 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Object-Centric Open-Vocabulary Image-Retrieval with Aggregated Features
Sep 26, 2023
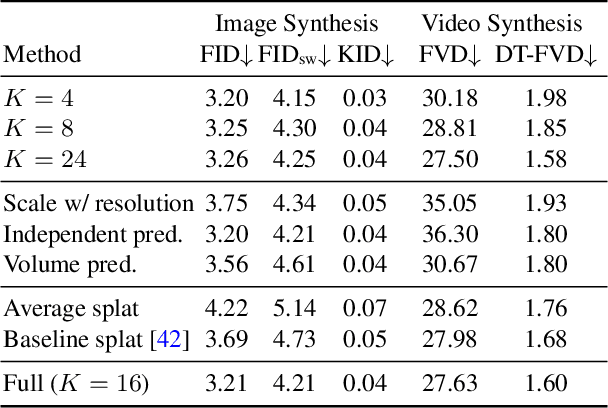
The task of open-vocabulary object-centric image retrieval involves the retrieval of images containing a specified object of interest, delineated by an open-set text query. As working on large image datasets becomes standard, solving this task efficiently has gained significant practical importance. Applications include targeted performance analysis of retrieved images using ad-hoc queries and hard example mining during training. Recent advancements in contrastive-based open vocabulary systems have yielded remarkable breakthroughs, facilitating large-scale open vocabulary image retrieval. However, these approaches use a single global embedding per image, thereby constraining the system's ability to retrieve images containing relatively small object instances. Alternatively, incorporating local embeddings from detection pipelines faces scalability challenges, making it unsuitable for retrieval from large databases. In this work, we present a simple yet effective approach to object-centric open-vocabulary image retrieval. Our approach aggregates dense embeddings extracted from CLIP into a compact representation, essentially combining the scalability of image retrieval pipelines with the object identification capabilities of dense detection methods. We show the effectiveness of our scheme to the task by achieving significantly better results than global feature approaches on three datasets, increasing accuracy by up to 15 mAP points. We further integrate our scheme into a large scale retrieval framework and demonstrate our method's advantages in terms of scalability and interpretability.
Single-shot Tomography of Discrete Dynamic Objects
Nov 09, 2023This paper presents a novel method for the reconstruction of high-resolution temporal images in dynamic tomographic imaging, particularly for discrete objects with smooth boundaries that vary over time. Addressing the challenge of limited measurements per time point, we propose a technique that synergistically incorporates spatial and temporal information of the dynamic objects. This is achieved through the application of the level-set method for image segmentation and the representation of motion via a sinusoidal basis. The result is a computationally efficient and easily optimizable variational framework that enables the reconstruction of high-quality 2D or 3D image sequences with a single projection per frame. Compared to current methods, our proposed approach demonstrates superior performance on both synthetic and pseudo-dynamic real X-ray tomography datasets. The implications of this research extend to improved visualization and analysis of dynamic processes in tomographic imaging, finding potential applications in diverse scientific and industrial domains.
Retinal OCT Synthesis with Denoising Diffusion Probabilistic Models for Layer Segmentation
Nov 09, 2023Modern biomedical image analysis using deep learning often encounters the challenge of limited annotated data. To overcome this issue, deep generative models can be employed to synthesize realistic biomedical images. In this regard, we propose an image synthesis method that utilizes denoising diffusion probabilistic models (DDPMs) to automatically generate retinal optical coherence tomography (OCT) images. By providing rough layer sketches, the trained DDPMs can generate realistic circumpapillary OCT images. We further find that more accurate pseudo labels can be obtained through knowledge adaptation, which greatly benefits the segmentation task. Through this, we observe a consistent improvement in layer segmentation accuracy, which is validated using various neural networks. Furthermore, we have discovered that a layer segmentation model trained solely with synthesized images can achieve comparable results to a model trained exclusively with real images. These findings demonstrate the promising potential of DDPMs in reducing the need for manual annotations of retinal OCT images.
FT-Shield: A Watermark Against Unauthorized Fine-tuning in Text-to-Image Diffusion Models
Oct 03, 2023
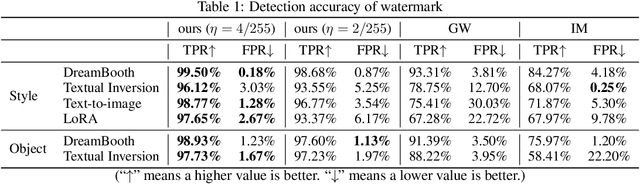
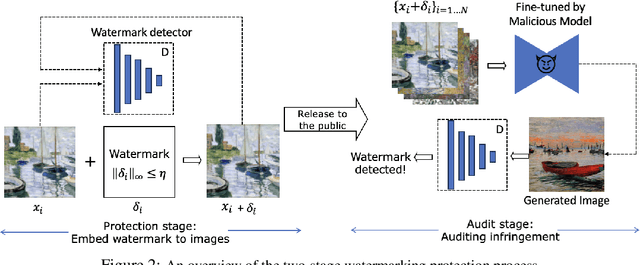
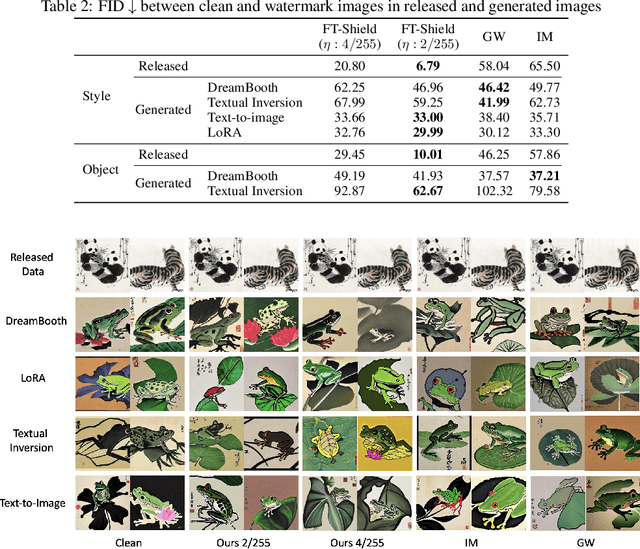
Text-to-image generative models based on latent diffusion models (LDM) have demonstrated their outstanding ability in generating high-quality and high-resolution images according to language prompt. Based on these powerful latent diffusion models, various fine-tuning methods have been proposed to achieve the personalization of text-to-image diffusion models such as artistic style adaptation and human face transfer. However, the unauthorized usage of data for model personalization has emerged as a prevalent concern in relation to copyright violations. For example, a malicious user may use the fine-tuning technique to generate images which mimic the style of a painter without his/her permission. In light of this concern, we have proposed FT-Shield, a watermarking approach specifically designed for the fine-tuning of text-to-image diffusion models to aid in detecting instances of infringement. We develop a novel algorithm for the generation of the watermark to ensure that the watermark on the training images can be quickly and accurately transferred to the generated images of text-to-image diffusion models. A watermark will be detected on an image by a binary watermark detector if the image is generated by a model that has been fine-tuned using the protected watermarked images. Comprehensive experiments were conducted to validate the effectiveness of FT-Shield.
Leveraging Function Space Aggregation for Federated Learning at Scale
Nov 17, 2023The federated learning paradigm has motivated the development of methods for aggregating multiple client updates into a global server model, without sharing client data. Many federated learning algorithms, including the canonical Federated Averaging (FedAvg), take a direct (possibly weighted) average of the client parameter updates, motivated by results in distributed optimization. In this work, we adopt a function space perspective and propose a new algorithm, FedFish, that aggregates local approximations to the functions learned by clients, using an estimate based on their Fisher information. We evaluate FedFish on realistic, large-scale cross-device benchmarks. While the performance of FedAvg can suffer as client models drift further apart, we demonstrate that FedFish is more robust to longer local training. Our evaluation across several settings in image and language benchmarks shows that FedFish outperforms FedAvg as local training epochs increase. Further, FedFish results in global networks that are more amenable to efficient personalization via local fine-tuning on the same or shifted data distributions. For instance, federated pretraining on the C4 dataset, followed by few-shot personalization on Stack Overflow, results in a 7% improvement in next-token prediction by FedFish over FedAvg.
Efficient Retrieval of Images with Irregular Patterns using Morphological Image Analysis: Applications to Industrial and Healthcare datasets
Oct 10, 2023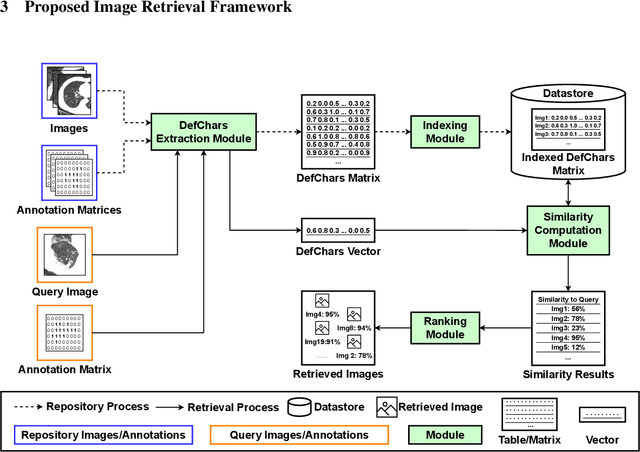

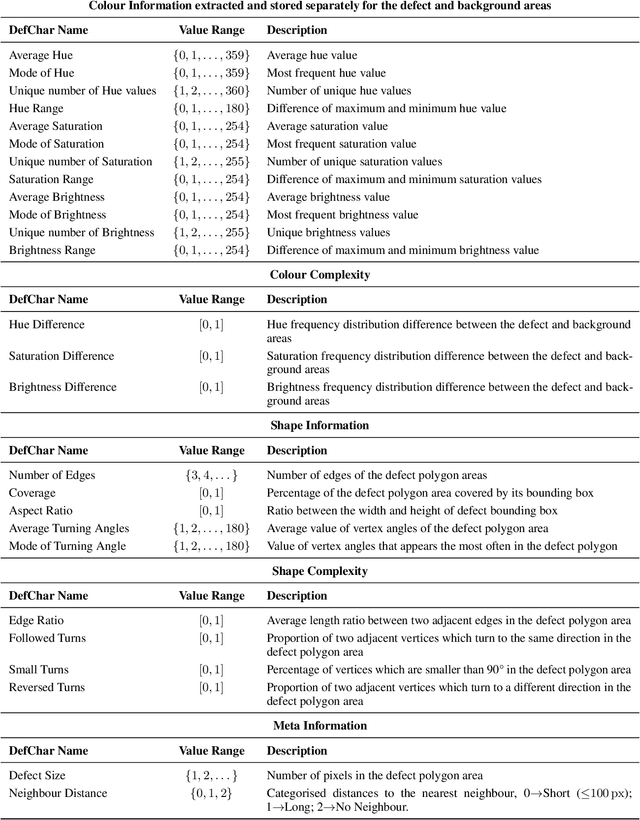
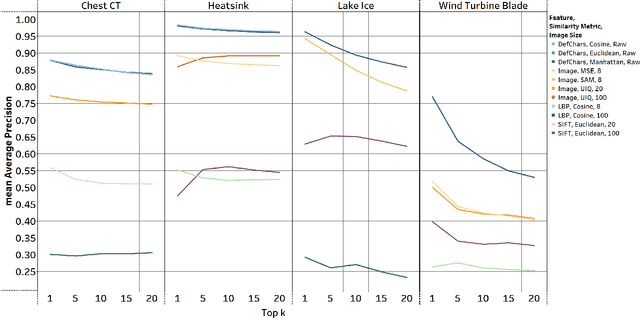
Image retrieval is the process of searching and retrieving images from a database based on their visual content and features. Recently, much attention has been directed towards the retrieval of irregular patterns within industrial or medical images by extracting features from the images, such as deep features, colour-based features, shape-based features and local features. This has applications across a spectrum of industries, including fault inspection, disease diagnosis, and maintenance prediction. This paper proposes an image retrieval framework to search for images containing similar irregular patterns by extracting a set of morphological features (DefChars) from images; the datasets employed in this paper contain wind turbine blade images with defects, chest computerised tomography scans with COVID-19 infection, heatsink images with defects, and lake ice images. The proposed framework was evaluated with different feature extraction methods (DefChars, resized raw image, local binary pattern, and scale-invariant feature transforms) and distance metrics to determine the most efficient parameters in terms of retrieval performance across datasets. The retrieval results show that the proposed framework using the DefChars and the Manhattan distance metric achieves a mean average precision of 80% and a low standard deviation of 0.09 across classes of irregular patterns, outperforming alternative feature-metric combinations across all datasets. Furthermore, the low standard deviation between each class highlights DefChars' capability for a reliable image retrieval task, even in the presence of class imbalances or small-sized datasets.
Generative Image Dynamics
Sep 14, 2023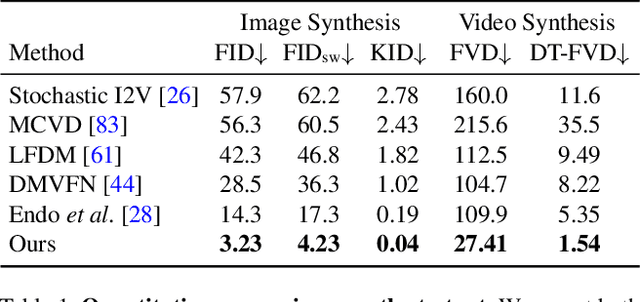
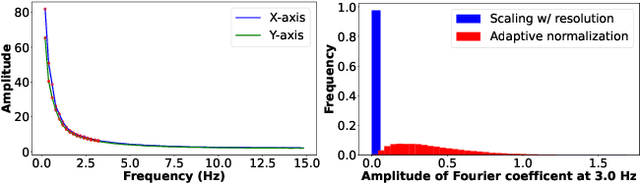
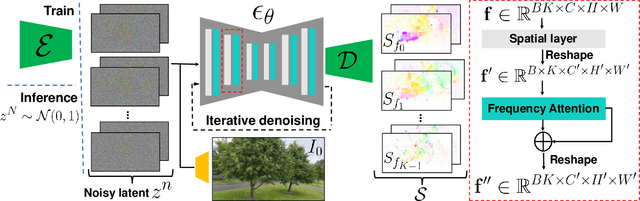
We present an approach to modeling an image-space prior on scene dynamics. Our prior is learned from a collection of motion trajectories extracted from real video sequences containing natural, oscillating motion such as trees, flowers, candles, and clothes blowing in the wind. Given a single image, our trained model uses a frequency-coordinated diffusion sampling process to predict a per-pixel long-term motion representation in the Fourier domain, which we call a neural stochastic motion texture. This representation can be converted into dense motion trajectories that span an entire video. Along with an image-based rendering module, these trajectories can be used for a number of downstream applications, such as turning still images into seamlessly looping dynamic videos, or allowing users to realistically interact with objects in real pictures.
Pruning random resistive memory for optimizing analogue AI
Nov 13, 2023The rapid advancement of artificial intelligence (AI) has been marked by the large language models exhibiting human-like intelligence. However, these models also present unprecedented challenges to energy consumption and environmental sustainability. One promising solution is to revisit analogue computing, a technique that predates digital computing and exploits emerging analogue electronic devices, such as resistive memory, which features in-memory computing, high scalability, and nonvolatility. However, analogue computing still faces the same challenges as before: programming nonidealities and expensive programming due to the underlying devices physics. Here, we report a universal solution, software-hardware co-design using structural plasticity-inspired edge pruning to optimize the topology of a randomly weighted analogue resistive memory neural network. Software-wise, the topology of a randomly weighted neural network is optimized by pruning connections rather than precisely tuning resistive memory weights. Hardware-wise, we reveal the physical origin of the programming stochasticity using transmission electron microscopy, which is leveraged for large-scale and low-cost implementation of an overparameterized random neural network containing high-performance sub-networks. We implemented the co-design on a 40nm 256K resistive memory macro, observing 17.3% and 19.9% accuracy improvements in image and audio classification on FashionMNIST and Spoken digits datasets, as well as 9.8% (2%) improvement in PR (ROC) in image segmentation on DRIVE datasets, respectively. This is accompanied by 82.1%, 51.2%, and 99.8% improvement in energy efficiency thanks to analogue in-memory computing. By embracing the intrinsic stochasticity and in-memory computing, this work may solve the biggest obstacle of analogue computing systems and thus unleash their immense potential for next-generation AI hardware.
HartleyMHA: Self-Attention in Frequency Domain for Resolution-Robust and Parameter-Efficient 3D Image Segmentation
Oct 05, 2023With the introduction of Transformers, different attention-based models have been proposed for image segmentation with promising results. Although self-attention allows capturing of long-range dependencies, it suffers from a quadratic complexity in the image size especially in 3D. To avoid the out-of-memory error during training, input size reduction is usually required for 3D segmentation, but the accuracy can be suboptimal when the trained models are applied on the original image size. To address this limitation, inspired by the Fourier neural operator (FNO), we introduce the HartleyMHA model which is robust to training image resolution with efficient self-attention. FNO is a deep learning framework for learning mappings between functions in partial differential equations, which has the appealing properties of zero-shot super-resolution and global receptive field. We modify the FNO by using the Hartley transform with shared parameters to reduce the model size by orders of magnitude, and this allows us to further apply self-attention in the frequency domain for more expressive high-order feature combination with improved efficiency. When tested on the BraTS'19 dataset, it achieved superior robustness to training image resolution than other tested models with less than 1% of their model parameters.
Zero-Shot Robotic Manipulation with Pretrained Image-Editing Diffusion Models
Oct 16, 2023If generalist robots are to operate in truly unstructured environments, they need to be able to recognize and reason about novel objects and scenarios. Such objects and scenarios might not be present in the robot's own training data. We propose SuSIE, a method that leverages an image-editing diffusion model to act as a high-level planner by proposing intermediate subgoals that a low-level controller can accomplish. Specifically, we finetune InstructPix2Pix on video data, consisting of both human videos and robot rollouts, such that it outputs hypothetical future "subgoal" observations given the robot's current observation and a language command. We also use the robot data to train a low-level goal-conditioned policy to act as the aforementioned low-level controller. We find that the high-level subgoal predictions can utilize Internet-scale pretraining and visual understanding to guide the low-level goal-conditioned policy, achieving significantly better generalization and precision than conventional language-conditioned policies. We achieve state-of-the-art results on the CALVIN benchmark, and also demonstrate robust generalization on real-world manipulation tasks, beating strong baselines that have access to privileged information or that utilize orders of magnitude more compute and training data. The project website can be found at http://rail-berkeley.github.io/susie .