 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
FetMRQC: an open-source machine learning framework for multi-centric fetal brain MRI quality control
Nov 08, 2023
Fetal brain MRI is becoming an increasingly relevant complement to neurosonography for perinatal diagnosis, allowing fundamental insights into fetal brain development throughout gestation. However, uncontrolled fetal motion and heterogeneity in acquisition protocols lead to data of variable quality, potentially biasing the outcome of subsequent studies. We present FetMRQC, an open-source machine-learning framework for automated image quality assessment and quality control that is robust to domain shifts induced by the heterogeneity of clinical data. FetMRQC extracts an ensemble of quality metrics from unprocessed anatomical MRI and combines them to predict experts' ratings using random forests. We validate our framework on a pioneeringly large and diverse dataset of more than 1600 manually rated fetal brain T2-weighted images from four clinical centers and 13 different scanners. Our study shows that FetMRQC's predictions generalize well to unseen data while being interpretable. FetMRQC is a step towards more robust fetal brain neuroimaging, which has the potential to shed new insights on the developing human brain.
Self-Supervised Learning for Visual Relationship Detection through Masked Bounding Box Reconstruction
Nov 08, 2023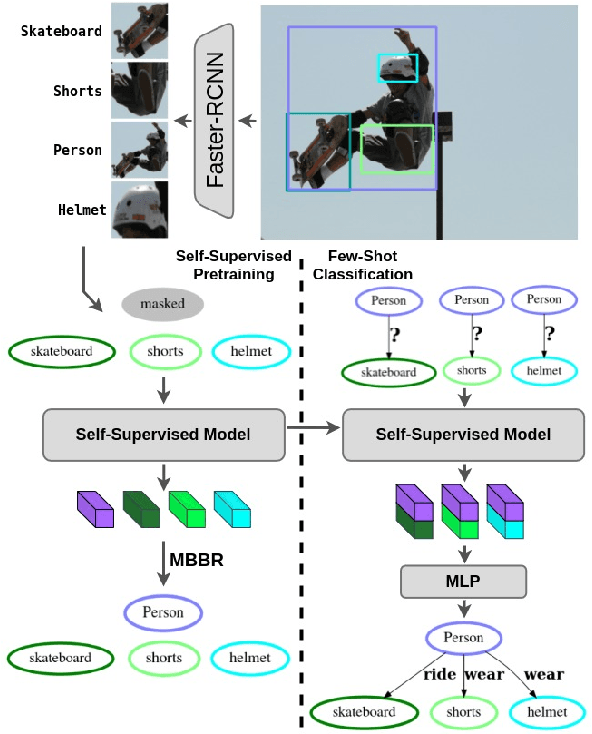
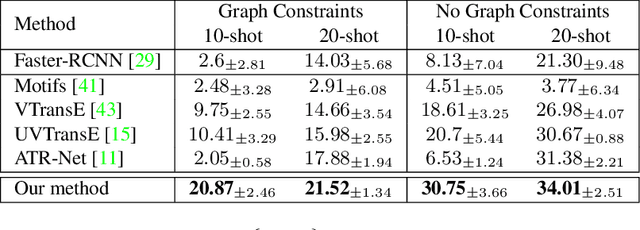
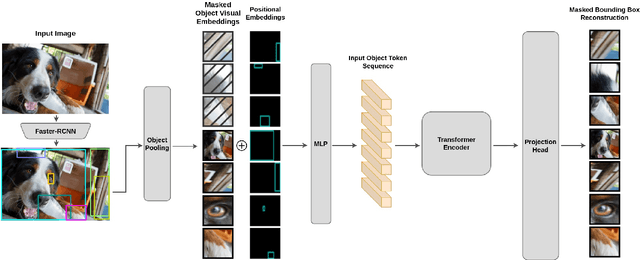
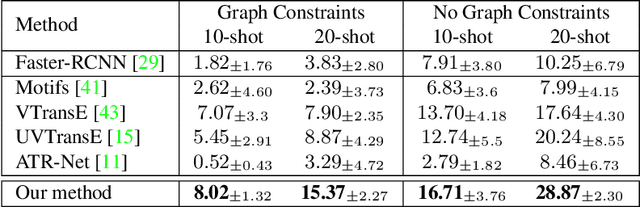
We present a novel self-supervised approach for representation learning, particularly for the task of Visual Relationship Detection (VRD). Motivated by the effectiveness of Masked Image Modeling (MIM), we propose Masked Bounding Box Reconstruction (MBBR), a variation of MIM where a percentage of the entities/objects within a scene are masked and subsequently reconstructed based on the unmasked objects. The core idea is that, through object-level masked modeling, the network learns context-aware representations that capture the interaction of objects within a scene and thus are highly predictive of visual object relationships. We extensively evaluate learned representations, both qualitatively and quantitatively, in a few-shot setting and demonstrate the efficacy of MBBR for learning robust visual representations, particularly tailored for VRD. The proposed method is able to surpass state-of-the-art VRD methods on the Predicate Detection (PredDet) evaluation setting, using only a few annotated samples. We make our code available at https://github.com/deeplab-ai/SelfSupervisedVRD.
Preserving Tumor Volumes for Unsupervised Medical Image Registration
Sep 18, 2023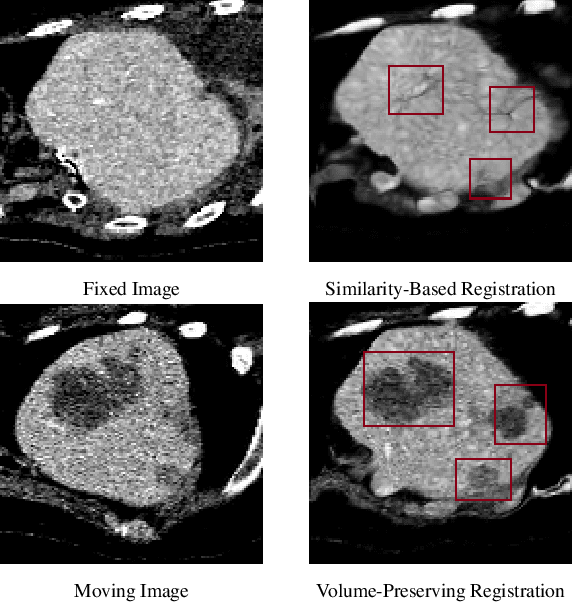
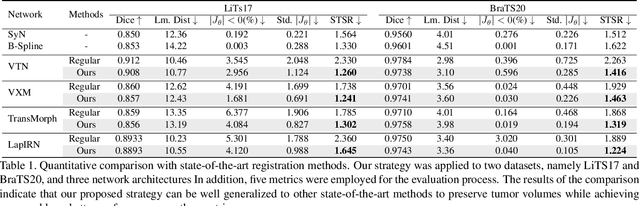
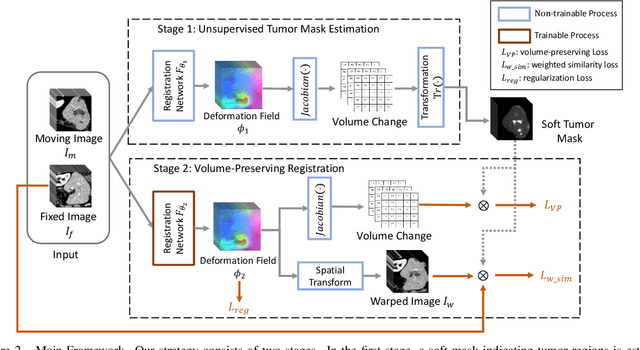
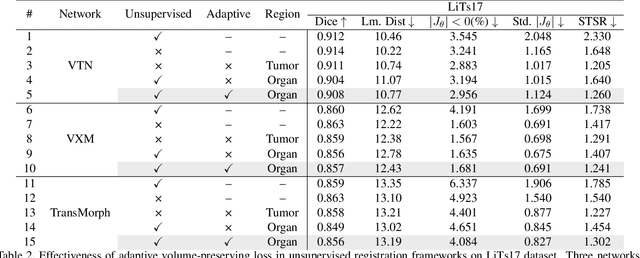
Medical image registration is a critical task that estimates the spatial correspondence between pairs of images. However, current traditional and deep-learning-based methods rely on similarity measures to generate a deforming field, which often results in disproportionate volume changes in dissimilar regions, especially in tumor regions. These changes can significantly alter the tumor size and underlying anatomy, which limits the practical use of image registration in clinical diagnosis. To address this issue, we have formulated image registration with tumors as a constraint problem that preserves tumor volumes while maximizing image similarity in other normal regions. Our proposed strategy involves a two-stage process. In the first stage, we use similarity-based registration to identify potential tumor regions by their volume change, generating a soft tumor mask accordingly. In the second stage, we propose a volume-preserving registration with a novel adaptive volume-preserving loss that penalizes the change in size adaptively based on the masks calculated from the previous stage. Our approach balances image similarity and volume preservation in different regions, i.e., normal and tumor regions, by using soft tumor masks to adjust the imposition of volume-preserving loss on each one. This ensures that the tumor volume is preserved during the registration process. We have evaluated our strategy on various datasets and network architectures, demonstrating that our method successfully preserves the tumor volume while achieving comparable registration results with state-of-the-art methods. Our codes is available at: \url{https://dddraxxx.github.io/Volume-Preserving-Registration/}.
Certification of Deep Learning Models for Medical Image Segmentation
Oct 05, 2023In medical imaging, segmentation models have known a significant improvement in the past decade and are now used daily in clinical practice. However, similar to classification models, segmentation models are affected by adversarial attacks. In a safety-critical field like healthcare, certifying model predictions is of the utmost importance. Randomized smoothing has been introduced lately and provides a framework to certify models and obtain theoretical guarantees. In this paper, we present for the first time a certified segmentation baseline for medical imaging based on randomized smoothing and diffusion models. Our results show that leveraging the power of denoising diffusion probabilistic models helps us overcome the limits of randomized smoothing. We conduct extensive experiments on five public datasets of chest X-rays, skin lesions, and colonoscopies, and empirically show that we are able to maintain high certified Dice scores even for highly perturbed images. Our work represents the first attempt to certify medical image segmentation models, and we aspire for it to set a foundation for future benchmarks in this crucial and largely uncharted area.
Preserving Node-level Privacy in Graph Neural Networks
Nov 12, 2023Differential privacy (DP) has seen immense applications in learning on tabular, image, and sequential data where instance-level privacy is concerned. In learning on graphs, contrastingly, works on node-level privacy are highly sparse. Challenges arise as existing DP protocols hardly apply to the message-passing mechanism in Graph Neural Networks (GNNs). In this study, we propose a solution that specifically addresses the issue of node-level privacy. Our protocol consists of two main components: 1) a sampling routine called HeterPoisson, which employs a specialized node sampling strategy and a series of tailored operations to generate a batch of sub-graphs with desired properties, and 2) a randomization routine that utilizes symmetric multivariate Laplace (SML) noise instead of the commonly used Gaussian noise. Our privacy accounting shows this particular combination provides a non-trivial privacy guarantee. In addition, our protocol enables GNN learning with good performance, as demonstrated by experiments on five real-world datasets; compared with existing baselines, our method shows significant advantages, especially in the high privacy regime. Experimentally, we also 1) perform membership inference attacks against our protocol and 2) apply privacy audit techniques to confirm our protocol's privacy integrity. In the sequel, we present a study on a seemingly appealing approach \cite{sajadmanesh2023gap} (USENIX'23) that protects node-level privacy via differentially private node/instance embeddings. Unfortunately, such work has fundamental privacy flaws, which are identified through a thorough case study. More importantly, we prove an impossibility result of achieving both (strong) privacy and (acceptable) utility through private instance embedding. The implication is that such an approach has intrinsic utility barriers when enforcing differential privacy.
MNN: Mixed Nearest-Neighbors for Self-Supervised Learning
Nov 01, 2023In contrastive self-supervised learning, positive samples are typically drawn from the same image but in different augmented views, resulting in a relatively limited source of positive samples. An effective way to alleviate this problem is to incorporate the relationship between samples, which involves including the top-k nearest neighbors of positive samples in the framework. However, the problem of false neighbors (i.e., neighbors that do not belong to the same category as the positive sample) is an objective but often overlooked challenge due to the query of neighbor samples without human supervision. In this paper, we present a simple Self-supervised learning framework called Mixed Nearest-Neighbors for Self-Supervised Learning (MNN). MNN optimizes the influence of neighbor samples on the semantics of positive samples through an intuitive weighting approach and image mixture operations. The results of our study demonstrate that MNN exhibits exceptional generalization performance and training efficiency on four benchmark datasets.
Neuromorphic Imaging with Joint Image Deblurring and Event Denoising
Sep 28, 2023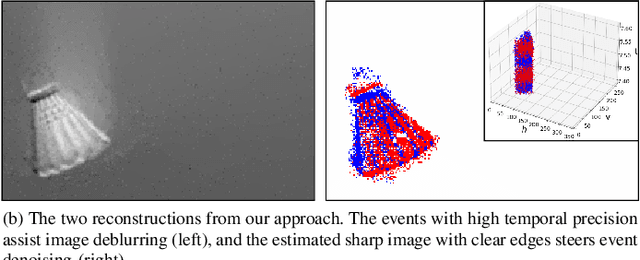



Neuromorphic imaging reacts to per-pixel brightness changes of a dynamic scene with high temporal precision and responds with asynchronous streaming events as a result. It also often supports a simultaneous output of an intensity image. Nevertheless, the raw events typically involve a great amount of noise due to the high sensitivity of the sensor, while capturing fast-moving objects at low frame rates results in blurry images. These deficiencies significantly degrade human observation and machine processing. Fortunately, the two information sources are inherently complementary -- events with microsecond temporal resolution, which are triggered by the edges of objects that are recorded in latent sharp images, can supply rich motion details missing from the blurry images. In this work, we bring the two types of data together and propose a simple yet effective unifying algorithm to jointly reconstruct blur-free images and noise-robust events, where an event-regularized prior offers auxiliary motion features for blind deblurring, and image gradients serve as a reference to regulate neuromorphic noise removal. Extensive evaluations on real and synthetic samples present our superiority over other competing methods in restoration quality and greater robustness to some challenging realistic scenarios. Our solution gives impetus to the improvement of both sensing data and paves the way for highly accurate neuromorphic reasoning and analysis.
UNIQA: A Unified Framework for Both Full-Reference and No-Reference Image Quality Assessment
Oct 14, 2023The human visual system (HVS) is effective at distinguishing low-quality images due to its ability to sense the distortion level and the resulting semantic impact. Prior research focuses on developing dedicated networks based on the presence and absence of pristine images, respectively, and this results in limited application scope and potential performance inconsistency when switching from NR to FR IQA. In addition, most methods heavily rely on spatial distortion modeling through difference maps or weighted features, and this may not be able to well capture the correlations between distortion and the semantic impact it causes. To this end, we aim to design a unified network for both Full-Reference (FR) and No-Reference (NR) IQA via semantic impact modeling. Specifically, we employ an encoder to extract multi-level features from input images. Then a Hierarchical Self-Attention (HSA) module is proposed as a universal adapter for both FR and NR inputs to model the spatial distortion level at each encoder stage. Furthermore, considering that distortions contaminate encoder stages and damage image semantic meaning differently, a Cross-Scale Cross-Attention (CSCA) module is proposed to examine correlations between distortion at shallow stages and deep ones. By adopting HSA and CSCA, the proposed network can effectively perform both FR and NR IQA. Extensive experiments demonstrate that the proposed simple network is effective and outperforms the relevant state-of-the-art FR and NR methods on four synthetic-distorted datasets and three authentic-distorted datasets.
Contextual Emotion Estimation from Image Captions
Sep 22, 2023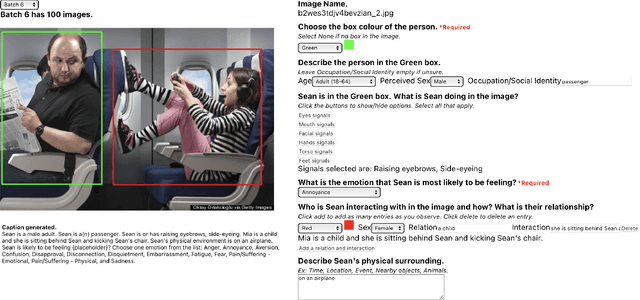

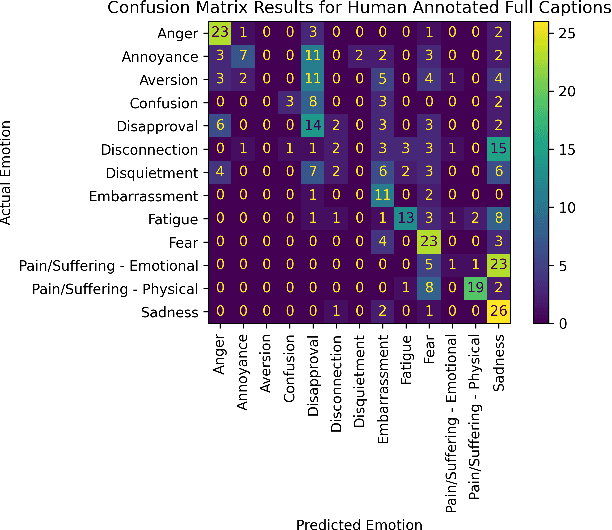
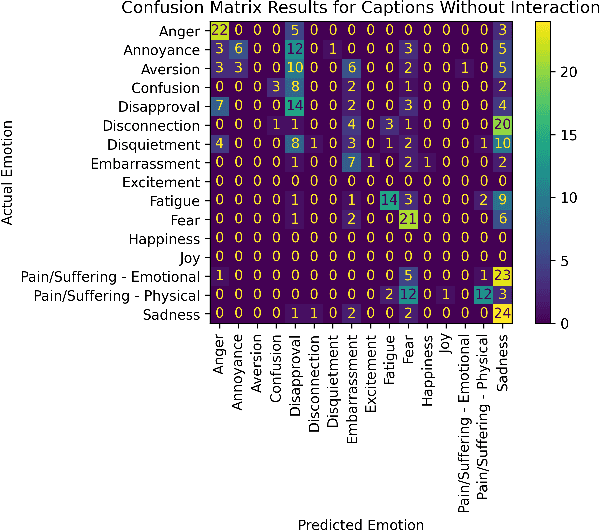
Emotion estimation in images is a challenging task, typically using computer vision methods to directly estimate people's emotions using face, body pose and contextual cues. In this paper, we explore whether Large Language Models (LLMs) can support the contextual emotion estimation task, by first captioning images, then using an LLM for inference. First, we must understand: how well do LLMs perceive human emotions? And which parts of the information enable them to determine emotions? One initial challenge is to construct a caption that describes a person within a scene with information relevant for emotion perception. Towards this goal, we propose a set of natural language descriptors for faces, bodies, interactions, and environments. We use them to manually generate captions and emotion annotations for a subset of 331 images from the EMOTIC dataset. These captions offer an interpretable representation for emotion estimation, towards understanding how elements of a scene affect emotion perception in LLMs and beyond. Secondly, we test the capability of a large language model to infer an emotion from the resulting image captions. We find that GPT-3.5, specifically the text-davinci-003 model, provides surprisingly reasonable emotion predictions consistent with human annotations, but accuracy can depend on the emotion concept. Overall, the results suggest promise in the image captioning and LLM approach.
CLIP-Motion: Learning Reward Functions for Robotic Actions Using Consecutive Observations
Nov 06, 2023This paper presents a novel method for learning reward functions for robotic motions by harnessing the power of a CLIP-based model. Traditional reward function design often hinges on manual feature engineering, which can struggle to generalize across an array of tasks. Our approach circumvents this challenge by capitalizing on CLIP's capability to process both state features and image inputs effectively. Given a pair of consecutive observations, our model excels in identifying the motion executed between them. We showcase results spanning various robotic activities, such as directing a gripper to a designated target and adjusting the position of a cube. Through experimental evaluations, we underline the proficiency of our method in precisely deducing motion and its promise to enhance reinforcement learning training in the realm of robotics.