 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Factorized Diffusion Architectures for Unsupervised Image Generation and Segmentation
Sep 27, 2023
We develop a neural network architecture which, trained in an unsupervised manner as a denoising diffusion model, simultaneously learns to both generate and segment images. Learning is driven entirely by the denoising diffusion objective, without any annotation or prior knowledge about regions during training. A computational bottleneck, built into the neural architecture, encourages the denoising network to partition an input into regions, denoise them in parallel, and combine the results. Our trained model generates both synthetic images and, by simple examination of its internal predicted partitions, a semantic segmentation of those images. Without any finetuning, we directly apply our unsupervised model to the downstream task of segmenting real images via noising and subsequently denoising them. Experiments demonstrate that our model achieves accurate unsupervised image segmentation and high-quality synthetic image generation across multiple datasets.
Text-to-Image Generation for Abstract Concepts
Sep 27, 2023Recent years have witnessed the substantial progress of large-scale models across various domains, such as natural language processing and computer vision, facilitating the expression of concrete concepts. Unlike concrete concepts that are usually directly associated with physical objects, expressing abstract concepts through natural language requires considerable effort, which results from their intricate semantics and connotations. An alternative approach is to leverage images to convey rich visual information as a supplement. Nevertheless, existing Text-to-Image (T2I) models are primarily trained on concrete physical objects and tend to fail to visualize abstract concepts. Inspired by the three-layer artwork theory that identifies critical factors, intent, object and form during artistic creation, we propose a framework of Text-to-Image generation for Abstract Concepts (TIAC). The abstract concept is clarified into a clear intent with a detailed definition to avoid ambiguity. LLMs then transform it into semantic-related physical objects, and the concept-dependent form is retrieved from an LLM-extracted form pattern set. Information from these three aspects will be integrated to generate prompts for T2I models via LLM. Evaluation results from human assessments and our newly designed metric concept score demonstrate the effectiveness of our framework in creating images that can sufficiently express abstract concepts.
TextCLIP: Text-Guided Face Image Generation And Manipulation Without Adversarial Training
Sep 21, 2023


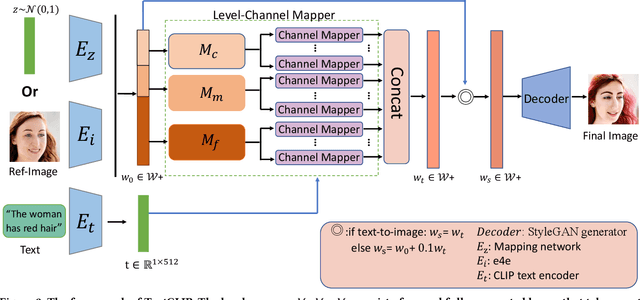
Text-guided image generation aimed to generate desired images conditioned on given texts, while text-guided image manipulation refers to semantically edit parts of a given image based on specified texts. For these two similar tasks, the key point is to ensure image fidelity as well as semantic consistency. Many previous approaches require complex multi-stage generation and adversarial training, while struggling to provide a unified framework for both tasks. In this work, we propose TextCLIP, a unified framework for text-guided image generation and manipulation without adversarial training. The proposed method accepts input from images or random noise corresponding to these two different tasks, and under the condition of the specific texts, a carefully designed mapping network that exploits the powerful generative capabilities of StyleGAN and the text image representation capabilities of Contrastive Language-Image Pre-training (CLIP) generates images of up to $1024\times1024$ resolution that can currently be generated. Extensive experiments on the Multi-modal CelebA-HQ dataset have demonstrated that our proposed method outperforms existing state-of-the-art methods, both on text-guided generation tasks and manipulation tasks.
Exploring Grounding Potential of VQA-oriented GPT-4V for Zero-shot Anomaly Detection
Nov 05, 2023Large Multimodal Model (LMM) GPT-4V(ision) endows GPT-4 with visual grounding capabilities, making it possible to handle certain tasks through the Visual Question Answering (VQA) paradigm. This paper explores the potential of VQA-oriented GPT-4V in the recently popular visual Anomaly Detection (AD) and is the first to conduct qualitative and quantitative evaluations on the popular MVTec AD and VisA datasets. Considering that this task requires both image-/pixel-level evaluations, the proposed GPT-4V-AD framework contains three components: 1) Granular Region Division, 2) Prompt Designing, 3) Text2Segmentation for easy quantitative evaluation, and have made some different attempts for comparative analysis. The results show that GPT-4V can achieve certain results in the zero-shot AD task through a VQA paradigm, such as achieving image-level 77.1/88.0 and pixel-level 68.0/76.6 AU-ROCs on MVTec AD and VisA datasets, respectively. However, its performance still has a certain gap compared to the state-of-the-art zero-shot method, e.g., WinCLIP ann CLIP-AD, and further research is needed. This study provides a baseline reference for the research of VQA-oriented LMM in the zero-shot AD task, and we also post several possible future works. Code is available at \url{https://github.com/zhangzjn/GPT-4V-AD}.
Wavelet-based Topological Loss for Low-Light Image Denoising
Sep 20, 2023Despite extensive research conducted in the field of image denoising, many algorithms still heavily depend on supervised learning and their effectiveness primarily relies on the quality and diversity of training data. It is widely assumed that digital image distortions are caused by spatially invariant Additive White Gaussian Noise (AWGN). However, the analysis of real-world data suggests that this assumption is invalid. Therefore, this paper tackles image corruption by real noise, providing a framework to capture and utilise the underlying structural information of an image along with the spatial information conventionally used for deep learning tasks. We propose a novel denoising loss function that incorporates topological invariants and is informed by textural information extracted from the image wavelet domain. The effectiveness of this proposed method was evaluated by training state-of-the-art denoising models on the BVI-Lowlight dataset, which features a wide range of real noise distortions. Adding a topological term to common loss functions leads to a significant increase in the LPIPS (Learned Perceptual Image Patch Similarity) metric, with the improvement reaching up to 25\%. The results indicate that the proposed loss function enables neural networks to learn noise characteristics better. We demonstrate that they can consequently extract the topological features of noise-free images, resulting in enhanced contrast and preserved textural information.
Ziya-Visual: Bilingual Large Vision-Language Model via Multi-Task Instruction Tuning
Oct 29, 2023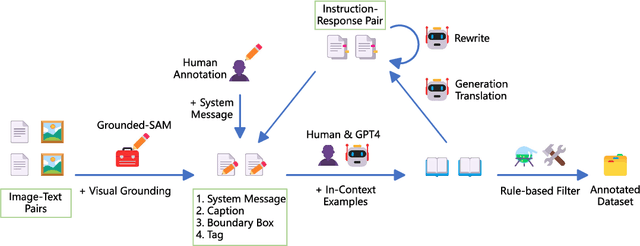
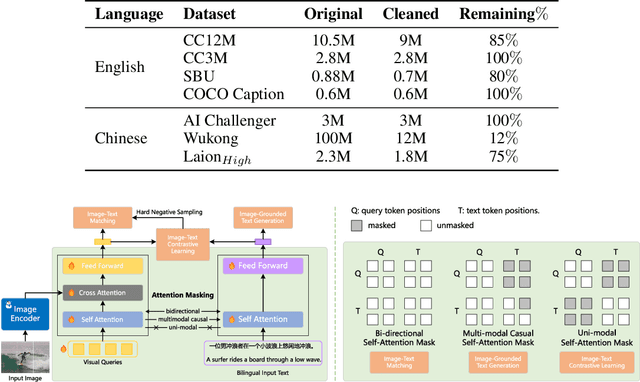
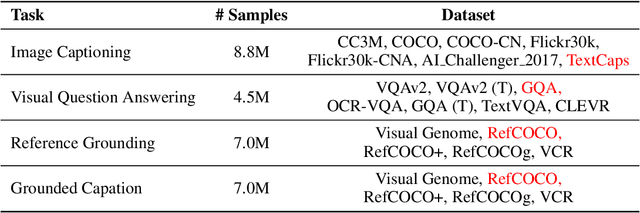
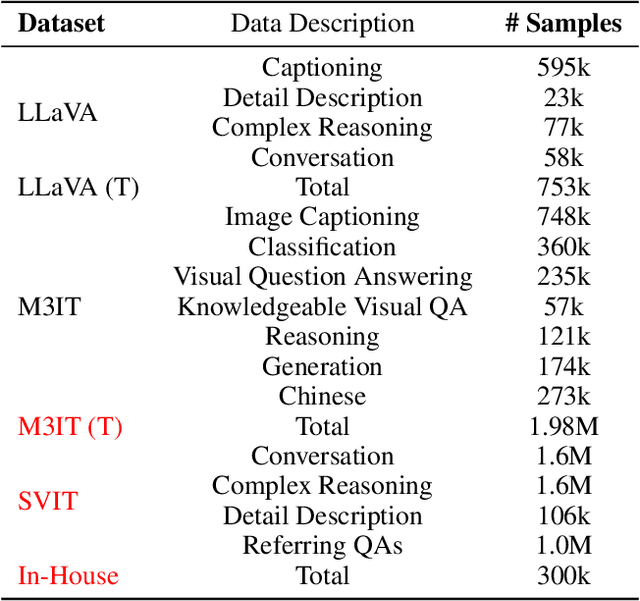
Recent advancements enlarge the capabilities of large language models (LLMs) in zero-shot image-to-text generation and understanding by integrating multi-modal inputs. However, such success is typically limited to English scenarios due to the lack of large-scale and high-quality non-English multi-modal resources, making it extremely difficult to establish competitive counterparts in other languages. In this paper, we introduce the Ziya-Visual series, a set of bilingual large-scale vision-language models (LVLMs) designed to incorporate visual semantics into LLM for multi-modal dialogue. Composed of Ziya-Visual-Base and Ziya-Visual-Chat, our models adopt the Querying Transformer from BLIP-2, further exploring the assistance of optimization schemes such as instruction tuning, multi-stage training and low-rank adaptation module for visual-language alignment. In addition, we stimulate the understanding ability of GPT-4 in multi-modal scenarios, translating our gathered English image-text datasets into Chinese and generating instruction-response through the in-context learning method. The experiment results demonstrate that compared to the existing LVLMs, Ziya-Visual achieves competitive performance across a wide range of English-only tasks including zero-shot image-text retrieval, image captioning, and visual question answering. The evaluation leaderboard accessed by GPT-4 also indicates that our models possess satisfactory image-text understanding and generation capabilities in Chinese multi-modal scenario dialogues. Code, demo and models are available at ~\url{https://huggingface.co/IDEA-CCNL/Ziya-BLIP2-14B-Visual-v1}.
Strategies and impact of learning curve estimation for CNN-based image classification
Oct 12, 2023Learning curves are a measure for how the performance of machine learning models improves given a certain volume of training data. Over a wide variety of applications and models it was observed that learning curves follow -- to a large extent -- a power law behavior. This makes the performance of different models for a given task somewhat predictable and opens the opportunity to reduce the training time for practitioners, who are exploring the space of possible models and hyperparameters for the problem at hand. By estimating the learning curve of a model from training on small subsets of data only the best models need to be considered for training on the full dataset. How to choose subset sizes and how often to sample models on these to obtain estimates is however not researched. Given that the goal is to reduce overall training time strategies are needed that sample the performance in a time-efficient way and yet leads to accurate learning curve estimates. In this paper we formulate the framework for these strategies and propose several strategies. Further we evaluate the strategies for simulated learning curves and in experiments with popular datasets and models for image classification tasks.
PET Tracer Conversion among Brain PET via Variable Augmented Invertible Network
Nov 01, 2023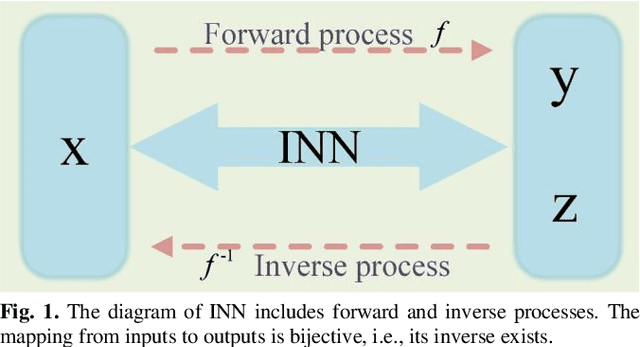
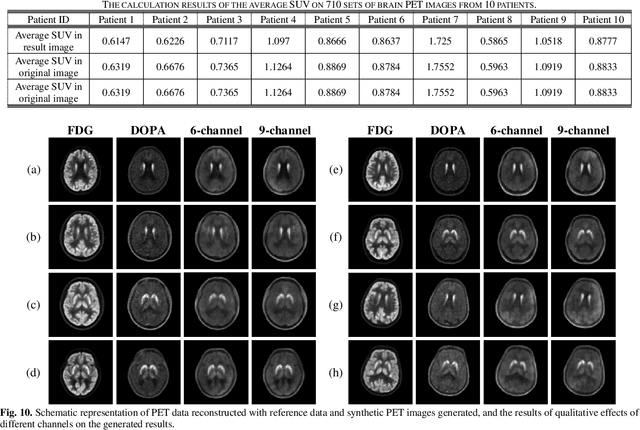
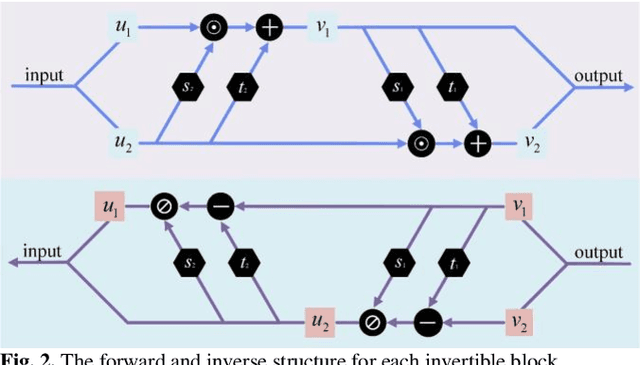
Positron emission tomography (PET), as an imaging technique with high biochemical sensitivity, has been widely used in diagnosis of encephalopathy and brain science research used in brain disease diagnosis and brain science research. Since different tracers present different effects on the same focal area, the choice of tracers is getting more significant for PET imaging. Nowadays, with the wide application of PET imaging in neuropsychiatric treatment, 6-18F-fluoro-3, 4-dihydroxy-L-phenylalanine (DOPA) has been found to be more effective than 18F-labeled fluorine-2-deoxyglucose (FDG) in this field. However, due to the complexity of its preparation and other limitations, DOPA is far less widely used than FDG. To address this issue, a tracer conversion invertible neural network (TC-INN) for image projection is developed to map FDG images to DOPA images through deep learning. More diagnostic information is obtained by generating PET images from FDG to DOPA. Specifically, the proposed TC-INN consists of two separate phases, one for training the traceable data, the other for re-building the new data. The reference DOPA PET image is used as the learning target for the corresponding network during the training process of tracer conversion. Mean-while, the invertible network iteratively estimates the resultant DOPA PET data and compares it to the reference DOPA PET data. Notably, the reversible model employed variable enhancement techniques to achieve better power generation. Moreover, image registration needs to be performed before training due to the angular deviation of the acquired FDG and DOPA data information. Experimental results show generative ability in mapping be-tween FDG images and DOPA images. It demonstrates great potential for PET image conversion in the case of limited tracer applications.
A Template Is All You Meme
Nov 11, 2023Memes are a modern form of communication and meme templates possess a base semantics that is customizable by whomever posts it on social media. Machine learning systems struggle with memes, which is likely due to such systems having insufficient context to understand memes, as there is more to memes than the obvious image and text. Here, to aid understanding of memes, we release a knowledge base of memes and information found on www.knowyourmeme.com, which we call the Know Your Meme Knowledge Base (KYMKB), composed of more than 54,000 images. The KYMKB includes popular meme templates, examples of each template, and detailed information about the template. We hypothesize that meme templates can be used to inject models with the context missing from previous approaches. To test our hypothesis, we create a non-parametric majority-based classifier, which we call Template-Label Counter (TLC). We find TLC more effective than or competitive with fine-tuned baselines. To demonstrate the power of meme templates and the value of both our knowledge base and method, we conduct thorough classification experiments and exploratory data analysis in the context of five meme analysis tasks.
GTP-ViT: Efficient Vision Transformers via Graph-based Token Propagation
Nov 06, 2023Vision Transformers (ViTs) have revolutionized the field of computer vision, yet their deployments on resource-constrained devices remain challenging due to high computational demands. To expedite pre-trained ViTs, token pruning and token merging approaches have been developed, which aim at reducing the number of tokens involved in the computation. However, these methods still have some limitations, such as image information loss from pruned tokens and inefficiency in the token-matching process. In this paper, we introduce a novel Graph-based Token Propagation (GTP) method to resolve the challenge of balancing model efficiency and information preservation for efficient ViTs. Inspired by graph summarization algorithms, GTP meticulously propagates less significant tokens' information to spatially and semantically connected tokens that are of greater importance. Consequently, the remaining few tokens serve as a summarization of the entire token graph, allowing the method to reduce computational complexity while preserving essential information of eliminated tokens. Combined with an innovative token selection strategy, GTP can efficiently identify image tokens to be propagated. Extensive experiments have validated GTP's effectiveness, demonstrating both efficiency and performance improvements. Specifically, GTP decreases the computational complexity of both DeiT-S and DeiT-B by up to 26% with only a minimal 0.3% accuracy drop on ImageNet-1K without finetuning, and remarkably surpasses the state-of-the-art token merging method on various backbones at an even faster inference speed. The source code is available at https://github.com/Ackesnal/GTP-ViT.