 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Multiple View Geometry Transformers for 3D Human Pose Estimation
Nov 18, 2023
In this work, we aim to improve the 3D reasoning ability of Transformers in multi-view 3D human pose estimation. Recent works have focused on end-to-end learning-based transformer designs, which struggle to resolve geometric information accurately, particularly during occlusion. Instead, we propose a novel hybrid model, MVGFormer, which has a series of geometric and appearance modules organized in an iterative manner. The geometry modules are learning-free and handle all viewpoint-dependent 3D tasks geometrically which notably improves the model's generalization ability. The appearance modules are learnable and are dedicated to estimating 2D poses from image signals end-to-end which enables them to achieve accurate estimates even when occlusion occurs, leading to a model that is both accurate and generalizable to new cameras and geometries. We evaluate our approach for both in-domain and out-of-domain settings, where our model consistently outperforms state-of-the-art methods, and especially does so by a significant margin in the out-of-domain setting. We will release the code and models: https://github.com/XunshanMan/MVGFormer.
The Development of LLMs for Embodied Navigation
Nov 18, 2023In recent years, the rapid advancement of Large Language Models (LLMs) such as the Generative Pre-trained Transformer (GPT) has attracted increasing attention due to their potential in a variety of practical applications. The application of LLMs with Embodied Intelligence has emerged as a significant area of focus. Among the myriad applications of LLMs, navigation tasks are particularly noteworthy because they demand a deep understanding of the environment and quick, accurate decision-making. LLMs can augment embodied intelligence systems with sophisticated environmental perception and decision-making support, leveraging their robust language and image-processing capabilities. This article offers an exhaustive summary of the symbiosis between LLMs and embodied intelligence with a focus on navigation. It reviews state-of-the-art models, research methodologies, and assesses the advantages and disadvantages of existing embodied navigation models and datasets. Finally, the article elucidates the role of LLMs in embodied intelligence, based on current research, and forecasts future directions in the field. A comprehensive list of studies in this survey is available at https://github.com/Rongtao-Xu/Awesome-LLM-EN
Fast and Interpretable Face Identification for Out-Of-Distribution Data Using Vision Transformers
Nov 06, 2023Most face identification approaches employ a Siamese neural network to compare two images at the image embedding level. Yet, this technique can be subject to occlusion (e.g. faces with masks or sunglasses) and out-of-distribution data. DeepFace-EMD (Phan et al. 2022) reaches state-of-the-art accuracy on out-of-distribution data by first comparing two images at the image level, and then at the patch level. Yet, its later patch-wise re-ranking stage admits a large $O(n^3 \log n)$ time complexity (for $n$ patches in an image) due to the optimal transport optimization. In this paper, we propose a novel, 2-image Vision Transformers (ViTs) that compares two images at the patch level using cross-attention. After training on 2M pairs of images on CASIA Webface (Yi et al. 2014), our model performs at a comparable accuracy as DeepFace-EMD on out-of-distribution data, yet at an inference speed more than twice as fast as DeepFace-EMD (Phan et al. 2022). In addition, via a human study, our model shows promising explainability through the visualization of cross-attention. We believe our work can inspire more explorations in using ViTs for face identification.
SCB-ST-Dataset4: Extending the Spatio-Temporal Behavior Dataset in Student Classroom Scenarios Through Image Dataset Method
Oct 25, 2023
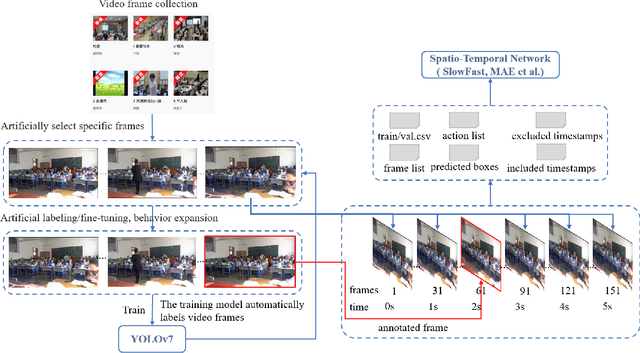


Using deep learning methods to detect students' classroom behavior automatically is a promising approach for analyzing their class performance and improving teaching effectiveness. However, the lack of publicly available spatio-temporal datasets on student behavior, as well as the high cost of manually labeling such datasets, pose significant challenges for researchers in this field. To address this issue, we proposed a method for extending the spatio-temporal behavior dataset in Student Classroom Scenarios (SCB-ST-Dataset4) through image dataset. Our SCB-ST-Dataset4 comprises 754094 images with 25670 labels, focusing on 3 behaviors: hand-raising, reading, writing. Our proposed method can rapidly generate spatio-temporal behavioral datasets without requiring annotation. Furthermore, we proposed a Behavior Similarity Index (BSI) to explore the similarity of behaviors. We evaluated the dataset using the YOLOv5, YOLOv7, YOLOv8, and SlowFast algorithms, achieving a mean average precision (map) of up to 82.3%. The experiment further demonstrates the effectiveness of our method. This dataset provides a robust foundation for future research in student behavior detection, potentially contributing to advancements in this field. The SCB-ST-Dataset4 is available for download at: https://github.com/Whiffe/SCB-dataset.
Leveraging Classic Deconvolution and Feature Extraction in Zero-Shot Image Restoration
Oct 03, 2023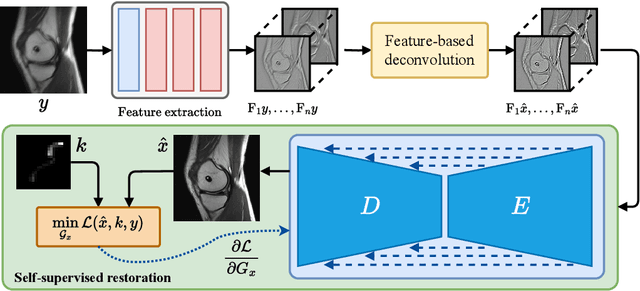
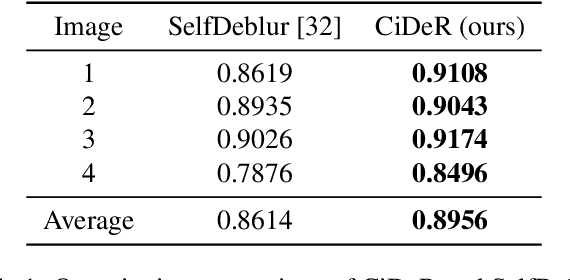
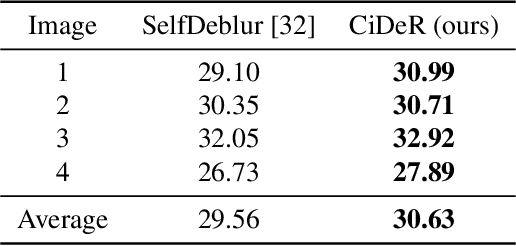
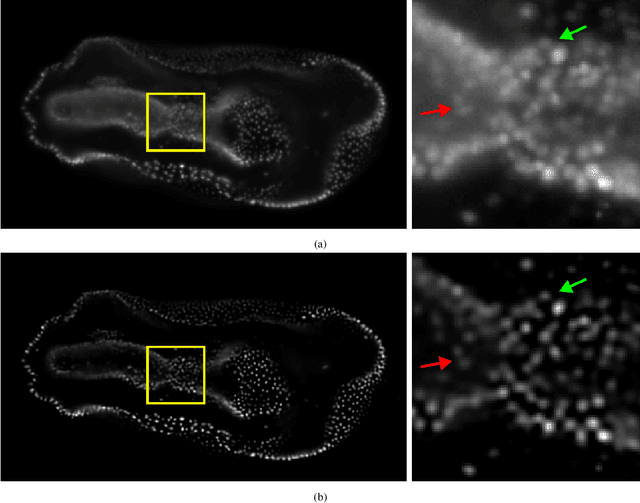
Non-blind deconvolution aims to restore a sharp image from its blurred counterpart given an obtained kernel. Existing deep neural architectures are often built based on large datasets of sharp ground truth images and trained with supervision. Sharp, high quality ground truth images, however, are not always available, especially for biomedical applications. This severely hampers the applicability of current approaches in practice. In this paper, we propose a novel non-blind deconvolution method that leverages the power of deep learning and classic iterative deconvolution algorithms. Our approach combines a pre-trained network to extract deep features from the input image with iterative Richardson-Lucy deconvolution steps. Subsequently, a zero-shot optimisation process is employed to integrate the deconvolved features, resulting in a high-quality reconstructed image. By performing the preliminary reconstruction with the classic iterative deconvolution method, we can effectively utilise a smaller network to produce the final image, thus accelerating the reconstruction whilst reducing the demand for valuable computational resources. Our method demonstrates significant improvements in various real-world applications non-blind deconvolution tasks.
Analyzing Deviations of Dyadic Lines in Fast Hough Transform
Nov 16, 2023Fast Hough transform is a widely used algorithm in pattern recognition. The algorithm relies on approximating lines using a specific discrete line model called dyadic lines. The worst-case deviation of a dyadic line from the ideal line it used to construct grows as $O(log(n))$, where $n$ is the linear size of the image. But few lines actually reach the worst-case bound. The present paper addresses a statistical analysis of the deviation of a dyadic line from its ideal counterpart. Specifically, our findings show that the mean deviation is zero, and the variance grows as $O(log(n))$. As $n$ increases, the distribution of these (suitably normalized) deviations converges towards a normal distribution with zero mean and a small variance. This limiting result makes an essential use of ergodic theory.
Improved TokenPose with Sparsity
Nov 16, 2023Over the past few years, the vision transformer and its various forms have gained significance in human pose estimation. By treating image patches as tokens, transformers can capture global relationships wisely, estimate the keypoint tokens by leveraging the visual tokens, and recognize the posture of the human body. Nevertheless, global attention is computationally demanding, which poses a challenge for scaling up transformer-based methods to high-resolution features. In this paper, we introduce sparsity in both keypoint token attention and visual token attention to improve human pose estimation. Experimental results on the MPII dataset demonstrate that our model has a higher level of accuracy and proved the feasibility of the method, achieving new state-of-the-art results. The idea can also provide references for other transformer-based models.
MARformer: An Efficient Metal Artifact Reduction Transformer for Dental CBCT Images
Nov 16, 2023Cone Beam Computed Tomography (CBCT) plays a key role in dental diagnosis and surgery. However, the metal teeth implants could bring annoying metal artifacts during the CBCT imaging process, interfering diagnosis and downstream processing such as tooth segmentation. In this paper, we develop an efficient Transformer to perform metal artifacts reduction (MAR) from dental CBCT images. The proposed MAR Transformer (MARformer) reduces computation complexity in the multihead self-attention by a new Dimension-Reduced Self-Attention (DRSA) module, based on that the CBCT images have globally similar structure. A Patch-wise Perceptive Feed Forward Network (P2FFN) is also proposed to perceive local image information for fine-grained restoration. Experimental results on CBCT images with synthetic and real-world metal artifacts show that our MARformer is efficient and outperforms previous MAR methods and two restoration Transformers.
Can CLIP Help Sound Source Localization?
Nov 07, 2023Large-scale pre-trained image-text models demonstrate remarkable versatility across diverse tasks, benefiting from their robust representational capabilities and effective multimodal alignment. We extend the application of these models, specifically CLIP, to the domain of sound source localization. Unlike conventional approaches, we employ the pre-trained CLIP model without explicit text input, relying solely on the audio-visual correspondence. To this end, we introduce a framework that translates audio signals into tokens compatible with CLIP's text encoder, yielding audio-driven embeddings. By directly using these embeddings, our method generates audio-grounded masks for the provided audio, extracts audio-grounded image features from the highlighted regions, and aligns them with the audio-driven embeddings using the audio-visual correspondence objective. Our findings suggest that utilizing pre-trained image-text models enable our model to generate more complete and compact localization maps for the sounding objects. Extensive experiments show that our method outperforms state-of-the-art approaches by a significant margin.
AGNES: Abstraction-guided Framework for Deep Neural Networks Security
Nov 07, 2023Deep Neural Networks (DNNs) are becoming widespread, particularly in safety-critical areas. One prominent application is image recognition in autonomous driving, where the correct classification of objects, such as traffic signs, is essential for safe driving. Unfortunately, DNNs are prone to backdoors, meaning that they concentrate on attributes of the image that should be irrelevant for their correct classification. Backdoors are integrated into a DNN during training, either with malicious intent (such as a manipulated training process, because of which a yellow sticker always leads to a traffic sign being recognised as a stop sign) or unintentional (such as a rural background leading to any traffic sign being recognised as animal crossing, because of biased training data). In this paper, we introduce AGNES, a tool to detect backdoors in DNNs for image recognition. We discuss the principle approach on which AGNES is based. Afterwards, we show that our tool performs better than many state-of-the-art methods for multiple relevant case studies.