 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Domain Generalization for Medical Image Analysis: A Survey
Oct 05, 2023
Medical Image Analysis (MedIA) has become an essential tool in medicine and healthcare, aiding in disease diagnosis, prognosis, and treatment planning, and recent successes in deep learning (DL) have made significant contributions to its advances. However, DL models for MedIA remain challenging to deploy in real-world situations, failing for generalization under the distributional gap between training and testing samples, known as a distribution shift problem. Researchers have dedicated their efforts to developing various DL methods to adapt and perform robustly on unknown and out-of-distribution data distributions. This paper comprehensively reviews domain generalization studies specifically tailored for MedIA. We provide a holistic view of how domain generalization techniques interact within the broader MedIA system, going beyond methodologies to consider the operational implications on the entire MedIA workflow. Specifically, we categorize domain generalization methods into data-level, feature-level, model-level, and analysis-level methods. We show how those methods can be used in various stages of the MedIA workflow with DL equipped from data acquisition to model prediction and analysis. Furthermore, we include benchmark datasets and applications used to evaluate these approaches and analyze the strengths and weaknesses of various methods, unveiling future research opportunities.
Diffusion Reconstruction of Ultrasound Images with Informative Uncertainty
Oct 31, 2023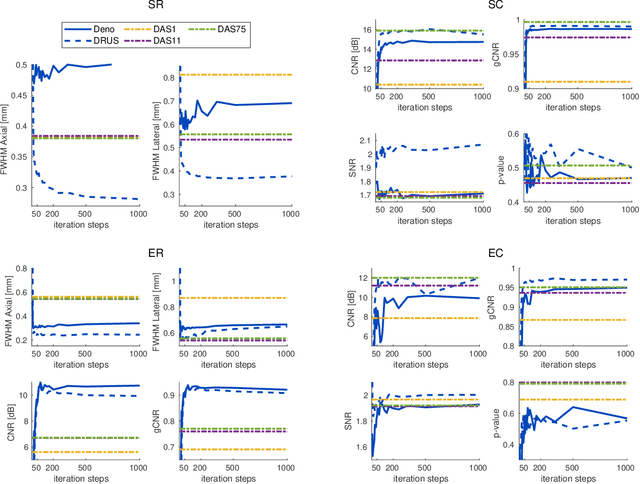
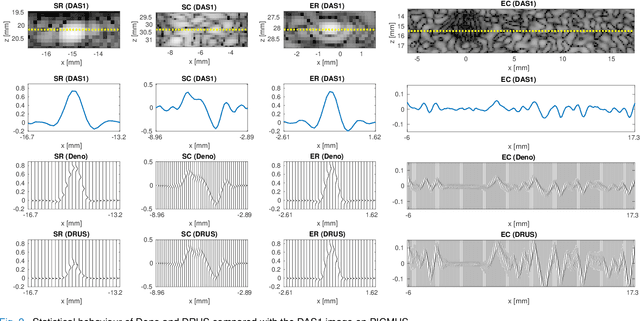
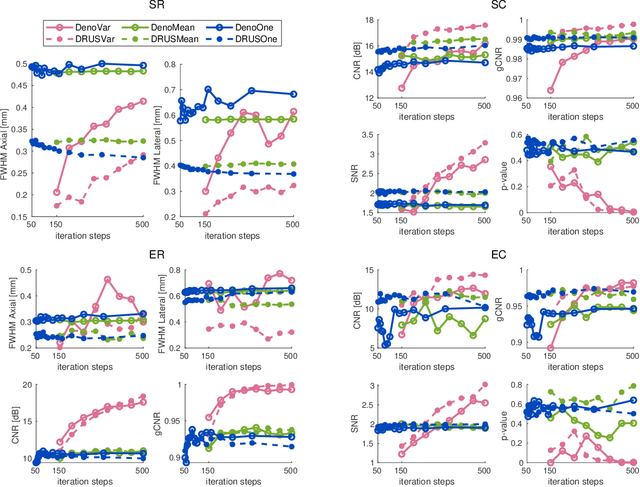
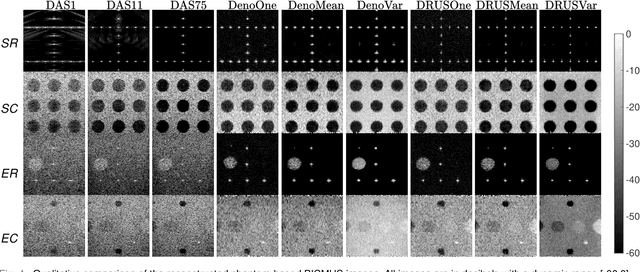
Despite its wide use in medicine, ultrasound imaging faces several challenges related to its poor signal-to-noise ratio and several sources of noise and artefacts. Enhancing ultrasound image quality involves balancing concurrent factors like contrast, resolution, and speckle preservation. In recent years, there has been progress both in model-based and learning-based approaches to improve ultrasound image reconstruction. Bringing the best from both worlds, we propose a hybrid approach leveraging advances in diffusion models. To this end, we adapt Denoising Diffusion Restoration Models (DDRM) to incorporate ultrasound physics through a linear direct model and an unsupervised fine-tuning of the prior diffusion model. We conduct comprehensive experiments on simulated, in-vitro, and in-vivo data, demonstrating the efficacy of our approach in achieving high-quality image reconstructions from a single plane wave input and in comparison to state-of-the-art methods. Finally, given the stochastic nature of the method, we analyse in depth the statistical properties of single and multiple-sample reconstructions, experimentally show the informativeness of their variance, and provide an empirical model relating this behaviour to speckle noise. The code and data are available at: (upon acceptance).
The Development of LLMs for Embodied Navigation
Nov 10, 2023In recent years, the rapid advancement of Large Language Models (LLMs) such as the Generative Pre-trained Transformer (GPT) has attracted increasing attention due to their potential in a variety of practical applications. The application of LLMs with Embodied Intelligence has emerged as a significant area of focus. Among the myriad applications of LLMs, navigation tasks are particularly noteworthy because they demand a deep understanding of the environment and quick, accurate decision-making. LLMs can augment embodied intelligence systems with sophisticated environmental perception and decision-making support, leveraging their robust language and image-processing capabilities. This article offers an exhaustive summary of the symbiosis between LLMs and embodied intelligence with a focus on navigation. It reviews state-of-the-art models, research methodologies, and assesses the advantages and disadvantages of existing embodied navigation models and datasets. Finally, the article elucidates the role of LLMs in embodied intelligence, based on current research, and forecasts future directions in the field. A comprehensive list of studies in this survey is available at https://github.com/Rongtao-Xu/Awesome-LLM-EN
Instant3D: Fast Text-to-3D with Sparse-View Generation and Large Reconstruction Model
Nov 10, 2023

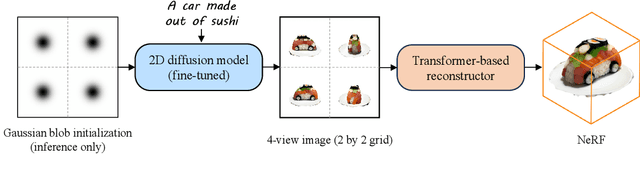
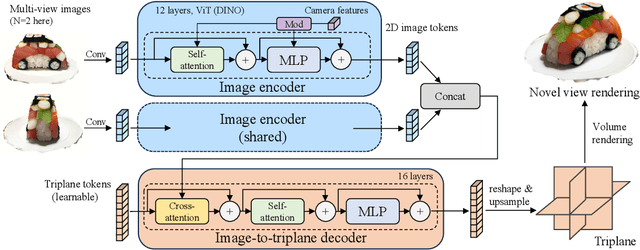
Text-to-3D with diffusion models have achieved remarkable progress in recent years. However, existing methods either rely on score distillation-based optimization which suffer from slow inference, low diversity and Janus problems, or are feed-forward methods that generate low quality results due to the scarcity of 3D training data. In this paper, we propose Instant3D, a novel method that generates high-quality and diverse 3D assets from text prompts in a feed-forward manner. We adopt a two-stage paradigm, which first generates a sparse set of four structured and consistent views from text in one shot with a fine-tuned 2D text-to-image diffusion model, and then directly regresses the NeRF from the generated images with a novel transformer-based sparse-view reconstructor. Through extensive experiments, we demonstrate that our method can generate high-quality, diverse and Janus-free 3D assets within 20 seconds, which is two order of magnitude faster than previous optimization-based methods that can take 1 to 10 hours. Our project webpage: https://jiahao.ai/instant3d/.
TacIPC: Intersection- and Inversion-free FEM-based Elastomer Simulation For Optical Tactile Sensors
Nov 10, 2023Tactile perception stands as a critical sensory modality for human interaction with the environment. Among various tactile sensor techniques, optical sensor-based approaches have gained traction, notably for producing high-resolution tactile images. This work explores gel elastomer deformation simulation through a physics-based approach. While previous works in this direction usually adopt the explicit material point method (MPM), which has certain limitations in force simulation and rendering, we adopt the finite element method (FEM) and address the challenges in penetration and mesh distortion with incremental potential contact (IPC) method. As a result, we present a simulator named TacIPC, which can ensure numerically stable simulations while accommodating direct rendering and friction modeling. To evaluate TacIPC, we conduct three tasks: pseudo-image quality assessment, deformed geometry estimation, and marker displacement prediction. These tasks show its superior efficacy in reducing the sim-to-real gap. Our method can also seamlessly integrate with existing simulators. More experiments and videos can be found in the supplementary materials and on the website: https://sites.google.com/view/tac-ipc.
Parameter-Efficient Orthogonal Finetuning via Butterfly Factorization
Nov 10, 2023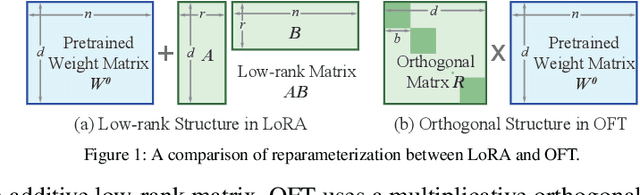
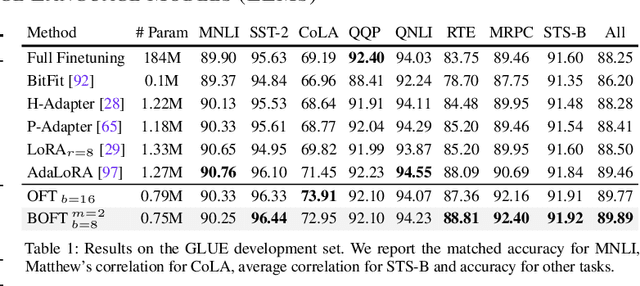
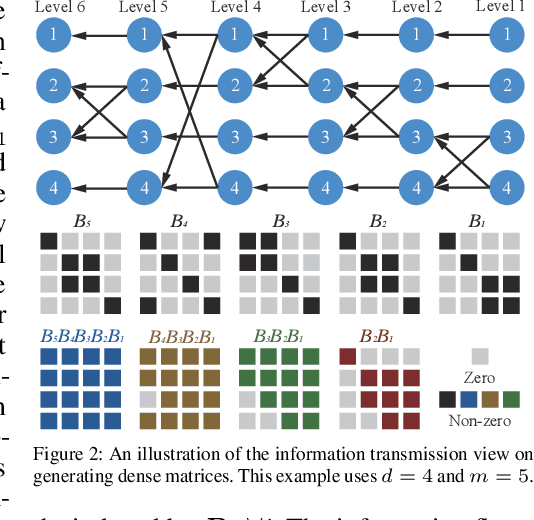
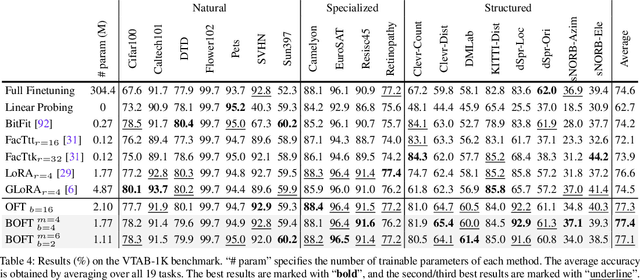
Large foundation models are becoming ubiquitous, but training them from scratch is prohibitively expensive. Thus, efficiently adapting these powerful models to downstream tasks is increasingly important. In this paper, we study a principled finetuning paradigm -- Orthogonal Finetuning (OFT) -- for downstream task adaptation. Despite demonstrating good generalizability, OFT still uses a fairly large number of trainable parameters due to the high dimensionality of orthogonal matrices. To address this, we start by examining OFT from an information transmission perspective, and then identify a few key desiderata that enable better parameter-efficiency. Inspired by how the Cooley-Tukey fast Fourier transform algorithm enables efficient information transmission, we propose an efficient orthogonal parameterization using butterfly structures. We apply this parameterization to OFT, creating a novel parameter-efficient finetuning method, called Orthogonal Butterfly (BOFT). By subsuming OFT as a special case, BOFT introduces a generalized orthogonal finetuning framework. Finally, we conduct an extensive empirical study of adapting large vision transformers, large language models, and text-to-image diffusion models to various downstream tasks in vision and language.
Florence-2: Advancing a Unified Representation for a Variety of Vision Tasks
Nov 10, 2023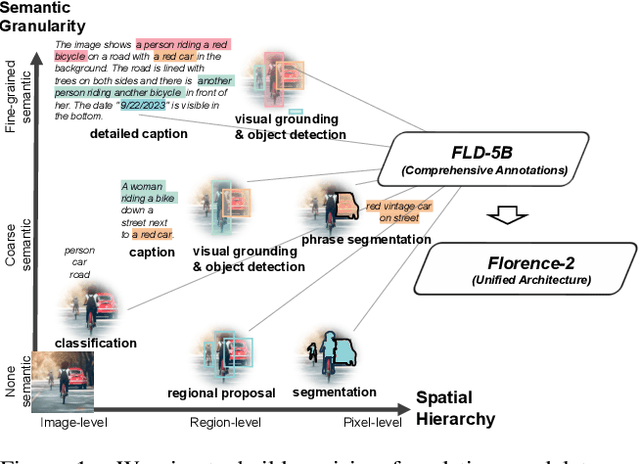
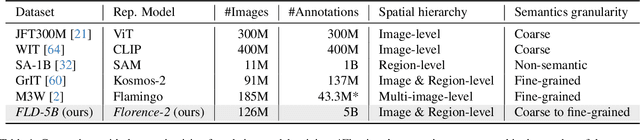
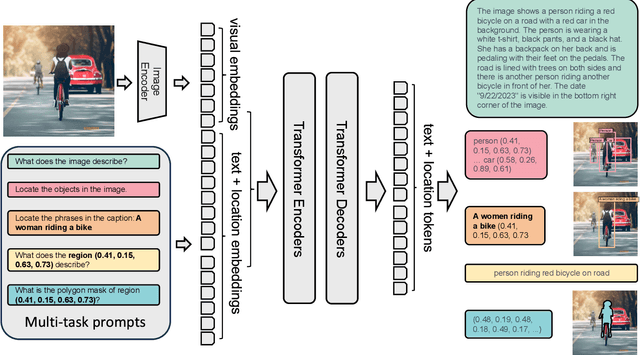
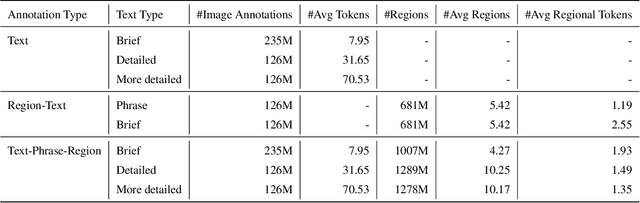
We introduce Florence-2, a novel vision foundation model with a unified, prompt-based representation for a variety of computer vision and vision-language tasks. While existing large vision models excel in transfer learning, they struggle to perform a diversity of tasks with simple instructions, a capability that implies handling the complexity of various spatial hierarchy and semantic granularity. Florence-2 was designed to take text-prompt as task instructions and generate desirable results in text forms, whether it be captioning, object detection, grounding or segmentation. This multi-task learning setup demands large-scale, high-quality annotated data. To this end, we co-developed FLD-5B that consists of 5.4 billion comprehensive visual annotations on 126 million images, using an iterative strategy of automated image annotation and model refinement. We adopted a sequence-to-sequence structure to train Florence-2 to perform versatile and comprehensive vision tasks. Extensive evaluations on numerous tasks demonstrated Florence-2 to be a strong vision foundation model contender with unprecedented zero-shot and fine-tuning capabilities.
TILFA: A Unified Framework for Text, Image, and Layout Fusion in Argument Mining
Oct 08, 2023A main goal of Argument Mining (AM) is to analyze an author's stance. Unlike previous AM datasets focusing only on text, the shared task at the 10th Workshop on Argument Mining introduces a dataset including both text and images. Importantly, these images contain both visual elements and optical characters. Our new framework, TILFA (A Unified Framework for Text, Image, and Layout Fusion in Argument Mining), is designed to handle this mixed data. It excels at not only understanding text but also detecting optical characters and recognizing layout details in images. Our model significantly outperforms existing baselines, earning our team, KnowComp, the 1st place in the leaderboard of Argumentative Stance Classification subtask in this shared task.
All-optical image denoising using a diffractive visual processor
Sep 17, 2023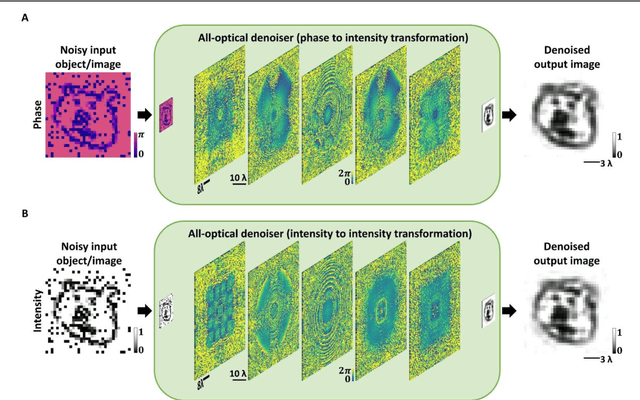
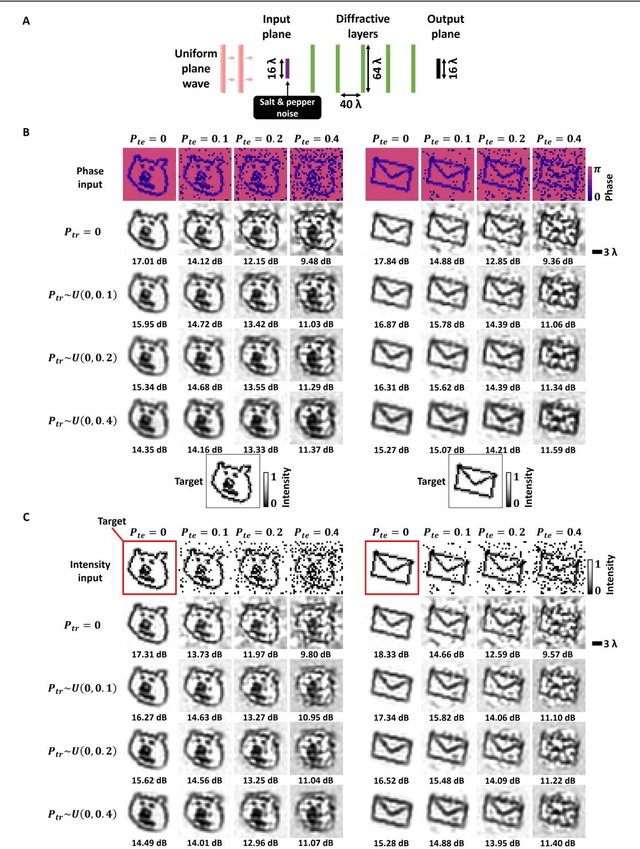
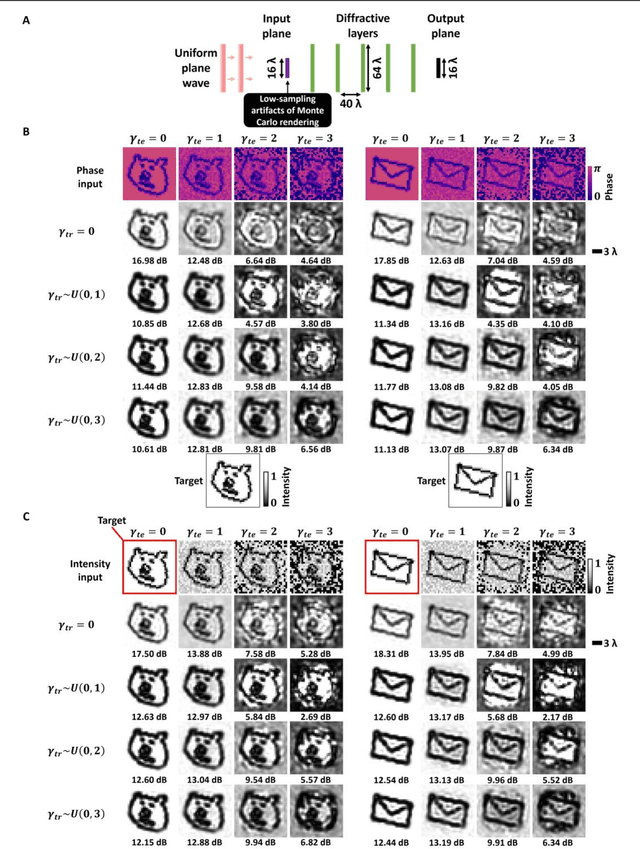
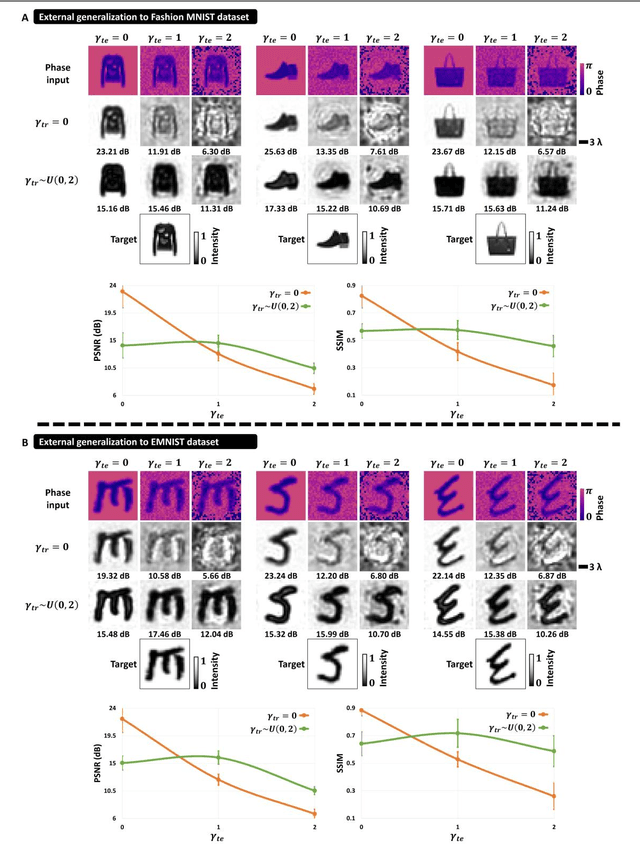
Image denoising, one of the essential inverse problems, targets to remove noise/artifacts from input images. In general, digital image denoising algorithms, executed on computers, present latency due to several iterations implemented in, e.g., graphics processing units (GPUs). While deep learning-enabled methods can operate non-iteratively, they also introduce latency and impose a significant computational burden, leading to increased power consumption. Here, we introduce an analog diffractive image denoiser to all-optically and non-iteratively clean various forms of noise and artifacts from input images - implemented at the speed of light propagation within a thin diffractive visual processor. This all-optical image denoiser comprises passive transmissive layers optimized using deep learning to physically scatter the optical modes that represent various noise features, causing them to miss the output image Field-of-View (FoV) while retaining the object features of interest. Our results show that these diffractive denoisers can efficiently remove salt and pepper noise and image rendering-related spatial artifacts from input phase or intensity images while achieving an output power efficiency of ~30-40%. We experimentally demonstrated the effectiveness of this analog denoiser architecture using a 3D-printed diffractive visual processor operating at the terahertz spectrum. Owing to their speed, power-efficiency, and minimal computational overhead, all-optical diffractive denoisers can be transformative for various image display and projection systems, including, e.g., holographic displays.
GCS-ICHNet: Assessment of Intracerebral Hemorrhage Prognosis using Self-Attention with Domain Knowledge Integration
Nov 08, 2023Intracerebral Hemorrhage (ICH) is a severe condition resulting from damaged brain blood vessel ruptures, often leading to complications and fatalities. Timely and accurate prognosis and management are essential due to its high mortality rate. However, conventional methods heavily rely on subjective clinician expertise, which can lead to inaccurate diagnoses and delays in treatment. Artificial intelligence (AI) models have been explored to assist clinicians, but many prior studies focused on model modification without considering domain knowledge. This paper introduces a novel deep learning algorithm, GCS-ICHNet, which integrates multimodal brain CT image data and the Glasgow Coma Scale (GCS) score to improve ICH prognosis. The algorithm utilizes a transformer-based fusion module for assessment. GCS-ICHNet demonstrates high sensitivity 81.03% and specificity 91.59%, outperforming average clinicians and other state-of-the-art methods.