 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
DPA-Net: Structured 3D Abstraction from Sparse Views via Differentiable Primitive Assembly
Apr 02, 2024
We present a differentiable rendering framework to learn structured 3D abstractions in the form of primitive assemblies from sparse RGB images capturing a 3D object. By leveraging differentiable volume rendering, our method does not require 3D supervision. Architecturally, our network follows the general pipeline of an image-conditioned neural radiance field (NeRF) exemplified by pixelNeRF for color prediction. As our core contribution, we introduce differential primitive assembly (DPA) into NeRF to output a 3D occupancy field in place of density prediction, where the predicted occupancies serve as opacity values for volume rendering. Our network, coined DPA-Net, produces a union of convexes, each as an intersection of convex quadric primitives, to approximate the target 3D object, subject to an abstraction loss and a masking loss, both defined in the image space upon volume rendering. With test-time adaptation and additional sampling and loss designs aimed at improving the accuracy and compactness of the obtained assemblies, our method demonstrates superior performance over state-of-the-art alternatives for 3D primitive abstraction from sparse views.
Towards Memorization-Free Diffusion Models
Apr 01, 2024Pretrained diffusion models and their outputs are widely accessible due to their exceptional capacity for synthesizing high-quality images and their open-source nature. The users, however, may face litigation risks owing to the models' tendency to memorize and regurgitate training data during inference. To address this, we introduce Anti-Memorization Guidance (AMG), a novel framework employing three targeted guidance strategies for the main causes of memorization: image and caption duplication, and highly specific user prompts. Consequently, AMG ensures memorization-free outputs while maintaining high image quality and text alignment, leveraging the synergy of its guidance methods, each indispensable in its own right. AMG also features an innovative automatic detection system for potential memorization during each step of inference process, allows selective application of guidance strategies, minimally interfering with the original sampling process to preserve output utility. We applied AMG to pretrained Denoising Diffusion Probabilistic Models (DDPM) and Stable Diffusion across various generation tasks. The results demonstrate that AMG is the first approach to successfully eradicates all instances of memorization with no or marginal impacts on image quality and text-alignment, as evidenced by FID and CLIP scores.
Marrying NeRF with Feature Matching for One-step Pose Estimation
Apr 01, 2024Given the image collection of an object, we aim at building a real-time image-based pose estimation method, which requires neither its CAD model nor hours of object-specific training. Recent NeRF-based methods provide a promising solution by directly optimizing the pose from pixel loss between rendered and target images. However, during inference, they require long converging time, and suffer from local minima, making them impractical for real-time robot applications. We aim at solving this problem by marrying image matching with NeRF. With 2D matches and depth rendered by NeRF, we directly solve the pose in one step by building 2D-3D correspondences between target and initial view, thus allowing for real-time prediction. Moreover, to improve the accuracy of 2D-3D correspondences, we propose a 3D consistent point mining strategy, which effectively discards unfaithful points reconstruted by NeRF. Moreover, current NeRF-based methods naively optimizing pixel loss fail at occluded images. Thus, we further propose a 2D matches based sampling strategy to preclude the occluded area. Experimental results on representative datasets prove that our method outperforms state-of-the-art methods, and improves inference efficiency by 90x, achieving real-time prediction at 6 FPS.
VmambaIR: Visual State Space Model for Image Restoration
Mar 18, 2024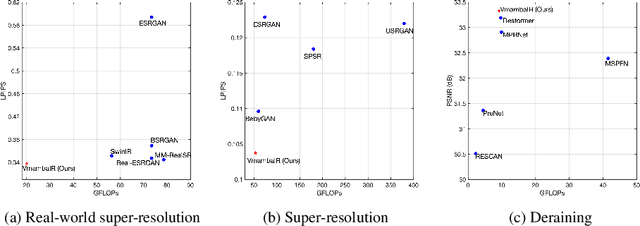
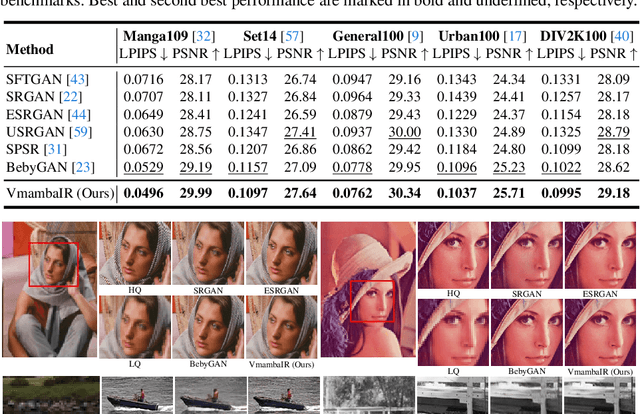
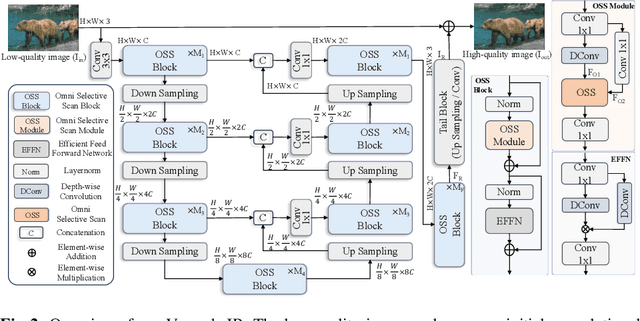
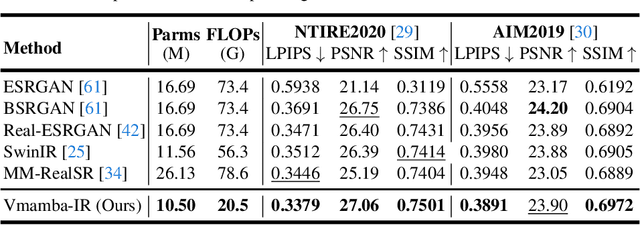
Image restoration is a critical task in low-level computer vision, aiming to restore high-quality images from degraded inputs. Various models, such as convolutional neural networks (CNNs), generative adversarial networks (GANs), transformers, and diffusion models (DMs), have been employed to address this problem with significant impact. However, CNNs have limitations in capturing long-range dependencies. DMs require large prior models and computationally intensive denoising steps. Transformers have powerful modeling capabilities but face challenges due to quadratic complexity with input image size. To address these challenges, we propose VmambaIR, which introduces State Space Models (SSMs) with linear complexity into comprehensive image restoration tasks. We utilize a Unet architecture to stack our proposed Omni Selective Scan (OSS) blocks, consisting of an OSS module and an Efficient Feed-Forward Network (EFFN). Our proposed omni selective scan mechanism overcomes the unidirectional modeling limitation of SSMs by efficiently modeling image information flows in all six directions. Furthermore, we conducted a comprehensive evaluation of our VmambaIR across multiple image restoration tasks, including image deraining, single image super-resolution, and real-world image super-resolution. Extensive experimental results demonstrate that our proposed VmambaIR achieves state-of-the-art (SOTA) performance with much fewer computational resources and parameters. Our research highlights the potential of state space models as promising alternatives to the transformer and CNN architectures in serving as foundational frameworks for next-generation low-level visual tasks.
Deep-learning Segmentation of Small Volumes in CT images for Radiotherapy Treatment Planning
Apr 05, 2024Our understanding of organs at risk is progressing to include physical small tissues such as coronary arteries and the radiosensitivities of many small organs and tissues are high. Therefore, the accurate segmentation of small volumes in external radiotherapy is crucial to protect them from over-irradiation. Moreover, with the development of the particle therapy and on-board imaging, the treatment becomes more accurate and precise. The purpose of this work is to optimize organ segmentation algorithms for small organs. We used 50 three-dimensional (3-D) computed tomography (CT) head and neck images from StructSeg2019 challenge to develop a general-purpose V-Net model to segment 20 organs in the head and neck region. We applied specific strategies to improve the segmentation accuracy of the small volumes in this anatomical region, i.e., the lens of the eye. Then, we used 17 additional head images from OSF healthcare to validate the robustness of the V Net model optimized for small-volume segmentation. With the study of the StructSeg2019 images, we found that the optimization of the image normalization range and classification threshold yielded a segmentation improvement of the lens of the eye of approximately 50%, compared to the use of the V-Net not optimized for small volumes. We used the optimized model to segment 17 images acquired using heterogeneous protocols. We obtained comparable Dice coefficient values for the clinical and StructSeg2019 images (0.61 plus/minus 0.07 and 0.58 plus/minus 0.10 for the left and right lens of the eye, respectively)
Increasing Fairness in Classification of Out of Distribution Data for Facial Recognition
Apr 05, 2024Standard classification theory assumes that the distribution of images in the test and training sets are identical. Unfortunately, real-life scenarios typically feature unseen data ("out-of-distribution data") which is different from data in the training distribution("in-distribution"). This issue is most prevalent in social justice problems where data from under-represented groups may appear in the test data without representing an equal proportion of the training data. This may result in a model returning confidently wrong decisions and predictions. We are interested in the following question: Can the performance of a neural network improve on facial images of out-of-distribution data when it is trained simultaneously on multiple datasets of in-distribution data? We approach this problem by incorporating the Outlier Exposure model and investigate how the model's performance changes when other datasets of facial images were implemented. We observe that the accuracy and other metrics of the model can be increased by applying Outlier Exposure, incorporating a trainable weight parameter to increase the machine's emphasis on outlier images, and by re-weighting the importance of different class labels. We also experimented with whether sorting the images and determining outliers via image features would have more of an effect on the metrics than sorting by average pixel value. Our goal was to make models not only more accurate but also more fair by scanning a more expanded range of images. We also tested the datasets in reverse order to see whether a more fair dataset with balanced features has an effect on the model's accuracy.
DPMesh: Exploiting Diffusion Prior for Occluded Human Mesh Recovery
Apr 01, 2024The recovery of occluded human meshes presents challenges for current methods due to the difficulty in extracting effective image features under severe occlusion. In this paper, we introduce DPMesh, an innovative framework for occluded human mesh recovery that capitalizes on the profound diffusion prior about object structure and spatial relationships embedded in a pre-trained text-to-image diffusion model. Unlike previous methods reliant on conventional backbones for vanilla feature extraction, DPMesh seamlessly integrates the pre-trained denoising U-Net with potent knowledge as its image backbone and performs a single-step inference to provide occlusion-aware information. To enhance the perception capability for occluded poses, DPMesh incorporates well-designed guidance via condition injection, which produces effective controls from 2D observations for the denoising U-Net. Furthermore, we explore a dedicated noisy key-point reasoning approach to mitigate disturbances arising from occlusion and crowded scenarios. This strategy fully unleashes the perceptual capability of the diffusion prior, thereby enhancing accuracy. Extensive experiments affirm the efficacy of our framework, as we outperform state-of-the-art methods on both occlusion-specific and standard datasets. The persuasive results underscore its ability to achieve precise and robust 3D human mesh recovery, particularly in challenging scenarios involving occlusion and crowded scenes.
DiffDet4SAR: Diffusion-based Aircraft Target Detection Network for SAR Images
Apr 04, 2024Aircraft target detection in SAR images is a challenging task due to the discrete scattering points and severe background clutter interference. Currently, methods with convolution-based or transformer-based paradigms cannot adequately address these issues. In this letter, we explore diffusion models for SAR image aircraft target detection for the first time and propose a novel \underline{Diff}usion-based aircraft target \underline{Det}ection network \underline{for} \underline{SAR} images (DiffDet4SAR). Specifically, the proposed DiffDet4SAR yields two main advantages for SAR aircraft target detection: 1) DiffDet4SAR maps the SAR aircraft target detection task to a denoising diffusion process of bounding boxes without heuristic anchor size selection, effectively enabling large variations in aircraft sizes to be accommodated; and 2) the dedicatedly designed Scattering Feature Enhancement (SFE) module further reduces the clutter intensity and enhances the target saliency during inference. Extensive experimental results on the SAR-AIRcraft-1.0 dataset show that the proposed DiffDet4SAR achieves 88.4\% mAP$_{50}$, outperforming the state-of-the-art methods by 6\%. Code is availabel at \href{https://github.com/JoyeZLearning/DiffDet4SAR}.
Future-Proofing Class Incremental Learning
Apr 04, 2024Exemplar-Free Class Incremental Learning is a highly challenging setting where replay memory is unavailable. Methods relying on frozen feature extractors have drawn attention recently in this setting due to their impressive performances and lower computational costs. However, those methods are highly dependent on the data used to train the feature extractor and may struggle when an insufficient amount of classes are available during the first incremental step. To overcome this limitation, we propose to use a pre-trained text-to-image diffusion model in order to generate synthetic images of future classes and use them to train the feature extractor. Experiments on the standard benchmarks CIFAR100 and ImageNet-Subset demonstrate that our proposed method can be used to improve state-of-the-art methods for exemplar-free class incremental learning, especially in the most difficult settings where the first incremental step only contains few classes. Moreover, we show that using synthetic samples of future classes achieves higher performance than using real data from different classes, paving the way for better and less costly pre-training methods for incremental learning.
AGL-NET: Aerial-Ground Cross-Modal Global Localization with Varying Scales
Apr 04, 2024We present AGL-NET, a novel learning-based method for global localization using LiDAR point clouds and satellite maps. AGL-NET tackles two critical challenges: bridging the representation gap between image and points modalities for robust feature matching, and handling inherent scale discrepancies between global view and local view. To address these challenges, AGL-NET leverages a unified network architecture with a novel two-stage matching design. The first stage extracts informative neural features directly from raw sensor data and performs initial feature matching. The second stage refines this matching process by extracting informative skeleton features and incorporating a novel scale alignment step to rectify scale variations between LiDAR and map data. Furthermore, a novel scale and skeleton loss function guides the network toward learning scale-invariant feature representations, eliminating the need for pre-processing satellite maps. This significantly improves real-world applicability in scenarios with unknown map scales. To facilitate rigorous performance evaluation, we introduce a meticulously designed dataset within the CARLA simulator specifically tailored for metric localization training and assessment. The code and dataset will be made publicly available.