 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
TransFusion -- A Transparency-Based Diffusion Model for Anomaly Detection
Nov 16, 2023
Surface anomaly detection is a vital component in manufacturing inspection. Reconstructive anomaly detection methods restore the normal appearance of an object, ideally modifying only the anomalous regions. Due to the limitations of commonly used reconstruction architectures, the produced reconstructions are often poor and either still contain anomalies or lack details in anomaly-free regions. Recent reconstructive methods adopt diffusion models, however with the standard diffusion process the problems are not adequately addressed. We propose a novel transparency-based diffusion process, where the transparency of anomalous regions is progressively increased, restoring their normal appearance accurately and maintaining the appearance of anomaly-free regions without loss of detail. We propose TRANSparency DifFUSION (TransFusion), a discriminative anomaly detection method that implements the proposed diffusion process, enabling accurate downstream anomaly detection. TransFusion achieves state-of-the-art performance on both the VisA and the MVTec AD datasets, with an image-level AUROC of 98.5% and 99.2%, respectively.
GSAP-NER: A Novel Task, Corpus, and Baseline for Scholarly Entity Extraction Focused on Machine Learning Models and Datasets
Nov 16, 2023Named Entity Recognition (NER) models play a crucial role in various NLP tasks, including information extraction (IE) and text understanding. In academic writing, references to machine learning models and datasets are fundamental components of various computer science publications and necessitate accurate models for identification. Despite the advancements in NER, existing ground truth datasets do not treat fine-grained types like ML model and model architecture as separate entity types, and consequently, baseline models cannot recognize them as such. In this paper, we release a corpus of 100 manually annotated full-text scientific publications and a first baseline model for 10 entity types centered around ML models and datasets. In order to provide a nuanced understanding of how ML models and datasets are mentioned and utilized, our dataset also contains annotations for informal mentions like "our BERT-based model" or "an image CNN". You can find the ground truth dataset and code to replicate model training at https://data.gesis.org/gsap/gsap-ner.
Large Language Models for Propaganda Span Annotation
Nov 16, 2023The use of propagandistic techniques in online communication has increased in recent years, aiming to manipulate online audiences. Efforts to automatically detect and debunk such content have been made, addressing various modeling scenarios. These include determining whether the content (text, image, or multimodal) (i) is propagandistic, (ii) employs one or more techniques, and (iii) includes techniques with identifiable spans. Significant research efforts have been devoted to the first two scenarios compared to the latter. Therefore, in this study, we focus on the task of detecting propagandistic textual spans. We investigate whether large language models such as GPT-4 can be utilized to perform the task of an annotator. For the experiments, we used an in-house developed dataset consisting of annotations from multiple annotators. Our results suggest that providing more information to the model as prompts improves the annotation agreement and performance compared to human annotations. We plan to make the annotated labels from multiple annotators, including GPT-4, available for the community.
3DStyle-Diffusion: Pursuing Fine-grained Text-driven 3D Stylization with 2D Diffusion Models
Nov 09, 20233D content creation via text-driven stylization has played a fundamental challenge to multimedia and graphics community. Recent advances of cross-modal foundation models (e.g., CLIP) have made this problem feasible. Those approaches commonly leverage CLIP to align the holistic semantics of stylized mesh with the given text prompt. Nevertheless, it is not trivial to enable more controllable stylization of fine-grained details in 3D meshes solely based on such semantic-level cross-modal supervision. In this work, we propose a new 3DStyle-Diffusion model that triggers fine-grained stylization of 3D meshes with additional controllable appearance and geometric guidance from 2D Diffusion models. Technically, 3DStyle-Diffusion first parameterizes the texture of 3D mesh into reflectance properties and scene lighting using implicit MLP networks. Meanwhile, an accurate depth map of each sampled view is achieved conditioned on 3D mesh. Then, 3DStyle-Diffusion leverages a pre-trained controllable 2D Diffusion model to guide the learning of rendered images, encouraging the synthesized image of each view semantically aligned with text prompt and geometrically consistent with depth map. This way elegantly integrates both image rendering via implicit MLP networks and diffusion process of image synthesis in an end-to-end fashion, enabling a high-quality fine-grained stylization of 3D meshes. We also build a new dataset derived from Objaverse and the evaluation protocol for this task. Through both qualitative and quantitative experiments, we validate the capability of our 3DStyle-Diffusion. Source code and data are available at \url{https://github.com/yanghb22-fdu/3DStyle-Diffusion-Official}.
Open-Vocabulary Camouflaged Object Segmentation
Nov 19, 2023
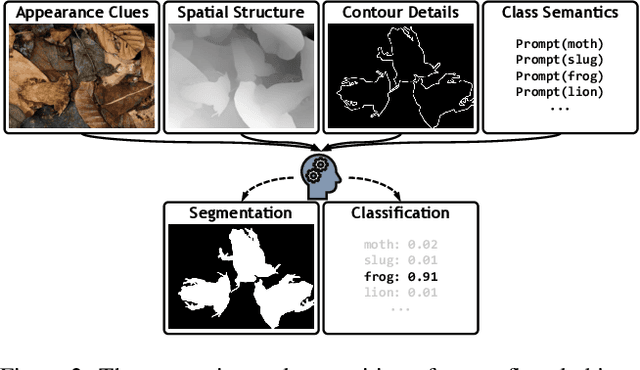
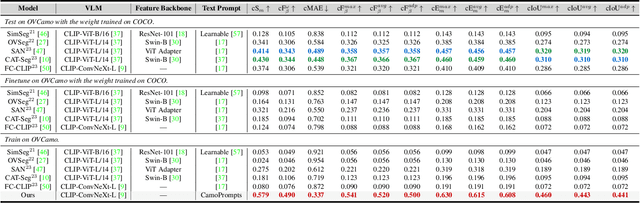

Recently, the emergence of the large-scale vision-language model (VLM), such as CLIP, has opened the way towards open-world object perception. Many works has explored the utilization of pre-trained VLM for the challenging open-vocabulary dense prediction task that requires perceive diverse objects with novel classes at inference time. Existing methods construct experiments based on the public datasets of related tasks, which are not tailored for open vocabulary and rarely involves imperceptible objects camouflaged in complex scenes due to data collection bias and annotation costs. To fill in the gaps, we introduce a new task, open-vocabulary camouflaged object segmentation (OVCOS) and construct a large-scale complex scene dataset (\textbf{OVCamo}) which containing 11,483 hand-selected images with fine annotations and corresponding object classes. Further, we build a strong single-stage open-vocabulary \underline{c}amouflaged \underline{o}bject \underline{s}egmentation transform\underline{er} baseline \textbf{OVCoser} attached to the parameter-fixed CLIP with iterative semantic guidance and structure enhancement. By integrating the guidance of class semantic knowledge and the supplement of visual structure cues from the edge and depth information, the proposed method can efficiently capture camouflaged objects. Moreover, this effective framework also surpasses previous state-of-the-arts of open-vocabulary semantic image segmentation by a large margin on our OVCamo dataset. With the proposed dataset and baseline, we hope that this new task with more practical value can further expand the research on open-vocabulary dense prediction tasks.
FS-Net: Full Scale Network and Adaptive Threshold for Improving Extraction of Micro-Retinal Vessel Structures
Nov 19, 2023Retinal vascular segmentation, is a widely researched subject in biomedical image processing, aims to relieve ophthalmologists' workload when treating and detecting retinal disorders. However, segmenting retinal vessels has its own set of challenges, with prior techniques failing to generate adequate results when segmenting branches and microvascular structures. The neural network approaches used recently are characterized by the inability to keep local and global properties together and the failure to capture tiny end vessels make it challenging to attain the desired result. To reduce this retinal vessel segmentation problem, we propose a full-scale micro-vessel extraction mechanism based on an encoder-decoder neural network architecture, sigmoid smoothing, and an adaptive threshold method. The network consists of of residual, encoder booster, bottleneck enhancement, squeeze, and excitation building blocks. All of these blocks together help to improve the feature extraction and prediction of the segmentation map. The proposed solution has been evaluated using the DRIVE, CHASE-DB1, and STARE datasets, and competitive results are obtained when compared with previous studies. The AUC and accuracy on the DRIVE dataset are 0.9884 and 0.9702, respectively. On the CHASE-DB1 dataset, the scores are 0.9903 and 0.9755, respectively. On the STARE dataset, the scores are 0.9916 and 0.9750, respectively. The performance achieved is one step ahead of what has been done in previous studies, and this results in a higher chance of having this solution in real-life diagnostic centers that seek ophthalmologists attention.
DreamCom: Finetuning Text-guided Inpainting Model for Image Composition
Sep 27, 2023The goal of image composition is merging a foreground object into a background image to obtain a realistic composite image. Recently, generative composition methods are built on large pretrained diffusion models, due to their unprecedented image generation ability. They train a model on abundant pairs of foregrounds and backgrounds, so that it can be directly applied to a new pair of foreground and background at test time. However, the generated results often lose the foreground details and exhibit noticeable artifacts. In this work, we propose an embarrassingly simple approach named DreamCom inspired by DreamBooth. Specifically, given a few reference images for a subject, we finetune text-guided inpainting diffusion model to associate this subject with a special token and inpaint this subject in the specified bounding box. We also construct a new dataset named MureCom well-tailored for this task.
PRIS: Practical robust invertible network for image steganography
Sep 24, 2023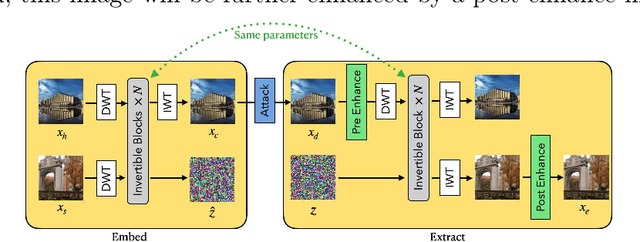
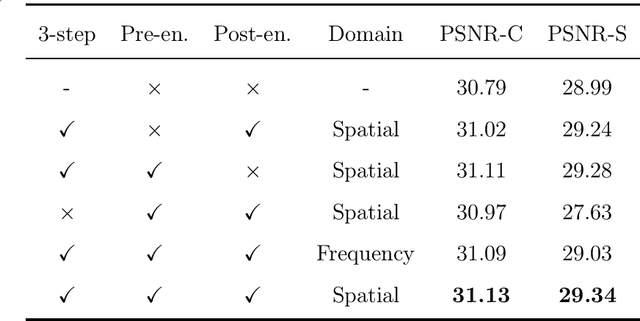
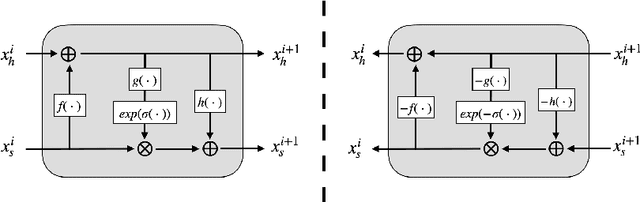
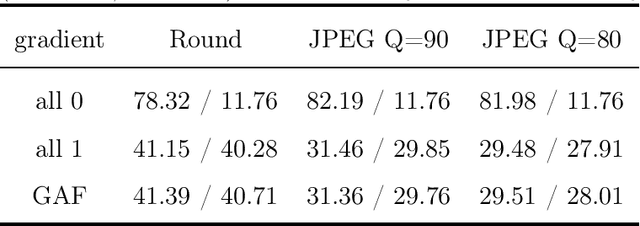
Image steganography is a technique of hiding secret information inside another image, so that the secret is not visible to human eyes and can be recovered when needed. Most of the existing image steganography methods have low hiding robustness when the container images affected by distortion. Such as Gaussian noise and lossy compression. This paper proposed PRIS to improve the robustness of image steganography, it based on invertible neural networks, and put two enhance modules before and after the extraction process with a 3-step training strategy. Moreover, rounding error is considered which is always ignored by existing methods, but actually it is unavoidable in practical. A gradient approximation function (GAF) is also proposed to overcome the undifferentiable issue of rounding distortion. Experimental results show that our PRIS outperforms the state-of-the-art robust image steganography method in both robustness and practicability. Codes are available at https://github.com/yanghangAI/PRIS, demonstration of our model in practical at http://yanghang.site/hide/.
Leveraging Optimization for Adaptive Attacks on Image Watermarks
Sep 29, 2023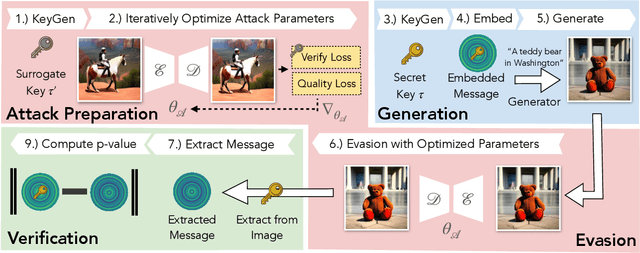
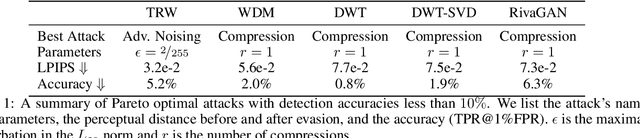
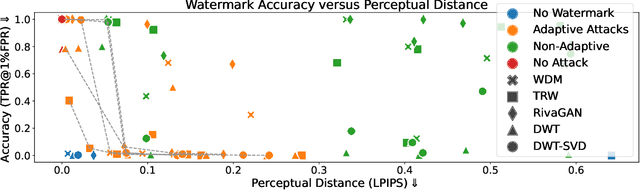
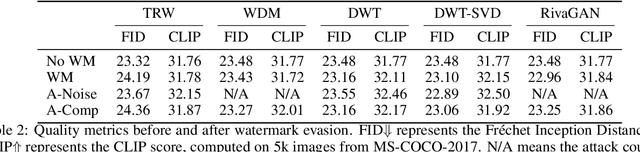
Untrustworthy users can misuse image generators to synthesize high-quality deepfakes and engage in online spam or disinformation campaigns. Watermarking deters misuse by marking generated content with a hidden message, enabling its detection using a secret watermarking key. A core security property of watermarking is robustness, which states that an attacker can only evade detection by substantially degrading image quality. Assessing robustness requires designing an adaptive attack for the specific watermarking algorithm. A challenge when evaluating watermarking algorithms and their (adaptive) attacks is to determine whether an adaptive attack is optimal, i.e., it is the best possible attack. We solve this problem by defining an objective function and then approach adaptive attacks as an optimization problem. The core idea of our adaptive attacks is to replicate secret watermarking keys locally by creating surrogate keys that are differentiable and can be used to optimize the attack's parameters. We demonstrate for Stable Diffusion models that such an attacker can break all five surveyed watermarking methods at negligible degradation in image quality. These findings emphasize the need for more rigorous robustness testing against adaptive, learnable attackers.
A review of uncertainty quantification in medical image analysis: probabilistic and non-probabilistic methods
Oct 09, 2023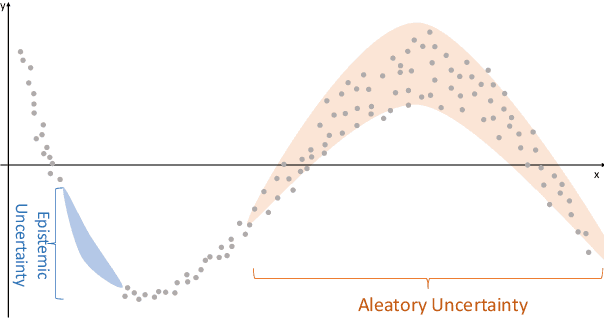
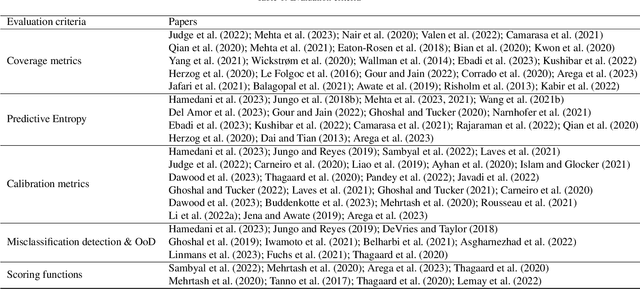
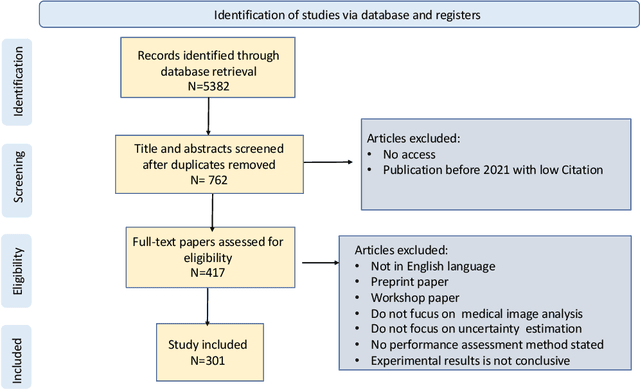
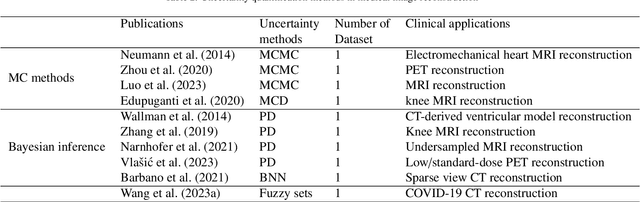
The comprehensive integration of machine learning healthcare models within clinical practice remains suboptimal, notwithstanding the proliferation of high-performing solutions reported in the literature. A predominant factor hindering widespread adoption pertains to an insufficiency of evidence affirming the reliability of the aforementioned models. Recently, uncertainty quantification methods have been proposed as a potential solution to quantify the reliability of machine learning models and thus increase the interpretability and acceptability of the result. In this review, we offer a comprehensive overview of prevailing methods proposed to quantify uncertainty inherent in machine learning models developed for various medical image tasks. Contrary to earlier reviews that exclusively focused on probabilistic methods, this review also explores non-probabilistic approaches, thereby furnishing a more holistic survey of research pertaining to uncertainty quantification for machine learning models. Analysis of medical images with the summary and discussion on medical applications and the corresponding uncertainty evaluation protocols are presented, which focus on the specific challenges of uncertainty in medical image analysis. We also highlight some potential future research work at the end. Generally, this review aims to allow researchers from both clinical and technical backgrounds to gain a quick and yet in-depth understanding of the research in uncertainty quantification for medical image analysis machine learning models.