It combines both channel attention and window-based self-attention schemes, thus making use of their complementary advantages. Moreover, to better aggregate the cross-window information, we introduce an overlapping cross-attention module to enhance the interaction between neighboring window features. In the training stage, we additionally adopt a same-task pre-training strategy to further exploit the potential of the model for further improvement. Extensive experiments have demonstrated the effectiveness of the proposed modules. We further scale up the model to show that the performance of the SR task can be greatly improved. Besides, we extend HAT to more image restoration applications, including real-world image super-resolution, Gaussian image denoising and image compression artifacts reduction. Experiments on benchmark and real-world datasets demonstrate that our HAT achieves state-of-the-art performance both quantitatively and qualitatively. Codes and models are publicly available at https://github.com/XPixelGroup/HAT.
Progressive Recurrent Network for Shadow Removal
Nov 01, 2023Single-image shadow removal is a significant task that is still unresolved. Most existing deep learning-based approaches attempt to remove the shadow directly, which can not deal with the shadow well. To handle this issue, we consider removing the shadow in a coarse-to-fine fashion and propose a simple but effective Progressive Recurrent Network (PRNet). The network aims to remove the shadow progressively, enabing us to flexibly adjust the number of iterations to strike a balance between performance and time. Our network comprises two parts: shadow feature extraction and progressive shadow removal. Specifically, the first part is a shallow ResNet which constructs the representations of the input shadow image on its original size, preventing the loss of high-frequency details caused by the downsampling operation. The second part has two critical components: the re-integration module and the update module. The proposed re-integration module can fully use the outputs of the previous iteration, providing input for the update module for further shadow removal. In this way, the proposed PRNet makes the whole process more concise and only uses 29% network parameters than the best published method. Extensive experiments on the three benchmarks, ISTD, ISTD+, and SRD, demonstrate that our method can effectively remove shadows and achieve superior performance.
Bidirectional Captioning for Clinically Accurate and Interpretable Models
Oct 30, 2023Vision-language pretraining has been shown to produce high-quality visual encoders which transfer efficiently to downstream computer vision tasks. While generative language models have gained widespread attention, image captioning has thus far been mostly overlooked as a form of cross-modal pretraining in favor of contrastive learning, especially in medical image analysis. In this paper, we experiment with bidirectional captioning of radiology reports as a form of pretraining and compare the quality and utility of learned embeddings with those from contrastive pretraining methods. We optimize a CNN encoder, transformer decoder architecture named RadTex for the radiology domain. Results show that not only does captioning pretraining yield visual encoders that are competitive with contrastive pretraining (CheXpert competition multi-label AUC of 89.4%), but also that our transformer decoder is capable of generating clinically relevant reports (captioning macro-F1 score of 0.349 using CheXpert labeler) and responding to prompts with targeted, interactive outputs.
SPADES: A Realistic Spacecraft Pose Estimation Dataset using Event Sensing
Nov 09, 2023In recent years, there has been a growing demand for improved autonomy for in-orbit operations such as rendezvous, docking, and proximity maneuvers, leading to increased interest in employing Deep Learning-based Spacecraft Pose Estimation techniques. However, due to limited access to real target datasets, algorithms are often trained using synthetic data and applied in the real domain, resulting in a performance drop due to the domain gap. State-of-the-art approaches employ Domain Adaptation techniques to mitigate this issue. In the search for viable solutions, event sensing has been explored in the past and shown to reduce the domain gap between simulations and real-world scenarios. Event sensors have made significant advancements in hardware and software in recent years. Moreover, the characteristics of the event sensor offer several advantages in space applications compared to RGB sensors. To facilitate further training and evaluation of DL-based models, we introduce a novel dataset, SPADES, comprising real event data acquired in a controlled laboratory environment and simulated event data using the same camera intrinsics. Furthermore, we propose an effective data filtering method to improve the quality of training data, thus enhancing model performance. Additionally, we introduce an image-based event representation that outperforms existing representations. A multifaceted baseline evaluation was conducted using different event representations, event filtering strategies, and algorithmic frameworks, and the results are summarized. The dataset will be made available at http://cvi2.uni.lu/spades.
Robust Retraining-free GAN Fingerprinting via Personalized Normalization
Nov 09, 2023In recent years, there has been significant growth in the commercial applications of generative models, licensed and distributed by model developers to users, who in turn use them to offer services. In this scenario, there is a need to track and identify the responsible user in the presence of a violation of the license agreement or any kind of malicious usage. Although there are methods enabling Generative Adversarial Networks (GANs) to include invisible watermarks in the images they produce, generating a model with a different watermark, referred to as a fingerprint, for each user is time- and resource-consuming due to the need to retrain the model to include the desired fingerprint. In this paper, we propose a retraining-free GAN fingerprinting method that allows model developers to easily generate model copies with the same functionality but different fingerprints. The generator is modified by inserting additional Personalized Normalization (PN) layers whose parameters (scaling and bias) are generated by two dedicated shallow networks (ParamGen Nets) taking the fingerprint as input. A watermark decoder is trained simultaneously to extract the fingerprint from the generated images. The proposed method can embed different fingerprints inside the GAN by just changing the input of the ParamGen Nets and performing a feedforward pass, without finetuning or retraining. The performance of the proposed method in terms of robustness against both model-level and image-level attacks is also superior to the state-of-the-art.
SA2-Net: Scale-aware Attention Network for Microscopic Image Segmentation
Sep 28, 2023Microscopic image segmentation is a challenging task, wherein the objective is to assign semantic labels to each pixel in a given microscopic image. While convolutional neural networks (CNNs) form the foundation of many existing frameworks, they often struggle to explicitly capture long-range dependencies. Although transformers were initially devised to address this issue using self-attention, it has been proven that both local and global features are crucial for addressing diverse challenges in microscopic images, including variations in shape, size, appearance, and target region density. In this paper, we introduce SA2-Net, an attention-guided method that leverages multi-scale feature learning to effectively handle diverse structures within microscopic images. Specifically, we propose scale-aware attention (SA2) module designed to capture inherent variations in scales and shapes of microscopic regions, such as cells, for accurate segmentation. This module incorporates local attention at each level of multi-stage features, as well as global attention across multiple resolutions. Furthermore, we address the issue of blurred region boundaries (e.g., cell boundaries) by introducing a novel upsampling strategy called the Adaptive Up-Attention (AuA) module. This module enhances the discriminative ability for improved localization of microscopic regions using an explicit attention mechanism. Extensive experiments on five challenging datasets demonstrate the benefits of our SA2-Net model. Our source code is publicly available at \url{https://github.com/mustansarfiaz/SA2-Net}.
Deformation-Invariant Neural Network and Its Applications in Distorted Image Restoration and Analysis
Oct 04, 2023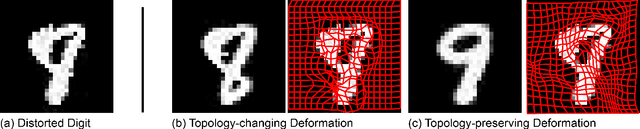

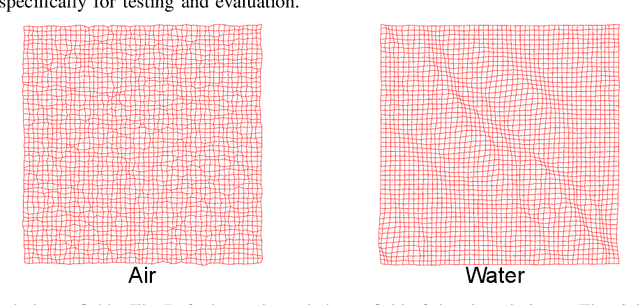

Images degraded by geometric distortions pose a significant challenge to imaging and computer vision tasks such as object recognition. Deep learning-based imaging models usually fail to give accurate performance for geometrically distorted images. In this paper, we propose the deformation-invariant neural network (DINN), a framework to address the problem of imaging tasks for geometrically distorted images. The DINN outputs consistent latent features for images that are geometrically distorted but represent the same underlying object or scene. The idea of DINN is to incorporate a simple component, called the quasiconformal transformer network (QCTN), into other existing deep networks for imaging tasks. The QCTN is a deep neural network that outputs a quasiconformal map, which can be used to transform a geometrically distorted image into an improved version that is closer to the distribution of natural or good images. It first outputs a Beltrami coefficient, which measures the quasiconformality of the output deformation map. By controlling the Beltrami coefficient, the local geometric distortion under the quasiconformal mapping can be controlled. The QCTN is lightweight and simple, which can be readily integrated into other existing deep neural networks to enhance their performance. Leveraging our framework, we have developed an image classification network that achieves accurate classification of distorted images. Our proposed framework has been applied to restore geometrically distorted images by atmospheric turbulence and water turbulence. DINN outperforms existing GAN-based restoration methods under these scenarios, demonstrating the effectiveness of the proposed framework. Additionally, we apply our proposed framework to the 1-1 verification of human face images under atmospheric turbulence and achieve satisfactory performance, further demonstrating the efficacy of our approach.
Progressive Text-to-Image Diffusion with Soft Latent Direction
Sep 18, 2023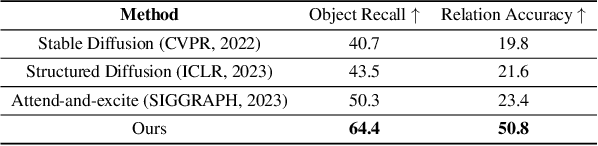

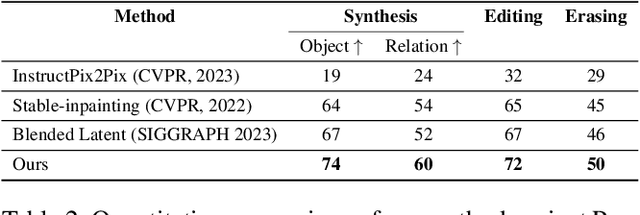
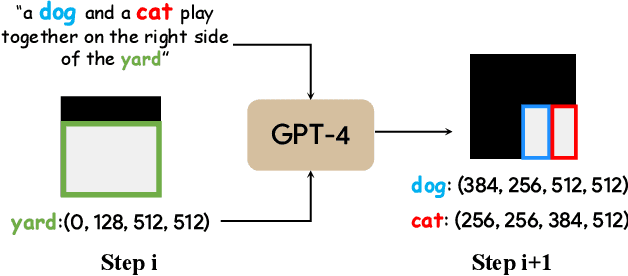
In spite of the rapidly evolving landscape of text-to-image generation, the synthesis and manipulation of multiple entities while adhering to specific relational constraints pose enduring challenges. This paper introduces an innovative progressive synthesis and editing operation that systematically incorporates entities into the target image, ensuring their adherence to spatial and relational constraints at each sequential step. Our key insight stems from the observation that while a pre-trained text-to-image diffusion model adeptly handles one or two entities, it often falters when dealing with a greater number. To address this limitation, we propose harnessing the capabilities of a Large Language Model (LLM) to decompose intricate and protracted text descriptions into coherent directives adhering to stringent formats. To facilitate the execution of directives involving distinct semantic operations-namely insertion, editing, and erasing-we formulate the Stimulus, Response, and Fusion (SRF) framework. Within this framework, latent regions are gently stimulated in alignment with each operation, followed by the fusion of the responsive latent components to achieve cohesive entity manipulation. Our proposed framework yields notable advancements in object synthesis, particularly when confronted with intricate and lengthy textual inputs. Consequently, it establishes a new benchmark for text-to-image generation tasks, further elevating the field's performance standards.
UNK-VQA: A Dataset and A Probe into Multi-modal Large Models' Abstention Ability
Oct 28, 2023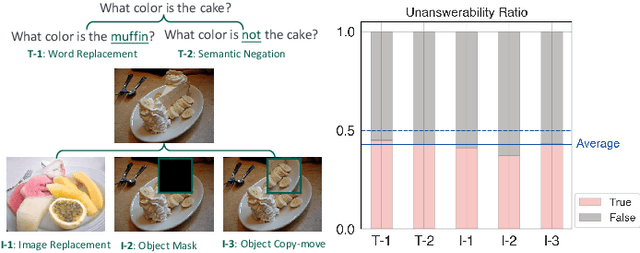


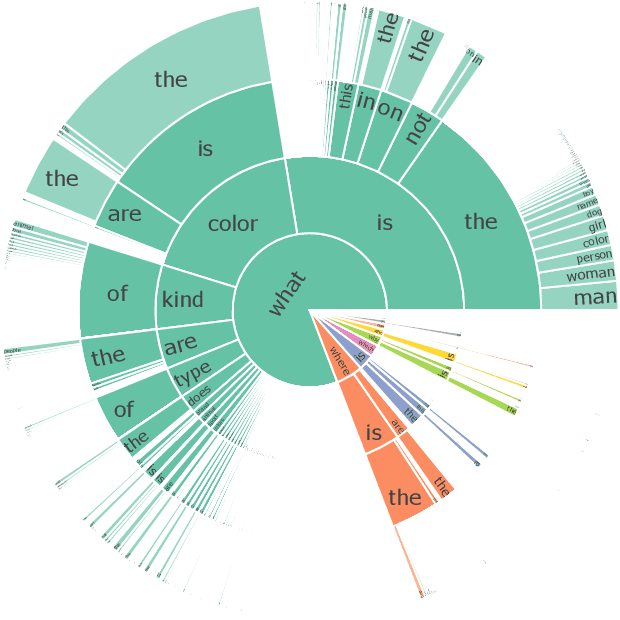
Teaching Visual Question Answering (VQA) models to refrain from answering unanswerable questions is necessary for building a trustworthy AI system. Existing studies, though have explored various aspects of VQA but somewhat ignored this particular attribute. This paper aims to bridge the research gap by contributing a comprehensive dataset, called UNK-VQA. The dataset is specifically designed to address the challenge of questions that models do not know. To this end, we first augment the existing data via deliberate perturbations on either the image or question. In specific, we carefully ensure that the question-image semantics remain close to the original unperturbed distribution. By this means, the identification of unanswerable questions becomes challenging, setting our dataset apart from others that involve mere image replacement. We then extensively evaluate the zero- and few-shot performance of several emerging multi-modal large models and discover their significant limitations when applied to our dataset. Additionally, we also propose a straightforward method to tackle these unanswerable questions. This dataset, we believe, will serve as a valuable benchmark for enhancing the abstention capability of VQA models, thereby leading to increased trustworthiness of AI systems. We have made the \href{https://github.com/guoyang9/UNK-VQA}{dataset} available to facilitate further exploration in this area.
A Bayesian optimization framework for the automatic tuning of MPC-based shared controllers
Nov 02, 2023This paper presents a Bayesian optimization framework for the automatic tuning of shared controllers which are defined as a Model Predictive Control (MPC) problem. The proposed framework includes the design of performance metrics as well as the representation of user inputs for simulation-based optimization. The framework is applied to the optimization of a shared controller for an Image Guided Therapy robot. VR-based user experiments confirm the increase in performance of the automatically tuned MPC shared controller with respect to a hand-tuned baseline version as well as its generalization ability.