 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
VideoCrafter1: Open Diffusion Models for High-Quality Video Generation
Oct 30, 2023
Video generation has increasingly gained interest in both academia and industry. Although commercial tools can generate plausible videos, there is a limited number of open-source models available for researchers and engineers. In this work, we introduce two diffusion models for high-quality video generation, namely text-to-video (T2V) and image-to-video (I2V) models. T2V models synthesize a video based on a given text input, while I2V models incorporate an additional image input. Our proposed T2V model can generate realistic and cinematic-quality videos with a resolution of $1024 \times 576$, outperforming other open-source T2V models in terms of quality. The I2V model is designed to produce videos that strictly adhere to the content of the provided reference image, preserving its content, structure, and style. This model is the first open-source I2V foundation model capable of transforming a given image into a video clip while maintaining content preservation constraints. We believe that these open-source video generation models will contribute significantly to the technological advancements within the community.
Machine Learning-Based Tea Leaf Disease Detection: A Comprehensive Review
Nov 06, 2023Tea leaf diseases are a major challenge to agricultural productivity, with far-reaching implications for yield and quality in the tea industry. The rise of machine learning has enabled the development of innovative approaches to combat these diseases. Early detection and diagnosis are crucial for effective crop management. For predicting tea leaf disease, several automated systems have already been developed using different image processing techniques. This paper delivers a systematic review of the literature on machine learning methodologies applied to diagnose tea leaf disease via image classification. It thoroughly evaluates the strengths and constraints of various Vision Transformer models, including Inception Convolutional Vision Transformer (ICVT), GreenViT, PlantXViT, PlantViT, MSCVT, Transfer Learning Model & Vision Transformer (TLMViT), IterationViT, IEM-ViT. Moreover, this paper also reviews models like Dense Convolutional Network (DenseNet), Residual Neural Network (ResNet)-50V2, YOLOv5, YOLOv7, Convolutional Neural Network (CNN), Deep CNN, Non-dominated Sorting Genetic Algorithm (NSGA-II), MobileNetv2, and Lesion-Aware Visual Transformer. These machine-learning models have been tested on various datasets, demonstrating their real-world applicability. This review study not only highlights current progress in the field but also provides valuable insights for future research directions in the machine learning-based detection and classification of tea leaf diseases.
Exploiting Image-Related Inductive Biases in Single-Branch Visual Tracking
Oct 30, 2023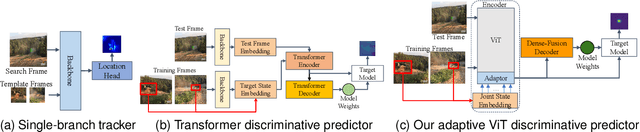
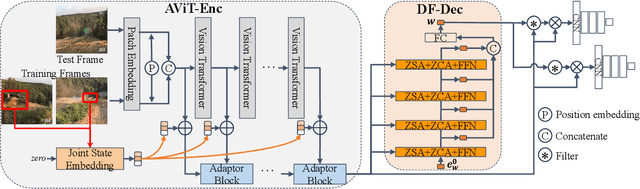

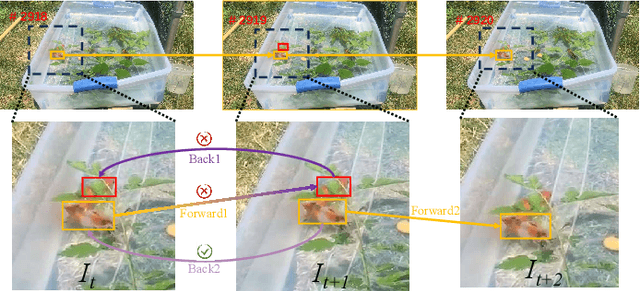
Despite achieving state-of-the-art performance in visual tracking, recent single-branch trackers tend to overlook the weak prior assumptions associated with the Vision Transformer (ViT) encoder and inference pipeline. Moreover, the effectiveness of discriminative trackers remains constrained due to the adoption of the dual-branch pipeline. To tackle the inferior effectiveness of the vanilla ViT, we propose an Adaptive ViT Model Prediction tracker (AViTMP) to bridge the gap between single-branch network and discriminative models. Specifically, in the proposed encoder AViT-Enc, we introduce an adaptor module and joint target state embedding to enrich the dense embedding paradigm based on ViT. Then, we combine AViT-Enc with a dense-fusion decoder and a discriminative target model to predict accurate location. Further, to mitigate the limitations of conventional inference practice, we present a novel inference pipeline called CycleTrack, which bolsters the tracking robustness in the presence of distractors via bidirectional cycle tracking verification. Lastly, we propose a dual-frame update inference strategy that adeptively handles significant challenges in long-term scenarios. In the experiments, we evaluate AViTMP on ten tracking benchmarks for a comprehensive assessment, including LaSOT, LaSOTExtSub, AVisT, etc. The experimental results unequivocally establish that AViTMP attains state-of-the-art performance, especially on long-time tracking and robustness.
Step and Smooth Decompositions as Topological Clustering
Nov 09, 2023We investigate a class of recovery problems for which observations are a noisy combination of continuous and step functions. These problems can be seen as non-injective instances of non-linear ICA with direct applications to image decontamination for magnetic resonance imaging. Alternately, the problem can be viewed as clustering in the presence of structured (smooth) contaminant. We show that a global topological property (graph connectivity) interacts with a local property (the degree of smoothness of the continuous component) to determine conditions under which the components are identifiable. Additionally, a practical estimation algorithm is provided for the case when the contaminant lies in a reproducing kernel Hilbert space of continuous functions. Algorithm effectiveness is demonstrated through a series of simulations and real-world studies.
Deep Hashing via Householder Quantization
Nov 07, 2023Hashing is at the heart of large-scale image similarity search, and recent methods have been substantially improved through deep learning techniques. Such algorithms typically learn continuous embeddings of the data. To avoid a subsequent costly binarization step, a common solution is to employ loss functions that combine a similarity learning term (to ensure similar images are grouped to nearby embeddings) and a quantization penalty term (to ensure that the embedding entries are close to binarized entries, e.g., -1 or 1). Still, the interaction between these two terms can make learning harder and the embeddings worse. We propose an alternative quantization strategy that decomposes the learning problem in two stages: first, perform similarity learning over the embedding space with no quantization; second, find an optimal orthogonal transformation of the embeddings so each coordinate of the embedding is close to its sign, and then quantize the transformed embedding through the sign function. In the second step, we parametrize orthogonal transformations using Householder matrices to efficiently leverage stochastic gradient descent. Since similarity measures are usually invariant under orthogonal transformations, this quantization strategy comes at no cost in terms of performance. The resulting algorithm is unsupervised, fast, hyperparameter-free and can be run on top of any existing deep hashing or metric learning algorithm. We provide extensive experimental results showing that this approach leads to state-of-the-art performance on widely used image datasets, and, unlike other quantization strategies, brings consistent improvements in performance to existing deep hashing algorithms.
A Perceptual Shape Loss for Monocular 3D Face Reconstruction
Oct 30, 2023Monocular 3D face reconstruction is a wide-spread topic, and existing approaches tackle the problem either through fast neural network inference or offline iterative reconstruction of face geometry. In either case carefully-designed energy functions are minimized, commonly including loss terms like a photometric loss, a landmark reprojection loss, and others. In this work we propose a new loss function for monocular face capture, inspired by how humans would perceive the quality of a 3D face reconstruction given a particular image. It is widely known that shading provides a strong indicator for 3D shape in the human visual system. As such, our new 'perceptual' shape loss aims to judge the quality of a 3D face estimate using only shading cues. Our loss is implemented as a discriminator-style neural network that takes an input face image and a shaded render of the geometry estimate, and then predicts a score that perceptually evaluates how well the shaded render matches the given image. This 'critic' network operates on the RGB image and geometry render alone, without requiring an estimate of the albedo or illumination in the scene. Furthermore, our loss operates entirely in image space and is thus agnostic to mesh topology. We show how our new perceptual shape loss can be combined with traditional energy terms for monocular 3D face optimization and deep neural network regression, improving upon current state-of-the-art results.
* Accepted to PG 2023. Project page: https://studios.disneyresearch.com/2023/10/09/a-perceptual-shape-loss-for-monocular-3d-face-reconstruction/ Video: https://www.youtube.com/watch?v=RYdyoIZEuUI
Multiview Transformer: Rethinking Spatial Information in Hyperspectral Image Classification
Oct 11, 2023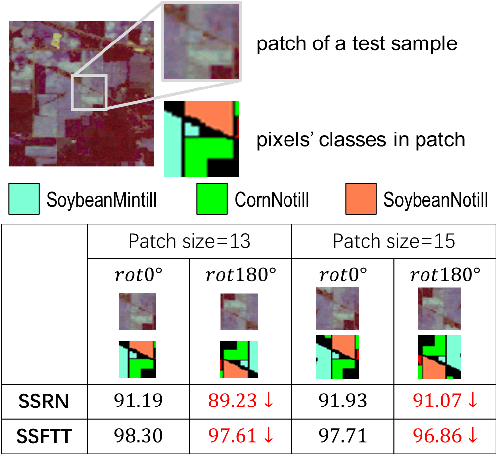
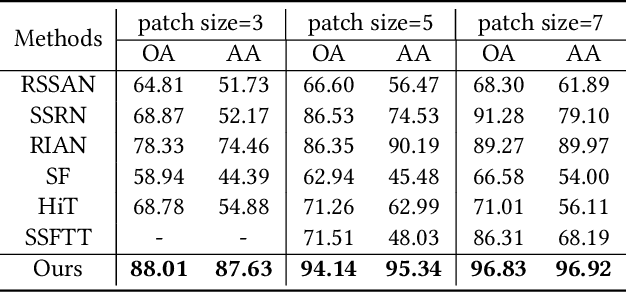

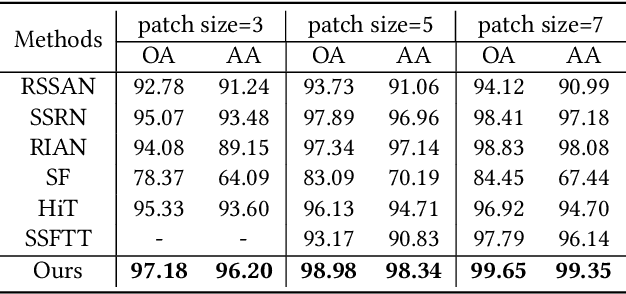
Identifying the land cover category for each pixel in a hyperspectral image (HSI) relies on spectral and spatial information. An HSI cuboid with a specific patch size is utilized to extract spatial-spectral feature representation for the central pixel. In this article, we investigate that scene-specific but not essential correlations may be recorded in an HSI cuboid. This additional information improves the model performance on existing HSI datasets and makes it hard to properly evaluate the ability of a model. We refer to this problem as the spatial overfitting issue and utilize strict experimental settings to avoid it. We further propose a multiview transformer for HSI classification, which consists of multiview principal component analysis (MPCA), spectral encoder-decoder (SED), and spatial-pooling tokenization transformer (SPTT). MPCA performs dimension reduction on an HSI via constructing spectral multiview observations and applying PCA on each view data to extract low-dimensional view representation. The combination of view representations, named multiview representation, is the dimension reduction output of the MPCA. To aggregate the multiview information, a fully-convolutional SED with a U-shape in spectral dimension is introduced to extract a multiview feature map. SPTT transforms the multiview features into tokens using the spatial-pooling tokenization strategy and learns robust and discriminative spatial-spectral features for land cover identification. Classification is conducted with a linear classifier. Experiments on three HSI datasets with rigid settings demonstrate the superiority of the proposed multiview transformer over the state-of-the-art methods.
Mixture-of-Experts for Open Set Domain Adaptation: A Dual-Space Detection Approach
Nov 01, 2023Open Set Domain Adaptation (OSDA) aims to cope with the distribution and label shifts between the source and target domains simultaneously, performing accurate classification for known classes while identifying unknown class samples in the target domain. Most existing OSDA approaches, depending on the final image feature space of deep models, require manually-tuned thresholds, and may easily misclassify unknown samples as known classes. Mixture-of-Expert (MoE) could be a remedy. Within an MoE, different experts address different input features, producing unique expert routing patterns for different classes in a routing feature space. As a result, unknown class samples may also display different expert routing patterns to known classes. This paper proposes Dual-Space Detection, which exploits the inconsistencies between the image feature space and the routing feature space to detect unknown class samples without any threshold. Graph Router is further introduced to better make use of the spatial information among image patches. Experiments on three different datasets validated the effectiveness and superiority of our approach. The code will come soon.
Convolutional Neural Networks Exploiting Attributes of Biological Neurons
Nov 14, 2023In this era of artificial intelligence, deep neural networks like Convolutional Neural Networks (CNNs) have emerged as front-runners, often surpassing human capabilities. These deep networks are often perceived as the panacea for all challenges. Unfortunately, a common downside of these networks is their ''black-box'' character, which does not necessarily mirror the operation of biological neural systems. Some even have millions/billions of learnable (tunable) parameters, and their training demands extensive data and time. Here, we integrate the principles of biological neurons in certain layer(s) of CNNs. Specifically, we explore the use of neuro-science-inspired computational models of the Lateral Geniculate Nucleus (LGN) and simple cells of the primary visual cortex. By leveraging such models, we aim to extract image features to use as input to CNNs, hoping to enhance training efficiency and achieve better accuracy. We aspire to enable shallow networks with a Push-Pull Combination of Receptive Fields (PP-CORF) model of simple cells as the foundation layer of CNNs to enhance their learning process and performance. To achieve this, we propose a two-tower CNN, one shallow tower and the other as ResNet 18. Rather than extracting the features blindly, it seeks to mimic how the brain perceives and extracts features. The proposed system exhibits a noticeable improvement in the performance (on an average of $5\%-10\%$) on CIFAR-10, CIFAR-100, and ImageNet-100 datasets compared to ResNet-18. We also check the efficiency of only the Push-Pull tower of the network.
Continual atlas-based segmentation of prostate MRI
Nov 02, 2023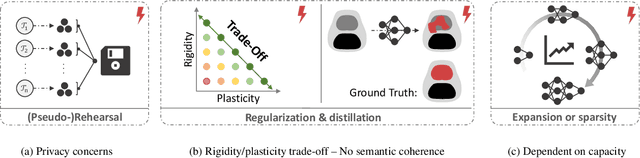
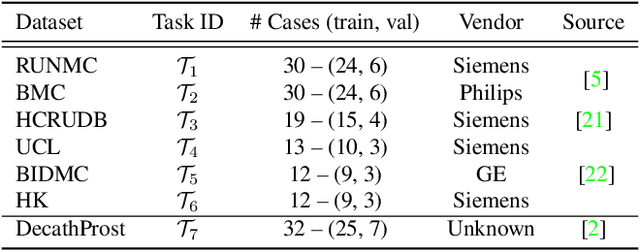
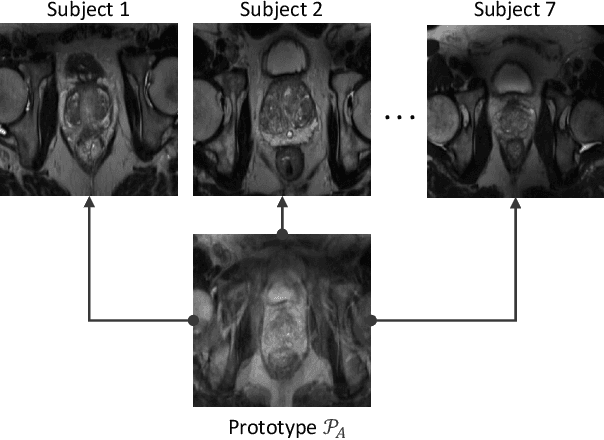
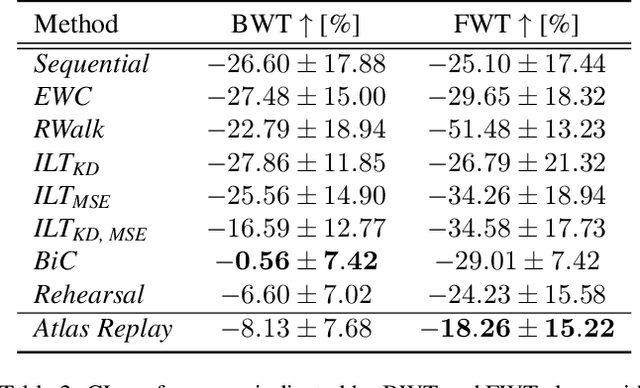
Continual learning (CL) methods designed for natural image classification often fail to reach basic quality standards for medical image segmentation. Atlas-based segmentation, a well-established approach in medical imaging, incorporates domain knowledge on the region of interest, leading to semantically coherent predictions. This is especially promising for CL, as it allows us to leverage structural information and strike an optimal balance between model rigidity and plasticity over time. When combined with privacy-preserving prototypes, this process offers the advantages of rehearsal-based CL without compromising patient privacy. We propose Atlas Replay, an atlas-based segmentation approach that uses prototypes to generate high-quality segmentation masks through image registration that maintain consistency even as the training distribution changes. We explore how our proposed method performs compared to state-of-the-art CL methods in terms of knowledge transferability across seven publicly available prostate segmentation datasets. Prostate segmentation plays a vital role in diagnosing prostate cancer, however, it poses challenges due to substantial anatomical variations, benign structural differences in older age groups, and fluctuating acquisition parameters. Our results show that Atlas Replay is both robust and generalizes well to yet-unseen domains while being able to maintain knowledge, unlike end-to-end segmentation methods. Our code base is available under https://github.com/MECLabTUDA/Atlas-Replay.