 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Diffusion Models for Earth Observation Use-cases: from cloud removal to urban change detection
Nov 10, 2023
The advancements in the state of the art of generative Artificial Intelligence (AI) brought by diffusion models can be highly beneficial in novel contexts involving Earth observation data. After introducing this new family of generative models, this work proposes and analyses three use cases which demonstrate the potential of diffusion-based approaches for satellite image data. Namely, we tackle cloud removal and inpainting, dataset generation for change-detection tasks, and urban replanning.
* Presented at Big Data from Space 2023 (BiDS)
ELIP: Efficient Language-Image Pre-training with Fewer Vision Tokens
Sep 28, 2023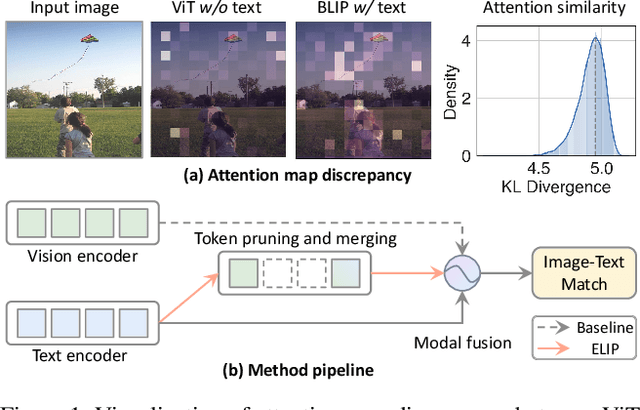
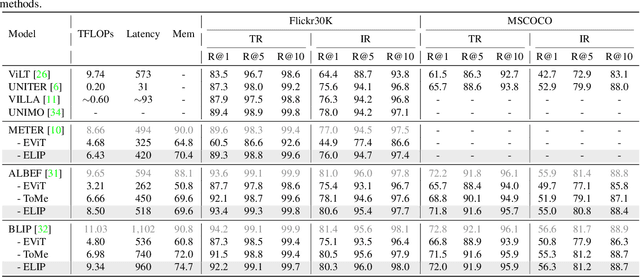
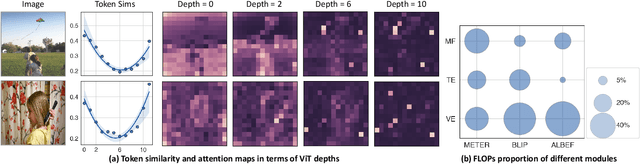
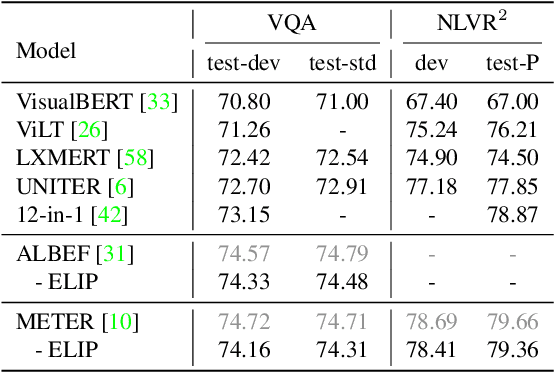
Learning a versatile language-image model is computationally prohibitive under a limited computing budget. This paper delves into the efficient language-image pre-training, an area that has received relatively little attention despite its importance in reducing computational cost and footprint. To that end, we propose a vision token pruning and merging method, ie ELIP, to remove less influential tokens based on the supervision of language outputs. Our method is designed with several strengths, such as being computation-efficient, memory-efficient, and trainable-parameter-free, and is distinguished from previous vision-only token pruning approaches by its alignment with task objectives. We implement this method in a progressively pruning manner using several sequential blocks. To evaluate its generalization performance, we apply ELIP to three commonly used language-image pre-training models and utilize public image-caption pairs with 4M images for pre-training. Our experiments demonstrate that with the removal of ~30$\%$ vision tokens across 12 ViT layers, ELIP maintains significantly comparable performance with baselines ($\sim$0.32 accuracy drop on average) over various downstream tasks including cross-modal retrieval, VQA, image captioning, etc. In addition, the spared GPU resources by our ELIP allow us to scale up with larger batch sizes, thereby accelerating model pre-training and even sometimes enhancing downstream model performance. Our code will be released at https://github.com/guoyang9/ELIP.
Unsupervised and semi-supervised co-salient object detection via segmentation frequency statistics
Nov 11, 2023In this paper, we address the detection of co-occurring salient objects (CoSOD) in an image group using frequency statistics in an unsupervised manner, which further enable us to develop a semi-supervised method. While previous works have mostly focused on fully supervised CoSOD, less attention has been allocated to detecting co-salient objects when limited segmentation annotations are available for training. Our simple yet effective unsupervised method US-CoSOD combines the object co-occurrence frequency statistics of unsupervised single-image semantic segmentations with salient foreground detections using self-supervised feature learning. For the first time, we show that a large unlabeled dataset e.g. ImageNet-1k can be effectively leveraged to significantly improve unsupervised CoSOD performance. Our unsupervised model is a great pre-training initialization for our semi-supervised model SS-CoSOD, especially when very limited labeled data is available for training. To avoid propagating erroneous signals from predictions on unlabeled data, we propose a confidence estimation module to guide our semi-supervised training. Extensive experiments on three CoSOD benchmark datasets show that both of our unsupervised and semi-supervised models outperform the corresponding state-of-the-art models by a significant margin (e.g., on the Cosal2015 dataset, our US-CoSOD model has an 8.8% F-measure gain over a SOTA unsupervised co-segmentation model and our SS-CoSOD model has an 11.81% F-measure gain over a SOTA semi-supervised CoSOD model).
Learning Symmetrization for Equivariance with Orbit Distance Minimization
Nov 13, 2023We present a general framework for symmetrizing an arbitrary neural-network architecture and making it equivariant with respect to a given group. We build upon the proposals of Kim et al. (2023); Kaba et al. (2023) for symmetrization, and improve them by replacing their conversion of neural features into group representations, with an optimization whose loss intuitively measures the distance between group orbits. This change makes our approach applicable to a broader range of matrix groups, such as the Lorentz group O(1, 3), than these two proposals. We experimentally show our method's competitiveness on the SO(2) image classification task, and also its increased generality on the task with O(1, 3). Our implementation will be made accessible at https://github.com/tiendatnguyen-vision/Orbit-symmetrize.
Reconciling Radio Tomographic Imaging with Phaseless Inverse Scattering
Nov 16, 2023Radio Tomographic Imaging (RTI) is a phaseless imaging approach that can provide shape reconstruction and localization of objects using received signal strength (RSS) measurements. RSS measurements can be straightforwardly obtained from wireless networks such as Wi-Fi and therefore RTI has been extensively researched and accepted as a good indoor RF imaging technique. However, RTI is formulated on empirical models using an assumption of light-of-sight (LOS) propagation that does not account for intricate scattering effects. There are two main objectives of this work. The first objective is to reconcile and compare the empirical RTI model with formal inverse scattering approaches to better understand why RTI is an effective RF imaging technique. The second objective is to obtain straightforward enhancements to RTI, based on inverse scattering, to enhance its performance. The resulting enhancements can provide reconstructions of the shape and also material properties of the objects that can aid image classification. We also provide numerical and experimental results to compare RTI with the enhanced RTI for indoor imaging applications using low-cost 2.4 GHz Wi-Fi transceivers. These results show that the enhanced RTI can outperform RTI while having similar computational complexity to RTI.
RED-DOT: Multimodal Fact-checking via Relevant Evidence Detection
Nov 16, 2023Online misinformation is often multimodal in nature, i.e., it is caused by misleading associations between texts and accompanying images. To support the fact-checking process, researchers have been recently developing automatic multimodal methods that gather and analyze external information, evidence, related to the image-text pairs under examination. However, prior works assumed all collected evidence to be relevant. In this study, we introduce a "Relevant Evidence Detection" (RED) module to discern whether each piece of evidence is relevant, to support or refute the claim. Specifically, we develop the "Relevant Evidence Detection Directed Transformer" (RED-DOT) and explore multiple architectural variants (e.g., single or dual-stage) and mechanisms (e.g., "guided attention"). Extensive ablation and comparative experiments demonstrate that RED-DOT achieves significant improvements over the state-of-the-art on the VERITE benchmark by up to 28.5%. Furthermore, our evidence re-ranking and element-wise modality fusion led to RED-DOT achieving competitive and even improved performance on NewsCLIPings+, without the need for numerous evidence or multiple backbone encoders. Finally, our qualitative analysis demonstrates that the proposed "guided attention" module has the potential to enhance the architecture's interpretability. We release our code at: https://github.com/stevejpapad/relevant-evidence-detection
Machine learning refinement of in situ images acquired by low electron dose LC-TEM
Oct 31, 2023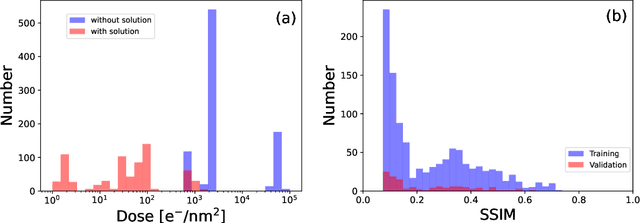
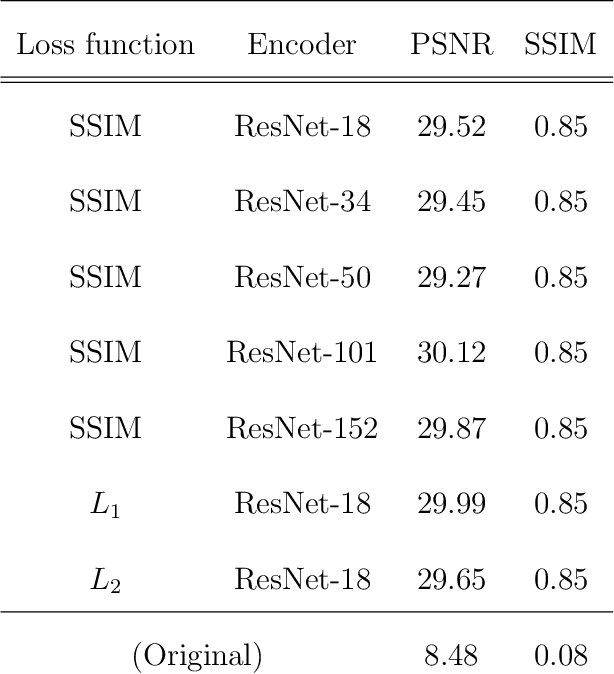
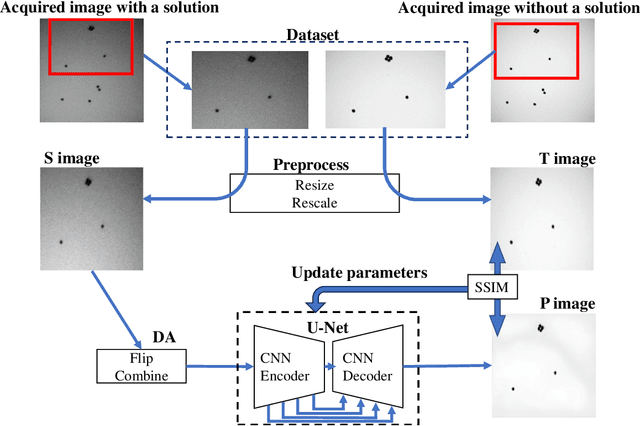
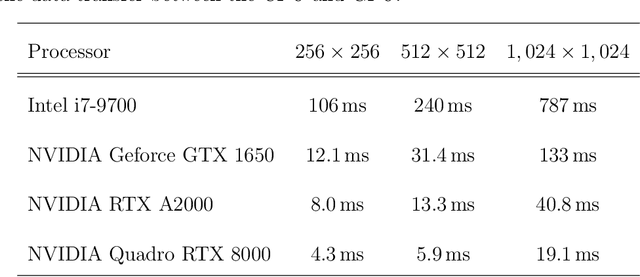
We study a machine learning (ML) technique for refining images acquired during in situ observation using liquid-cell transmission electron microscopy (LC-TEM). Our model is constructed using a U-Net architecture and a ResNet encoder. For training our ML model, we prepared an original image dataset that contained pairs of images of samples acquired with and without a solution present. The former images were used as noisy images and the latter images were used as corresponding ground truth images. The number of pairs of image sets was $1,204$ and the image sets included images acquired at several different magnifications and electron doses. The trained model converted a noisy image into a clear image. The time necessary for the conversion was on the order of 10ms, and we applied the model to in situ observations using the software Gatan DigitalMicrograph (DM). Even if a nanoparticle was not visible in a view window in the DM software because of the low electron dose, it was visible in a successive refined image generated by our ML model.
ChatAnything: Facetime Chat with LLM-Enhanced Personas
Nov 12, 2023In this technical report, we target generating anthropomorphized personas for LLM-based characters in an online manner, including visual appearance, personality and tones, with only text descriptions. To achieve this, we first leverage the in-context learning capability of LLMs for personality generation by carefully designing a set of system prompts. We then propose two novel concepts: the mixture of voices (MoV) and the mixture of diffusers (MoD) for diverse voice and appearance generation. For MoV, we utilize the text-to-speech (TTS) algorithms with a variety of pre-defined tones and select the most matching one based on the user-provided text description automatically. For MoD, we combine the recent popular text-to-image generation techniques and talking head algorithms to streamline the process of generating talking objects. We termed the whole framework as ChatAnything. With it, users could be able to animate anything with any personas that are anthropomorphic using just a few text inputs. However, we have observed that the anthropomorphic objects produced by current generative models are often undetectable by pre-trained face landmark detectors, leading to failure of the face motion generation, even if these faces possess human-like appearances because those images are nearly seen during the training (e.g., OOD samples). To address this issue, we incorporate pixel-level guidance to infuse human face landmarks during the image generation phase. To benchmark these metrics, we have built an evaluation dataset. Based on it, we verify that the detection rate of the face landmark is significantly increased from 57.0% to 92.5% thus allowing automatic face animation based on generated speech content. The code and more results can be found at https://chatanything.github.io/.
Re-initialization-free Level Set Method via Molecular Beam Epitaxy Equation Regularization for Image Segmentation
Oct 13, 2023Variational level set method has become a powerful tool in image segmentation due to its ability to handle complex topological changes and maintain continuity and smoothness in the process of evolution. However its evolution process can be unstable, which results in over flatted or over sharpened contours and segmentation failure. To improve the accuracy and stability of evolution, we propose a high-order level set variational segmentation method integrated with molecular beam epitaxy (MBE) equation regularization. This method uses the crystal growth in the MBE process to limit the evolution of the level set function, and thus can avoid the re-initialization in the evolution process and regulate the smoothness of the segmented curve. It also works for noisy images with intensity inhomogeneity, which is a challenge in image segmentation. To solve the variational model, we derive the gradient flow and design scalar auxiliary variable (SAV) scheme coupled with fast Fourier transform (FFT), which can significantly improve the computational efficiency compared with the traditional semi-implicit and semi-explicit scheme. Numerical experiments show that the proposed method can generate smooth segmentation curves, retain fine segmentation targets and obtain robust segmentation results of small objects. Compared to existing level set methods, this model is state-of-the-art in both accuracy and efficiency.
Continual atlas-based segmentation of prostate MRI
Nov 06, 2023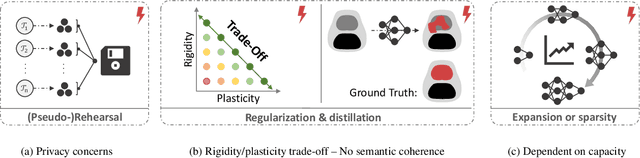
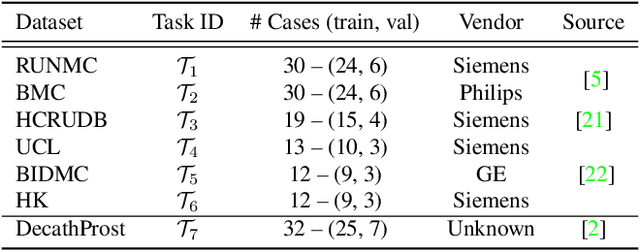
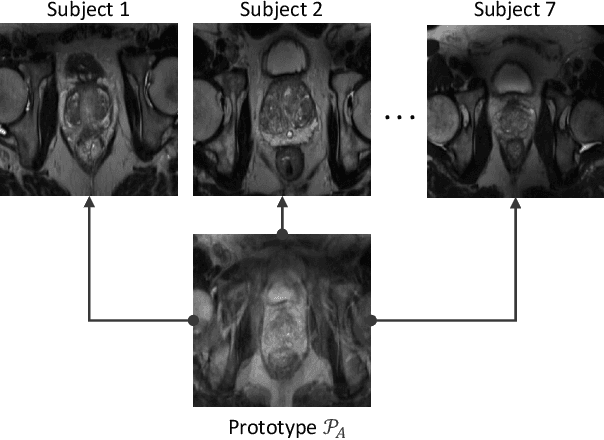
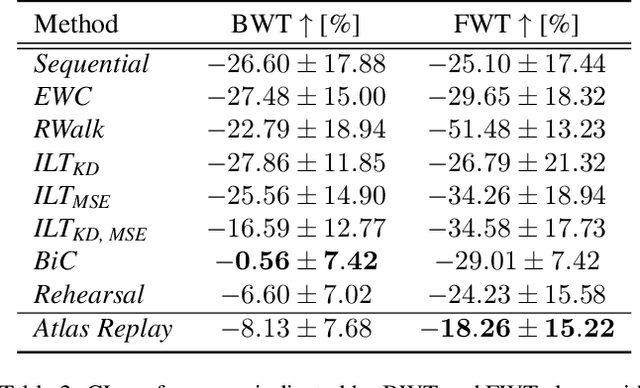
Continual learning (CL) methods designed for natural image classification often fail to reach basic quality standards for medical image segmentation. Atlas-based segmentation, a well-established approach in medical imaging, incorporates domain knowledge on the region of interest, leading to semantically coherent predictions. This is especially promising for CL, as it allows us to leverage structural information and strike an optimal balance between model rigidity and plasticity over time. When combined with privacy-preserving prototypes, this process offers the advantages of rehearsal-based CL without compromising patient privacy. We propose Atlas Replay, an atlas-based segmentation approach that uses prototypes to generate high-quality segmentation masks through image registration that maintain consistency even as the training distribution changes. We explore how our proposed method performs compared to state-of-the-art CL methods in terms of knowledge transferability across seven publicly available prostate segmentation datasets. Prostate segmentation plays a vital role in diagnosing prostate cancer, however, it poses challenges due to substantial anatomical variations, benign structural differences in older age groups, and fluctuating acquisition parameters. Our results show that Atlas Replay is both robust and generalizes well to yet-unseen domains while being able to maintain knowledge, unlike end-to-end segmentation methods. Our code base is available under https://github.com/MECLabTUDA/Atlas-Replay.