 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Decompose Semantic Shifts for Composed Image Retrieval
Sep 18, 2023
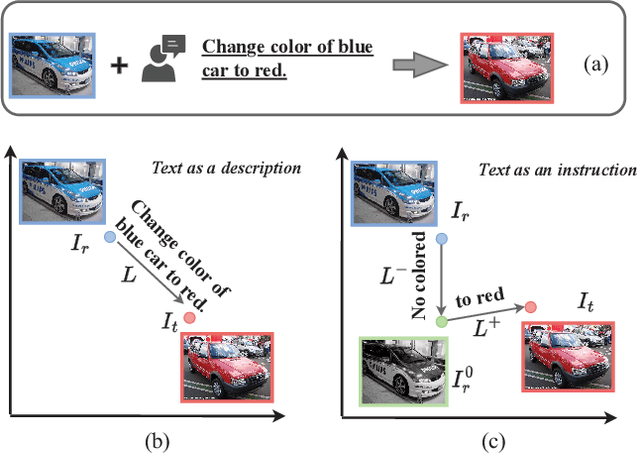
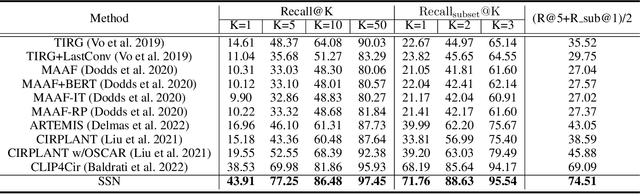

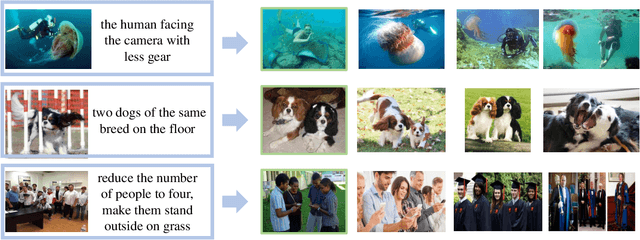
Composed image retrieval is a type of image retrieval task where the user provides a reference image as a starting point and specifies a text on how to shift from the starting point to the desired target image. However, most existing methods focus on the composition learning of text and reference images and oversimplify the text as a description, neglecting the inherent structure and the user's shifting intention of the texts. As a result, these methods typically take shortcuts that disregard the visual cue of the reference images. To address this issue, we reconsider the text as instructions and propose a Semantic Shift network (SSN) that explicitly decomposes the semantic shifts into two steps: from the reference image to the visual prototype and from the visual prototype to the target image. Specifically, SSN explicitly decomposes the instructions into two components: degradation and upgradation, where the degradation is used to picture the visual prototype from the reference image, while the upgradation is used to enrich the visual prototype into the final representations to retrieve the desired target image. The experimental results show that the proposed SSN demonstrates a significant improvement of 5.42% and 1.37% on the CIRR and FashionIQ datasets, respectively, and establishes a new state-of-the-art performance. Codes will be publicly available.
Progressive Neural Compression for Adaptive Image Offloading under Timing Constraints
Oct 08, 2023IoT devices are increasingly the source of data for machine learning (ML) applications running on edge servers. Data transmissions from devices to servers are often over local wireless networks whose bandwidth is not just limited but, more importantly, variable. Furthermore, in cyber-physical systems interacting with the physical environment, image offloading is also commonly subject to timing constraints. It is, therefore, important to develop an adaptive approach that maximizes the inference performance of ML applications under timing constraints and the resource constraints of IoT devices. In this paper, we use image classification as our target application and propose progressive neural compression (PNC) as an efficient solution to this problem. Although neural compression has been used to compress images for different ML applications, existing solutions often produce fixed-size outputs that are unsuitable for timing-constrained offloading over variable bandwidth. To address this limitation, we train a multi-objective rateless autoencoder that optimizes for multiple compression rates via stochastic taildrop to create a compression solution that produces features ordered according to their importance to inference performance. Features are then transmitted in that order based on available bandwidth, with classification ultimately performed using the (sub)set of features received by the deadline. We demonstrate the benefits of PNC over state-of-the-art neural compression approaches and traditional compression methods on a testbed comprising an IoT device and an edge server connected over a wireless network with varying bandwidth.
Synthetic Image Detection: Highlights from the IEEE Video and Image Processing Cup 2022 Student Competition
Sep 21, 2023
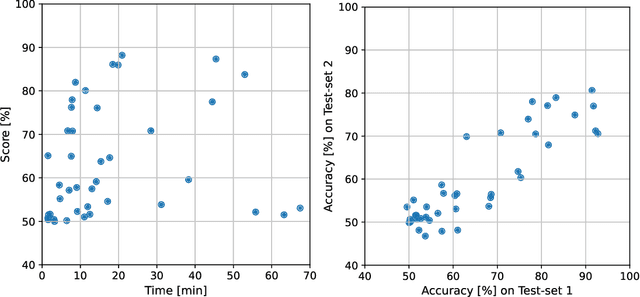
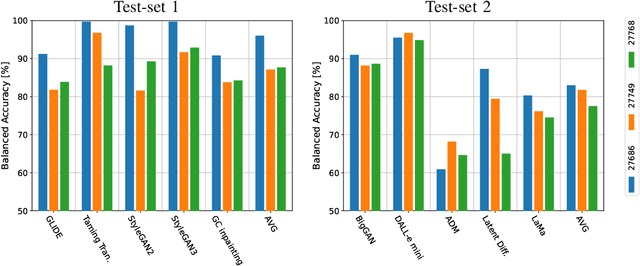
The Video and Image Processing (VIP) Cup is a student competition that takes place each year at the IEEE International Conference on Image Processing. The 2022 IEEE VIP Cup asked undergraduate students to develop a system capable of distinguishing pristine images from generated ones. The interest in this topic stems from the incredible advances in the AI-based generation of visual data, with tools that allows the synthesis of highly realistic images and videos. While this opens up a large number of new opportunities, it also undermines the trustworthiness of media content and fosters the spread of disinformation on the internet. Recently there was strong concern about the generation of extremely realistic images by means of editing software that includes the recent technology on diffusion models. In this context, there is a need to develop robust and automatic tools for synthetic image detection.
GPT-4V(ision) as a Generalist Evaluator for Vision-Language Tasks
Nov 02, 2023Automatically evaluating vision-language tasks is challenging, especially when it comes to reflecting human judgments due to limitations in accounting for fine-grained details. Although GPT-4V has shown promising results in various multi-modal tasks, leveraging GPT-4V as a generalist evaluator for these tasks has not yet been systematically explored. We comprehensively validate GPT-4V's capabilities for evaluation purposes, addressing tasks ranging from foundational image-to-text and text-to-image synthesis to high-level image-to-image translations and multi-images to text alignment. We employ two evaluation methods, single-answer grading and pairwise comparison, using GPT-4V. Notably, GPT-4V shows promising agreement with humans across various tasks and evaluation methods, demonstrating immense potential for multi-modal LLMs as evaluators. Despite limitations like restricted visual clarity grading and real-world complex reasoning, its ability to provide human-aligned scores enriched with detailed explanations is promising for universal automatic evaluator.
On Manipulating Scene Text in the Wild with Diffusion Models
Nov 03, 2023
Diffusion models have gained attention for image editing yielding impressive results in text-to-image tasks. On the downside, one might notice that generated images of stable diffusion models suffer from deteriorated details. This pitfall impacts image editing tasks that require information preservation e.g., scene text editing. As a desired result, the model must show the capability to replace the text on the source image to the target text while preserving the details e.g., color, font size, and background. To leverage the potential of diffusion models, in this work, we introduce Diffusion-BasEd Scene Text manipulation Network so-called DBEST. Specifically, we design two adaptation strategies, namely one-shot style adaptation and text-recognition guidance. In experiments, we thoroughly assess and compare our proposed method against state-of-the-arts on various scene text datasets, then provide extensive ablation studies for each granularity to analyze our performance gain. Also, we demonstrate the effectiveness of our proposed method to synthesize scene text indicated by competitive Optical Character Recognition (OCR) accuracy. Our method achieves 94.15% and 98.12% on COCO-text and ICDAR2013 datasets for character-level evaluation.
WATUNet: A Deep Neural Network for Segmentation of Volumetric Sweep Imaging Ultrasound
Nov 17, 2023Objective. Limited access to breast cancer diagnosis globally leads to delayed treatment. Ultrasound, an effective yet underutilized method, requires specialized training for sonographers, which hinders its widespread use. Approach. Volume sweep imaging (VSI) is an innovative approach that enables untrained operators to capture high-quality ultrasound images. Combined with deep learning, like convolutional neural networks (CNNs), it can potentially transform breast cancer diagnosis, enhancing accuracy, saving time and costs, and improving patient outcomes. The widely used UNet architecture, known for medical image segmentation, has limitations, such as vanishing gradients and a lack of multi-scale feature extraction and selective region attention. In this study, we present a novel segmentation model known as Wavelet_Attention_UNet (WATUNet). In this model, we incorporate wavelet gates (WGs) and attention gates (AGs) between the encoder and decoder instead of a simple connection to overcome the limitations mentioned, thereby improving model performance. Main results. Two datasets are utilized for the analysis. The public "Breast Ultrasound Images" (BUSI) dataset of 780 images and a VSI dataset of 3818 images. Both datasets contained segmented lesions categorized into three types: no mass, benign mass, and malignant mass. Our segmentation results show superior performance compared to other deep networks. The proposed algorithm attained a Dice coefficient of 0.94 and an F1 score of 0.94 on the VSI dataset and scored 0.93 and 0.94 on the public dataset, respectively.
Control3D: Towards Controllable Text-to-3D Generation
Nov 09, 2023Recent remarkable advances in large-scale text-to-image diffusion models have inspired a significant breakthrough in text-to-3D generation, pursuing 3D content creation solely from a given text prompt. However, existing text-to-3D techniques lack a crucial ability in the creative process: interactively control and shape the synthetic 3D contents according to users' desired specifications (e.g., sketch). To alleviate this issue, we present the first attempt for text-to-3D generation conditioning on the additional hand-drawn sketch, namely Control3D, which enhances controllability for users. In particular, a 2D conditioned diffusion model (ControlNet) is remoulded to guide the learning of 3D scene parameterized as NeRF, encouraging each view of 3D scene aligned with the given text prompt and hand-drawn sketch. Moreover, we exploit a pre-trained differentiable photo-to-sketch model to directly estimate the sketch of the rendered image over synthetic 3D scene. Such estimated sketch along with each sampled view is further enforced to be geometrically consistent with the given sketch, pursuing better controllable text-to-3D generation. Through extensive experiments, we demonstrate that our proposal can generate accurate and faithful 3D scenes that align closely with the input text prompts and sketches.
InstructCV: Instruction-Tuned Text-to-Image Diffusion Models as Vision Generalists
Sep 30, 2023Recent advances in generative diffusion models have enabled text-controlled synthesis of realistic and diverse images with impressive quality. Despite these remarkable advances, the application of text-to-image generative models in computer vision for standard visual recognition tasks remains limited. The current de facto approach for these tasks is to design model architectures and loss functions that are tailored to the task at hand. In this paper, we develop a unified language interface for computer vision tasks that abstracts away task-specific design choices and enables task execution by following natural language instructions. Our approach involves casting multiple computer vision tasks as text-to-image generation problems. Here, the text represents an instruction describing the task, and the resulting image is a visually-encoded task output. To train our model, we pool commonly-used computer vision datasets covering a range of tasks, including segmentation, object detection, depth estimation, and classification. We then use a large language model to paraphrase prompt templates that convey the specific tasks to be conducted on each image, and through this process, we create a multi-modal and multi-task training dataset comprising input and output images along with annotated instructions. Following the InstructPix2Pix architecture, we apply instruction-tuning to a text-to-image diffusion model using our constructed dataset, steering its functionality from a generative model to an instruction-guided multi-task vision learner. Experiments demonstrate that our model, dubbed InstructCV, performs competitively compared to other generalist and task-specific vision models. Moreover, it exhibits compelling generalization capabilities to unseen data, categories, and user instructions.
Morphology-Enhanced CAM-Guided SAM for weakly supervised Breast Lesion Segmentation
Nov 18, 2023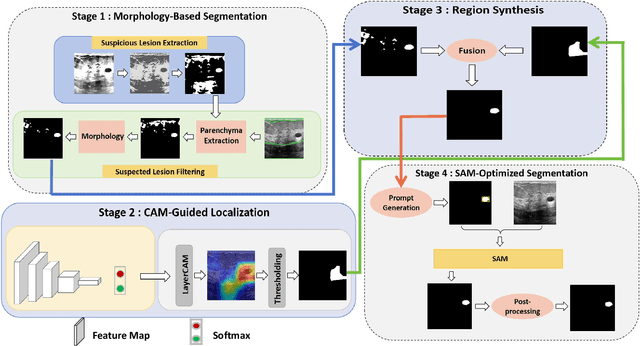
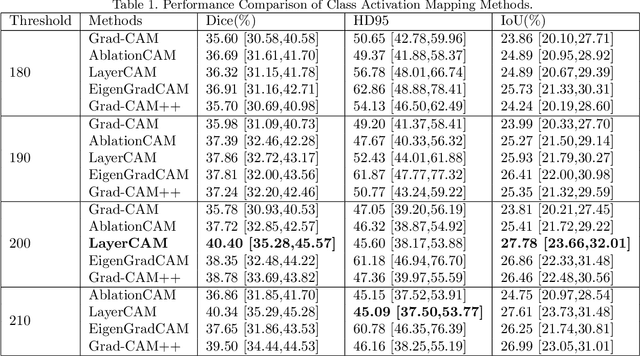
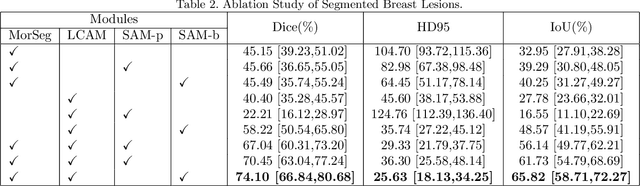
Breast cancer diagnosis challenges both patients and clinicians, with early detection being crucial for effective treatment. Ultrasound imaging plays a key role in this, but its utility is hampered by the need for precise lesion segmentation-a task that is both time-consuming and labor-intensive. To address these challenges, we propose a new framework: a morphology-enhanced, Class Activation Map (CAM)-guided model, which is optimized using a computer vision foundation model known as SAM. This innovative framework is specifically designed for weakly supervised lesion segmentation in early-stage breast ultrasound images. Our approach uniquely leverages image-level annotations, which removes the requirement for detailed pixel-level annotation. Initially, we perform a preliminary segmentation using breast lesion morphology knowledge. Following this, we accurately localize lesions by extracting semantic information through a CAM-based heatmap. These two elements are then fused together, serving as a prompt to guide the SAM in performing refined segmentation. Subsequently, post-processing techniques are employed to rectify topological errors made by the SAM. Our method not only simplifies the segmentation process but also attains accuracy comparable to supervised learning methods that rely on pixel-level annotation. Our framework achieves a Dice score of 74.39% on the test set, demonstrating compareable performance with supervised learning methods. Additionally, it outperforms a supervised learning model, in terms of the Hausdorff distance, scoring 24.27 compared to Deeplabv3+'s 32.22. These experimental results showcase its feasibility and superior performance in integrating weakly supervised learning with SAM. The code is made available at: https://github.com/YueXin18/MorSeg-CAM-SAM.
Representing visual classification as a linear combination of words
Nov 18, 2023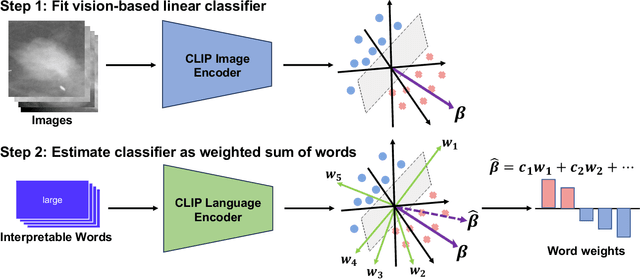
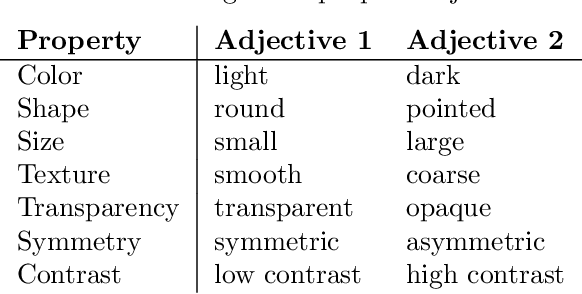
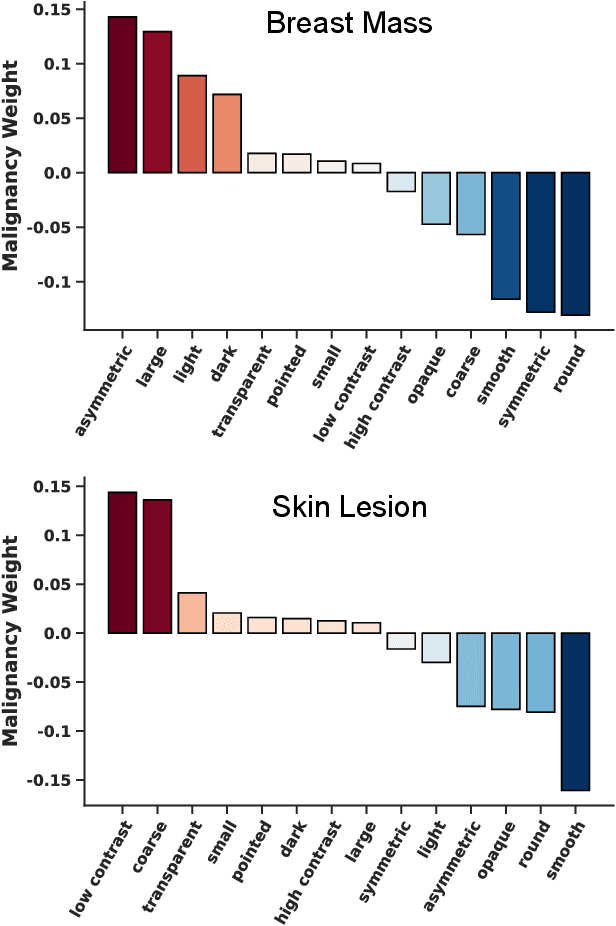
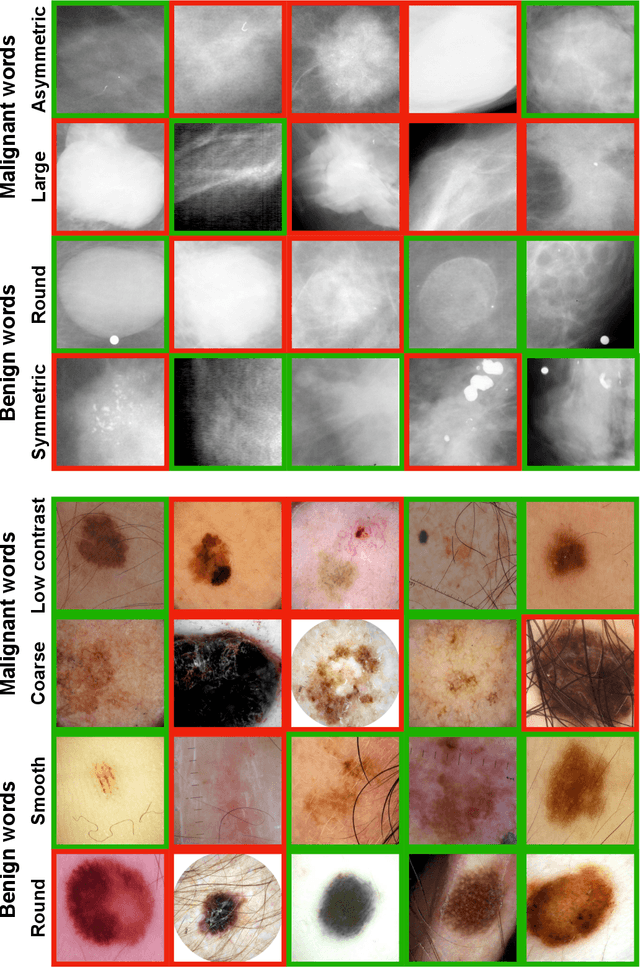
Explainability is a longstanding challenge in deep learning, especially in high-stakes domains like healthcare. Common explainability methods highlight image regions that drive an AI model's decision. Humans, however, heavily rely on language to convey explanations of not only "where" but "what". Additionally, most explainability approaches focus on explaining individual AI predictions, rather than describing the features used by an AI model in general. The latter would be especially useful for model and dataset auditing, and potentially even knowledge generation as AI is increasingly being used in novel tasks. Here, we present an explainability strategy that uses a vision-language model to identify language-based descriptors of a visual classification task. By leveraging a pre-trained joint embedding space between images and text, our approach estimates a new classification task as a linear combination of words, resulting in a weight for each word that indicates its alignment with the vision-based classifier. We assess our approach using two medical imaging classification tasks, where we find that the resulting descriptors largely align with clinical knowledge despite a lack of domain-specific language training. However, our approach also identifies the potential for 'shortcut connections' in the public datasets used. Towards a functional measure of explainability, we perform a pilot reader study where we find that the AI-identified words can enable non-expert humans to perform a specialized medical task at a non-trivial level. Altogether, our results emphasize the potential of using multimodal foundational models to deliver intuitive, language-based explanations of visual tasks.