 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
MoCo-Transfer: Investigating out-of-distribution contrastive learning for limited-data domains
Nov 15, 2023
Medical imaging data is often siloed within hospitals, limiting the amount of data available for specialized model development. With limited in-domain data, one might hope to leverage larger datasets from related domains. In this paper, we analyze the benefit of transferring self-supervised contrastive representations from moment contrast (MoCo) pretraining on out-of-distribution data to settings with limited data. We consider two X-ray datasets which image different parts of the body, and compare transferring from each other to transferring from ImageNet. We find that depending on quantity of labeled and unlabeled data, contrastive pretraining on larger out-of-distribution datasets can perform nearly as well or better than MoCo pretraining in-domain, and pretraining on related domains leads to higher performance than if one were to use the ImageNet pretrained weights. Finally, we provide a preliminary way of quantifying similarity between datasets.
Support or Refute: Analyzing the Stance of Evidence to Detect Out-of-Context Mis- and Disinformation
Nov 16, 2023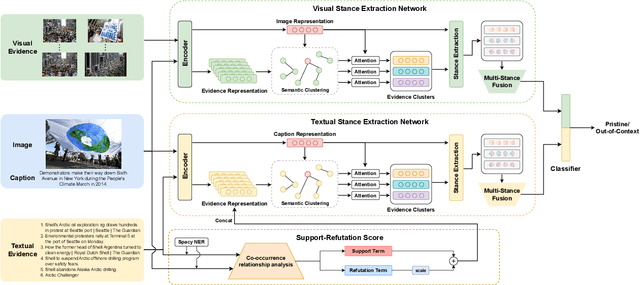
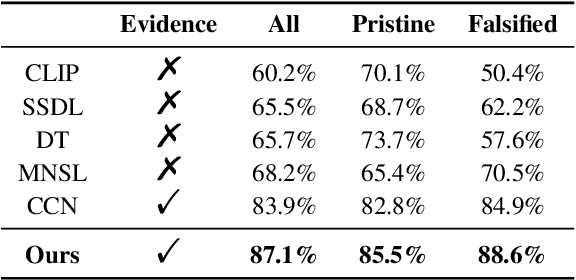
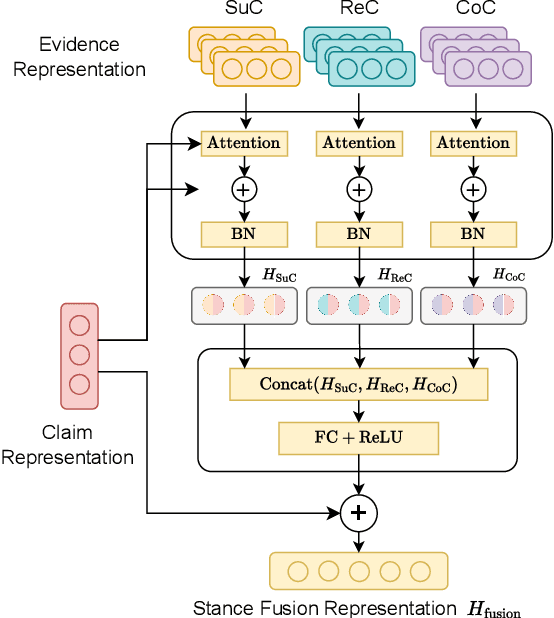
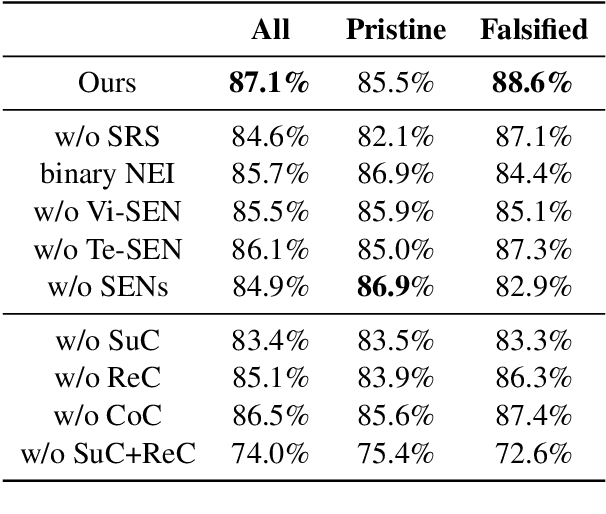
Mis- and disinformation online have become a major societal problem as major sources of online harms of different kinds. One common form of mis- and disinformation is out-of-context (OOC) information, where different pieces of information are falsely associated, e.g., a real image combined with a false textual caption or a misleading textual description. Although some past studies have attempted to defend against OOC mis- and disinformation through external evidence, they tend to disregard the role of different pieces of evidence with different stances. Motivated by the intuition that the stance of evidence represents a bias towards different detection results, we propose a stance extraction network (SEN) that can extract the stances of different pieces of multi-modal evidence in a unified framework. Moreover, we introduce a support-refutation score calculated based on the co-occurrence relations of named entities into the textual SEN. Extensive experiments on a public large-scale dataset demonstrated that our proposed method outperformed the state-of-the-art baselines, with the best model achieving a performance gain of 3.2% in accuracy.
PixT3: Pixel-based Table To Text generation
Nov 16, 2023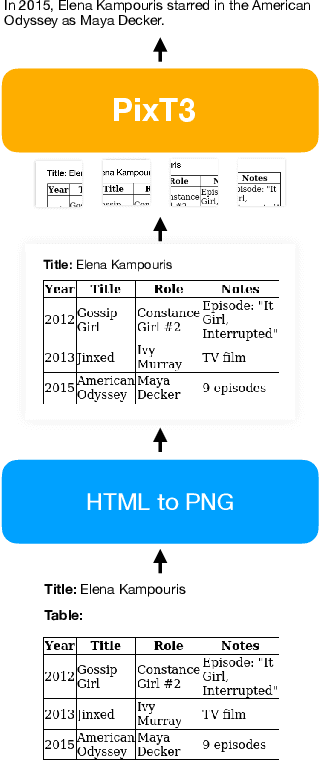
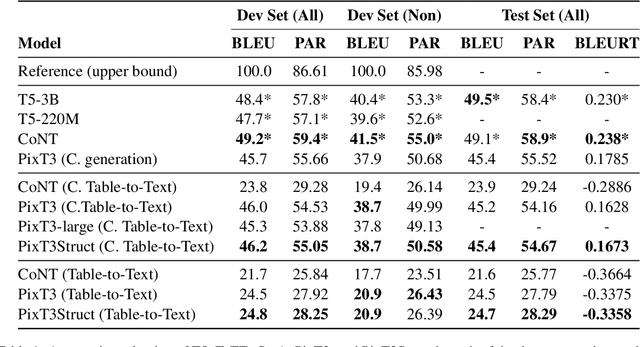
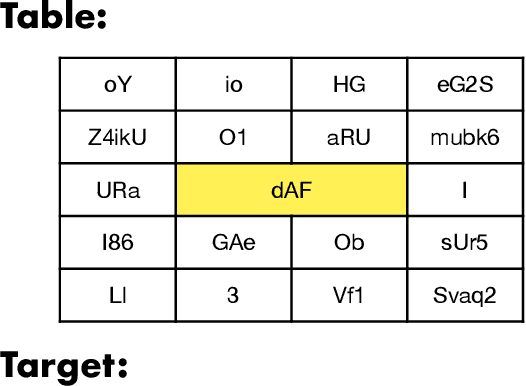
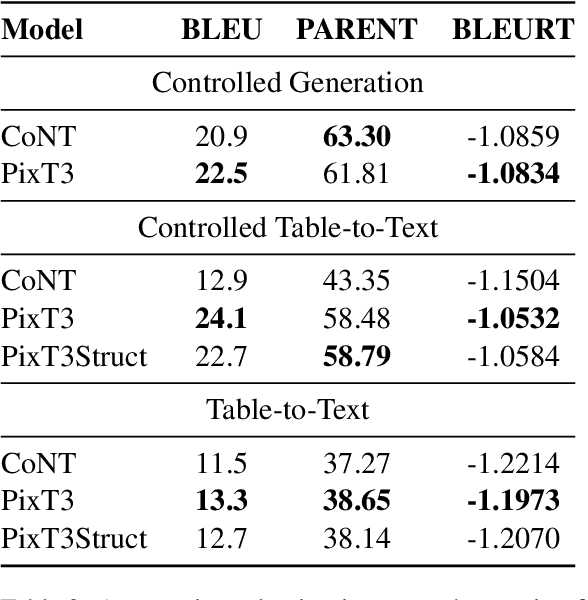
Table-to-Text has been traditionally approached as a linear language to text problem. However, visually represented tables are rich in visual information and serve as a concise, effective form of representing data and its relationships. When using text-based approaches, after the linearization process, this information is either lost or represented in a space inefficient manner. This inefficiency has remained a constant challenge for text-based approaches making them struggle with large tables. In this paper, we demonstrate that image representation of tables are more space-efficient than the typical textual linearizations, and multi-modal approaches are competitive in Table-to-Text tasks. We present PixT3, a multimodal table-to-text model that outperforms the state-of-the-art (SotA) in the ToTTo benchmark in a pure Table-to-Text setting while remaining competitive in controlled Table-to-Text scenarios. It also generalizes better in unseen datasets, outperforming ToTTo SotA in all generation settings. Additionally, we introduce a new intermediate training curriculum to reinforce table structural awareness, leading to improved generation and overall faithfulness of the models.
Match and Locate: low-frequency monocular odometry based on deep feature matching
Nov 16, 2023Accurate and robust pose estimation plays a crucial role in many robotic systems. Popular algorithms for pose estimation typically rely on high-fidelity and high-frequency signals from various sensors. Inclusion of these sensors makes the system less affordable and much more complicated. In this work we introduce a novel approach for the robotic odometry which only requires a single camera and, importantly, can produce reliable estimates given even extremely low-frequency signal of around one frame per second. The approach is based on matching image features between the consecutive frames of the video stream using deep feature matching models. The resulting coarse estimate is then adjusted by a convolutional neural network, which is also responsible for estimating the scale of the transition, otherwise irretrievable using only the feature matching information. We evaluate the performance of the approach in the AISG-SLA Visual Localisation Challenge and find that while being computationally efficient and easy to implement our method shows competitive results with only around $3^{\circ}$ of orientation estimation error and $2m$ of translation estimation error taking the third place in the challenge.
Imaging through multimode fibres with physical prior
Nov 14, 2023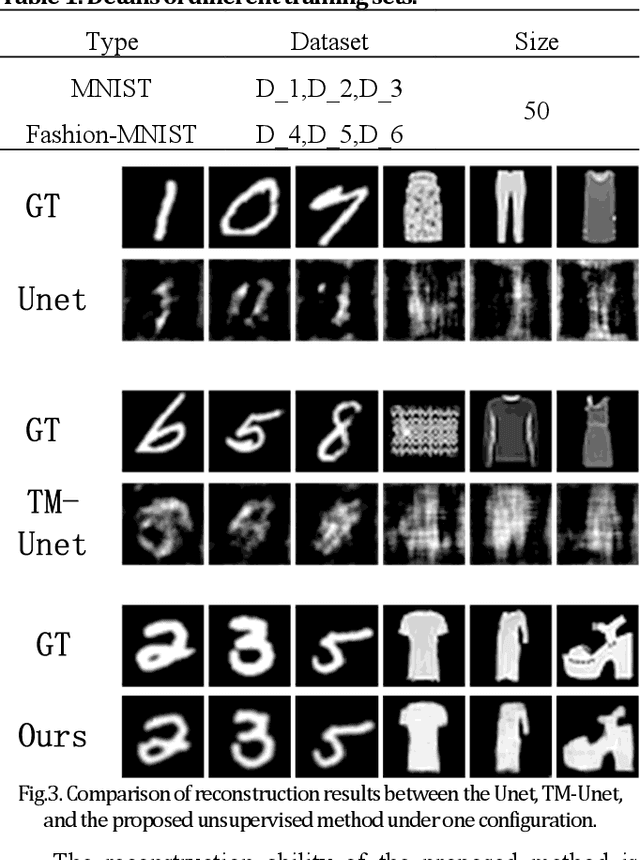
Imaging through perturbed multimode fibres based on deep learning has been widely researched. However, existing methods mainly use target-speckle pairs in different configurations. It is challenging to reconstruct targets without trained networks. In this paper, we propose a physics-assisted, unsupervised, learning-based fibre imaging scheme. The role of the physical prior is to simplify the mapping relationship between the speckle pattern and the target image, thereby reducing the computational complexity. The unsupervised network learns target features according to the optimized direction provided by the physical prior. Therefore, the reconstruction process of the online learning only requires a few speckle patterns and unpaired targets. The proposed scheme also increases the generalization ability of the learning-based method in perturbed multimode fibres. Our scheme has the potential to extend the application of multimode fibre imaging.
CP-SLAM: Collaborative Neural Point-based SLAM System
Nov 14, 2023This paper presents a collaborative implicit neural simultaneous localization and mapping (SLAM) system with RGB-D image sequences, which consists of complete front-end and back-end modules including odometry, loop detection, sub-map fusion, and global refinement. In order to enable all these modules in a unified framework, we propose a novel neural point based 3D scene representation in which each point maintains a learnable neural feature for scene encoding and is associated with a certain keyframe. Moreover, a distributed-to-centralized learning strategy is proposed for the collaborative implicit SLAM to improve consistency and cooperation. A novel global optimization framework is also proposed to improve the system accuracy like traditional bundle adjustment. Experiments on various datasets demonstrate the superiority of the proposed method in both camera tracking and mapping.
An Enhanced Low-Resolution Image Recognition Method for Traffic Environments
Sep 28, 2023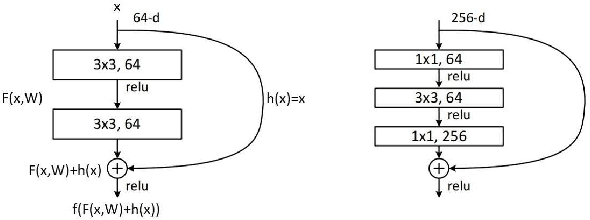
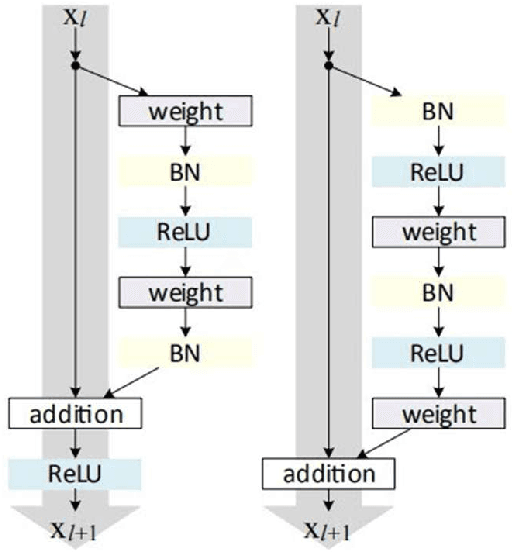
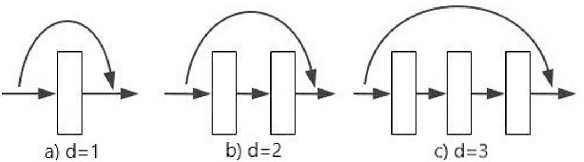
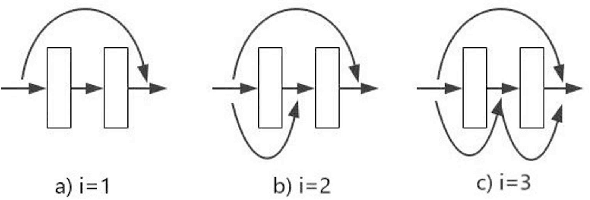
Currently, low-resolution image recognition is confronted with a significant challenge in the field of intelligent traffic perception. Compared to high-resolution images, low-resolution images suffer from small size, low quality, and lack of detail, leading to a notable decrease in the accuracy of traditional neural network recognition algorithms. The key to low-resolution image recognition lies in effective feature extraction. Therefore, this paper delves into the fundamental dimensions of residual modules and their impact on feature extraction and computational efficiency. Based on experiments, we introduce a dual-branch residual network structure that leverages the basic architecture of residual networks and a common feature subspace algorithm. Additionally, it incorporates the utilization of intermediate-layer features to enhance the accuracy of low-resolution image recognition. Furthermore, we employ knowledge distillation to reduce network parameters and computational overhead. Experimental results validate the effectiveness of this algorithm for low-resolution image recognition in traffic environments.
Neural Network Methods for Radiation Detectors and Imaging
Nov 09, 2023Recent advances in image data processing through machine learning and especially deep neural networks (DNNs) allow for new optimization and performance-enhancement schemes for radiation detectors and imaging hardware through data-endowed artificial intelligence. We give an overview of data generation at photon sources, deep learning-based methods for image processing tasks, and hardware solutions for deep learning acceleration. Most existing deep learning approaches are trained offline, typically using large amounts of computational resources. However, once trained, DNNs can achieve fast inference speeds and can be deployed to edge devices. A new trend is edge computing with less energy consumption (hundreds of watts or less) and real-time analysis potential. While popularly used for edge computing, electronic-based hardware accelerators ranging from general purpose processors such as central processing units (CPUs) to application-specific integrated circuits (ASICs) are constantly reaching performance limits in latency, energy consumption, and other physical constraints. These limits give rise to next-generation analog neuromorhpic hardware platforms, such as optical neural networks (ONNs), for high parallel, low latency, and low energy computing to boost deep learning acceleration.
Physics-Enhanced Multi-fidelity Learning for Optical Surface Imprint
Nov 17, 2023Human fingerprints serve as one unique and powerful characteristic for each person, from which policemen can recognize the identity. Similar to humans, many natural bodies and intrinsic mechanical qualities can also be uniquely identified from surface characteristics. To measure the elasto-plastic properties of one material, one formally sharp indenter is pushed into the measured body under constant force and retracted, leaving a unique residual imprint of the minute size from several micrometers to nanometers. However, one great challenge is how to map the optical image of this residual imprint into the real wanted mechanical properties, i.e., the tensile force curve. In this paper, we propose a novel method to use multi-fidelity neural networks (MFNN) to solve this inverse problem. We first actively train the NN model via pure simulation data, and then bridge the sim-to-real gap via transfer learning. The most innovative part is that we use NN to dig out the unknown physics and also implant the known physics into the transfer learning framework, thus highly improving the model stability and decreasing the data requirement. This work serves as one great example of applying machine learning into the real experimental research, especially under the constraints of data limitation and fidelity variance.
* 8 pages, 4 figures, NeurIPS 2023 Workshop on Adaptive Experimental Design and Active Learning in the Real World
3D-TexSeg: Unsupervised Segmentation of 3D Texture using Mutual Transformer Learning
Nov 17, 2023Analysis of the 3D Texture is indispensable for various tasks, such as retrieval, segmentation, classification, and inspection of sculptures, knitted fabrics, and biological tissues. A 3D texture is a locally repeated surface variation independent of the surface's overall shape and can be determined using the local neighborhood and its characteristics. Existing techniques typically employ computer vision techniques that analyze a 3D mesh globally, derive features, and then utilize the obtained features for retrieval or classification. Several traditional and learning-based methods exist in the literature, however, only a few are on 3D texture, and nothing yet, to the best of our knowledge, on the unsupervised schemes. This paper presents an original framework for the unsupervised segmentation of the 3D texture on the mesh manifold. We approach this problem as binary surface segmentation, partitioning the mesh surface into textured and non-textured regions without prior annotation. We devise a mutual transformer-based system comprising a label generator and a cleaner. The two models take geometric image representations of the surface mesh facets and label them as texture or non-texture across an iterative mutual learning scheme. Extensive experiments on three publicly available datasets with diverse texture patterns demonstrate that the proposed framework outperforms standard and SOTA unsupervised techniques and competes reasonably with supervised methods.