 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Parallel Proportional Fusion of Spiking Quantum Neural Network for Optimizing Image Classification
Apr 01, 2024
The recent emergence of the hybrid quantum-classical neural network (HQCNN) architecture has garnered considerable attention due to the potential advantages associated with integrating quantum principles to enhance various facets of machine learning algorithms and computations. However, the current investigated serial structure of HQCNN, wherein information sequentially passes from one network to another, often imposes limitations on the trainability and expressivity of the network. In this study, we introduce a novel architecture termed Parallel Proportional Fusion of Quantum and Spiking Neural Networks (PPF-QSNN). The dataset information is simultaneously fed into both the spiking neural network and the variational quantum circuits, with the outputs amalgamated in proportion to their individual contributions. We systematically assess the impact of diverse PPF-QSNN parameters on network performance for image classification, aiming to identify the optimal configuration. Numerical results on the MNIST dataset unequivocally illustrate that our proposed PPF-QSNN outperforms both the existing spiking neural network and the serial quantum neural network across metrics such as accuracy, loss, and robustness. This study introduces a novel and effective amalgamation approach for HQCNN, thereby laying the groundwork for the advancement and application of quantum advantage in artificial intelligent computations.
Look-Around Before You Leap: High-Frequency Injected Transformer for Image Restoration
Mar 30, 2024Transformer-based approaches have achieved superior performance in image restoration, since they can model long-term dependencies well. However, the limitation in capturing local information restricts their capacity to remove degradations. While existing approaches attempt to mitigate this issue by incorporating convolutional operations, the core component in Transformer, i.e., self-attention, which serves as a low-pass filter, could unintentionally dilute or even eliminate the acquired local patterns. In this paper, we propose HIT, a simple yet effective High-frequency Injected Transformer for image restoration. Specifically, we design a window-wise injection module (WIM), which incorporates abundant high-frequency details into the feature map, to provide reliable references for restoring high-quality images. We also develop a bidirectional interaction module (BIM) to aggregate features at different scales using a mutually reinforced paradigm, resulting in spatially and contextually improved representations. In addition, we introduce a spatial enhancement unit (SEU) to preserve essential spatial relationships that may be lost due to the computations carried out across channel dimensions in the BIM. Extensive experiments on 9 tasks (real noise, real rain streak, raindrop, motion blur, moir\'e, shadow, snow, haze, and low-light condition) demonstrate that HIT with linear computational complexity performs favorably against the state-of-the-art methods. The source code and pre-trained models will be available at https://github.com/joshyZhou/HIT.
NeuroPictor: Refining fMRI-to-Image Reconstruction via Multi-individual Pretraining and Multi-level Modulation
Mar 27, 2024Recent fMRI-to-image approaches mainly focused on associating fMRI signals with specific conditions of pre-trained diffusion models. These approaches, while producing high-quality images, capture only a limited aspect of the complex information in fMRI signals and offer little detailed control over image creation. In contrast, this paper proposes to directly modulate the generation process of diffusion models using fMRI signals. Our approach, NeuroPictor, divides the fMRI-to-image process into three steps: i) fMRI calibrated-encoding, to tackle multi-individual pre-training for a shared latent space to minimize individual difference and enable the subsequent cross-subject training; ii) fMRI-to-image cross-subject pre-training, perceptually learning to guide diffusion model with high- and low-level conditions across different individuals; iii) fMRI-to-image single-subject refining, similar with step ii but focus on adapting to particular individual. NeuroPictor extracts high-level semantic features from fMRI signals that characterizing the visual stimulus and incrementally fine-tunes the diffusion model with a low-level manipulation network to provide precise structural instructions. By training with over 60,000 fMRI-image pairs from various individuals, our model enjoys superior fMRI-to-image decoding capacity, particularly in the within-subject setting, as evidenced in benchmark datasets. Project page: https://jingyanghuo.github.io/neuropictor/.
Multi-modal Document Presentation Attack Detection With Forensics Trace Disentanglement
Apr 10, 2024Document Presentation Attack Detection (DPAD) is an important measure in protecting the authenticity of a document image. However, recent DPAD methods demand additional resources, such as manual effort in collecting additional data or knowing the parameters of acquisition devices. This work proposes a DPAD method based on multi-modal disentangled traces (MMDT) without the above drawbacks. We first disentangle the recaptured traces by a self-supervised disentanglement and synthesis network to enhance the generalization capacity in document images with different contents and layouts. Then, unlike the existing DPAD approaches that rely only on data in the RGB domain, we propose to explicitly employ the disentangled recaptured traces as new modalities in the transformer backbone through adaptive multi-modal adapters to fuse RGB/trace features efficiently. Visualization of the disentangled traces confirms the effectiveness of the proposed method in different document contents. Extensive experiments on three benchmark datasets demonstrate the superiority of our MMDT method on representing forensic traces of recapturing distortion.
Raster Forge: Interactive Raster Manipulation Library and GUI for Python
Apr 09, 2024Raster Forge is a Python library and graphical user interface for raster data manipulation and analysis. The tool is focused on remote sensing applications, particularly in wildfire management. It allows users to import, visualize, and process raster layers for tasks such as image compositing or topographical analysis. For wildfire management, it generates fuel maps using predefined models. Its impact extends from disaster management to hydrological modeling, agriculture, and environmental monitoring. Raster Forge can be a valuable asset for geoscientists and researchers who rely on raster data analysis, enhancing geospatial data processing and visualization across various disciplines.
G-NeRF: Geometry-enhanced Novel View Synthesis from Single-View Images
Apr 11, 2024Novel view synthesis aims to generate new view images of a given view image collection. Recent attempts address this problem relying on 3D geometry priors (e.g., shapes, sizes, and positions) learned from multi-view images. However, such methods encounter the following limitations: 1) they require a set of multi-view images as training data for a specific scene (e.g., face, car or chair), which is often unavailable in many real-world scenarios; 2) they fail to extract the geometry priors from single-view images due to the lack of multi-view supervision. In this paper, we propose a Geometry-enhanced NeRF (G-NeRF), which seeks to enhance the geometry priors by a geometry-guided multi-view synthesis approach, followed by a depth-aware training. In the synthesis process, inspired that existing 3D GAN models can unconditionally synthesize high-fidelity multi-view images, we seek to adopt off-the-shelf 3D GAN models, such as EG3D, as a free source to provide geometry priors through synthesizing multi-view data. Simultaneously, to further improve the geometry quality of the synthetic data, we introduce a truncation method to effectively sample latent codes within 3D GAN models. To tackle the absence of multi-view supervision for single-view images, we design the depth-aware training approach, incorporating a depth-aware discriminator to guide geometry priors through depth maps. Experiments demonstrate the effectiveness of our method in terms of both qualitative and quantitative results.
MindSet: Vision. A toolbox for testing DNNs on key psychological experiments
Apr 08, 2024Multiple benchmarks have been developed to assess the alignment between deep neural networks (DNNs) and human vision. In almost all cases these benchmarks are observational in the sense they are composed of behavioural and brain responses to naturalistic images that have not been manipulated to test hypotheses regarding how DNNs or humans perceive and identify objects. Here we introduce the toolbox MindSet: Vision, consisting of a collection of image datasets and related scripts designed to test DNNs on 30 psychological findings. In all experimental conditions, the stimuli are systematically manipulated to test specific hypotheses regarding human visual perception and object recognition. In addition to providing pre-generated datasets of images, we provide code to regenerate these datasets, offering many configurable parameters which greatly extend the dataset versatility for different research contexts, and code to facilitate the testing of DNNs on these image datasets using three different methods (similarity judgments, out-of-distribution classification, and decoder method), accessible at https://github.com/MindSetVision/mindset-vision. We test ResNet-152 on each of these methods as an example of how the toolbox can be used.
Linear Anchored Gaussian Mixture Model for Location and Width Computation of Objects in Thick Line Shape
Apr 07, 2024An accurate detection of the centerlines of linear objects is a challenging topic in many sensitive real-world applications such X-ray imaging, remote sensing and lane marking detection in road traffic. Model-based approaches using Hough and Radon transforms are often used but, are not recommended for thick line detection, whereas approaches based on image derivatives need further step-by-step processing, making their efficiency dependent on each step outcomes. In this paper, we aim to detect linear structures found in images by considering the 3D representation of the image gray levels as a finite mixture model of statistical distribution. The latter, which we named linear anchored Gaussian distribution could be parametrized by a scale value ${\sigma}$ describing the linear structure thickness and a line equation, parametrized, in turn, by a radius ${\rho}$ and an orientation angle ${\theta}$, describing the linear structure centerline location. Expectation-Maximization (EM) algorithm is used for the mixture model parameter estimation, where a new paradigm, using the background subtraction for the likelihood function computation, is proposed. For the EM algorithm, two ${\theta}$ parameter initialization schemes are used: the first one is based on a random choice of the first component of ${\theta}$ vector, whereas the second is based on the image Hessian with a simultaneous computation of the mixture model components number. Experiments on real world images and synthetic images corrupted by blur and additive noise show the good performance of the proposed methods, where the algorithm using background subtraction and Hessian-based ${\theta}$ initialization provides an outstanding accuracy of the linear structure detection despite irregular image background and presence of blur and noise.
Unsupervised Tumor-Aware Distillation for Multi-Modal Brain Image Translation
Mar 29, 2024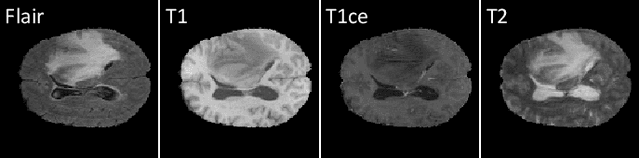
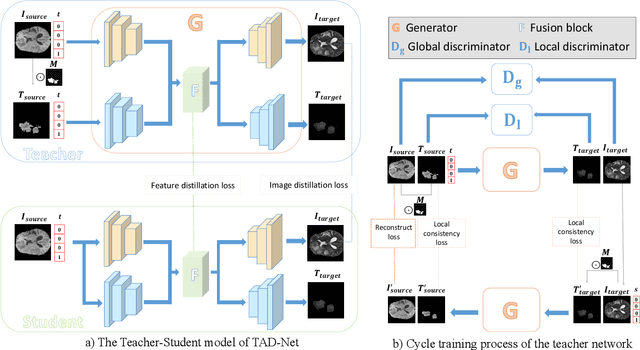
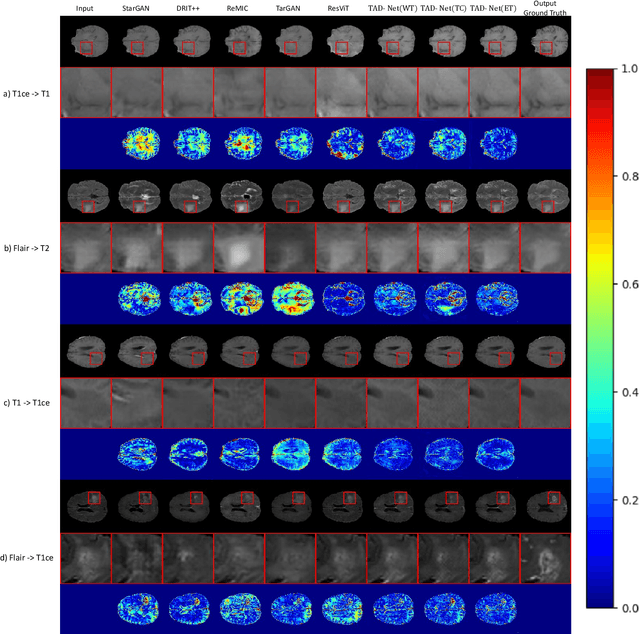

Multi-modal brain images from MRI scans are widely used in clinical diagnosis to provide complementary information from different modalities. However, obtaining fully paired multi-modal images in practice is challenging due to various factors, such as time, cost, and artifacts, resulting in modality-missing brain images. To address this problem, unsupervised multi-modal brain image translation has been extensively studied. Existing methods suffer from the problem of brain tumor deformation during translation, as they fail to focus on the tumor areas when translating the whole images. In this paper, we propose an unsupervised tumor-aware distillation teacher-student network called UTAD-Net, which is capable of perceiving and translating tumor areas precisely. Specifically, our model consists of two parts: a teacher network and a student network. The teacher network learns an end-to-end mapping from source to target modality using unpaired images and corresponding tumor masks first. Then, the translation knowledge is distilled into the student network, enabling it to generate more realistic tumor areas and whole images without masks. Experiments show that our model achieves competitive performance on both quantitative and qualitative evaluations of image quality compared with state-of-the-art methods. Furthermore, we demonstrate the effectiveness of the generated images on downstream segmentation tasks. Our code is available at https://github.com/scut-HC/UTAD-Net.
denoiSplit: a method for joint image splitting and unsupervised denoising
Mar 25, 2024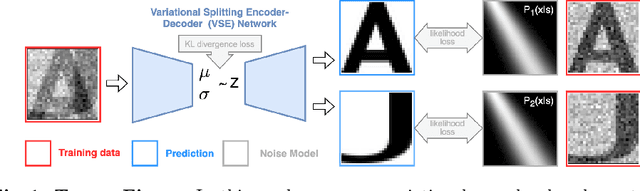
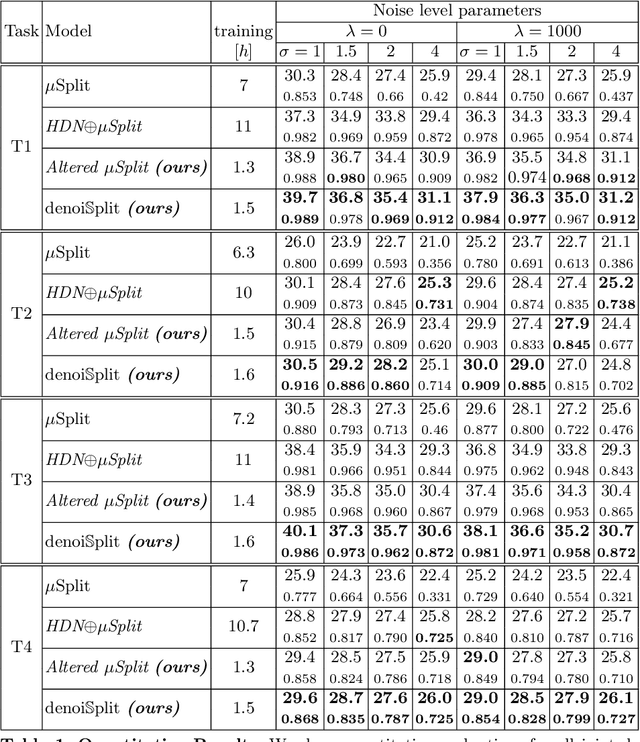
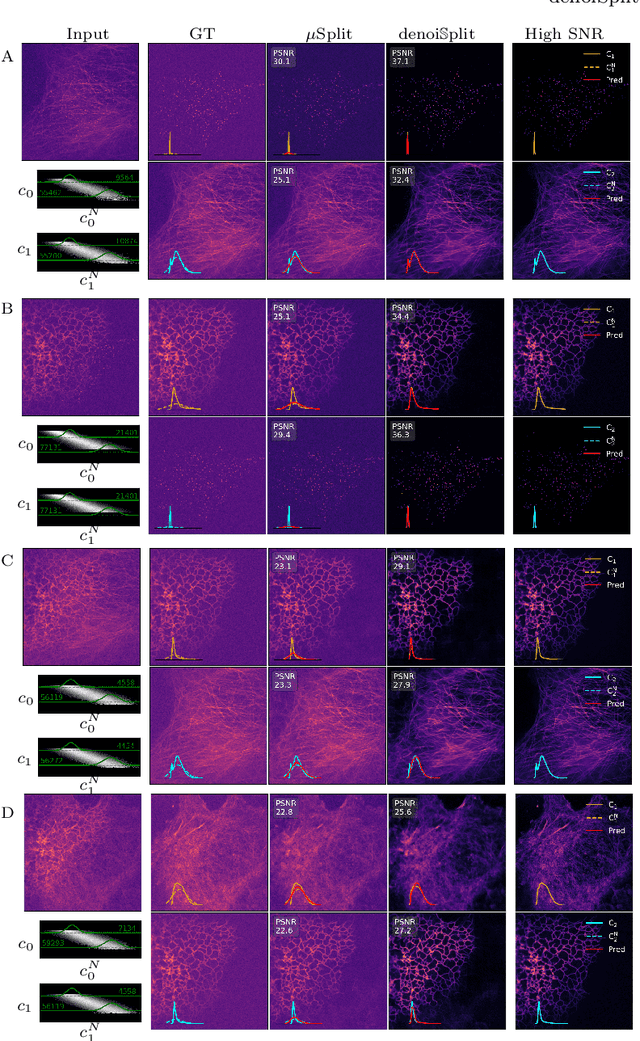
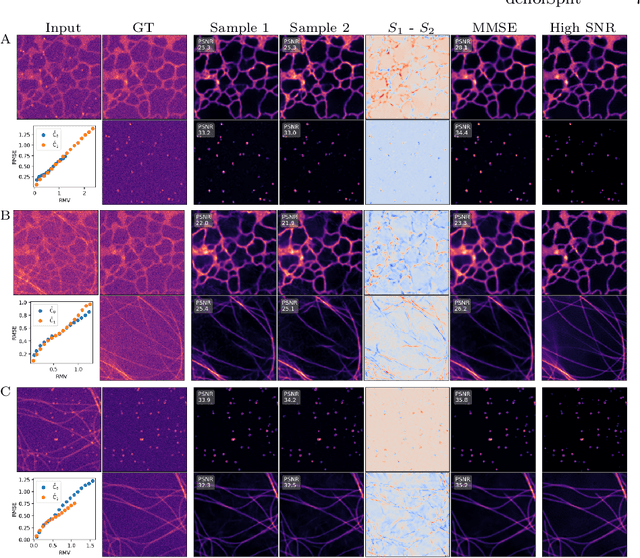
In this work we present denoiSplit, a method to tackle a new analysis task, i.e. the challenge of joint semantic image splitting and unsupervised denoising. This dual approach has important applications in fluorescence microscopy, where semantic image splitting has important applications but noise does generally hinder the downstream analysis of image content. Image splitting involves dissecting an image into its distinguishable semantic structures. We show that the current state-of-the-art method for this task struggles in the presence of image noise, inadvertently also distributing the noise across the predicted outputs. The method we present here can deal with image noise by integrating an unsupervised denoising sub-task. This integration results in improved semantic image unmixing, even in the presence of notable and realistic levels of imaging noise. A key innovation in denoiSplit is the use of specifically formulated noise models and the suitable adjustment of KL-divergence loss for the high-dimensional hierarchical latent space we are training. We showcase the performance of denoiSplit across 4 tasks on real-world microscopy images. Additionally, we perform qualitative and quantitative evaluations and compare results to existing benchmarks, demonstrating the effectiveness of using denoiSplit: a single Variational Splitting Encoder-Decoder (VSE) Network using two suitable noise models to jointly perform semantic splitting and denoising.