 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Retargeting video with an end-to-end framework
Nov 08, 2023
Video holds significance in computer graphics applications. Because of the heterogeneous of digital devices, retargeting videos becomes an essential function to enhance user viewing experience in such applications. In the research of video retargeting, preserving the relevant visual content in videos, avoiding flicking, and processing time are the vital challenges. Extending image retargeting techniques to the video domain is challenging due to the high running time. Prior work of video retargeting mainly utilizes time-consuming preprocessing to analyze frames. Plus, being tolerant of different video content, avoiding important objects from shrinking, and the ability to play with arbitrary ratios are the limitations that need to be resolved in these systems requiring investigation. In this paper, we present an end-to-end RETVI method to retarget videos to arbitrary aspect ratios. We eliminate the computational bottleneck in the conventional approaches by designing RETVI with two modules, content feature analyzer (CFA) and adaptive deforming estimator (ADE). The extensive experiments and evaluations show that our system outperforms previous work in quality and running time. Visit our project website for more results at $\href{http://graphics.csie.ncku.edu.tw/RETVI}{http://graphics.csie.ncku.edu.tw/RETVI}$.
S$^3$AD: Semi-supervised Small Apple Detection in Orchard Environments
Nov 08, 2023Crop detection is integral for precision agriculture applications such as automated yield estimation or fruit picking. However, crop detection, e.g., apple detection in orchard environments remains challenging due to a lack of large-scale datasets and the small relative size of the crops in the image. In this work, we address these challenges by reformulating the apple detection task in a semi-supervised manner. To this end, we provide the large, high-resolution dataset MAD comprising 105 labeled images with 14,667 annotated apple instances and 4,440 unlabeled images. Utilizing this dataset, we also propose a novel Semi-Supervised Small Apple Detection system S$^3$AD based on contextual attention and selective tiling to improve the challenging detection of small apples, while limiting the computational overhead. We conduct an extensive evaluation on MAD and the MSU dataset, showing that S$^3$AD substantially outperforms strong fully-supervised baselines, including several small object detection systems, by up to $14.9\%$. Additionally, we exploit the detailed annotations of our dataset w.r.t. apple properties to analyze the influence of relative size or level of occlusion on the results of various systems, quantifying current challenges.
Apollo: Zero-shot MultiModal Reasoning with Multiple Experts
Oct 25, 2023
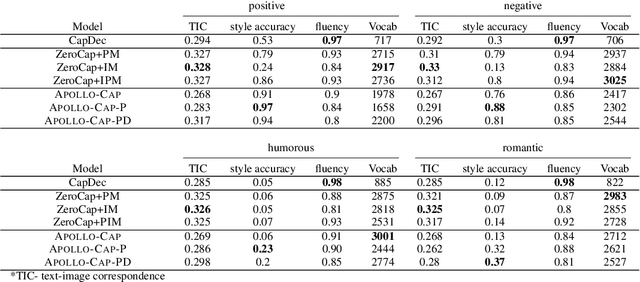


We propose a modular framework that leverages the expertise of different foundation models over different modalities and domains in order to perform a single, complex, multi-modal task, without relying on prompt engineering or otherwise tailor-made multi-modal training. Our approach enables decentralized command execution and allows each model to both contribute and benefit from the expertise of the other models. Our method can be extended to a variety of foundation models (including audio and vision), above and beyond only language models, as it does not depend on prompts. We demonstrate our approach on two tasks. On the well-known task of stylized image captioning, our experiments show that our approach outperforms semi-supervised state-of-the-art models, while being zero-shot and avoiding costly training, data collection, and prompt engineering. We further demonstrate this method on a novel task, audio-aware image captioning, in which an image and audio are given and the task is to generate text that describes the image within the context of the provided audio. Our code is available on GitHub.
Elastic Interaction Energy Loss for Traffic Image Segmentation
Oct 02, 2023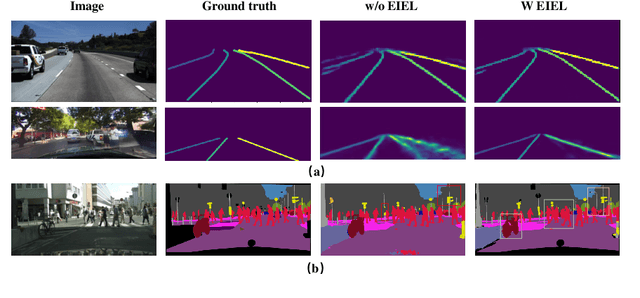
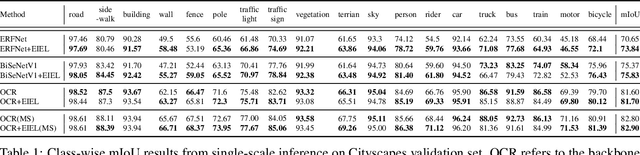

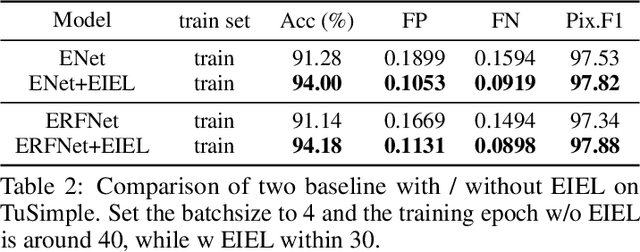
Segmentation is a pixel-level classification of images. The accuracy and fast inference speed of image segmentation are crucial for autonomous driving safety. Fine and complex geometric objects are the most difficult but important recognition targets in traffic scene, such as pedestrians, traffic signs and lanes. In this paper, a simple and efficient geometry-sensitive energy-based loss function is proposed to Convolutional Neural Network (CNN) for multi-class segmentation on real-time traffic scene understanding. To be specific, the elastic interaction energy (EIE) between two boundaries will drive the prediction moving toward the ground truth until completely overlap. The EIE loss function is incorporated into CNN to enhance accuracy on fine-scale structure segmentation. In particular, small or irregularly shaped objects can be identified more accurately, and discontinuity issues on slender objects can be improved. Our approach can be applied to different segmentation-based problems, such as urban scene segmentation and lane detection. We quantitatively and qualitatively analyze our method on three traffic datasets, including urban scene data Cityscapes, lane data TuSimple and CULane. The results show that our approach consistently improves performance, especially when using real-time, lightweight networks as the backbones, which is more suitable for autonomous driving.
Detecting internal disorders in fruit by CT. Part 1: Joint 2D to 3D image registration workflow for comparing multiple slice photographs and CT scans of apple fruit
Oct 03, 2023A large percentage of apples are affected by internal disorders after long-term storage, which makes them unacceptable in the supply chain. CT imaging is a promising technique for in-line detection of these disorders. Therefore, it is crucial to understand how different disorders affect the image features that can be observed in CT scans. This paper presents a workflow for creating datasets of image pairs of photographs of apple slices and their corresponding CT slices. By having CT and photographic images of the same part of the apple, the complementary information in both images can be used to study the processes underlying internal disorders and how internal disorders can be measured in CT images. The workflow includes data acquisition, image segmentation, image registration, and validation methods. The image registration method aligns all available slices of an apple within a single optimization problem, assuming that the slices are parallel. This method outperformed optimizing the alignment separately for each slice. The workflow was applied to create a dataset of 1347 slice photographs and their corresponding CT slices. The dataset was acquired from 107 'Kanzi' apples that had been stored in controlled atmosphere (CA) storage for 8 months. In this dataset, the distance between annotations in the slice photograph and the matching CT slice was, on average, $1.47 \pm 0.40$ mm. Our workflow allows collecting large datasets of accurately aligned photo-CT image pairs, which can help distinguish internal disorders with a similar appearance on CT. With slight modifications, a similar workflow can be applied to other fruits or MRI instead of CT scans.
TransReg: Cross-transformer as auto-registration module for multi-view mammogram mass detection
Nov 09, 2023Screening mammography is the most widely used method for early breast cancer detection, significantly reducing mortality rates. The integration of information from multi-view mammograms enhances radiologists' confidence and diminishes false-positive rates since they can examine on dual-view of the same breast to cross-reference the existence and location of the lesion. Inspired by this, we present TransReg, a Computer-Aided Detection (CAD) system designed to exploit the relationship between craniocaudal (CC), and mediolateral oblique (MLO) views. The system includes cross-transformer to model the relationship between the region of interest (RoIs) extracted by siamese Faster RCNN network for mass detection problems. Our work is the first time cross-transformer has been integrated into an object detection framework to model the relation between ipsilateral views. Our experimental evaluation on DDSM and VinDr-Mammo datasets shows that our TransReg, equipped with SwinT as a feature extractor achieves state-of-the-art performance. Specifically, at the false positive rate per image at 0.5, TransReg using SwinT gets a recall at 83.3% for DDSM dataset and 79.7% for VinDr-Mammo dataset. Furthermore, we conduct a comprehensive analysis to demonstrate that cross-transformer can function as an auto-registration module, aligning the masses in dual-view and utilizing this information to inform final predictions. It is a replication diagnostic workflow of expert radiologists
Chain of Images for Intuitively Reasoning
Nov 09, 2023The human brain is naturally equipped to comprehend and interpret visual information rapidly. When confronted with complex problems or concepts, we use flowcharts, sketches, and diagrams to aid our thought process. Leveraging this inherent ability can significantly enhance logical reasoning. However, current Large Language Models (LLMs) do not utilize such visual intuition to help their thinking. Even the most advanced version language models (e.g., GPT-4V and LLaVA) merely align images into textual space, which means their reasoning processes remain purely verbal. To mitigate such limitations, we present a Chain of Images (CoI) approach, which can convert complex language reasoning problems to simple pattern recognition by generating a series of images as intermediate representations. Furthermore, we have developed a CoI evaluation dataset encompassing 15 distinct domains where images can intuitively aid problem-solving. Based on this dataset, we aim to construct a benchmark to assess the capability of future multimodal large-scale models to leverage images for reasoning. In supporting our CoI reasoning, we introduce a symbolic multimodal large language model (SyMLLM) that generates images strictly based on language instructions and accepts both text and image as input. Experiments on Geometry, Chess and Common Sense tasks sourced from the CoI evaluation dataset show that CoI improves performance significantly over the pure-language Chain of Thoughts (CoT) baselines. The code is available at https://github.com/GraphPKU/CoI.
Improving Image Classification of Knee Radiographs: An Automated Image Labeling Approach
Sep 06, 2023Large numbers of radiographic images are available in knee radiology practices which could be used for training of deep learning models for diagnosis of knee abnormalities. However, those images do not typically contain readily available labels due to limitations of human annotations. The purpose of our study was to develop an automated labeling approach that improves the image classification model to distinguish normal knee images from those with abnormalities or prior arthroplasty. The automated labeler was trained on a small set of labeled data to automatically label a much larger set of unlabeled data, further improving the image classification performance for knee radiographic diagnosis. We developed our approach using 7,382 patients and validated it on a separate set of 637 patients. The final image classification model, trained using both manually labeled and pseudo-labeled data, had the higher weighted average AUC (WAUC: 0.903) value and higher AUC-ROC values among all classes (normal AUC-ROC: 0.894; abnormal AUC-ROC: 0.896, arthroplasty AUC-ROC: 0.990) compared to the baseline model (WAUC=0.857; normal AUC-ROC: 0.842; abnormal AUC-ROC: 0.848, arthroplasty AUC-ROC: 0.987), trained using only manually labeled data. DeLong tests show that the improvement is significant on normal (p-value<0.002) and abnormal (p-value<0.001) images. Our findings demonstrated that the proposed automated labeling approach significantly improves the performance of image classification for radiographic knee diagnosis, allowing for facilitating patient care and curation of large knee datasets.
CoFiI2P: Coarse-to-Fine Correspondences for Image-to-Point Cloud Registration
Sep 26, 2023Image-to-point cloud (I2P) registration is a fundamental task in the fields of robot navigation and mobile mapping. Existing I2P registration works estimate correspondences at the point-to-pixel level, neglecting the global alignment. However, I2P matching without high-level guidance from global constraints may converge to the local optimum easily. To solve the problem, this paper proposes CoFiI2P, a novel I2P registration network that extracts correspondences in a coarse-to-fine manner for the global optimal solution. First, the image and point cloud are fed into a Siamese encoder-decoder network for hierarchical feature extraction. Then, a coarse-to-fine matching module is designed to exploit features and establish resilient feature correspondences. Specifically, in the coarse matching block, a novel I2P transformer module is employed to capture the homogeneous and heterogeneous global information from image and point cloud. With the discriminate descriptors, coarse super-point-to-super-pixel matching pairs are estimated. In the fine matching module, point-to-pixel pairs are established with the super-point-to-super-pixel correspondence supervision. Finally, based on matching pairs, the transform matrix is estimated with the EPnP-RANSAC algorithm. Extensive experiments conducted on the KITTI dataset have demonstrated that CoFiI2P achieves a relative rotation error (RRE) of 2.25 degrees and a relative translation error (RTE) of 0.61 meters. These results represent a significant improvement of 14% in RRE and 52% in RTE compared to the current state-of-the-art (SOTA) method. The demo video for the experiments is available at https://youtu.be/TG2GBrJTuW4. The source code will be public at https://github.com/kang-1-2-3/CoFiI2P.
Personalized Food Image Classification: Benchmark Datasets and New Baseline
Sep 15, 2023Food image classification is a fundamental step of image-based dietary assessment, enabling automated nutrient analysis from food images. Many current methods employ deep neural networks to train on generic food image datasets that do not reflect the dynamism of real-life food consumption patterns, in which food images appear sequentially over time, reflecting the progression of what an individual consumes. Personalized food classification aims to address this problem by training a deep neural network using food images that reflect the consumption pattern of each individual. However, this problem is under-explored and there is a lack of benchmark datasets with individualized food consumption patterns due to the difficulty in data collection. In this work, we first introduce two benchmark personalized datasets including the Food101-Personal, which is created based on surveys of daily dietary patterns from participants in the real world, and the VFNPersonal, which is developed based on a dietary study. In addition, we propose a new framework for personalized food image classification by leveraging self-supervised learning and temporal image feature information. Our method is evaluated on both benchmark datasets and shows improved performance compared to existing works. The dataset has been made available at: https://skynet.ecn.purdue.edu/~pan161/dataset_personal.html