 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Medical Image Registration and Its Application in Retinal Images: A Review
Mar 25, 2024
Medical image registration is vital for disease diagnosis and treatment with its ability to merge diverse information of images, which may be captured under different times, angles, or modalities. Although several surveys have reviewed the development of medical image registration, these surveys have not systematically summarized methodologies of existing medical image registration methods. To this end, we provide a comprehensive review of these methods from traditional and deep learning-based directions, aiming to help audiences understand the development of medical image registration quickly. In particular, we review recent advances in retinal image registration at the end of each section, which has not attracted much attention. Additionally, we also discuss the current challenges of retinal image registration and provide insights and prospects for future research.
Content-aware Masked Image Modeling Transformer for Stereo Image Compression
Mar 20, 2024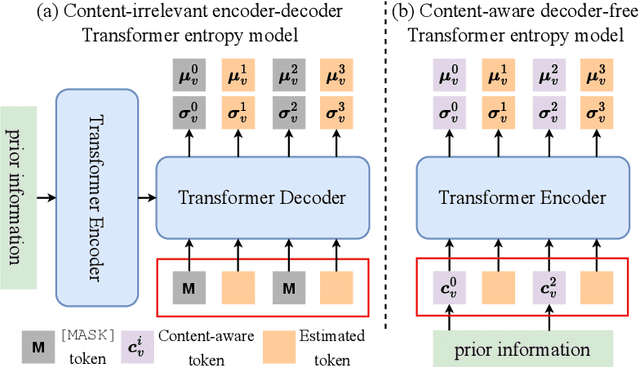
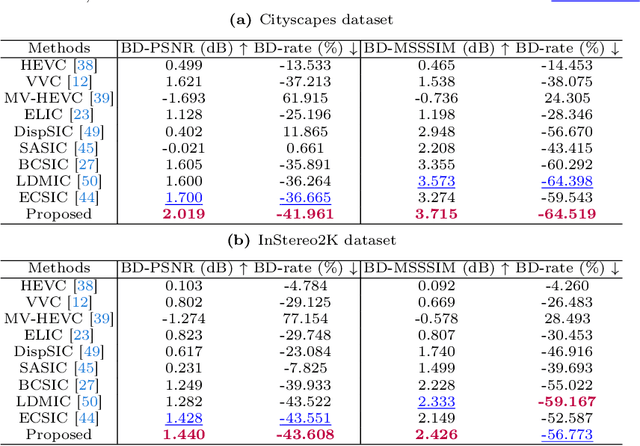
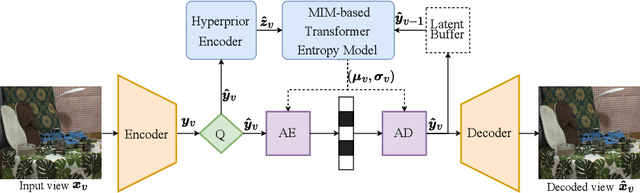
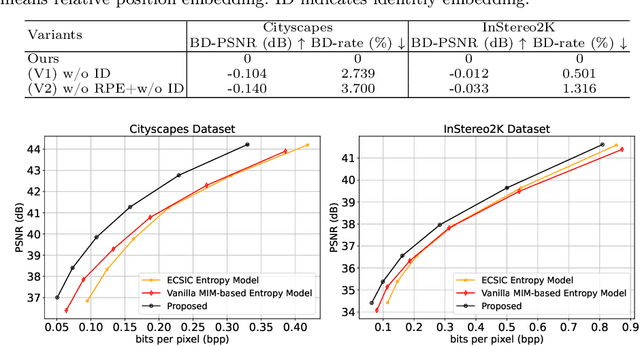
Existing learning-based stereo image codec adopt sophisticated transformation with simple entropy models derived from single image codecs to encode latent representations. However, those entropy models struggle to effectively capture the spatial-disparity characteristics inherent in stereo images, which leads to suboptimal rate-distortion results. In this paper, we propose a stereo image compression framework, named CAMSIC. CAMSIC independently transforms each image to latent representation and employs a powerful decoder-free Transformer entropy model to capture both spatial and disparity dependencies, by introducing a novel content-aware masked image modeling (MIM) technique. Our content-aware MIM facilitates efficient bidirectional interaction between prior information and estimated tokens, which naturally obviates the need for an extra Transformer decoder. Experiments show that our stereo image codec achieves state-of-the-art rate-distortion performance on two stereo image datasets Cityscapes and InStereo2K with fast encoding and decoding speed.
Tuning-Free Image Customization with Image and Text Guidance
Mar 19, 2024
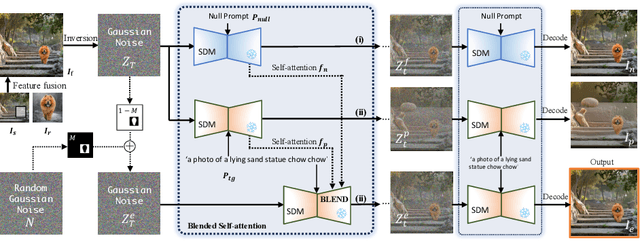


Despite significant advancements in image customization with diffusion models, current methods still have several limitations: 1) unintended changes in non-target areas when regenerating the entire image; 2) guidance solely by a reference image or text descriptions; and 3) time-consuming fine-tuning, which limits their practical application. In response, we introduce a tuning-free framework for simultaneous text-image-guided image customization, enabling precise editing of specific image regions within seconds. Our approach preserves the semantic features of the reference image subject while allowing modification of detailed attributes based on text descriptions. To achieve this, we propose an innovative attention blending strategy that blends self-attention features in the UNet decoder during the denoising process. To our knowledge, this is the first tuning-free method that concurrently utilizes text and image guidance for image customization in specific regions. Our approach outperforms previous methods in both human and quantitative evaluations, providing an efficient solution for various practical applications, such as image synthesis, design, and creative photography.
Knowledge-Enhanced Dual-stream Zero-shot Composed Image Retrieval
Mar 24, 2024We study the zero-shot Composed Image Retrieval (ZS-CIR) task, which is to retrieve the target image given a reference image and a description without training on the triplet datasets. Previous works generate pseudo-word tokens by projecting the reference image features to the text embedding space. However, they focus on the global visual representation, ignoring the representation of detailed attributes, e.g., color, object number and layout. To address this challenge, we propose a Knowledge-Enhanced Dual-stream zero-shot composed image retrieval framework (KEDs). KEDs implicitly models the attributes of the reference images by incorporating a database. The database enriches the pseudo-word tokens by providing relevant images and captions, emphasizing shared attribute information in various aspects. In this way, KEDs recognizes the reference image from diverse perspectives. Moreover, KEDs adopts an extra stream that aligns pseudo-word tokens with textual concepts, leveraging pseudo-triplets mined from image-text pairs. The pseudo-word tokens generated in this stream are explicitly aligned with fine-grained semantics in the text embedding space. Extensive experiments on widely used benchmarks, i.e. ImageNet-R, COCO object, Fashion-IQ and CIRR, show that KEDs outperforms previous zero-shot composed image retrieval methods.
ReMamber: Referring Image Segmentation with Mamba Twister
Mar 26, 2024Referring Image Segmentation (RIS) leveraging transformers has achieved great success on the interpretation of complex visual-language tasks. However, the quadratic computation cost makes it resource-consuming in capturing long-range visual-language dependencies. Fortunately, Mamba addresses this with efficient linear complexity in processing. However, directly applying Mamba to multi-modal interactions presents challenges, primarily due to inadequate channel interactions for the effective fusion of multi-modal data. In this paper, we propose ReMamber, a novel RIS architecture that integrates the power of Mamba with a multi-modal Mamba Twister block. The Mamba Twister explicitly models image-text interaction, and fuses textual and visual features through its unique channel and spatial twisting mechanism. We achieve the state-of-the-art on three challenging benchmarks. Moreover, we conduct thorough analyses of ReMamber and discuss other fusion designs using Mamba. These provide valuable perspectives for future research.
Using Stratified Sampling to Improve LIME Image Explanations
Mar 26, 2024We investigate the use of a stratified sampling approach for LIME Image, a popular model-agnostic explainable AI method for computer vision tasks, in order to reduce the artifacts generated by typical Monte Carlo sampling. Such artifacts are due to the undersampling of the dependent variable in the synthetic neighborhood around the image being explained, which may result in inadequate explanations due to the impossibility of fitting a linear regressor on the sampled data. We then highlight a connection with the Shapley theory, where similar arguments about undersampling and sample relevance were suggested in the past. We derive all the formulas and adjustment factors required for an unbiased stratified sampling estimator. Experiments show the efficacy of the proposed approach.
LaRE^2: Latent Reconstruction Error Based Method for Diffusion-Generated Image Detection
Mar 26, 2024The evolution of Diffusion Models has dramatically improved image generation quality, making it increasingly difficult to differentiate between real and generated images. This development, while impressive, also raises significant privacy and security concerns. In response to this, we propose a novel Latent REconstruction error guided feature REfinement method (LaRE^2) for detecting the diffusion-generated images. We come up with the Latent Reconstruction Error (LaRE), the first reconstruction-error based feature in the latent space for generated image detection. LaRE surpasses existing methods in terms of feature extraction efficiency while preserving crucial cues required to differentiate between the real and the fake. To exploit LaRE, we propose an Error-Guided feature REfinement module (EGRE), which can refine the image feature guided by LaRE to enhance the discriminativeness of the feature. Our EGRE utilizes an align-then-refine mechanism, which effectively refines the image feature for generated-image detection from both spatial and channel perspectives. Extensive experiments on the large-scale GenImage benchmark demonstrate the superiority of our LaRE^2, which surpasses the best SoTA method by up to 11.9%/12.1% average ACC/AP across 8 different image generators. LaRE also surpasses existing methods in terms of feature extraction cost, delivering an impressive speed enhancement of 8 times.
Multi-scale Unified Network for Image Classification
Mar 27, 2024Convolutional Neural Networks (CNNs) have advanced significantly in visual representation learning and recognition. However, they face notable challenges in performance and computational efficiency when dealing with real-world, multi-scale image inputs. Conventional methods rescale all input images into a fixed size, wherein a larger fixed size favors performance but rescaling small size images to a larger size incurs digitization noise and increased computation cost. In this work, we carry out a comprehensive, layer-wise investigation of CNN models in response to scale variation, based on Centered Kernel Alignment (CKA) analysis. The observations reveal lower layers are more sensitive to input image scale variations than high-level layers. Inspired by this insight, we propose Multi-scale Unified Network (MUSN) consisting of multi-scale subnets, a unified network, and scale-invariant constraint. Our method divides the shallow layers into multi-scale subnets to enable feature extraction from multi-scale inputs, and the low-level features are unified in deep layers for extracting high-level semantic features. A scale-invariant constraint is posed to maintain feature consistency across different scales. Extensive experiments on ImageNet and other scale-diverse datasets, demonstrate that MSUN achieves significant improvements in both model performance and computational efficiency. Particularly, MSUN yields an accuracy increase up to 44.53% and diminishes FLOPs by 7.01-16.13% in multi-scale scenarios.
Learning Strategies For Successful Crowd Navigation
Apr 09, 2024Teaching autonomous mobile robots to successfully navigate human crowds is a challenging task. Not only does it require planning, but it requires maintaining social norms which may differ from one context to another. Here we focus on crowd navigation, using a neural network to learn specific strategies in-situ with a robot. This allows us to take into account human behavior and reactions toward a real robot as well as learn strategies that are specific to various scenarios in that context. A CNN takes a top-down image of the scene as input and outputs the next action for the robot to take in terms of speed and angle. Here we present the method, experimental results, and quantitatively evaluate our approach.
FairRAG: Fair Human Generation via Fair Retrieval Augmentation
Apr 05, 2024
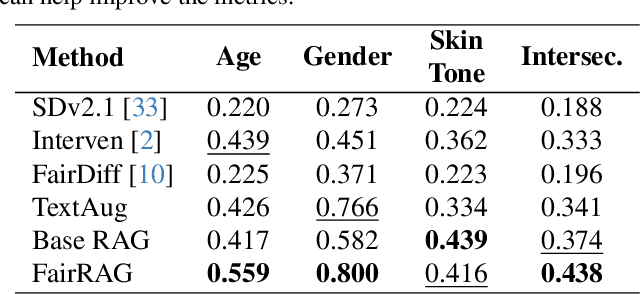
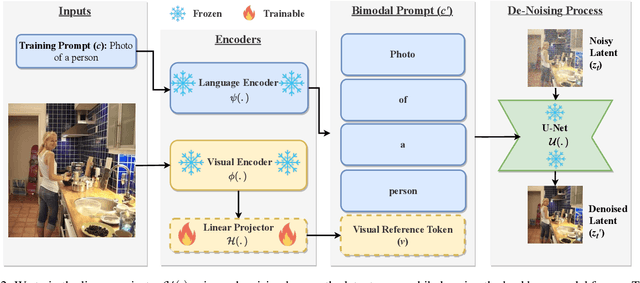
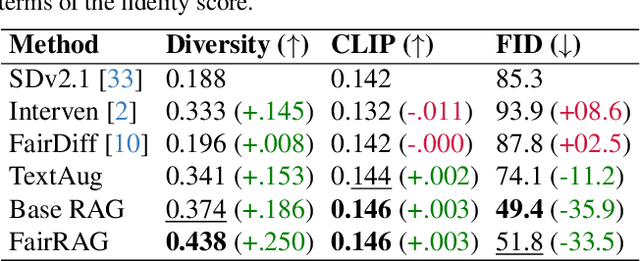
Existing text-to-image generative models reflect or even amplify societal biases ingrained in their training data. This is especially concerning for human image generation where models are biased against certain demographic groups. Existing attempts to rectify this issue are hindered by the inherent limitations of the pre-trained models and fail to substantially improve demographic diversity. In this work, we introduce Fair Retrieval Augmented Generation (FairRAG), a novel framework that conditions pre-trained generative models on reference images retrieved from an external image database to improve fairness in human generation. FairRAG enables conditioning through a lightweight linear module that projects reference images into the textual space. To enhance fairness, FairRAG applies simple-yet-effective debiasing strategies, providing images from diverse demographic groups during the generative process. Extensive experiments demonstrate that FairRAG outperforms existing methods in terms of demographic diversity, image-text alignment, and image fidelity while incurring minimal computational overhead during inference.