 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
An evaluation of pre-trained models for feature extraction in image classification
Oct 03, 2023
In recent years, we have witnessed a considerable increase in performance in image classification tasks. This performance improvement is mainly due to the adoption of deep learning techniques. Generally, deep learning techniques demand a large set of annotated data, making it a challenge when applying it to small datasets. In this scenario, transfer learning strategies have become a promising alternative to overcome these issues. This work aims to compare the performance of different pre-trained neural networks for feature extraction in image classification tasks. We evaluated 16 different pre-trained models in four image datasets. Our results demonstrate that the best general performance along the datasets was achieved by CLIP-ViT-B and ViT-H-14, where the CLIP-ResNet50 model had similar performance but with less variability. Therefore, our study provides evidence supporting the choice of models for feature extraction in image classification tasks.
HeightFormer: A Multilevel Interaction and Image-adaptive Classification-regression Network for Monocular Height Estimation with Aerial Images
Oct 12, 2023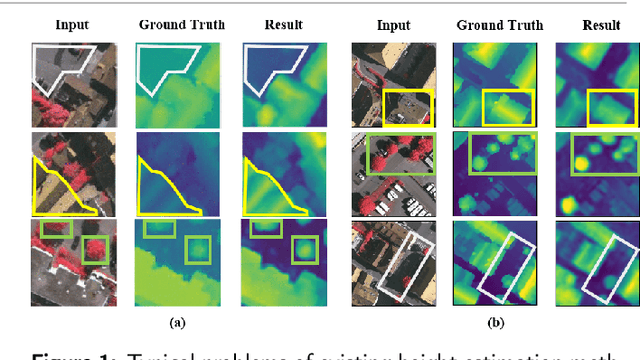
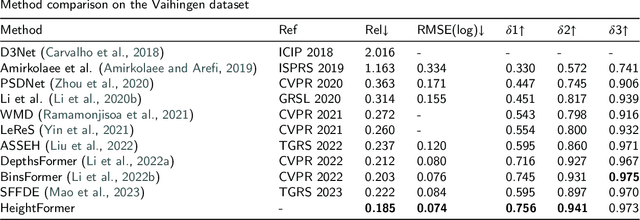
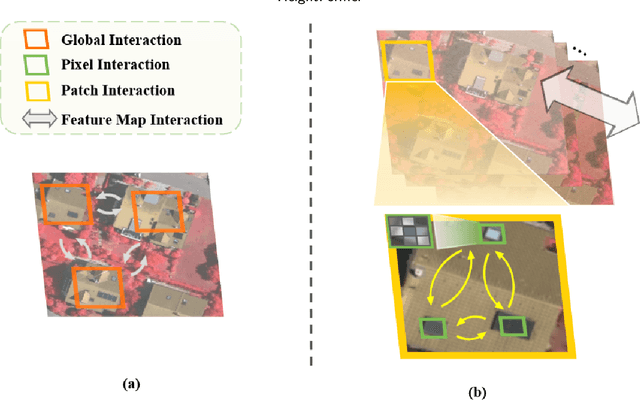

Height estimation has long been a pivotal topic within measurement and remote sensing disciplines, proving critical for endeavours such as 3D urban modelling, MR and autonomous driving. Traditional methods utilise stereo matching or multisensor fusion, both well-established techniques that typically necessitate multiple images from varying perspectives and adjunct sensors like SAR, leading to substantial deployment costs. Single image height estimation has emerged as an attractive alternative, boasting a larger data source variety and simpler deployment. However, current methods suffer from limitations such as fixed receptive fields, a lack of global information interaction, leading to noticeable instance-level height deviations. The inherent complexity of height prediction can result in a blurry estimation of object edge depth when using mainstream regression methods based on fixed height division. This paper presents a comprehensive solution for monocular height estimation in remote sensing, termed HeightFormer, combining multilevel interactions and image-adaptive classification-regression. It features the Multilevel Interaction Backbone (MIB) and Image-adaptive Classification-regression Height Generator (ICG). MIB supplements the fixed sample grid in CNN of the conventional backbone network with tokens of different interaction ranges. It is complemented by a pixel-, patch-, and feature map-level hierarchical interaction mechanism, designed to relay spatial geometry information across different scales and introducing a global receptive field to enhance the quality of instance-level height estimation. The ICG dynamically generates height partition for each image and reframes the traditional regression task, using a refinement from coarse to fine classification-regression that significantly mitigates the innate ill-posedness issue and drastically improves edge sharpness.
Expanding Scene Graph Boundaries: Fully Open-vocabulary Scene Graph Generation via Visual-Concept Alignment and Retention
Nov 18, 2023Scene Graph Generation (SGG) offers a structured representation critical in many computer vision applications. Traditional SGG approaches, however, are limited by a closed-set assumption, restricting their ability to recognize only predefined object and relation categories. To overcome this, we categorize SGG scenarios into four distinct settings based on the node and edge: Closed-set SGG, Open Vocabulary (object) Detection-based SGG (OvD-SGG), Open Vocabulary Relation-based SGG (OvR-SGG), and Open Vocabulary Detection + Relation-based SGG (OvD+R-SGG). While object-centric open vocabulary SGG has been studied recently, the more challenging problem of relation-involved open-vocabulary SGG remains relatively unexplored. To fill this gap, we propose a unified framework named OvSGTR towards fully open vocabulary SGG from a holistic view. The proposed framework is an end-toend transformer architecture, which learns a visual-concept alignment for both nodes and edges, enabling the model to recognize unseen categories. For the more challenging settings of relation-involved open vocabulary SGG, the proposed approach integrates relation-aware pre-training utilizing image-caption data and retains visual-concept alignment through knowledge distillation. Comprehensive experimental results on the Visual Genome benchmark demonstrate the effectiveness and superiority of the proposed framework.
Auxiliary Losses for Learning Generalizable Concept-based Models
Nov 18, 2023The increasing use of neural networks in various applications has lead to increasing apprehensions, underscoring the necessity to understand their operations beyond mere final predictions. As a solution to enhance model transparency, Concept Bottleneck Models (CBMs) have gained popularity since their introduction. CBMs essentially limit the latent space of a model to human-understandable high-level concepts. While beneficial, CBMs have been reported to often learn irrelevant concept representations that consecutively damage model performance. To overcome the performance trade-off, we propose cooperative-Concept Bottleneck Model (coop-CBM). The concept representation of our model is particularly meaningful when fine-grained concept labels are absent. Furthermore, we introduce the concept orthogonal loss (COL) to encourage the separation between the concept representations and to reduce the intra-concept distance. This paper presents extensive experiments on real-world datasets for image classification tasks, namely CUB, AwA2, CelebA and TIL. We also study the performance of coop-CBM models under various distributional shift settings. We show that our proposed method achieves higher accuracy in all distributional shift settings even compared to the black-box models with the highest concept accuracy.
Enhancing Recommender System Performance by Histogram Equalization
Nov 15, 2023Recommender system has been researched for decades with millions of different versions of algorithms created in the industry. In spite of the huge amount of work spent on the field, there are many basic questions to be answered in the field. The most fundamental question to be answered is the accuracy problem, and in recent years, fairness becomes the new buzz word for researchers. In this paper, we borrow an idea from image processing, namely, histogram equalization. As a preprocessing step to recommender system algorithms, histogram equalization could enhance both the accuracy and fairness metrics of the recommender system algorithms. In the experiment section, we prove that our new approach could improve vanilla algorithms by a large margin in accuracy metric and stay competitive on fairness metrics.
A method for quantifying sectoral optic disc pallor in fundus photographs and its association with peripapillary RNFL thickness
Nov 13, 2023Purpose: To develop an automatic method of quantifying optic disc pallor in fundus photographs and determine associations with peripapillary retinal nerve fibre layer (pRNFL) thickness. Methods: We used deep learning to segment the optic disc, fovea, and vessels in fundus photographs, and measured pallor. We assessed the relationship between pallor and pRNFL thickness derived from optical coherence tomography scans in 118 participants. Separately, we used images diagnosed by clinical inspection as pale (N=45) and assessed how measurements compared to healthy controls (N=46). We also developed automatic rejection thresholds, and tested the software for robustness to camera type, image format, and resolution. Results: We developed software that automatically quantified disc pallor across several zones in fundus photographs. Pallor was associated with pRNFL thickness globally (\b{eta} = -9.81 (SE = 3.16), p < 0.05), in the temporal inferior zone (\b{eta} = -29.78 (SE = 8.32), p < 0.01), with the nasal/temporal ratio (\b{eta} = 0.88 (SE = 0.34), p < 0.05), and in the whole disc (\b{eta} = -8.22 (SE = 2.92), p < 0.05). Furthermore, pallor was significantly higher in the patient group. Lastly, we demonstrate the analysis to be robust to camera type, image format, and resolution. Conclusions: We developed software that automatically locates and quantifies disc pallor in fundus photographs and found associations between pallor measurements and pRNFL thickness. Translational relevance: We think our method will be useful for the identification, monitoring and progression of diseases characterized by disc pallor/optic atrophy, including glaucoma, compression, and potentially in neurodegenerative disorders.
A Hybrid Joint Source-Channel Coding Scheme for Mobile Multi-hop Networks
Nov 13, 2023We propose a novel hybrid joint source-channel coding (JSCC) scheme for robust image transmission over multi-hop networks. In the considered scenario, a mobile user wants to deliver an image to its destination over a mobile cellular network. We assume a practical setting, where the links between the nodes belonging to the mobile core network are stable and of high quality, while the link between the mobile user and the first node (e.g., the access point) is potentially time-varying with poorer quality. In recent years, neural network based JSCC schemes (called DeepJSCC) have emerged as promising solutions to overcome the limitations of separation-based fully digital schemes. However, relying on analog transmission, DeepJSCC suffers from noise accumulation over multi-hop networks. Moreover, most of the hops within the mobile core network may be high-capacity wireless connections, calling for digital approaches. To this end, we propose a hybrid solution, where DeepJSCC is adopted for the first hop, while the received signal at the first relay is digitally compressed and forwarded through the mobile core network. We show through numerical simulations that the proposed scheme is able to outperform both the fully analog and fully digital schemes. Thanks to DeepJSCC it can avoid the cliff effect over the first hop, while also avoiding noise forwarding over the mobile core network thank to digital transmission. We believe this work paves the way for the practical deployment of DeepJSCC solutions in 6G and future wireless networks.
Learning Robust Multi-Scale Representation for Neural Radiance Fields from Unposed Images
Nov 08, 2023We introduce an improved solution to the neural image-based rendering problem in computer vision. Given a set of images taken from a freely moving camera at train time, the proposed approach could synthesize a realistic image of the scene from a novel viewpoint at test time. The key ideas presented in this paper are (i) Recovering accurate camera parameters via a robust pipeline from unposed day-to-day images is equally crucial in neural novel view synthesis problem; (ii) It is rather more practical to model object's content at different resolutions since dramatic camera motion is highly likely in day-to-day unposed images. To incorporate the key ideas, we leverage the fundamentals of scene rigidity, multi-scale neural scene representation, and single-image depth prediction. Concretely, the proposed approach makes the camera parameters as learnable in a neural fields-based modeling framework. By assuming per view depth prediction is given up to scale, we constrain the relative pose between successive frames. From the relative poses, absolute camera pose estimation is modeled via a graph-neural network-based multiple motion averaging within the multi-scale neural-fields network, leading to a single loss function. Optimizing the introduced loss function provides camera intrinsic, extrinsic, and image rendering from unposed images. We demonstrate, with examples, that for a unified framework to accurately model multiscale neural scene representation from day-to-day acquired unposed multi-view images, it is equally essential to have precise camera-pose estimates within the scene representation framework. Without considering robustness measures in the camera pose estimation pipeline, modeling for multi-scale aliasing artifacts can be counterproductive. We present extensive experiments on several benchmark datasets to demonstrate the suitability of our approach.
Comparing Humans, GPT-4, and GPT-4V On Abstraction and Reasoning Tasks
Nov 14, 2023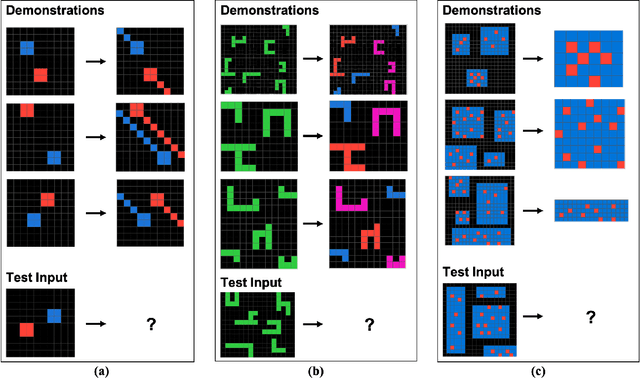
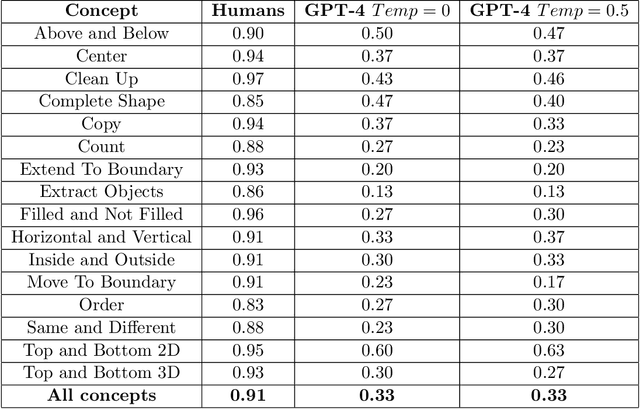

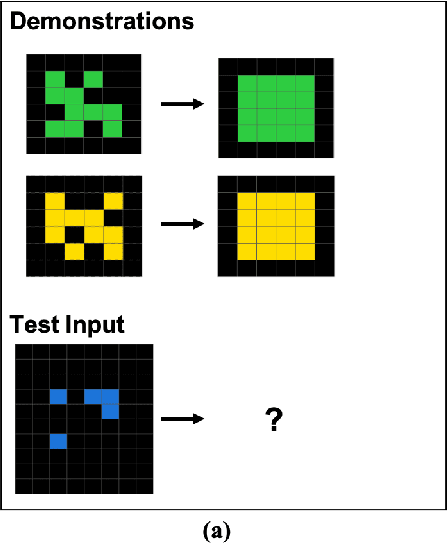
We explore the abstract reasoning abilities of text-only and multimodal versions of GPT-4, using the ConceptARC benchmark [10], which is designed to evaluate robust understanding and reasoning with core-knowledge concepts. We extend the work of Moskvichev et al. [10] by evaluating GPT-4 on more detailed, one-shot prompting (rather than simple, zero-shot prompts) with text versions of ConceptARC tasks, and by evaluating GPT-4V, the multimodal version of GPT-4, on zero- and one-shot prompts using image versions of the simplest tasks. Our experimental results support the conclusion that neither version of GPT-4 has developed robust abstraction abilities at humanlike levels.
Comparative Multi-View Language Grounding
Nov 14, 2023In this work, we consider the task of resolving object referents when given a comparative language description. We present a Multi-view Approach to Grounding in Context (MAGiC) that leverages transformers to pragmatically reason over both objects given multiple image views and a language description. In contrast to past efforts that attempt to connect vision and language for this task without fully considering the resulting referential context, MAGiC makes use of the comparative information by jointly reasoning over multiple views of both object referent candidates and the referring language expression. We present an analysis demonstrating that comparative reasoning contributes to SOTA performance on the SNARE object reference task.