 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
CP-EB: Talking Face Generation with Controllable Pose and Eye Blinking Embedding
Nov 15, 2023
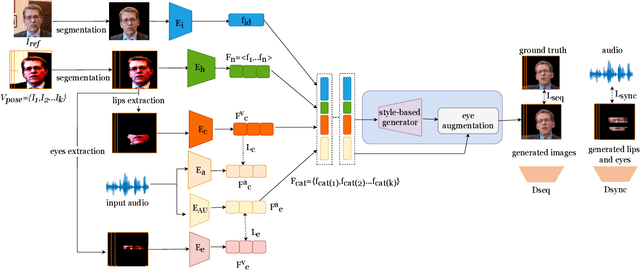
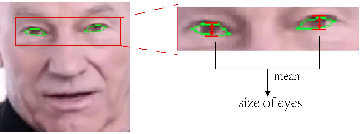
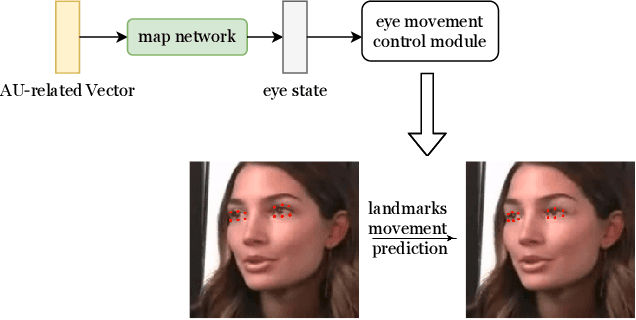

This paper proposes a talking face generation method named "CP-EB" that takes an audio signal as input and a person image as reference, to synthesize a photo-realistic people talking video with head poses controlled by a short video clip and proper eye blinking embedding. It's noted that not only the head pose but also eye blinking are both important aspects for deep fake detection. The implicit control of poses by video has already achieved by the state-of-art work. According to recent research, eye blinking has weak correlation with input audio which means eye blinks extraction from audio and generation are possible. Hence, we propose a GAN-based architecture to extract eye blink feature from input audio and reference video respectively and employ contrastive training between them, then embed it into the concatenated features of identity and poses to generate talking face images. Experimental results show that the proposed method can generate photo-realistic talking face with synchronous lips motions, natural head poses and blinking eyes.
MMC: Advancing Multimodal Chart Understanding with Large-scale Instruction Tuning
Nov 15, 2023With the rapid development of large language models (LLMs) and their integration into large multimodal models (LMMs), there has been impressive progress in zero-shot completion of user-oriented vision-language tasks. However, a gap remains in the domain of chart image understanding due to the distinct abstract components in charts. To address this, we introduce a large-scale MultiModal Chart Instruction (MMC-Instruction) dataset comprising 600k instances supporting diverse tasks and chart types. Leveraging this data, we develop MultiModal Chart Assistant (MMCA), an LMM that achieves state-of-the-art performance on existing chart QA benchmarks. Recognizing the need for a comprehensive evaluation of LMM chart understanding, we also propose a MultiModal Chart Benchmark (MMC-Benchmark), a comprehensive human-annotated benchmark with 9 distinct tasks evaluating reasoning capabilities over charts. Extensive experiments on MMC-Benchmark reveal the limitations of existing LMMs on correctly interpreting charts, even for the most recent GPT-4V model. Our work provides an instruction-tuning methodology and benchmark to advance multimodal understanding of charts.
Using Stochastic Gradient Descent to Smooth Nonconvex Functions: Analysis of Implicit Graduated Optimization with Optimal Noise Scheduling
Nov 15, 2023The graduated optimization approach is a heuristic method for finding globally optimal solutions for nonconvex functions and has been theoretically analyzed in several studies. This paper defines a new family of nonconvex functions for graduated optimization, discusses their sufficient conditions, and provides a convergence analysis of the graduated optimization algorithm for them. It shows that stochastic gradient descent (SGD) with mini-batch stochastic gradients has the effect of smoothing the function, the degree of which is determined by the learning rate and batch size. This finding provides theoretical insights from a graduated optimization perspective on why large batch sizes fall into sharp local minima, why decaying learning rates and increasing batch sizes are superior to fixed learning rates and batch sizes, and what the optimal learning rate scheduling is. To the best of our knowledge, this is the first paper to provide a theoretical explanation for these aspects. Moreover, a new graduated optimization framework that uses a decaying learning rate and increasing batch size is analyzed and experimental results of image classification that support our theoretical findings are reported.
EyeLS: Shadow-Guided Instrument Landing System for Intraocular Target Approaching in Robotic Eye Surgery
Nov 15, 2023Robotic ophthalmic surgery is an emerging technology to facilitate high-precision interventions such as retina penetration in subretinal injection and removal of floating tissues in retinal detachment depending on the input imaging modalities such as microscopy and intraoperative OCT (iOCT). Although iOCT is explored to locate the needle tip within its range-limited ROI, it is still difficult to coordinate iOCT's motion with the needle, especially at the initial target-approaching stage. Meanwhile, due to 2D perspective projection and thus the loss of depth information, current image-based methods cannot effectively estimate the needle tip's trajectory towards both retinal and floating targets. To address this limitation, we propose to use the shadow positions of the target and the instrument tip to estimate their relative depth position and accordingly optimize the instrument tip's insertion trajectory until the tip approaches targets within iOCT's scanning area. Our method succeeds target approaching on a retina model, and achieves an average depth error of 0.0127 mm and 0.3473 mm for floating and retinal targets respectively in the surgical simulator without damaging the retina.
CogVLM: Visual Expert for Pretrained Language Models
Nov 06, 2023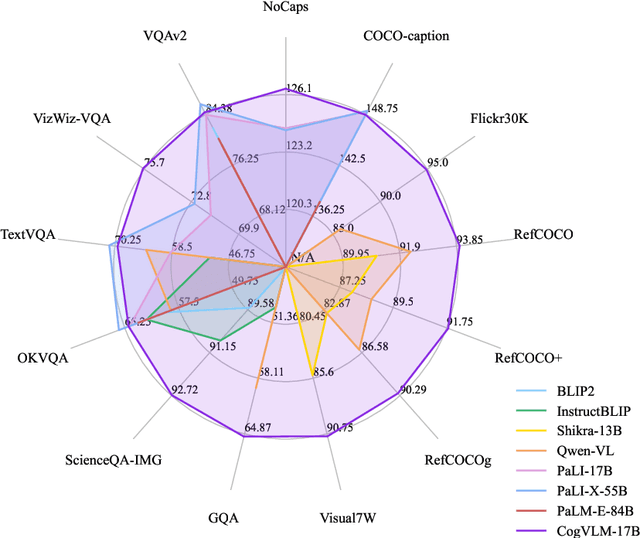
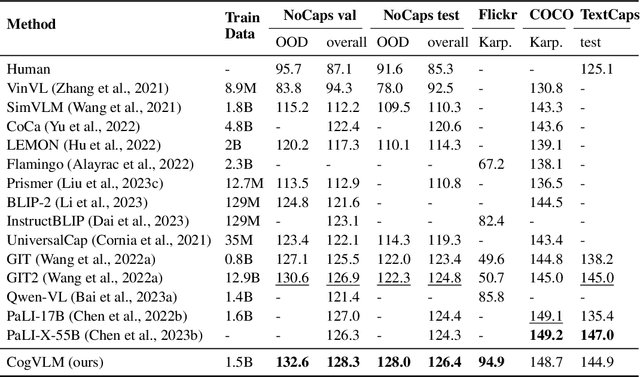

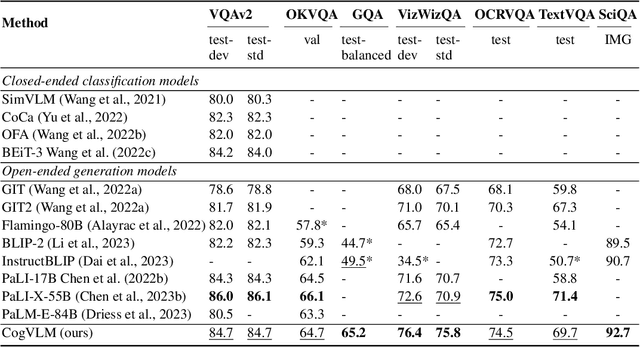
We introduce CogVLM, a powerful open-source visual language foundation model. Different from the popular shallow alignment method which maps image features into the input space of language model, CogVLM bridges the gap between the frozen pretrained language model and image encoder by a trainable visual expert module in the attention and FFN layers. As a result, CogVLM enables deep fusion of vision language features without sacrificing any performance on NLP tasks. CogVLM-17B achieves state-of-the-art performance on 10 classic cross-modal benchmarks, including NoCaps, Flicker30k captioning, RefCOCO, RefCOCO+, RefCOCOg, Visual7W, GQA, ScienceQA, VizWiz VQA and TDIUC, and ranks the 2nd on VQAv2, OKVQA, TextVQA, COCO captioning, etc., surpassing or matching PaLI-X 55B. Codes and checkpoints are available at https://github.com/THUDM/CogVLM.
InstructCV: Instruction-Tuned Text-to-Image Diffusion Models as Vision Generalists
Sep 30, 2023Recent advances in generative diffusion models have enabled text-controlled synthesis of realistic and diverse images with impressive quality. Despite these remarkable advances, the application of text-to-image generative models in computer vision for standard visual recognition tasks remains limited. The current de facto approach for these tasks is to design model architectures and loss functions that are tailored to the task at hand. In this paper, we develop a unified language interface for computer vision tasks that abstracts away task-specific design choices and enables task execution by following natural language instructions. Our approach involves casting multiple computer vision tasks as text-to-image generation problems. Here, the text represents an instruction describing the task, and the resulting image is a visually-encoded task output. To train our model, we pool commonly-used computer vision datasets covering a range of tasks, including segmentation, object detection, depth estimation, and classification. We then use a large language model to paraphrase prompt templates that convey the specific tasks to be conducted on each image, and through this process, we create a multi-modal and multi-task training dataset comprising input and output images along with annotated instructions. Following the InstructPix2Pix architecture, we apply instruction-tuning to a text-to-image diffusion model using our constructed dataset, steering its functionality from a generative model to an instruction-guided multi-task vision learner. Experiments demonstrate that our model, dubbed InstructCV, performs competitively compared to other generalist and task-specific vision models. Moreover, it exhibits compelling generalization capabilities to unseen data, categories, and user instructions.
LT-ViT: A Vision Transformer for multi-label Chest X-ray classification
Nov 13, 2023Vision Transformers (ViTs) are widely adopted in medical imaging tasks, and some existing efforts have been directed towards vision-language training for Chest X-rays (CXRs). However, we envision that there still exists a potential for improvement in vision-only training for CXRs using ViTs, by aggregating information from multiple scales, which has been proven beneficial for non-transformer networks. Hence, we have developed LT-ViT, a transformer that utilizes combined attention between image tokens and randomly initialized auxiliary tokens that represent labels. Our experiments demonstrate that LT-ViT (1) surpasses the state-of-the-art performance using pure ViTs on two publicly available CXR datasets, (2) is generalizable to other pre-training methods and therefore is agnostic to model initialization, and (3) enables model interpretability without grad-cam and its variants.
FIRST: A Million-Entry Dataset for Text-Driven Fashion Synthesis and Design
Nov 13, 2023Text-driven fashion synthesis and design is an extremely valuable part of artificial intelligence generative content(AIGC), which has the potential to propel a tremendous revolution in the traditional fashion industry. To advance the research on text-driven fashion synthesis and design, we introduce a new dataset comprising a million high-resolution fashion images with rich structured textual(FIRST) descriptions. In the FIRST, there is a wide range of attire categories and each image-paired textual description is organized at multiple hierarchical levels. Experiments on prevalent generative models trained over FISRT show the necessity of FIRST. We invite the community to further develop more intelligent fashion synthesis and design systems that make fashion design more creative and imaginative based on our dataset. The dataset will be released soon.
Multi-domain improves out-of-distribution and data-limited scenarios for medical image analysis
Oct 10, 2023Current machine learning methods for medical image analysis primarily focus on developing models tailored for their specific tasks, utilizing data within their target domain. These specialized models tend to be data-hungry and often exhibit limitations in generalizing to out-of-distribution samples. Recently, foundation models have been proposed, which combine data from various domains and demonstrate excellent generalization capabilities. Building upon this, this work introduces the incorporation of diverse medical image domains, including different imaging modalities like X-ray, MRI, CT, and ultrasound images, as well as various viewpoints such as axial, coronal, and sagittal views. We refer to this approach as multi-domain model and compare its performance to that of specialized models. Our findings underscore the superior generalization capabilities of multi-domain models, particularly in scenarios characterized by limited data availability and out-of-distribution, frequently encountered in healthcare applications. The integration of diverse data allows multi-domain models to utilize shared information across domains, enhancing the overall outcomes significantly. To illustrate, for organ recognition, multi-domain model can enhance accuracy by up to 10% compared to conventional specialized models.
NeuroQuantify -- An Image Analysis Software for Detection and Quantification of Neurons and Neurites using Deep Learning
Oct 19, 2023The segmentation of cells and neurites in microscopy images of neuronal networks provides valuable quantitative information about neuron growth and neuronal differentiation, including the number of cells, neurites, neurite length and neurite orientation. This information is essential for assessing the development of neuronal networks in response to extracellular stimuli, which is useful for studying neuronal structures, for example, the study of neurodegenerative diseases and pharmaceuticals. However, automatic and accurate analysis of neuronal structures from phase contrast images has remained challenging. To address this, we have developed NeuroQuantify, an open-source software that uses deep learning to efficiently and quickly segment cells and neurites in phase contrast microscopy images. NeuroQuantify offers several key features: (i) automatic detection of cells and neurites; (ii) post-processing of the images for the quantitative neurite length measurement based on segmentation of phase contrast microscopy images, and (iii) identification of neurite orientations. The user-friendly NeuroQuantify software can be installed and freely downloaded from GitHub https://github.com/StanleyZ0528/neural-image-segmentation.