 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Dynamic Prompt Learning: Addressing Cross-Attention Leakage for Text-Based Image Editing
Sep 27, 2023
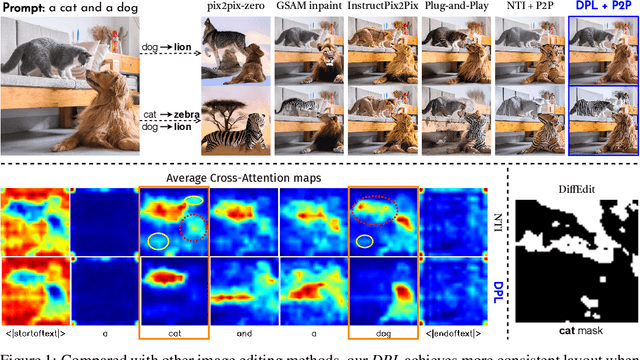
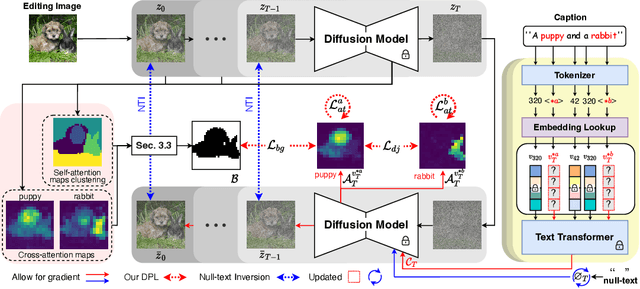

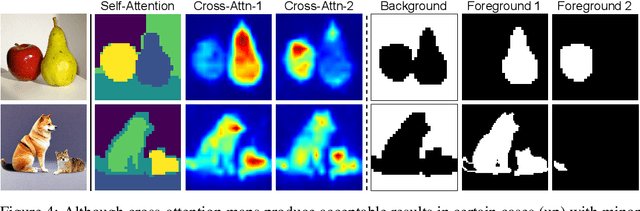
Large-scale text-to-image generative models have been a ground-breaking development in generative AI, with diffusion models showing their astounding ability to synthesize convincing images following an input text prompt. The goal of image editing research is to give users control over the generated images by modifying the text prompt. Current image editing techniques are susceptible to unintended modifications of regions outside the targeted area, such as on the background or on distractor objects which have some semantic or visual relationship with the targeted object. According to our experimental findings, inaccurate cross-attention maps are at the root of this problem. Based on this observation, we propose Dynamic Prompt Learning (DPL) to force cross-attention maps to focus on correct noun words in the text prompt. By updating the dynamic tokens for nouns in the textual input with the proposed leakage repairment losses, we achieve fine-grained image editing over particular objects while preventing undesired changes to other image regions. Our method DPL, based on the publicly available Stable Diffusion, is extensively evaluated on a wide range of images, and consistently obtains superior results both quantitatively (CLIP score, Structure-Dist) and qualitatively (on user-evaluation). We show improved prompt editing results for Word-Swap, Prompt Refinement, and Attention Re-weighting, especially for complex multi-object scenes.
Context-I2W: Mapping Images to Context-dependent Words for Accurate Zero-Shot Composed Image Retrieval
Sep 28, 2023Different from Composed Image Retrieval task that requires expensive labels for training task-specific models, Zero-Shot Composed Image Retrieval (ZS-CIR) involves diverse tasks with a broad range of visual content manipulation intent that could be related to domain, scene, object, and attribute. The key challenge for ZS-CIR tasks is to learn a more accurate image representation that has adaptive attention to the reference image for various manipulation descriptions. In this paper, we propose a novel context-dependent mapping network, named Context-I2W, for adaptively converting description-relevant Image information into a pseudo-word token composed of the description for accurate ZS-CIR. Specifically, an Intent View Selector first dynamically learns a rotation rule to map the identical image to a task-specific manipulation view. Then a Visual Target Extractor further captures local information covering the main targets in ZS-CIR tasks under the guidance of multiple learnable queries. The two complementary modules work together to map an image to a context-dependent pseudo-word token without extra supervision. Our model shows strong generalization ability on four ZS-CIR tasks, including domain conversion, object composition, object manipulation, and attribute manipulation. It obtains consistent and significant performance boosts ranging from 1.88% to 3.60% over the best methods and achieves new state-of-the-art results on ZS-CIR. Our code is available at https://github.com/Pter61/context_i2w.
Local-Global Self-Supervised Visual Representation Learning
Oct 28, 2023Self-supervised representation learning methods mainly focus on image-level instance discrimination. This study explores the potential benefits of incorporating patch-level discrimination into existing methods to enhance the quality of learned representations by simultaneously looking at local and global visual features. Towards this idea, we present a straightforward yet effective patch-matching algorithm that can find the corresponding patches across the augmented views of an image. The augmented views are subsequently fed into a self-supervised learning framework employing Vision Transformer (ViT) as its backbone. The result is the generation of both image-level and patch-level representations. Leveraging the proposed patch-matching algorithm, the model minimizes the representation distance between not only the CLS tokens but also the corresponding patches. As a result, the model gains a more comprehensive understanding of both the entirety of the image as well as its finer details. We pretrain the proposed method on small, medium, and large-scale datasets. It is shown that our approach could outperform state-of-the-art image-level representation learning methods on both image classification and downstream tasks. Keywords: Self-Supervised Learning; Visual Representations; Local-Global Representation Learning; Patch-Wise Representation Learning; Vision Transformer (ViT)
Adversarial Fine-tuning using Generated Respiratory Sound to Address Class Imbalance
Nov 11, 2023Deep generative models have emerged as a promising approach in the medical image domain to address data scarcity. However, their use for sequential data like respiratory sounds is less explored. In this work, we propose a straightforward approach to augment imbalanced respiratory sound data using an audio diffusion model as a conditional neural vocoder. We also demonstrate a simple yet effective adversarial fine-tuning method to align features between the synthetic and real respiratory sound samples to improve respiratory sound classification performance. Our experimental results on the ICBHI dataset demonstrate that the proposed adversarial fine-tuning is effective, while only using the conventional augmentation method shows performance degradation. Moreover, our method outperforms the baseline by 2.24% on the ICBHI Score and improves the accuracy of the minority classes up to 26.58%. For the supplementary material, we provide the code at https://github.com/kaen2891/adversarial_fine-tuning_using_generated_respiratory_sound.
Degradation Estimation Recurrent Neural Network with Local and Non-Local Priors for Compressive Spectral Imaging
Nov 15, 2023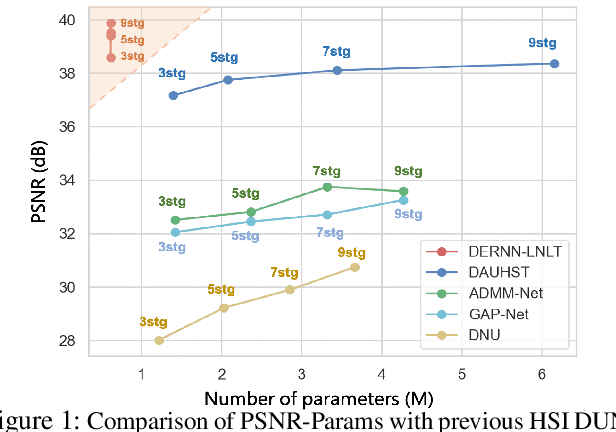
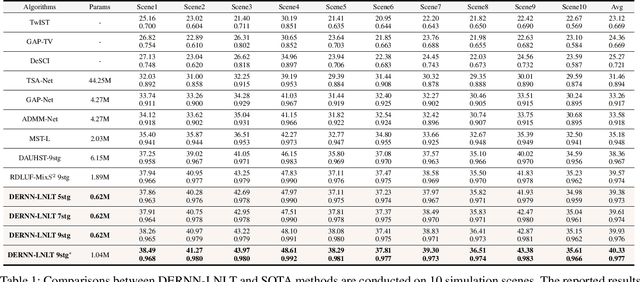
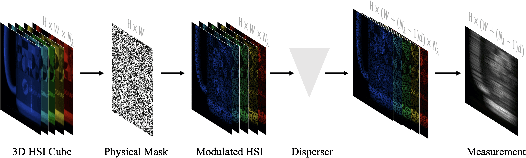
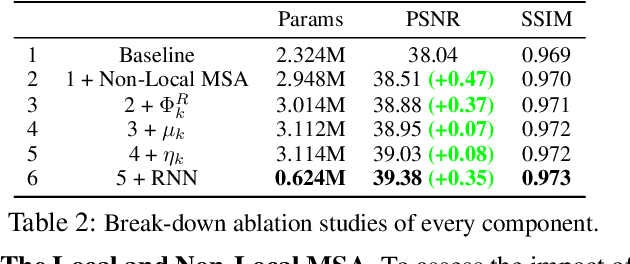
In coded aperture snapshot spectral imaging (CASSI) systems, a core problem is to recover the 3D hyperspectral image (HSI) from the 2D measurement. Current deep unfolding networks (DUNs) for the HSI reconstruction mainly suffered from three issues. Firstly, in previous DUNs, the DNNs across different stages were unable to share the feature representations learned from different stages, leading to parameter sparsity, which in turn limited their reconstruction potential. Secondly, previous DUNs fail to estimate degradation-related parameters within a unified framework, including the degradation matrix in the data subproblem and the noise level in the prior subproblem. Consequently, either the accuracy of solving the data or the prior subproblem is compromised. Thirdly, exploiting both local and non-local priors for the HSI reconstruction is crucial, and it remains a key issue to be addressed. In this paper, we first transform the DUN into a Recurrent Neural Network (RNN) by sharing parameters across stages, which allows the DNN in each stage could learn feature representation from different stages, enhancing the representativeness of the DUN. Secondly, we incorporate the Degradation Estimation Network into the RNN (DERNN), which simultaneously estimates the degradation matrix and the noise level by residual learning with reference to the sensing matrix. Thirdly, we propose a Local and Non-Local Transformer (LNLT) to effectively exploit both local and non-local priors in HSIs. By integrating the LNLT into the DERNN for solving the prior subproblem, we propose the DERNN-LNLT, which achieves state-of-the-art performance.
ConeQuest: A Benchmark for Cone Segmentation on Mars
Nov 15, 2023Over the years, space scientists have collected terabytes of Mars data from satellites and rovers. One important set of features identified in Mars orbital images is pitted cones, which are interpreted to be mud volcanoes believed to form in regions that were once saturated in water (i.e., a lake or ocean). Identifying pitted cones globally on Mars would be of great importance, but expert geologists are unable to sort through the massive orbital image archives to identify all examples. However, this task is well suited for computer vision. Although several computer vision datasets exist for various Mars-related tasks, there is currently no open-source dataset available for cone detection/segmentation. Furthermore, previous studies trained models using data from a single region, which limits their applicability for global detection and mapping. Motivated by this, we introduce ConeQuest, the first expert-annotated public dataset to identify cones on Mars. ConeQuest consists of >13k samples from 3 different regions of Mars. We propose two benchmark tasks using ConeQuest: (i) Spatial Generalization and (ii) Cone-size Generalization. We finetune and evaluate widely-used segmentation models on both benchmark tasks. Results indicate that cone segmentation is a challenging open problem not solved by existing segmentation models, which achieve an average IoU of 52.52% and 42.55% on in-distribution data for tasks (i) and (ii), respectively. We believe this new benchmark dataset will facilitate the development of more accurate and robust models for cone segmentation. Data and code are available at https://github.com/kerner-lab/ConeQuest.
Emu: Enhancing Image Generation Models Using Photogenic Needles in a Haystack
Sep 27, 2023

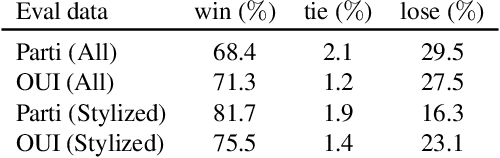

Training text-to-image models with web scale image-text pairs enables the generation of a wide range of visual concepts from text. However, these pre-trained models often face challenges when it comes to generating highly aesthetic images. This creates the need for aesthetic alignment post pre-training. In this paper, we propose quality-tuning to effectively guide a pre-trained model to exclusively generate highly visually appealing images, while maintaining generality across visual concepts. Our key insight is that supervised fine-tuning with a set of surprisingly small but extremely visually appealing images can significantly improve the generation quality. We pre-train a latent diffusion model on $1.1$ billion image-text pairs and fine-tune it with only a few thousand carefully selected high-quality images. The resulting model, Emu, achieves a win rate of $82.9\%$ compared with its pre-trained only counterpart. Compared to the state-of-the-art SDXLv1.0, Emu is preferred $68.4\%$ and $71.3\%$ of the time on visual appeal on the standard PartiPrompts and our Open User Input benchmark based on the real-world usage of text-to-image models. In addition, we show that quality-tuning is a generic approach that is also effective for other architectures, including pixel diffusion and masked generative transformer models.
IMPRESS: Evaluating the Resilience of Imperceptible Perturbations Against Unauthorized Data Usage in Diffusion-Based Generative AI
Oct 30, 2023Diffusion-based image generation models, such as Stable Diffusion or DALL-E 2, are able to learn from given images and generate high-quality samples following the guidance from prompts. For instance, they can be used to create artistic images that mimic the style of an artist based on his/her original artworks or to maliciously edit the original images for fake content. However, such ability also brings serious ethical issues without proper authorization from the owner of the original images. In response, several attempts have been made to protect the original images from such unauthorized data usage by adding imperceptible perturbations, which are designed to mislead the diffusion model and make it unable to properly generate new samples. In this work, we introduce a perturbation purification platform, named IMPRESS, to evaluate the effectiveness of imperceptible perturbations as a protective measure. IMPRESS is based on the key observation that imperceptible perturbations could lead to a perceptible inconsistency between the original image and the diffusion-reconstructed image, which can be used to devise a new optimization strategy for purifying the image, which may weaken the protection of the original image from unauthorized data usage (e.g., style mimicking, malicious editing). The proposed IMPRESS platform offers a comprehensive evaluation of several contemporary protection methods, and can be used as an evaluation platform for future protection methods.
KV Inversion: KV Embeddings Learning for Text-Conditioned Real Image Action Editing
Sep 28, 2023
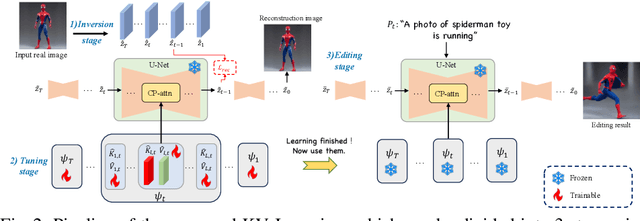


Text-conditioned image editing is a recently emerged and highly practical task, and its potential is immeasurable. However, most of the concurrent methods are unable to perform action editing, i.e. they can not produce results that conform to the action semantics of the editing prompt and preserve the content of the original image. To solve the problem of action editing, we propose KV Inversion, a method that can achieve satisfactory reconstruction performance and action editing, which can solve two major problems: 1) the edited result can match the corresponding action, and 2) the edited object can retain the texture and identity of the original real image. In addition, our method does not require training the Stable Diffusion model itself, nor does it require scanning a large-scale dataset to perform time-consuming training.
Forgedit: Text Guided Image Editing via Learning and Forgetting
Sep 19, 2023Text guided image editing on real images given only the image and the target text prompt as inputs, is a very general and challenging problem, which requires the editing model to reason by itself which part of the image should be edited, to preserve the characteristics of original image, and also to perform complicated non-rigid editing. Previous fine-tuning based solutions are time-consuming and vulnerable to overfitting, limiting their editing capabilities. To tackle these issues, we design a novel text guided image editing method, Forgedit. First, we propose a novel fine-tuning framework which learns to reconstruct the given image in less than one minute by vision language joint learning. Then we introduce vector subtraction and vector projection to explore the proper text embedding for editing. We also find a general property of UNet structures in Diffusion Models and inspired by such a finding, we design forgetting strategies to diminish the fatal overfitting issues and significantly boost the editing abilities of Diffusion Models. Our method, Forgedit, implemented with Stable Diffusion, achieves new state-of-the-art results on the challenging text guided image editing benchmark TEdBench, surpassing the previous SOTA method Imagic with Imagen, in terms of both CLIP score and LPIPS score. Codes are available at https://github.com/witcherofresearch/Forgedit.