 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Lidar Annotation Is All You Need
Nov 08, 2023
In recent years, computer vision has transformed fields such as medical imaging, object recognition, and geospatial analytics. One of the fundamental tasks in computer vision is semantic image segmentation, which is vital for precise object delineation. Autonomous driving represents one of the key areas where computer vision algorithms are applied. The task of road surface segmentation is crucial in self-driving systems, but it requires a labor-intensive annotation process in several data domains. The work described in this paper aims to improve the efficiency of image segmentation using a convolutional neural network in a multi-sensor setup. This approach leverages lidar (Light Detection and Ranging) annotations to directly train image segmentation models on RGB images. Lidar supplements the images by emitting laser pulses and measuring reflections to provide depth information. However, lidar's sparse point clouds often create difficulties for accurate object segmentation. Segmentation of point clouds requires time-consuming preliminary data preparation and a large amount of computational resources. The key innovation of our approach is the masked loss, addressing sparse ground-truth masks from point clouds. By calculating loss exclusively where lidar points exist, the model learns road segmentation on images by using lidar points as ground truth. This approach allows for blending of different ground-truth data types during model training. Experimental validation of the approach on benchmark datasets shows comparable performance to a high-quality image segmentation model. Incorporating lidar reduces the load on annotations and enables training of image-segmentation models without loss of segmentation quality. The methodology is tested on diverse datasets, both publicly available and proprietary. The strengths and weaknesses of the proposed method are also discussed in the paper.
AnyText: Multilingual Visual Text Generation And Editing
Nov 07, 2023Diffusion model based Text-to-Image has achieved impressive achievements recently. Although current technology for synthesizing images is highly advanced and capable of generating images with high fidelity, it is still possible to give the show away when focusing on the text area in the generated image. To address this issue, we introduce AnyText, a diffusion-based multilingual visual text generation and editing model, that focuses on rendering accurate and coherent text in the image. AnyText comprises a diffusion pipeline with two primary elements: an auxiliary latent module and a text embedding module. The former uses inputs like text glyph, position, and masked image to generate latent features for text generation or editing. The latter employs an OCR model for encoding stroke data as embeddings, which blend with image caption embeddings from the tokenizer to generate texts that seamlessly integrate with the background. We employed text-control diffusion loss and text perceptual loss for training to further enhance writing accuracy. AnyText can write characters in multiple languages, to the best of our knowledge, this is the first work to address multilingual visual text generation. It is worth mentioning that AnyText can be plugged into existing diffusion models from the community for rendering or editing text accurately. After conducting extensive evaluation experiments, our method has outperformed all other approaches by a significant margin. Additionally, we contribute the first large-scale multilingual text images dataset, AnyWord-3M, containing 3 million image-text pairs with OCR annotations in multiple languages. Based on AnyWord-3M dataset, we propose AnyText-benchmark for the evaluation of visual text generation accuracy and quality. Our project will be open-sourced on https://github.com/tyxsspa/AnyText to improve and promote the development of text generation technology.
Dual-channel Prototype Network for few-shot Classification of Pathological Images
Nov 14, 2023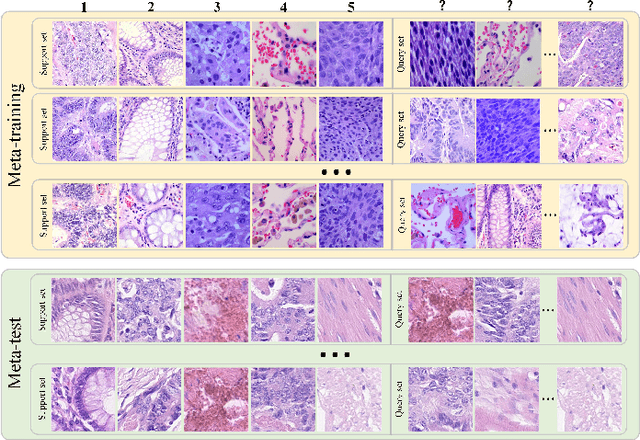
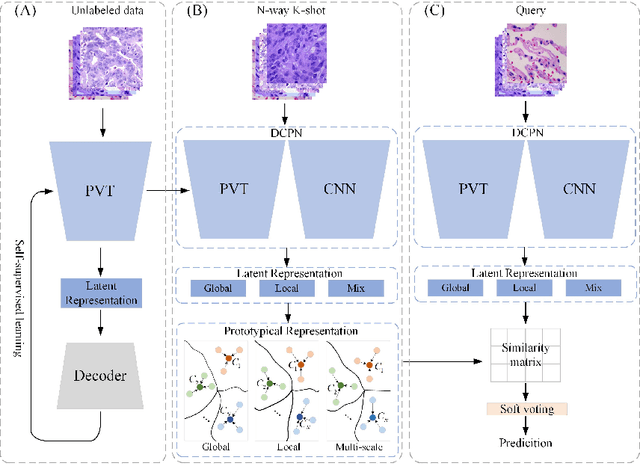
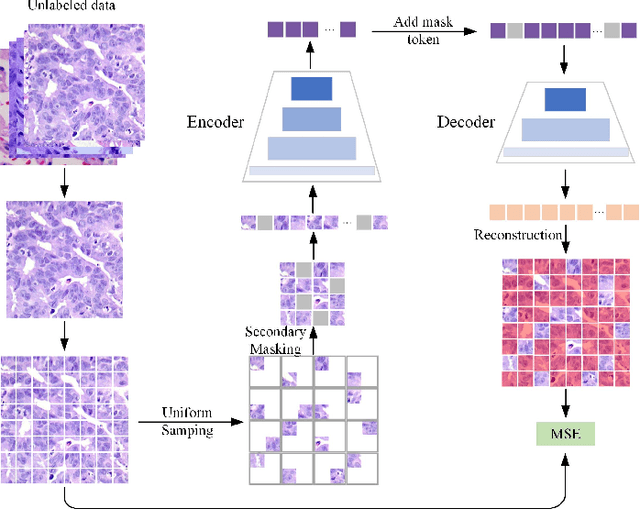
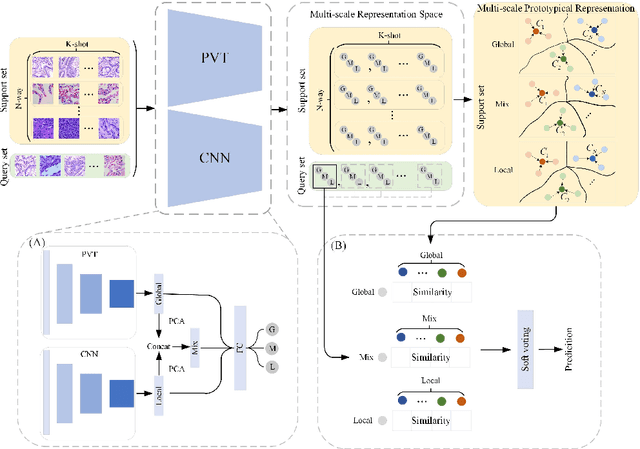
In pathology, the rarity of certain diseases and the complexity in annotating pathological images significantly hinder the creation of extensive, high-quality datasets. This limitation impedes the progress of deep learning-assisted diagnostic systems in pathology. Consequently, it becomes imperative to devise a technology that can discern new disease categories from a minimal number of annotated examples. Such a technology would substantially advance deep learning models for rare diseases. Addressing this need, we introduce the Dual-channel Prototype Network (DCPN), rooted in the few-shot learning paradigm, to tackle the challenge of classifying pathological images with limited samples. DCPN augments the Pyramid Vision Transformer (PVT) framework for few-shot classification via self-supervised learning and integrates it with convolutional neural networks. This combination forms a dual-channel architecture that extracts multi-scale, highly precise pathological features. The approach enhances the versatility of prototype representations and elevates the efficacy of prototype networks in few-shot pathological image classification tasks. We evaluated DCPN using three publicly available pathological datasets, configuring small-sample classification tasks that mirror varying degrees of clinical scenario domain shifts. Our experimental findings robustly affirm DCPN's superiority in few-shot pathological image classification, particularly in tasks within the same domain, where it achieves the benchmarks of supervised learning.
Unearthing Common Inconsistency for Generalisable Deepfake Detection
Nov 20, 2023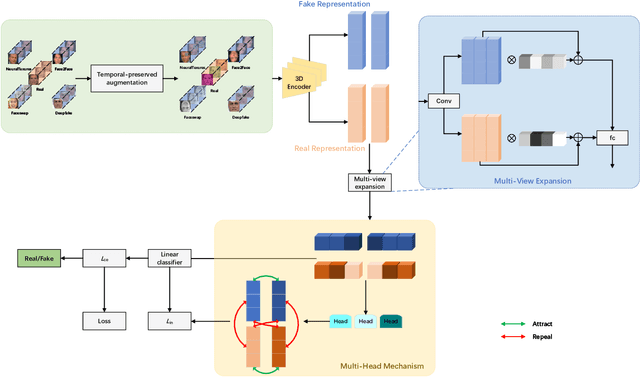
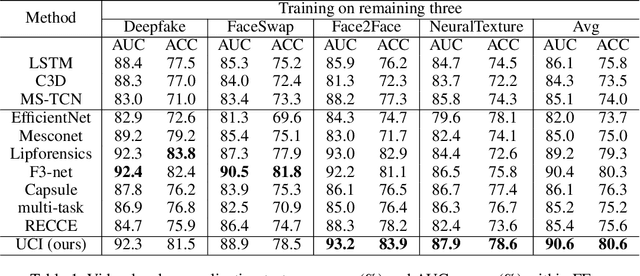
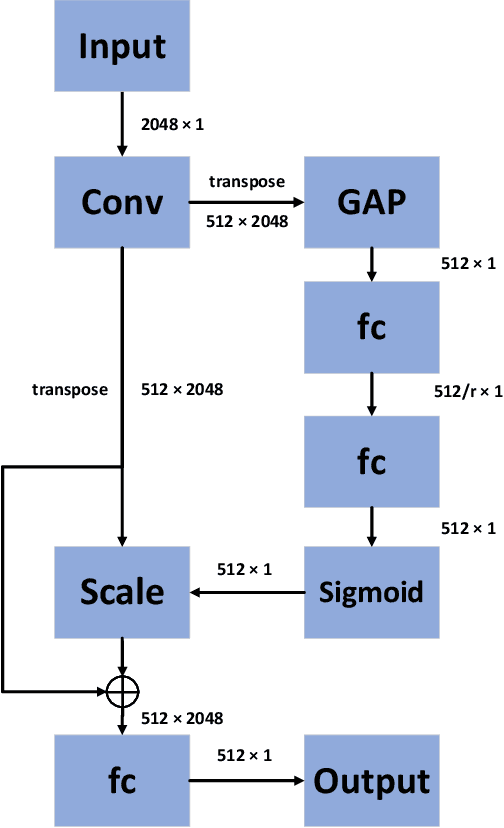
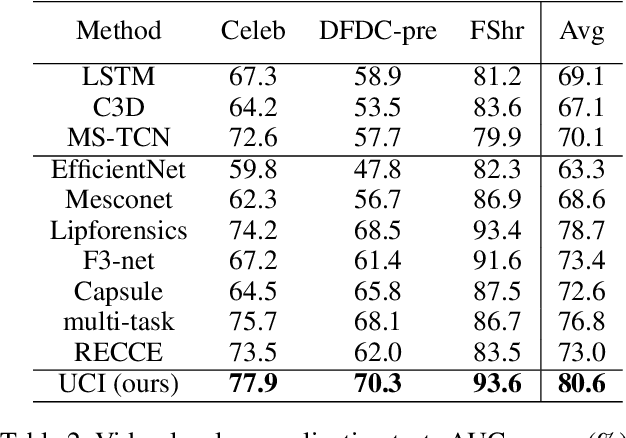
Deepfake has emerged for several years, yet efficient detection techniques could generalize over different manipulation methods require further research. While current image-level detection method fails to generalize to unseen domains, owing to the domain-shift phenomenon brought by CNN's strong inductive bias towards Deepfake texture, video-level one shows its potential to have both generalization across multiple domains and robustness to compression. We argue that although distinct face manipulation tools have different inherent bias, they all disrupt the consistency between frames, which is a natural characteristic shared by authentic videos. Inspired by this, we proposed a detection approach by capturing frame inconsistency that broadly exists in different forgery techniques, termed unearthing-common-inconsistency (UCI). Concretely, the UCI network based on self-supervised contrastive learning can better distinguish temporal consistency between real and fake videos from multiple domains. We introduced a temporally-preserved module method to introduce spatial noise perturbations, directing the model's attention towards temporal information. Subsequently, leveraging a multi-view cross-correlation learning module, we extensively learn the disparities in temporal representations between genuine and fake samples. Extensive experiments demonstrate the generalization ability of our method on unseen Deepfake domains.
OmniSeg3D: Omniversal 3D Segmentation via Hierarchical Contrastive Learning
Nov 20, 2023Towards holistic understanding of 3D scenes, a general 3D segmentation method is needed that can segment diverse objects without restrictions on object quantity or categories, while also reflecting the inherent hierarchical structure. To achieve this, we propose OmniSeg3D, an omniversal segmentation method aims for segmenting anything in 3D all at once. The key insight is to lift multi-view inconsistent 2D segmentations into a consistent 3D feature field through a hierarchical contrastive learning framework, which is accomplished by two steps. Firstly, we design a novel hierarchical representation based on category-agnostic 2D segmentations to model the multi-level relationship among pixels. Secondly, image features rendered from the 3D feature field are clustered at different levels, which can be further drawn closer or pushed apart according to the hierarchical relationship between different levels. In tackling the challenges posed by inconsistent 2D segmentations, this framework yields a global consistent 3D feature field, which further enables hierarchical segmentation, multi-object selection, and global discretization. Extensive experiments demonstrate the effectiveness of our method on high-quality 3D segmentation and accurate hierarchical structure understanding. A graphical user interface further facilitates flexible interaction for omniversal 3D segmentation.
A Good Feature Extractor Is All You Need for Weakly Supervised Learning in Histopathology
Nov 20, 2023Deep learning is revolutionising pathology, offering novel opportunities in disease prognosis and personalised treatment. Historically, stain normalisation has been a crucial preprocessing step in computational pathology pipelines, and persists into the deep learning era. Yet, with the emergence of feature extractors trained using self-supervised learning (SSL) on diverse pathology datasets, we call this practice into question. In an empirical evaluation of publicly available feature extractors, we find that omitting stain normalisation and image augmentations does not compromise downstream performance, while incurring substantial savings in memory and compute. Further, we show that the top-performing feature extractors are remarkably robust to variations in stain and augmentations like rotation in their latent space. Contrary to previous patch-level benchmarking studies, our approach emphasises clinical relevance by focusing on slide-level prediction tasks in a weakly supervised setting with external validation cohorts. This work represents the most comprehensive robustness evaluation of public pathology SSL feature extractors to date, involving more than 6,000 training runs across nine tasks, five datasets, three downstream architectures, and various preprocessing setups. Our findings stand to streamline digital pathology workflows by minimising preprocessing needs and informing the selection of feature extractors.
Counterfactual Explanation for Regression via Disentanglement in Latent Space
Nov 23, 2023Counterfactual Explanations (CEs) help address the question: How can the factors that influence the prediction of a predictive model be changed to achieve a more favorable outcome from a user's perspective? Thus, they bear the potential to guide the user's interaction with AI systems since they represent easy-to-understand explanations. To be applicable, CEs need to be realistic and actionable. In the literature, various methods have been proposed to generate CEs. However, the majority of research on CEs focuses on classification problems where questions like "What should I do to get my rejected loan approved?" are raised. In practice, answering questions like "What should I do to increase my salary?" are of a more regressive nature. In this paper, we introduce a novel method to generate CEs for a pre-trained regressor by first disentangling the label-relevant from the label-irrelevant dimensions in the latent space. CEs are then generated by combining the label-irrelevant dimensions and the predefined output. The intuition behind this approach is that the ideal counterfactual search should focus on the label-irrelevant characteristics of the input and suggest changes toward target-relevant characteristics. Searching in the latent space could help achieve this goal. We show that our method maintains the characteristics of the query sample during the counterfactual search. In various experiments, we demonstrate that the proposed method is competitive based on different quality measures on image and tabular datasets in regression problem settings. It efficiently returns results closer to the original data manifold compared to three state-of-the-art methods, which is essential for realistic high-dimensional machine learning applications. Our code will be made available as an open-source package upon the publication of this work.
Image Generation and Learning Strategy for Deep Document Forgery Detection
Nov 07, 2023
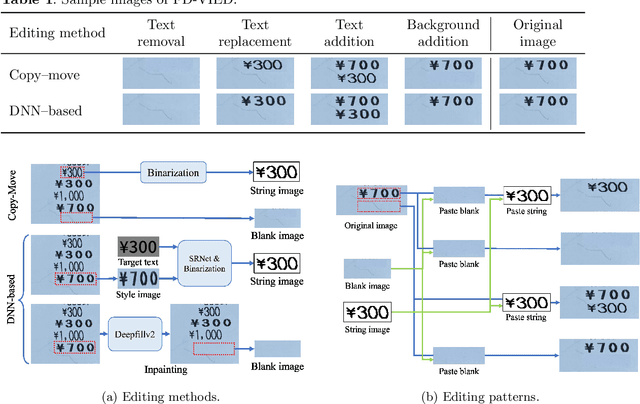

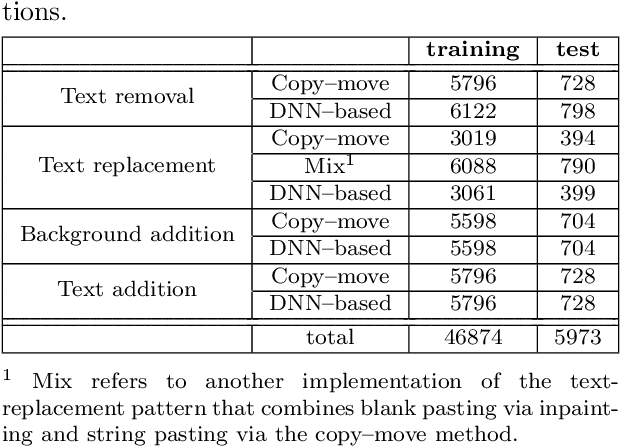
In recent years, document processing has flourished and brought numerous benefits. However, there has been a significant rise in reported cases of forged document images. Specifically, recent advancements in deep neural network (DNN) methods for generative tasks may amplify the threat of document forgery. Traditional approaches for forged document images created by prevalent copy-move methods are unsuitable against those created by DNN-based methods, as we have verified. To address this issue, we construct a training dataset of document forgery images, named FD-VIED, by emulating possible attacks, such as text addition, removal, and replacement with recent DNN-methods. Additionally, we introduce an effective pre-training approach through self-supervised learning with both natural images and document images. In our experiments, we demonstrate that our approach enhances detection performance.
Image-Pointcloud Fusion based Anomaly Detection using PD-REAL Dataset
Nov 07, 2023We present PD-REAL, a novel large-scale dataset for unsupervised anomaly detection (AD) in the 3D domain. It is motivated by the fact that 2D-only representations in the AD task may fail to capture the geometric structures of anomalies due to uncertainty in lighting conditions or shooting angles. PD-REAL consists entirely of Play-Doh models for 15 object categories and focuses on the analysis of potential benefits from 3D information in a controlled environment. Specifically, objects are first created with six types of anomalies, such as dent, crack, or perforation, and then photographed under different lighting conditions to mimic real-world inspection scenarios. To demonstrate the usefulness of 3D information, we use a commercially available RealSense camera to capture RGB and depth images. Compared to the existing 3D dataset for AD tasks, the data acquisition of PD-REAL is significantly cheaper, easily scalable and easier to control variables. Extensive evaluations with state-of-the-art AD algorithms on our dataset demonstrate the benefits as well as challenges of using 3D information. Our dataset can be downloaded from https://github.com/Andy-cs008/PD-REAL
LCM-LoRA: A Universal Stable-Diffusion Acceleration Module
Nov 09, 2023Latent Consistency Models (LCMs) have achieved impressive performance in accelerating text-to-image generative tasks, producing high-quality images with minimal inference steps. LCMs are distilled from pre-trained latent diffusion models (LDMs), requiring only ~32 A100 GPU training hours. This report further extends LCMs' potential in two aspects: First, by applying LoRA distillation to Stable-Diffusion models including SD-V1.5, SSD-1B, and SDXL, we have expanded LCM's scope to larger models with significantly less memory consumption, achieving superior image generation quality. Second, we identify the LoRA parameters obtained through LCM distillation as a universal Stable-Diffusion acceleration module, named LCM-LoRA. LCM-LoRA can be directly plugged into various Stable-Diffusion fine-tuned models or LoRAs without training, thus representing a universally applicable accelerator for diverse image generation tasks. Compared with previous numerical PF-ODE solvers such as DDIM, DPM-Solver, LCM-LoRA can be viewed as a plug-in neural PF-ODE solver that possesses strong generalization abilities. Project page: https://github.com/luosiallen/latent-consistency-model.