 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
One-Shot Federated Learning with Classifier-Guided Diffusion Models
Nov 16, 2023
One-shot federated learning (OSFL) has gained attention in recent years due to its low communication cost. However, most of the existing methods require auxiliary datasets or training generators, which hinders their practicality in real-world scenarios. In this paper, we explore the novel opportunities that diffusion models bring to OSFL and propose FedCADO, utilizing guidance from client classifiers to generate data that complies with clients' distributions and subsequently training the aggregated model on the server. Specifically, our method involves targeted optimizations in two aspects. On one hand, we conditionally edit the randomly sampled initial noises, embedding them with specified semantics and distributions, resulting in a significant improvement in both the quality and stability of generation. On the other hand, we employ the BN statistics from the classifiers to provide detailed guidance during generation. These tailored optimizations enable us to limitlessly generate datasets, which closely resemble the distribution and quality of the original client dataset. Our method effectively handles the heterogeneous client models and the problems of non-IID features or labels. In terms of privacy protection, our method avoids training any generator or transferring any auxiliary information on clients, eliminating any additional privacy leakage risks. Leveraging the extensive knowledge stored in the pre-trained diffusion model, the synthetic datasets can assist us in surpassing the knowledge limitations of the client samples, resulting in aggregation models that even outperform the performance ceiling of centralized training in some cases, which is convincingly demonstrated in the sufficient quantification and visualization experiments conducted on three large-scale multi-domain image datasets.
Structural-Based Uncertainty in Deep Learning Across Anatomical Scales: Analysis in White Matter Lesion Segmentation
Nov 15, 2023This paper explores uncertainty quantification (UQ) as an indicator of the trustworthiness of automated deep-learning (DL) tools in the context of white matter lesion (WML) segmentation from magnetic resonance imaging (MRI) scans of multiple sclerosis (MS) patients. Our study focuses on two principal aspects of uncertainty in structured output segmentation tasks. Firstly, we postulate that a good uncertainty measure should indicate predictions likely to be incorrect with high uncertainty values. Second, we investigate the merit of quantifying uncertainty at different anatomical scales (voxel, lesion, or patient). We hypothesize that uncertainty at each scale is related to specific types of errors. Our study aims to confirm this relationship by conducting separate analyses for in-domain and out-of-domain settings. Our primary methodological contributions are (i) the development of novel measures for quantifying uncertainty at lesion and patient scales, derived from structural prediction discrepancies, and (ii) the extension of an error retention curve analysis framework to facilitate the evaluation of UQ performance at both lesion and patient scales. The results from a multi-centric MRI dataset of 172 patients demonstrate that our proposed measures more effectively capture model errors at the lesion and patient scales compared to measures that average voxel-scale uncertainty values. We provide the UQ protocols code at https://github.com/Medical-Image-Analysis-Laboratory/MS_WML_uncs.
$H$-RANSAC, an algorithmic variant for Homography image transform from featureless point sets: application to video-based football analytics
Oct 07, 2023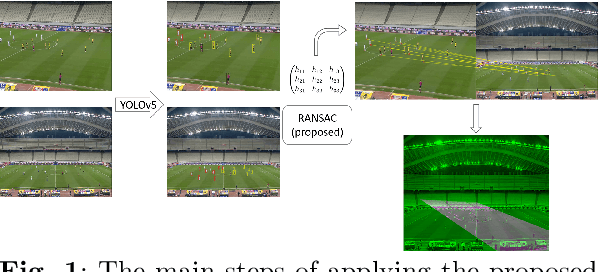
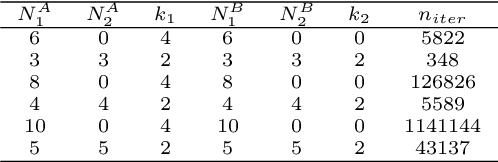
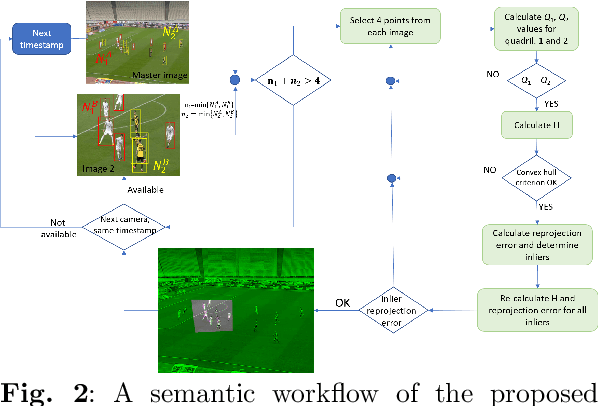
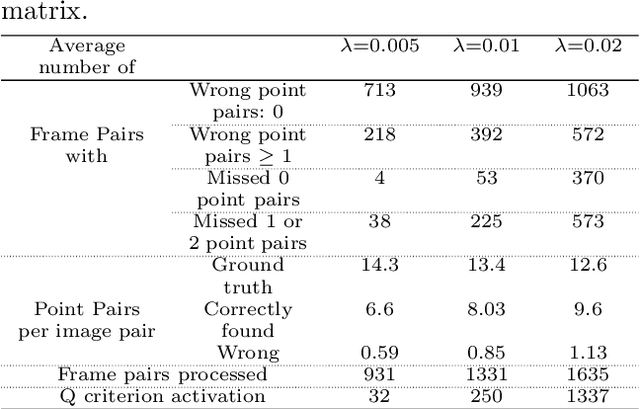
Estimating homography matrix between two images has various applications like image stitching or image mosaicing and spatial information retrieval from multiple camera views, but has been proved to be a complicated problem, especially in cases of radically different camera poses and zoom factors. Many relevant approaches have been proposed, utilizing direct feature based, or deep learning methodologies. In this paper, we propose a generalized RANSAC algorithm, H-RANSAC, to retrieve homography image transformations from sets of points without descriptive local feature vectors and point pairing. We allow the points to be optionally labelled in two classes. We propose a robust criterion that rejects implausible point selection before each iteration of RANSAC, based on the type of the quadrilaterals formed by random point pair selection (convex or concave and (non)-self-intersecting). A similar post-hoc criterion rejects implausible homography transformations is included at the end of each iteration. The expected maximum iterations of $H$-RANSAC are derived for different probabilities of success, according to the number of points per image and per class, and the percentage of outliers. The proposed methodology is tested on a large dataset of images acquired by 12 cameras during real football matches, where radically different views at each timestamp are to be matched. Comparisons with state-of-the-art implementations of RANSAC combined with classic and deep learning image salient point detection indicates the superiority of the proposed $H$-RANSAC, in terms of average reprojection error and number of successfully processed pairs of frames, rendering it the method of choice in cases of image homography alignment with few tens of points, while local features are not available, or not descriptive enough. The implementation of $H$-RANSAC is available in https://github.com/gnousias/H-RANSAC
BID-NeRF: RGB-D image pose estimation with inverted Neural Radiance Fields
Oct 05, 2023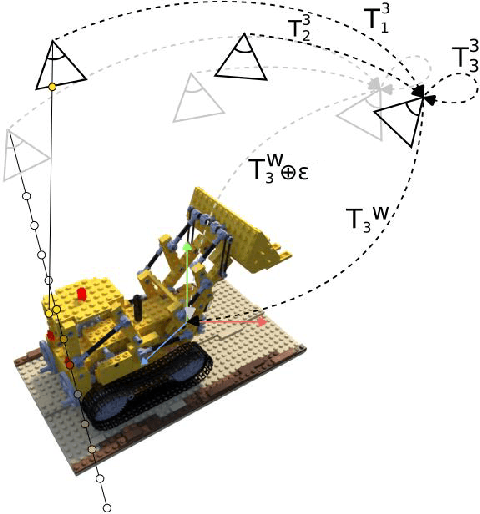

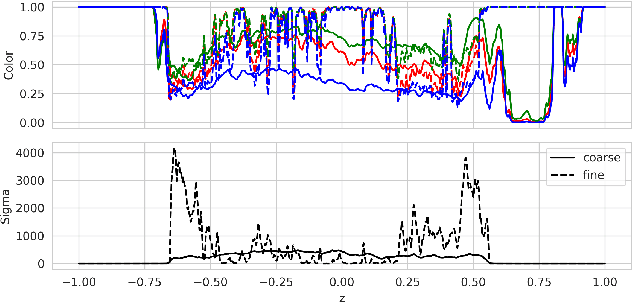
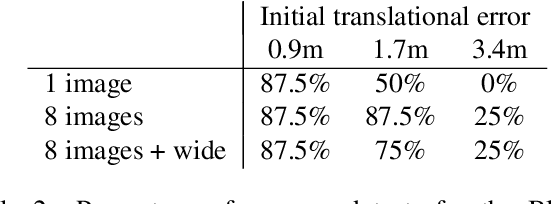
We aim to improve the Inverted Neural Radiance Fields (iNeRF) algorithm which defines the image pose estimation problem as a NeRF based iterative linear optimization. NeRFs are novel neural space representation models that can synthesize photorealistic novel views of real-world scenes or objects. Our contributions are as follows: we extend the localization optimization objective with a depth-based loss function, we introduce a multi-image based loss function where a sequence of images with known relative poses are used without increasing the computational complexity, we omit hierarchical sampling during volumetric rendering, meaning only the coarse model is used for pose estimation, and we how that by extending the sampling interval convergence can be achieved even or higher initial pose estimate errors. With the proposed modifications the convergence speed is significantly improved, and the basin of convergence is substantially extended.
CPIPS: Learning to Preserve Perceptual Distances in End-to-End Image Compression
Oct 01, 2023Lossy image coding standards such as JPEG and MPEG have successfully achieved high compression rates for human consumption of multimedia data. However, with the increasing prevalence of IoT devices, drones, and self-driving cars, machines rather than humans are processing a greater portion of captured visual content. Consequently, it is crucial to pursue an efficient compressed representation that caters not only to human vision but also to image processing and machine vision tasks. Drawing inspiration from the efficient coding hypothesis in biological systems and the modeling of the sensory cortex in neural science, we repurpose the compressed latent representation to prioritize semantic relevance while preserving perceptual distance. Our proposed method, Compressed Perceptual Image Patch Similarity (CPIPS), can be derived at a minimal cost from a learned neural codec and computed significantly faster than DNN-based perceptual metrics such as LPIPS and DISTS.
IAIFNet: An Illumination-Aware Infrared and Visible Image Fusion Network
Sep 26, 2023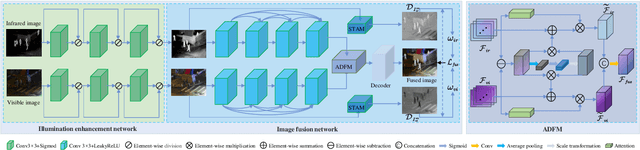

Infrared and visible image fusion (IVIF) is used to generate fusion images with comprehensive features of both images, which is beneficial for downstream vision tasks. However, current methods rarely consider the illumination condition in low-light environments, and the targets in the fused images are often not prominent. To address the above issues, we propose an Illumination-Aware Infrared and Visible Image Fusion Network, named as IAIFNet. In our framework, an illumination enhancement network first estimates the incident illumination maps of input images. Afterwards, with the help of proposed adaptive differential fusion module (ADFM) and salient target aware module (STAM), an image fusion network effectively integrates the salient features of the illumination-enhanced infrared and visible images into a fusion image of high visual quality. Extensive experimental results verify that our method outperforms five state-of-the-art methods of fusing infrared and visible images.
Leveraging Cutting Edge Deep Learning Based Image Matching for Reconstructing a Large Scene from Sparse Images
Oct 02, 2023We present the top ranked solution for the AISG-SLA Visual Localisation Challenge benchmark (IJCAI 2023), where the task is to estimate relative motion between images taken in sequence by a camera mounted on a car driving through an urban scene. For matching images we use our recent deep learning based matcher RoMa. Matching image pairs sequentially and estimating relative motion from point correspondences sampled by RoMa already gives very competitive results -- third rank on the challenge benchmark. To improve the estimations we extract keypoints in the images, match them using RoMa, and perform structure from motion reconstruction using COLMAP. We choose our recent DeDoDe keypoints for their high repeatability. Further, we address time jumps in the image sequence by matching specific non-consecutive image pairs based on image retrieval with DINOv2. These improvements yield a solution beating all competitors. We further present a loose upper bound on the accuracy obtainable by the image retrieval approach by also matching hand-picked non-consecutive pairs.
Single Image Test-Time Adaptation for Segmentation
Sep 25, 2023Test-Time Adaptation (TTA) methods improve the robustness of deep neural networks to domain shift on a variety of tasks such as image classification or segmentation. This work explores adapting segmentation models to a single unlabelled image with no other data available at test-time. In particular, this work focuses on adaptation by optimizing self-supervised losses at test-time. Multiple baselines based on different principles are evaluated under diverse conditions and a novel adversarial training is introduced for adaptation with mask refinement. Our additions to the baselines result in a 3.51 and 3.28 % increase over non-adapted baselines, without these improvements, the increase would be 1.7 and 2.16 % only.
To See is to Believe: Prompting GPT-4V for Better Visual Instruction Tuning
Nov 13, 2023Existing visual instruction tuning methods typically prompt large language models with textual descriptions to generate instruction-following data. Despite the promising performance achieved, these descriptions are derived from image annotations, which are oftentimes coarse-grained. Furthermore, the instructions might even contradict the visual content without observing the entire visual context. To address this challenge, we introduce a fine-grained visual instruction dataset, LVIS-Instruct4V, which contains 220K visually aligned and context-aware instructions produced by prompting the powerful GPT-4V with images from LVIS. Through experimental validation and case studies, we demonstrate that high-quality visual instructional data could improve the performance of LLaVA-1.5, a state-of-the-art large multimodal model, across a wide spectrum of benchmarks by clear margins. Notably, by simply replacing the LLaVA-Instruct with our LVIS-Instruct4V, we achieve better results than LLaVA on most challenging LMM benchmarks, e.g., LLaVA$^w$ (76.7 vs. 70.7) and MM-Vet (40.2 vs. 35.4). We release our data and model at https://github.com/X2FD/LVIS-INSTRUCT4V.
Fast Normalized Cross-Correlation for Template Matching with Rotations
Nov 13, 2023Normalized cross-correlation is the reference approach to carry out template matching on images. When it is computed in Fourier space, it can handle efficiently template translations but it cannot do so with template rotations. Including rotations requires sampling the whole space of rotations, repeating the computation of the correlation each time. This article develops an alternative mathematical theory to handle efficiently, at the same time, rotations and translations. Our proposal has a reduced computational complexity because it does not require to repeatedly sample the space of rotations. To do so, we integrate the information relative to all rotated versions of the template into a unique symmetric tensor template -which is computed only once per template-. Afterward, we demonstrate that the correlation between the image to be processed with the independent tensor components of the tensorial template contains enough information to recover template instance positions and rotations. Our proposed method has the potential to speed up conventional template matching computations by a factor of several magnitude orders for the case of 3D images.