 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
AdaFuse: Adaptive Medical Image Fusion Based on Spatial-Frequential Cross Attention
Oct 09, 2023
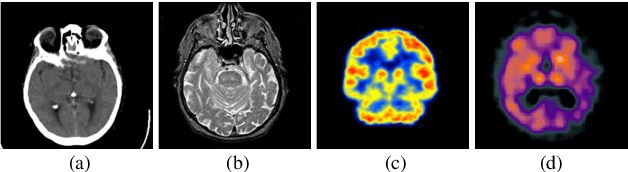
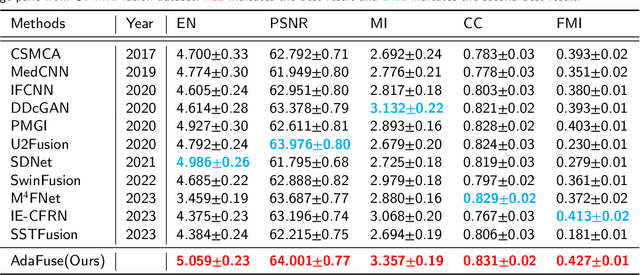
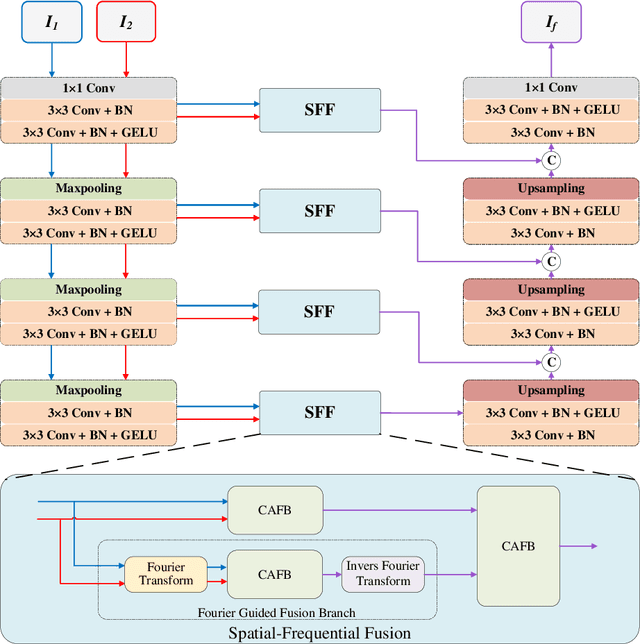
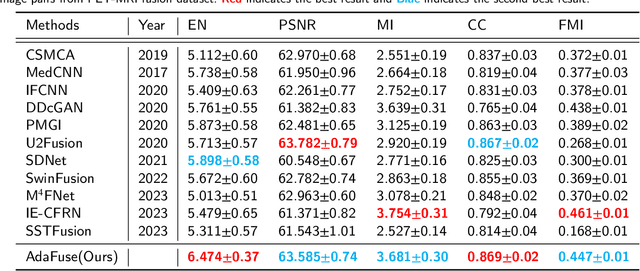
Multi-modal medical image fusion is essential for the precise clinical diagnosis and surgical navigation since it can merge the complementary information in multi-modalities into a single image. The quality of the fused image depends on the extracted single modality features as well as the fusion rules for multi-modal information. Existing deep learning-based fusion methods can fully exploit the semantic features of each modality, they cannot distinguish the effective low and high frequency information of each modality and fuse them adaptively. To address this issue, we propose AdaFuse, in which multimodal image information is fused adaptively through frequency-guided attention mechanism based on Fourier transform. Specifically, we propose the cross-attention fusion (CAF) block, which adaptively fuses features of two modalities in the spatial and frequency domains by exchanging key and query values, and then calculates the cross-attention scores between the spatial and frequency features to further guide the spatial-frequential information fusion. The CAF block enhances the high-frequency features of the different modalities so that the details in the fused images can be retained. Moreover, we design a novel loss function composed of structure loss and content loss to preserve both low and high frequency information. Extensive comparison experiments on several datasets demonstrate that the proposed method outperforms state-of-the-art methods in terms of both visual quality and quantitative metrics. The ablation experiments also validate the effectiveness of the proposed loss and fusion strategy. Our code is publicly available at https://github.com/xianming-gu/AdaFuse.
ICU: Conquering Language Barriers in Vision-and-Language Modeling by Dividing the Tasks into Image Captioning and Language Understanding
Oct 20, 2023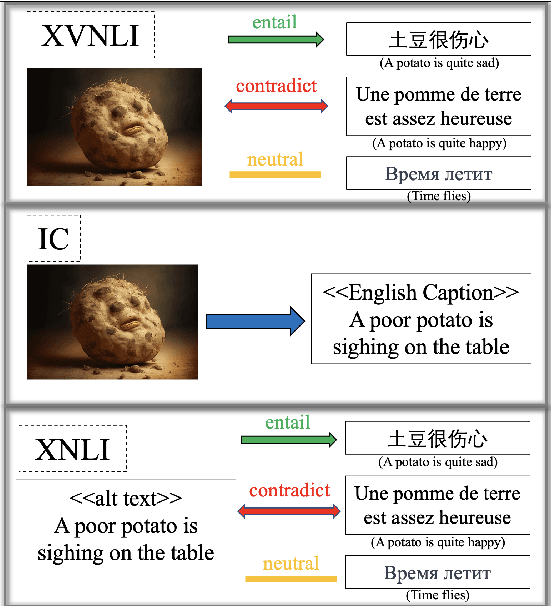

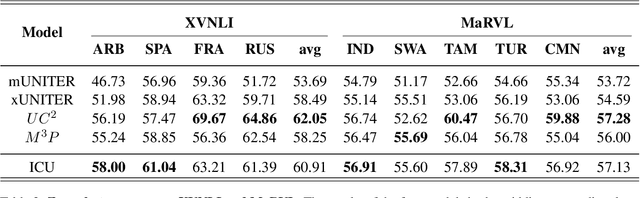
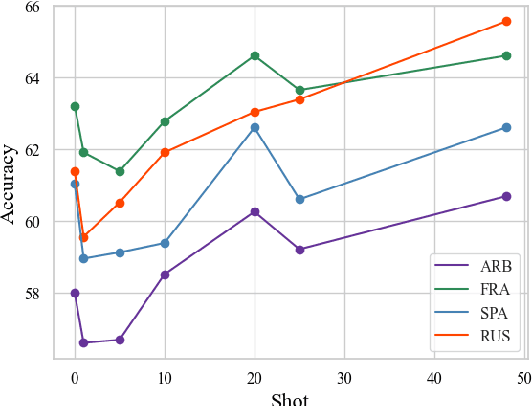
Most multilingual vision-and-language (V&L) research aims to accomplish multilingual and multimodal capabilities within one model. However, the scarcity of multilingual captions for images has hindered the development. To overcome this obstacle, we propose ICU, Image Caption Understanding, which divides a V&L task into two stages: a V&L model performs image captioning in English, and a multilingual language model (mLM), in turn, takes the caption as the alt text and performs crosslingual language understanding. The burden of multilingual processing is lifted off V&L model and placed on mLM. Since the multilingual text data is relatively of higher abundance and quality, ICU can facilitate the conquering of language barriers for V&L models. In experiments on two tasks across 9 languages in the IGLUE benchmark, we show that ICU can achieve new state-of-the-art results for five languages, and comparable results for the rest.
Investigating Weight-Perturbed Deep Neural Networks With Application in Iris Presentation Attack Detection
Nov 21, 2023Deep neural networks (DNNs) exhibit superior performance in various machine learning tasks, e.g., image classification, speech recognition, biometric recognition, object detection, etc. However, it is essential to analyze their sensitivity to parameter perturbations before deploying them in real-world applications. In this work, we assess the sensitivity of DNNs against perturbations to their weight and bias parameters. The sensitivity analysis involves three DNN architectures (VGG, ResNet, and DenseNet), three types of parameter perturbations (Gaussian noise, weight zeroing, and weight scaling), and two settings (entire network and layer-wise). We perform experiments in the context of iris presentation attack detection and evaluate on two publicly available datasets: LivDet-Iris-2017 and LivDet-Iris-2020. Based on the sensitivity analysis, we propose improved models simply by perturbing parameters of the network without undergoing training. We further combine these perturbed models at the score-level and at the parameter-level to improve the performance over the original model. The ensemble at the parameter-level shows an average improvement of 43.58% on the LivDet-Iris-2017 dataset and 9.25% on the LivDet-Iris-2020 dataset. The source code is available at \href{https://github.com/redwankarimsony/WeightPerturbation-MSU}{https://github.com/redwankarimsony/WeightPerturbation-MSU}.
Attacking Motion Planners Using Adversarial Perception Errors
Nov 21, 2023Autonomous driving (AD) systems are often built and tested in a modular fashion, where the performance of different modules is measured using task-specific metrics. These metrics should be chosen so as to capture the downstream impact of each module and the performance of the system as a whole. For example, high perception quality should enable prediction and planning to be performed safely. Even though this is true in general, we show here that it is possible to construct planner inputs that score very highly on various perception quality metrics but still lead to planning failures. In an analogy to adversarial attacks on image classifiers, we call such inputs \textbf{adversarial perception errors} and show they can be systematically constructed using a simple boundary-attack algorithm. We demonstrate the effectiveness of this algorithm by finding attacks for two different black-box planners in several urban and highway driving scenarios using the CARLA simulator. Finally, we analyse the properties of these attacks and show that they are isolated in the input space of the planner, and discuss their implications for AD system deployment and testing.
Attention Deficit is Ordered! Fooling Deformable Vision Transformers with Collaborative Adversarial Patches
Nov 21, 2023The latest generation of transformer-based vision models have proven to be superior to Convolutional Neural Network (CNN)-based models across several vision tasks, largely attributed to their remarkable prowess in relation modeling. Deformable vision transformers significantly reduce the quadratic complexity of modeling attention by using sparse attention structures, enabling them to be used in larger scale applications such as multi-view vision systems. Recent work demonstrated adversarial attacks against transformers; we show that these attacks do not transfer to deformable transformers due to their sparse attention structure. Specifically, attention in deformable transformers is modeled using pointers to the most relevant other tokens. In this work, we contribute for the first time adversarial attacks that manipulate the attention of deformable transformers, distracting them to focus on irrelevant parts of the image. We also develop new collaborative attacks where a source patch manipulates attention to point to a target patch that adversarially attacks the system. In our experiments, we find that only 1% patched area of the input field can lead to 0% AP. We also show that the attacks provide substantial versatility to support different attacker scenarios because of their ability to redirect attention under the attacker control.
Simple but Effective Unsupervised Classification for Specified Domain Images: A Case Study on Fungi Images
Nov 15, 2023High-quality labeled datasets are essential for deep learning. Traditional manual annotation methods are not only costly and inefficient but also pose challenges in specialized domains where expert knowledge is needed. Self-supervised methods, despite leveraging unlabeled data for feature extraction, still require hundreds or thousands of labeled instances to guide the model for effective specialized image classification. Current unsupervised learning methods offer automatic classification without prior annotation but often compromise on accuracy. As a result, efficiently procuring high-quality labeled datasets remains a pressing challenge for specialized domain images devoid of annotated data. Addressing this, an unsupervised classification method with three key ideas is introduced: 1) dual-step feature dimensionality reduction using a pre-trained model and manifold learning, 2) a voting mechanism from multiple clustering algorithms, and 3) post-hoc instead of prior manual annotation. This approach outperforms supervised methods in classification accuracy, as demonstrated with fungal image data, achieving 94.1% and 96.7% on public and private datasets respectively. The proposed unsupervised classification method reduces dependency on pre-annotated datasets, enabling a closed-loop for data classification. The simplicity and ease of use of this method will also bring convenience to researchers in various fields in building datasets, promoting AI applications for images in specialized domains.
Multiple-Question Multiple-Answer Text-VQA
Nov 15, 2023We present Multiple-Question Multiple-Answer (MQMA), a novel approach to do text-VQA in encoder-decoder transformer models. The text-VQA task requires a model to answer a question by understanding multi-modal content: text (typically from OCR) and an associated image. To the best of our knowledge, almost all previous approaches for text-VQA process a single question and its associated content to predict a single answer. In order to answer multiple questions from the same image, each question and content are fed into the model multiple times. In contrast, our proposed MQMA approach takes multiple questions and content as input at the encoder and predicts multiple answers at the decoder in an auto-regressive manner at the same time. We make several novel architectural modifications to standard encoder-decoder transformers to support MQMA. We also propose a novel MQMA denoising pre-training task which is designed to teach the model to align and delineate multiple questions and content with associated answers. MQMA pre-trained model achieves state-of-the-art results on multiple text-VQA datasets, each with strong baselines. Specifically, on OCR-VQA (+2.5%), TextVQA (+1.4%), ST-VQA (+0.6%), DocVQA (+1.1%) absolute improvements over the previous state-of-the-art approaches.
L-WaveBlock: A Novel Feature Extractor Leveraging Wavelets for Generative Adversarial Networks
Nov 09, 2023Generative Adversarial Networks (GANs) have risen to prominence in the field of deep learning, facilitating the generation of realistic data from random noise. The effectiveness of GANs often depends on the quality of feature extraction, a critical aspect of their architecture. This paper introduces L-WaveBlock, a novel and robust feature extractor that leverages the capabilities of the Discrete Wavelet Transform (DWT) with deep learning methodologies. L-WaveBlock is catered to quicken the convergence of GAN generators while simultaneously enhancing their performance. The paper demonstrates the remarkable utility of L-WaveBlock across three datasets, a road satellite imagery dataset, the CelebA dataset and the GoPro dataset, showcasing its ability to ease feature extraction and make it more efficient. By utilizing DWT, L-WaveBlock efficiently captures the intricate details of both structural and textural details, and further partitions feature maps into orthogonal subbands across multiple scales while preserving essential information at the same time. Not only does it lead to faster convergence, but also gives competent results on every dataset by employing the L-WaveBlock. The proposed method achieves an Inception Score of 3.6959 and a Structural Similarity Index of 0.4261 on the maps dataset, a Peak Signal-to-Noise Ratio of 29.05 and a Structural Similarity Index of 0.874 on the CelebA dataset. The proposed method performs competently to the state-of-the-art for the image denoising dataset, albeit not better, but still leads to faster convergence than conventional methods. With this, L-WaveBlock emerges as a robust and efficient tool for enhancing GAN-based image generation, demonstrating superior convergence speed and competitive performance across multiple datasets for image resolution, image generation and image denoising.
SemST: Semantically Consistent Multi-Scale Image Translation via Structure-Texture Alignment
Oct 08, 2023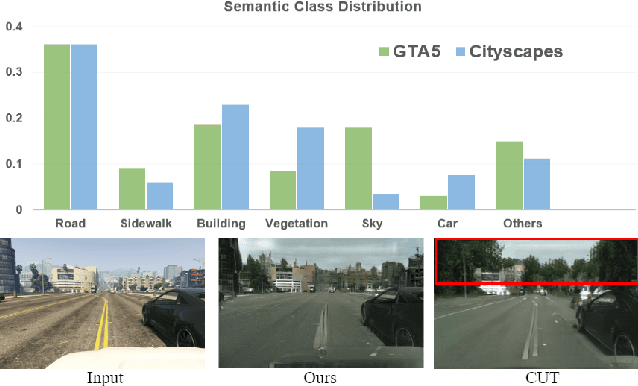
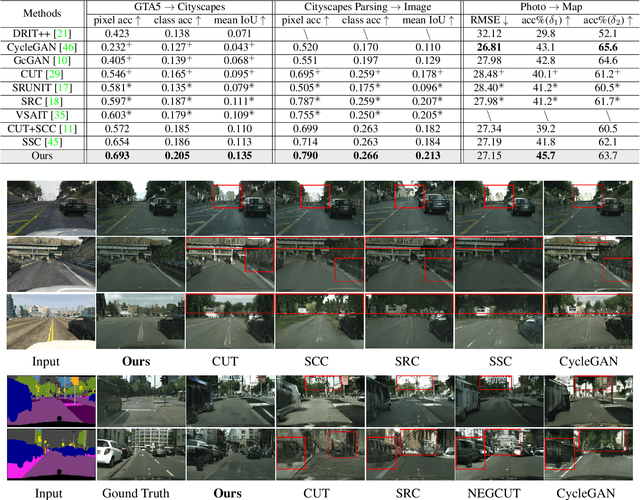
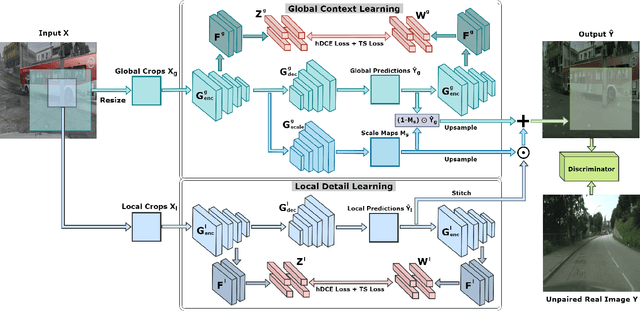
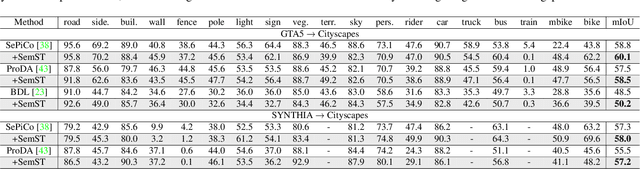
Unsupervised image-to-image (I2I) translation learns cross-domain image mapping that transfers input from the source domain to output in the target domain while preserving its semantics. One challenge is that different semantic statistics in source and target domains result in content discrepancy known as semantic distortion. To address this problem, a novel I2I method that maintains semantic consistency in translation is proposed and named SemST in this work. SemST reduces semantic distortion by employing contrastive learning and aligning the structural and textural properties of input and output by maximizing their mutual information. Furthermore, a multi-scale approach is introduced to enhance translation performance, thereby enabling the applicability of SemST to domain adaptation in high-resolution images. Experiments show that SemST effectively mitigates semantic distortion and achieves state-of-the-art performance. Also, the application of SemST to domain adaptation (DA) is explored. It is demonstrated by preliminary experiments that SemST can be utilized as a beneficial pre-training for the semantic segmentation task.
Mitigating Exposure Bias in Discriminator Guided Diffusion Models
Nov 18, 2023Diffusion Models have demonstrated remarkable performance in image generation. However, their demanding computational requirements for training have prompted ongoing efforts to enhance the quality of generated images through modifications in the sampling process. A recent approach, known as Discriminator Guidance, seeks to bridge the gap between the model score and the data score by incorporating an auxiliary term, derived from a discriminator network. We show that despite significantly improving sample quality, this technique has not resolved the persistent issue of Exposure Bias and we propose SEDM-G++, which incorporates a modified sampling approach, combining Discriminator Guidance and Epsilon Scaling. Our proposed approach outperforms the current state-of-the-art, by achieving an FID score of 1.73 on the unconditional CIFAR-10 dataset.