 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
CL-Flow:Strengthening the Normalizing Flows by Contrastive Learning for Better Anomaly Detection
Nov 12, 2023
In the anomaly detection field, the scarcity of anomalous samples has directed the current research emphasis towards unsupervised anomaly detection. While these unsupervised anomaly detection methods offer convenience, they also overlook the crucial prior information embedded within anomalous samples. Moreover, among numerous deep learning methods, supervised methods generally exhibit superior performance compared to unsupervised methods. Considering the reasons mentioned above, we propose a self-supervised anomaly detection approach that combines contrastive learning with 2D-Flow to achieve more precise detection outcomes and expedited inference processes. On one hand, we introduce a novel approach to anomaly synthesis, yielding anomalous samples in accordance with authentic industrial scenarios, alongside their surrogate annotations. On the other hand, having obtained a substantial number of anomalous samples, we enhance the 2D-Flow framework by incorporating contrastive learning, leveraging diverse proxy tasks to fine-tune the network. Our approach enables the network to learn more precise mapping relationships from self-generated labels while retaining the lightweight characteristics of the 2D-Flow. Compared to mainstream unsupervised approaches, our self-supervised method demonstrates superior detection accuracy, fewer additional model parameters, and faster inference speed. Furthermore, the entire training and inference process is end-to-end. Our approach showcases new state-of-the-art results, achieving a performance of 99.6\% in image-level AUROC on the MVTecAD dataset and 96.8\% in image-level AUROC on the BTAD dataset.
PrototypeFormer: Learning to Explore Prototype Relationships for Few-shot Image Classification
Oct 05, 2023Few-shot image classification has received considerable attention for addressing the challenge of poor classification performance with limited samples in novel classes. However, numerous studies have employed sophisticated learning strategies and diversified feature extraction methods to address this issue. In this paper, we propose our method called PrototypeFormer, which aims to significantly advance traditional few-shot image classification approaches by exploring prototype relationships. Specifically, we utilize a transformer architecture to build a prototype extraction module, aiming to extract class representations that are more discriminative for few-shot classification. Additionally, during the model training process, we propose a contrastive learning-based optimization approach to optimize prototype features in few-shot learning scenarios. Despite its simplicity, the method performs remarkably well, with no bells and whistles. We have experimented with our approach on several popular few-shot image classification benchmark datasets, which shows that our method outperforms all current state-of-the-art methods. In particular, our method achieves 97.07% and 90.88% on 5-way 5-shot and 5-way 1-shot tasks of miniImageNet, which surpasses the state-of-the-art results with accuracy of 7.27% and 8.72%, respectively. The code will be released later.
Music ControlNet: Multiple Time-varying Controls for Music Generation
Nov 13, 2023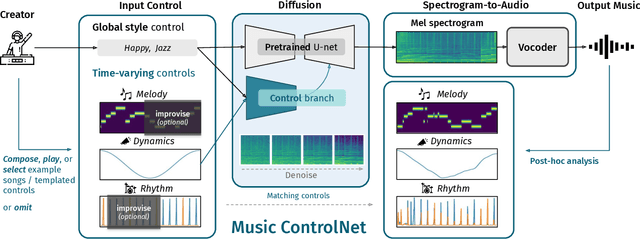
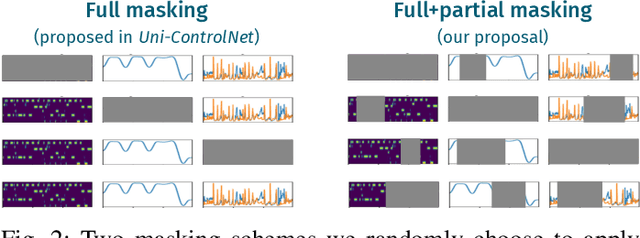
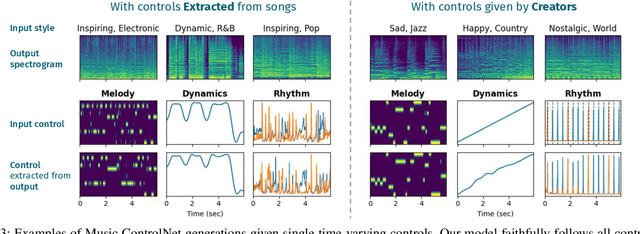
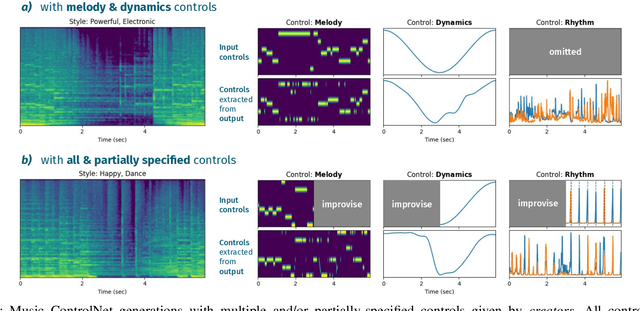
Text-to-music generation models are now capable of generating high-quality music audio in broad styles. However, text control is primarily suitable for the manipulation of global musical attributes like genre, mood, and tempo, and is less suitable for precise control over time-varying attributes such as the positions of beats in time or the changing dynamics of the music. We propose Music ControlNet, a diffusion-based music generation model that offers multiple precise, time-varying controls over generated audio. To imbue text-to-music models with time-varying control, we propose an approach analogous to pixel-wise control of the image-domain ControlNet method. Specifically, we extract controls from training audio yielding paired data, and fine-tune a diffusion-based conditional generative model over audio spectrograms given melody, dynamics, and rhythm controls. While the image-domain Uni-ControlNet method already allows generation with any subset of controls, we devise a new strategy to allow creators to input controls that are only partially specified in time. We evaluate both on controls extracted from audio and controls we expect creators to provide, demonstrating that we can generate realistic music that corresponds to control inputs in both settings. While few comparable music generation models exist, we benchmark against MusicGen, a recent model that accepts text and melody input, and show that our model generates music that is 49% more faithful to input melodies despite having 35x fewer parameters, training on 11x less data, and enabling two additional forms of time-varying control. Sound examples can be found at https://MusicControlNet.github.io/web/.
Deformable Groupwise Registration Using a Locally Low-Rank Dissimilarity Metric for Myocardial Strain Estimation from Cardiac Cine MRI Images
Nov 13, 2023Objective: Cardiovascular magnetic resonance-feature tracking (CMR-FT) represents a group of methods for myocardial strain estimation from cardiac cine MRI images. Established CMR-FT methods are mainly based on optical flow or pairwise registration. However, these methods suffer from either inaccurate estimation of large motion or drift effect caused by accumulative tracking errors. In this work, we propose a deformable groupwise registration method using a locally low-rank (LLR) dissimilarity metric for CMR-FT. Methods: The proposed method (Groupwise-LLR) tracks the feature points by a groupwise registration-based two-step strategy. Unlike the globally low-rank (GLR) dissimilarity metric, the proposed LLR metric imposes low-rankness on local image patches rather than the whole image. We quantitatively compared Groupwise-LLR with the Farneback optical flow, a pairwise registration method, and a GLR-based groupwise registration method on simulated and in vivo datasets. Results: Results from the simulated dataset showed that Groupwise-LLR achieved more accurate tracking and strain estimation compared with the other methods. Results from the in vivo dataset showed that Groupwise-LLR achieved more accurate tracking and elimination of the drift effect in late-diastole. Inter-observer reproducibility of strain estimates was similar between all studied methods. Conclusion: The proposed method estimates myocardial strains more accurately due to the application of a groupwise registration-based tracking strategy and an LLR-based dissimilarity metric. Significance: The proposed CMR-FT method may facilitate more accurate estimation of myocardial strains, especially in diastole, for clinical assessments of cardiac dysfunction.
Contrastive Learning for Multi-Object Tracking with Transformers
Nov 14, 2023The DEtection TRansformer (DETR) opened new possibilities for object detection by modeling it as a translation task: converting image features into object-level representations. Previous works typically add expensive modules to DETR to perform Multi-Object Tracking (MOT), resulting in more complicated architectures. We instead show how DETR can be turned into a MOT model by employing an instance-level contrastive loss, a revised sampling strategy and a lightweight assignment method. Our training scheme learns object appearances while preserving detection capabilities and with little overhead. Its performance surpasses the previous state-of-the-art by +2.6 mMOTA on the challenging BDD100K dataset and is comparable to existing transformer-based methods on the MOT17 dataset.
MagicDance: Realistic Human Dance Video Generation with Motions & Facial Expressions Transfer
Nov 18, 2023In this work, we propose MagicDance, a diffusion-based model for 2D human motion and facial expression transfer on challenging human dance videos. Specifically, we aim to generate human dance videos of any target identity driven by novel pose sequences while keeping the identity unchanged. To this end, we propose a two-stage training strategy to disentangle human motions and appearance (e.g., facial expressions, skin tone and dressing), consisting of the pretraining of an appearance-control block and fine-tuning of an appearance-pose-joint-control block over human dance poses of the same dataset. Our novel design enables robust appearance control with temporally consistent upper body, facial attributes, and even background. The model also generalizes well on unseen human identities and complex motion sequences without the need for any fine-tuning with additional data with diverse human attributes by leveraging the prior knowledge of image diffusion models. Moreover, the proposed model is easy to use and can be considered as a plug-in module/extension to Stable Diffusion. We also demonstrate the model's ability for zero-shot 2D animation generation, enabling not only the appearance transfer from one identity to another but also allowing for cartoon-like stylization given only pose inputs. Extensive experiments demonstrate our superior performance on the TikTok dataset.
Boost Adversarial Transferability by Uniform Scale and Mix Mask Method
Nov 18, 2023
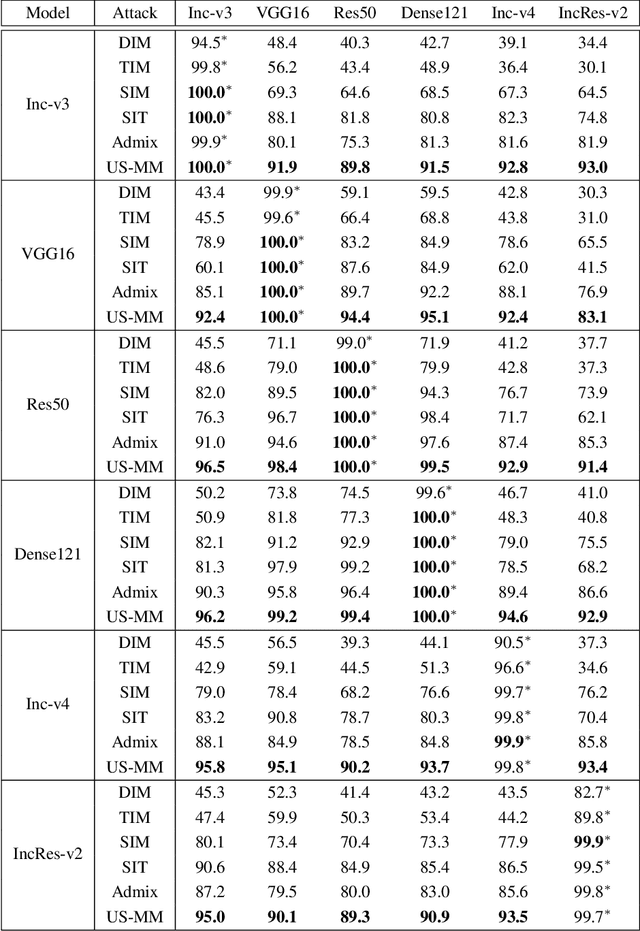
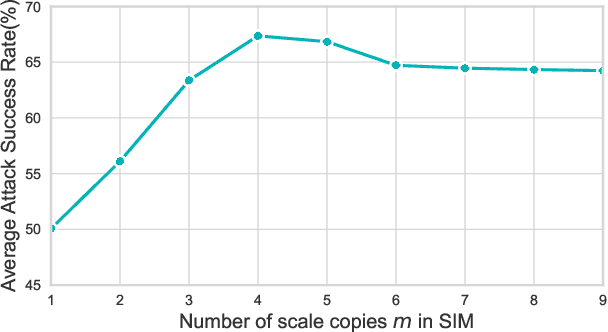
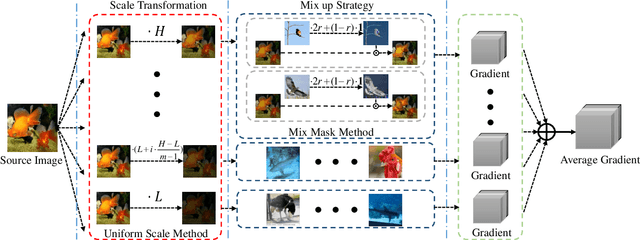
Adversarial examples generated from surrogate models often possess the ability to deceive other black-box models, a property known as transferability. Recent research has focused on enhancing adversarial transferability, with input transformation being one of the most effective approaches. However, existing input transformation methods suffer from two issues. Firstly, certain methods, such as the Scale-Invariant Method, employ exponentially decreasing scale invariant parameters that decrease the adaptability in generating effective adversarial examples across multiple scales. Secondly, most mixup methods only linearly combine candidate images with the source image, leading to reduced features blending effectiveness. To address these challenges, we propose a framework called Uniform Scale and Mix Mask Method (US-MM) for adversarial example generation. The Uniform Scale approach explores the upper and lower boundaries of perturbation with a linear factor, minimizing the negative impact of scale copies. The Mix Mask method introduces masks into the mixing process in a nonlinear manner, significantly improving the effectiveness of mixing strategies. Ablation experiments are conducted to validate the effectiveness of each component in US-MM and explore the effect of hyper-parameters. Empirical evaluations on standard ImageNet datasets demonstrate that US-MM achieves an average of 7% better transfer attack success rate compared to state-of-the-art methods.
Energy-based Calibrated VAE with Test Time Free Lunch
Nov 07, 2023In this paper, we propose a novel Energy-Calibrated Generative Model that utilizes a Conditional EBM for enhancing Variational Autoencoders (VAEs). VAEs are sampling efficient but often suffer from blurry generation results due to the lack of training in the generative direction. On the other hand, Energy-Based Models (EBMs) can generate high-quality samples but require expensive Markov Chain Monte Carlo (MCMC) sampling. To address these issues, we introduce a Conditional EBM for calibrating the generative direction during training, without requiring it for test time sampling. Our approach enables the generative model to be trained upon data and calibrated samples with adaptive weight, thereby enhancing efficiency and effectiveness without necessitating MCMC sampling in the inference phase. We also show that the proposed approach can be extended to calibrate normalizing flows and variational posterior. Moreover, we propose to apply the proposed method to zero-shot image restoration via neural transport prior and range-null theory. We demonstrate the effectiveness of the proposed method through extensive experiments in various applications, including image generation and zero-shot image restoration. Our method shows state-of-the-art performance over single-step non-adversarial generation.
Inertial Guided Uncertainty Estimation of Feature Correspondence in Visual-Inertial Odometry/SLAM
Nov 07, 2023Visual odometry and Simultaneous Localization And Mapping (SLAM) has been studied as one of the most important tasks in the areas of computer vision and robotics, to contribute to autonomous navigation and augmented reality systems. In case of feature-based odometry/SLAM, a moving visual sensor observes a set of 3D points from different viewpoints, correspondences between the projected 2D points in each image are usually established by feature tracking and matching. However, since the corresponding point could be erroneous and noisy, reliable uncertainty estimation can improve the accuracy of odometry/SLAM methods. In addition, inertial measurement unit is utilized to aid the visual sensor in terms of Visual-Inertial fusion. In this paper, we propose a method to estimate the uncertainty of feature correspondence using an inertial guidance robust to image degradation caused by motion blur, illumination change and occlusion. Modeling a guidance distribution to sample possible correspondence, we fit the distribution to an energy function based on image error, yielding more robust uncertainty than conventional methods. We also demonstrate the feasibility of our approach by incorporating it into one of recent visual-inertial odometry/SLAM algorithms for public datasets.
On the Overconfidence Problem in Semantic 3D Mapping
Nov 16, 2023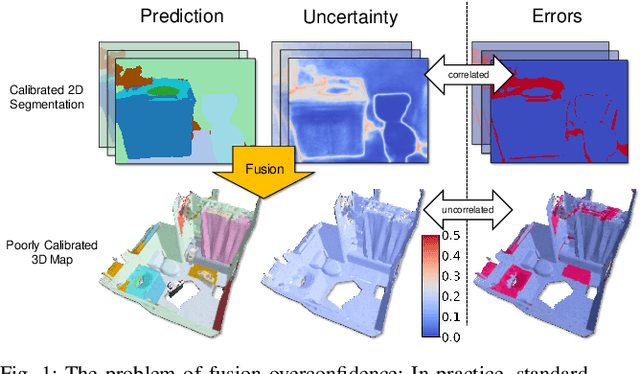
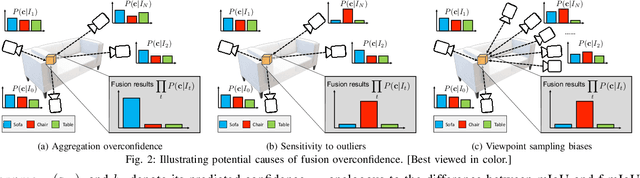
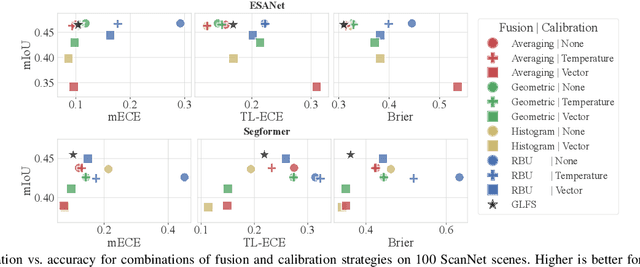
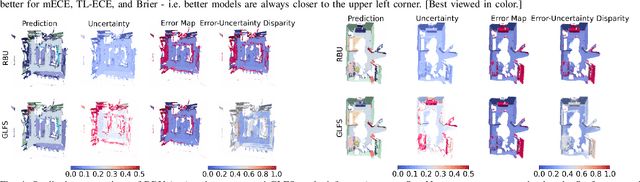
Semantic 3D mapping, the process of fusing depth and image segmentation information between multiple views to build 3D maps annotated with object classes in real-time, is a recent topic of interest. This paper highlights the fusion overconfidence problem, in which conventional mapping methods assign high confidence to the entire map even when they are incorrect, leading to miscalibrated outputs. Several methods to improve uncertainty calibration at different stages in the fusion pipeline are presented and compared on the ScanNet dataset. We show that the most widely used Bayesian fusion strategy is among the worst calibrated, and propose a learned pipeline that combines fusion and calibration, GLFS, which achieves simultaneously higher accuracy and 3D map calibration while retaining real-time capability. We further illustrate the importance of map calibration on a downstream task by showing that incorporating proper semantic fusion on a modular ObjectNav agent improves its success rates. Our code will be provided on Github for reproducibility upon acceptance.