 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Towards High-quality HDR Deghosting with Conditional Diffusion Models
Nov 02, 2023
High Dynamic Range (HDR) images can be recovered from several Low Dynamic Range (LDR) images by existing Deep Neural Networks (DNNs) techniques. Despite the remarkable progress, DNN-based methods still generate ghosting artifacts when LDR images have saturation and large motion, which hinders potential applications in real-world scenarios. To address this challenge, we formulate the HDR deghosting problem as an image generation that leverages LDR features as the diffusion model's condition, consisting of the feature condition generator and the noise predictor. Feature condition generator employs attention and Domain Feature Alignment (DFA) layer to transform the intermediate features to avoid ghosting artifacts. With the learned features as conditions, the noise predictor leverages a stochastic iterative denoising process for diffusion models to generate an HDR image by steering the sampling process. Furthermore, to mitigate semantic confusion caused by the saturation problem of LDR images, we design a sliding window noise estimator to sample smooth noise in a patch-based manner. In addition, an image space loss is proposed to avoid the color distortion of the estimated HDR results. We empirically evaluate our model on benchmark datasets for HDR imaging. The results demonstrate that our approach achieves state-of-the-art performances and well generalization to real-world images.
Greedy PIG: Adaptive Integrated Gradients
Nov 10, 2023Deep learning has become the standard approach for most machine learning tasks. While its impact is undeniable, interpreting the predictions of deep learning models from a human perspective remains a challenge. In contrast to model training, model interpretability is harder to quantify and pose as an explicit optimization problem. Inspired by the AUC softmax information curve (AUC SIC) metric for evaluating feature attribution methods, we propose a unified discrete optimization framework for feature attribution and feature selection based on subset selection. This leads to a natural adaptive generalization of the path integrated gradients (PIG) method for feature attribution, which we call Greedy PIG. We demonstrate the success of Greedy PIG on a wide variety of tasks, including image feature attribution, graph compression/explanation, and post-hoc feature selection on tabular data. Our results show that introducing adaptivity is a powerful and versatile method for making attribution methods more powerful.
Impressions: Understanding Visual Semiotics and Aesthetic Impact
Oct 27, 2023Is aesthetic impact different from beauty? Is visual salience a reflection of its capacity for effective communication? We present Impressions, a novel dataset through which to investigate the semiotics of images, and how specific visual features and design choices can elicit specific emotions, thoughts and beliefs. We posit that the impactfulness of an image extends beyond formal definitions of aesthetics, to its success as a communicative act, where style contributes as much to meaning formation as the subject matter. However, prior image captioning datasets are not designed to empower state-of-the-art architectures to model potential human impressions or interpretations of images. To fill this gap, we design an annotation task heavily inspired by image analysis techniques in the Visual Arts to collect 1,440 image-caption pairs and 4,320 unique annotations exploring impact, pragmatic image description, impressions, and aesthetic design choices. We show that existing multimodal image captioning and conditional generation models struggle to simulate plausible human responses to images. However, this dataset significantly improves their ability to model impressions and aesthetic evaluations of images through fine-tuning and few-shot adaptation.
CVTHead: One-shot Controllable Head Avatar with Vertex-feature Transformer
Nov 11, 2023Reconstructing personalized animatable head avatars has significant implications in the fields of AR/VR. Existing methods for achieving explicit face control of 3D Morphable Models (3DMM) typically rely on multi-view images or videos of a single subject, making the reconstruction process complex. Additionally, the traditional rendering pipeline is time-consuming, limiting real-time animation possibilities. In this paper, we introduce CVTHead, a novel approach that generates controllable neural head avatars from a single reference image using point-based neural rendering. CVTHead considers the sparse vertices of mesh as the point set and employs the proposed Vertex-feature Transformer to learn local feature descriptors for each vertex. This enables the modeling of long-range dependencies among all the vertices. Experimental results on the VoxCeleb dataset demonstrate that CVTHead achieves comparable performance to state-of-the-art graphics-based methods. Moreover, it enables efficient rendering of novel human heads with various expressions, head poses, and camera views. These attributes can be explicitly controlled using the coefficients of 3DMMs, facilitating versatile and realistic animation in real-time scenarios.
Detecting Spurious Correlations via Robust Visual Concepts in Real and AI-Generated Image Classification
Nov 03, 2023Often machine learning models tend to automatically learn associations present in the training data without questioning their validity or appropriateness. This undesirable property is the root cause of the manifestation of spurious correlations, which render models unreliable and prone to failure in the presence of distribution shifts. Research shows that most methods attempting to remedy spurious correlations are only effective for a model's known spurious associations. Current spurious correlation detection algorithms either rely on extensive human annotations or are too restrictive in their formulation. Moreover, they rely on strict definitions of visual artifacts that may not apply to data produced by generative models, as they are known to hallucinate contents that do not conform to standard specifications. In this work, we introduce a general-purpose method that efficiently detects potential spurious correlations, and requires significantly less human interference in comparison to the prior art. Additionally, the proposed method provides intuitive explanations while eliminating the need for pixel-level annotations. We demonstrate the proposed method's tolerance to the peculiarity of AI-generated images, which is a considerably challenging task, one where most of the existing methods fall short. Consequently, our method is also suitable for detecting spurious correlations that may propagate to downstream applications originating from generative models.
Context-I2W: Mapping Images to Context-dependent Words for Accurate Zero-Shot Composed Image Retrieval
Sep 28, 2023Different from Composed Image Retrieval task that requires expensive labels for training task-specific models, Zero-Shot Composed Image Retrieval (ZS-CIR) involves diverse tasks with a broad range of visual content manipulation intent that could be related to domain, scene, object, and attribute. The key challenge for ZS-CIR tasks is to learn a more accurate image representation that has adaptive attention to the reference image for various manipulation descriptions. In this paper, we propose a novel context-dependent mapping network, named Context-I2W, for adaptively converting description-relevant Image information into a pseudo-word token composed of the description for accurate ZS-CIR. Specifically, an Intent View Selector first dynamically learns a rotation rule to map the identical image to a task-specific manipulation view. Then a Visual Target Extractor further captures local information covering the main targets in ZS-CIR tasks under the guidance of multiple learnable queries. The two complementary modules work together to map an image to a context-dependent pseudo-word token without extra supervision. Our model shows strong generalization ability on four ZS-CIR tasks, including domain conversion, object composition, object manipulation, and attribute manipulation. It obtains consistent and significant performance boosts ranging from 1.88% to 3.60% over the best methods and achieves new state-of-the-art results on ZS-CIR. Our code is available at https://github.com/Pter61/context_i2w.
Dynamic Prompt Learning: Addressing Cross-Attention Leakage for Text-Based Image Editing
Sep 27, 2023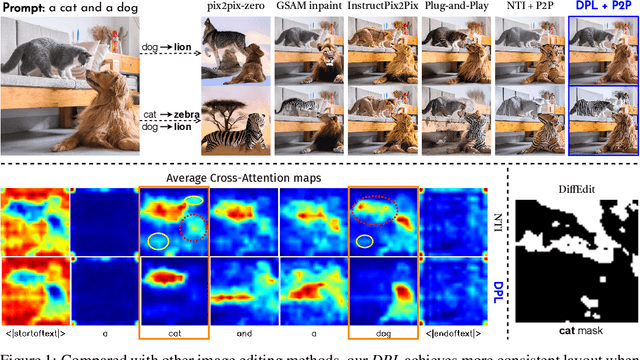
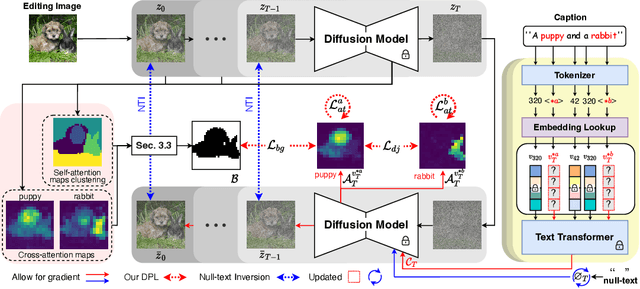

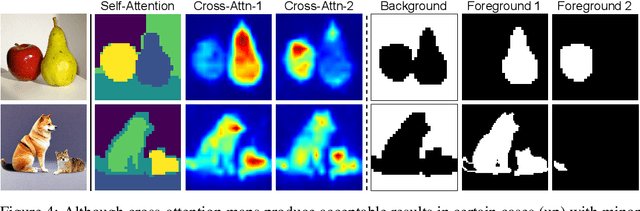
Large-scale text-to-image generative models have been a ground-breaking development in generative AI, with diffusion models showing their astounding ability to synthesize convincing images following an input text prompt. The goal of image editing research is to give users control over the generated images by modifying the text prompt. Current image editing techniques are susceptible to unintended modifications of regions outside the targeted area, such as on the background or on distractor objects which have some semantic or visual relationship with the targeted object. According to our experimental findings, inaccurate cross-attention maps are at the root of this problem. Based on this observation, we propose Dynamic Prompt Learning (DPL) to force cross-attention maps to focus on correct noun words in the text prompt. By updating the dynamic tokens for nouns in the textual input with the proposed leakage repairment losses, we achieve fine-grained image editing over particular objects while preventing undesired changes to other image regions. Our method DPL, based on the publicly available Stable Diffusion, is extensively evaluated on a wide range of images, and consistently obtains superior results both quantitatively (CLIP score, Structure-Dist) and qualitatively (on user-evaluation). We show improved prompt editing results for Word-Swap, Prompt Refinement, and Attention Re-weighting, especially for complex multi-object scenes.
Direction-Oriented Visual-semantic Embedding Model for Remote Sensing Image-text Retrieval
Oct 12, 2023Image-text retrieval has developed rapidly in recent years. However, it is still a challenge in remote sensing due to visual-semantic imbalance, which leads to incorrect matching of non-semantic visual and textual features. To solve this problem, we propose a novel Direction-Oriented Visual-semantic Embedding Model (DOVE) to mine the relationship between vision and language. Concretely, a Regional-Oriented Attention Module (ROAM) adaptively adjusts the distance between the final visual and textual embeddings in the latent semantic space, oriented by regional visual features. Meanwhile, a lightweight Digging Text Genome Assistant (DTGA) is designed to expand the range of tractable textual representation and enhance global word-level semantic connections using less attention operations. Ultimately, we exploit a global visual-semantic constraint to reduce single visual dependency and serve as an external constraint for the final visual and textual representations. The effectiveness and superiority of our method are verified by extensive experiments including parameter evaluation, quantitative comparison, ablation studies and visual analysis, on two benchmark datasets, RSICD and RSITMD.
Emu: Enhancing Image Generation Models Using Photogenic Needles in a Haystack
Sep 27, 2023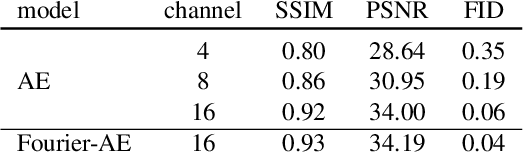

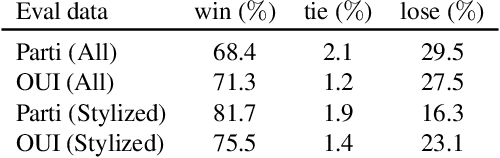

Training text-to-image models with web scale image-text pairs enables the generation of a wide range of visual concepts from text. However, these pre-trained models often face challenges when it comes to generating highly aesthetic images. This creates the need for aesthetic alignment post pre-training. In this paper, we propose quality-tuning to effectively guide a pre-trained model to exclusively generate highly visually appealing images, while maintaining generality across visual concepts. Our key insight is that supervised fine-tuning with a set of surprisingly small but extremely visually appealing images can significantly improve the generation quality. We pre-train a latent diffusion model on $1.1$ billion image-text pairs and fine-tune it with only a few thousand carefully selected high-quality images. The resulting model, Emu, achieves a win rate of $82.9\%$ compared with its pre-trained only counterpart. Compared to the state-of-the-art SDXLv1.0, Emu is preferred $68.4\%$ and $71.3\%$ of the time on visual appeal on the standard PartiPrompts and our Open User Input benchmark based on the real-world usage of text-to-image models. In addition, we show that quality-tuning is a generic approach that is also effective for other architectures, including pixel diffusion and masked generative transformer models.
KV Inversion: KV Embeddings Learning for Text-Conditioned Real Image Action Editing
Sep 28, 2023
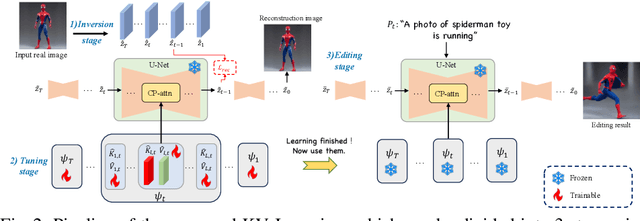


Text-conditioned image editing is a recently emerged and highly practical task, and its potential is immeasurable. However, most of the concurrent methods are unable to perform action editing, i.e. they can not produce results that conform to the action semantics of the editing prompt and preserve the content of the original image. To solve the problem of action editing, we propose KV Inversion, a method that can achieve satisfactory reconstruction performance and action editing, which can solve two major problems: 1) the edited result can match the corresponding action, and 2) the edited object can retain the texture and identity of the original real image. In addition, our method does not require training the Stable Diffusion model itself, nor does it require scanning a large-scale dataset to perform time-consuming training.