 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
CV-Attention UNet: Attention-based UNet for 3D Cerebrovascular Segmentation of Enhanced TOF-MRA Images
Nov 16, 2023
Due to the lack of automated methods, to diagnose cerebrovascular disease, time-of-flight magnetic resonance angiography (TOF-MRA) is assessed visually, making it time-consuming. The commonly used encoder-decoder architectures for cerebrovascular segmentation utilize redundant features, eventually leading to the extraction of low-level features multiple times. Additionally, convolutional neural networks (CNNs) suffer from performance degradation when the batch size is small, and deeper networks experience the vanishing gradient problem. Methods: In this paper, we attempt to solve these limitations and propose the 3D cerebrovascular attention UNet method, named CV-AttentionUNet, for precise extraction of brain vessel images. We proposed a sequence of preprocessing techniques followed by deeply supervised UNet to improve the accuracy of segmentation of the brain vessels leading to a stroke. To combine the low and high semantics, we applied the attention mechanism. This mechanism focuses on relevant associations and neglects irrelevant anatomical information. Furthermore, the inclusion of deep supervision incorporates different levels of features that prove to be beneficial for network convergence. Results: We demonstrate the efficiency of the proposed method by cross-validating with an unlabeled dataset, which was further labeled by us. We believe that the novelty of this algorithm lies in its ability to perform well on both labeled and unlabeled data with image processing-based enhancement. The results indicate that our method performed better than the existing state-of-the-art methods on the TubeTK dataset. Conclusion: The proposed method will help in accurate segmentation of cerebrovascular structure leading to stroke
MetaDreamer: Efficient Text-to-3D Creation With Disentangling Geometry and Texture
Nov 16, 2023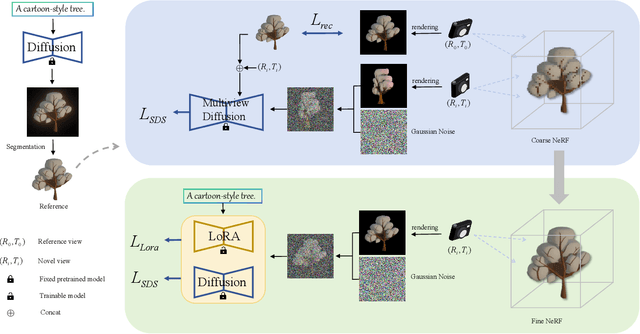
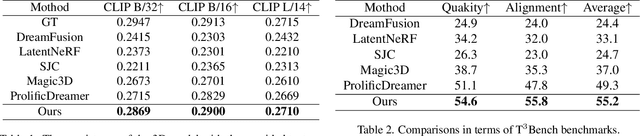


Generative models for 3D object synthesis have seen significant advancements with the incorporation of prior knowledge distilled from 2D diffusion models. Nevertheless, challenges persist in the form of multi-view geometric inconsistencies and slow generation speeds within the existing 3D synthesis frameworks. This can be attributed to two factors: firstly, the deficiency of abundant geometric a priori knowledge in optimization, and secondly, the entanglement issue between geometry and texture in conventional 3D generation methods.In response, we introduce MetaDreammer, a two-stage optimization approach that leverages rich 2D and 3D prior knowledge. In the first stage, our emphasis is on optimizing the geometric representation to ensure multi-view consistency and accuracy of 3D objects. In the second stage, we concentrate on fine-tuning the geometry and optimizing the texture, thereby achieving a more refined 3D object. Through leveraging 2D and 3D prior knowledge in two stages, respectively, we effectively mitigate the interdependence between geometry and texture. MetaDreamer establishes clear optimization objectives for each stage, resulting in significant time savings in the 3D generation process. Ultimately, MetaDreamer can generate high-quality 3D objects based on textual prompts within 20 minutes, and to the best of our knowledge, it is the most efficient text-to-3D generation method. Furthermore, we introduce image control into the process, enhancing the controllability of 3D generation. Extensive empirical evidence confirms that our method is not only highly efficient but also achieves a quality level that is at the forefront of current state-of-the-art 3D generation techniques.
One-Shot Federated Learning with Classifier-Guided Diffusion Models
Nov 16, 2023One-shot federated learning (OSFL) has gained attention in recent years due to its low communication cost. However, most of the existing methods require auxiliary datasets or training generators, which hinders their practicality in real-world scenarios. In this paper, we explore the novel opportunities that diffusion models bring to OSFL and propose FedCADO, utilizing guidance from client classifiers to generate data that complies with clients' distributions and subsequently training the aggregated model on the server. Specifically, our method involves targeted optimizations in two aspects. On one hand, we conditionally edit the randomly sampled initial noises, embedding them with specified semantics and distributions, resulting in a significant improvement in both the quality and stability of generation. On the other hand, we employ the BN statistics from the classifiers to provide detailed guidance during generation. These tailored optimizations enable us to limitlessly generate datasets, which closely resemble the distribution and quality of the original client dataset. Our method effectively handles the heterogeneous client models and the problems of non-IID features or labels. In terms of privacy protection, our method avoids training any generator or transferring any auxiliary information on clients, eliminating any additional privacy leakage risks. Leveraging the extensive knowledge stored in the pre-trained diffusion model, the synthetic datasets can assist us in surpassing the knowledge limitations of the client samples, resulting in aggregation models that even outperform the performance ceiling of centralized training in some cases, which is convincingly demonstrated in the sufficient quantification and visualization experiments conducted on three large-scale multi-domain image datasets.
IterInv: Iterative Inversion for Pixel-Level T2I Models
Oct 30, 2023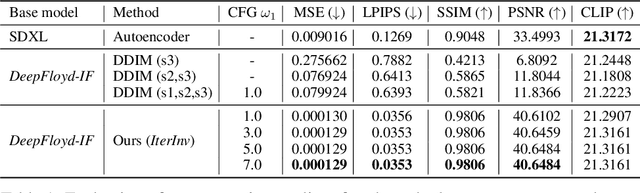

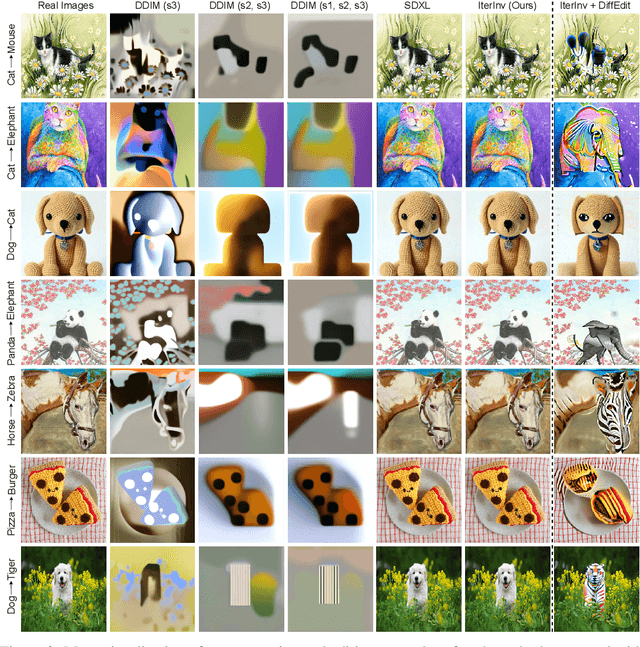
Large-scale text-to-image diffusion models have been a ground-breaking development in generating convincing images following an input text prompt. The goal of image editing research is to give users control over the generated images by modifying the text prompt. Current image editing techniques are relying on DDIM inversion as a common practice based on the Latent Diffusion Models (LDM). However, the large pretrained T2I models working on the latent space as LDM suffer from losing details due to the first compression stage with an autoencoder mechanism. Instead, another mainstream T2I pipeline working on the pixel level, such as Imagen and DeepFloyd-IF, avoids this problem. They are commonly composed of several stages, normally with a text-to-image stage followed by several super-resolution stages. In this case, the DDIM inversion is unable to find the initial noise to generate the original image given that the super-resolution diffusion models are not compatible with the DDIM technique. According to our experimental findings, iteratively concatenating the noisy image as the condition is the root of this problem. Based on this observation, we develop an iterative inversion (IterInv) technique for this stream of T2I models and verify IterInv with the open-source DeepFloyd-IF model. By combining our method IterInv with a popular image editing method, we prove the application prospects of IterInv. The code will be released at \url{https://github.com/Tchuanm/IterInv.git}.
Structural-Based Uncertainty in Deep Learning Across Anatomical Scales: Analysis in White Matter Lesion Segmentation
Nov 15, 2023This paper explores uncertainty quantification (UQ) as an indicator of the trustworthiness of automated deep-learning (DL) tools in the context of white matter lesion (WML) segmentation from magnetic resonance imaging (MRI) scans of multiple sclerosis (MS) patients. Our study focuses on two principal aspects of uncertainty in structured output segmentation tasks. Firstly, we postulate that a good uncertainty measure should indicate predictions likely to be incorrect with high uncertainty values. Second, we investigate the merit of quantifying uncertainty at different anatomical scales (voxel, lesion, or patient). We hypothesize that uncertainty at each scale is related to specific types of errors. Our study aims to confirm this relationship by conducting separate analyses for in-domain and out-of-domain settings. Our primary methodological contributions are (i) the development of novel measures for quantifying uncertainty at lesion and patient scales, derived from structural prediction discrepancies, and (ii) the extension of an error retention curve analysis framework to facilitate the evaluation of UQ performance at both lesion and patient scales. The results from a multi-centric MRI dataset of 172 patients demonstrate that our proposed measures more effectively capture model errors at the lesion and patient scales compared to measures that average voxel-scale uncertainty values. We provide the UQ protocols code at https://github.com/Medical-Image-Analysis-Laboratory/MS_WML_uncs.
Synthetic Image Detection: Highlights from the IEEE Video and Image Processing Cup 2022 Student Competition
Sep 21, 2023
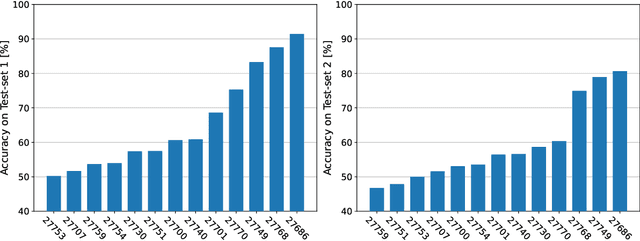
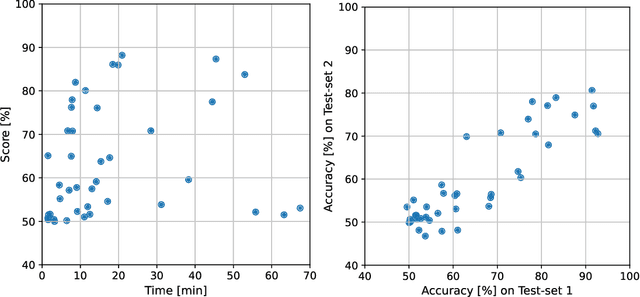
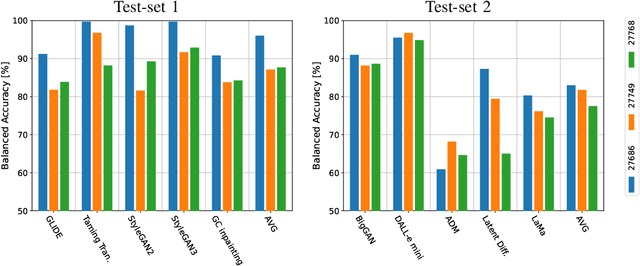
The Video and Image Processing (VIP) Cup is a student competition that takes place each year at the IEEE International Conference on Image Processing. The 2022 IEEE VIP Cup asked undergraduate students to develop a system capable of distinguishing pristine images from generated ones. The interest in this topic stems from the incredible advances in the AI-based generation of visual data, with tools that allows the synthesis of highly realistic images and videos. While this opens up a large number of new opportunities, it also undermines the trustworthiness of media content and fosters the spread of disinformation on the internet. Recently there was strong concern about the generation of extremely realistic images by means of editing software that includes the recent technology on diffusion models. In this context, there is a need to develop robust and automatic tools for synthetic image detection.
Decompose Semantic Shifts for Composed Image Retrieval
Sep 18, 2023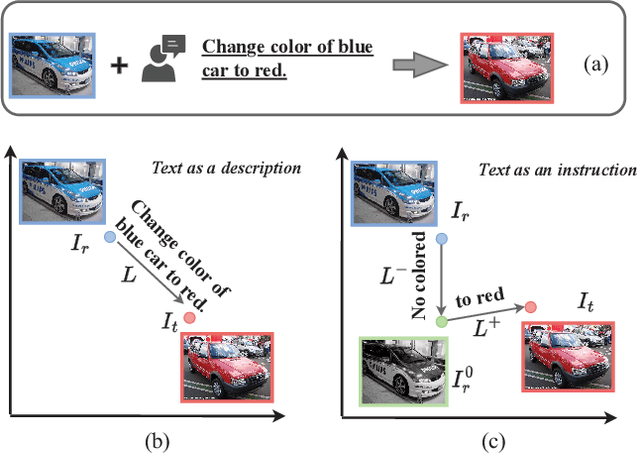
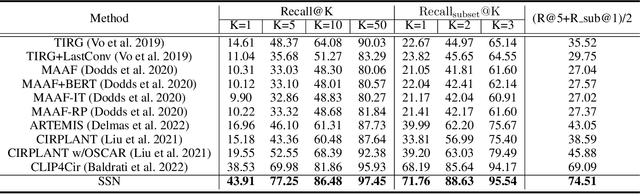

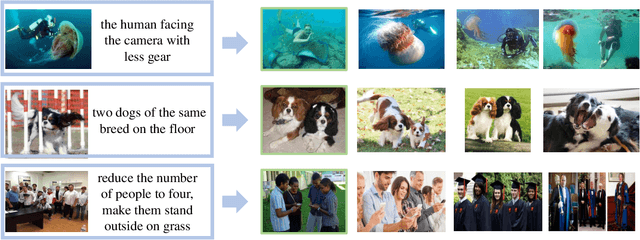
Composed image retrieval is a type of image retrieval task where the user provides a reference image as a starting point and specifies a text on how to shift from the starting point to the desired target image. However, most existing methods focus on the composition learning of text and reference images and oversimplify the text as a description, neglecting the inherent structure and the user's shifting intention of the texts. As a result, these methods typically take shortcuts that disregard the visual cue of the reference images. To address this issue, we reconsider the text as instructions and propose a Semantic Shift network (SSN) that explicitly decomposes the semantic shifts into two steps: from the reference image to the visual prototype and from the visual prototype to the target image. Specifically, SSN explicitly decomposes the instructions into two components: degradation and upgradation, where the degradation is used to picture the visual prototype from the reference image, while the upgradation is used to enrich the visual prototype into the final representations to retrieve the desired target image. The experimental results show that the proposed SSN demonstrates a significant improvement of 5.42% and 1.37% on the CIRR and FashionIQ datasets, respectively, and establishes a new state-of-the-art performance. Codes will be publicly available.
Steered Diffusion: A Generalized Framework for Plug-and-Play Conditional Image Synthesis
Sep 30, 2023
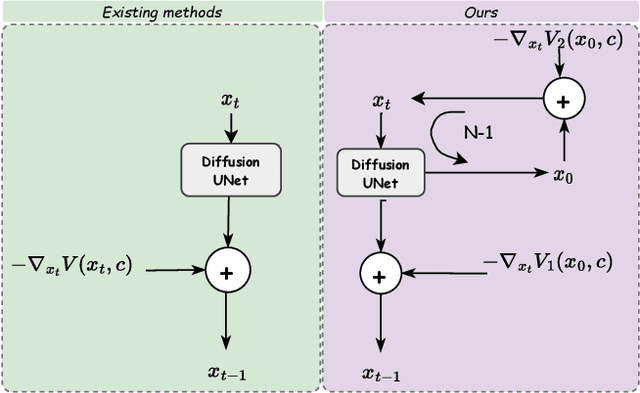
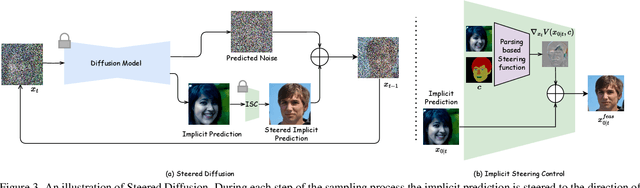
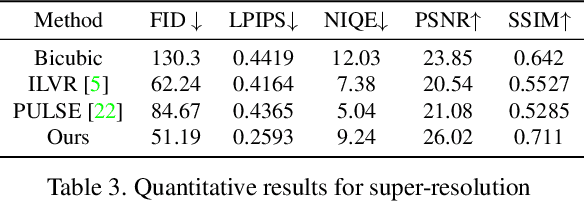
Conditional generative models typically demand large annotated training sets to achieve high-quality synthesis. As a result, there has been significant interest in designing models that perform plug-and-play generation, i.e., to use a predefined or pretrained model, which is not explicitly trained on the generative task, to guide the generative process (e.g., using language). However, such guidance is typically useful only towards synthesizing high-level semantics rather than editing fine-grained details as in image-to-image translation tasks. To this end, and capitalizing on the powerful fine-grained generative control offered by the recent diffusion-based generative models, we introduce Steered Diffusion, a generalized framework for photorealistic zero-shot conditional image generation using a diffusion model trained for unconditional generation. The key idea is to steer the image generation of the diffusion model at inference time via designing a loss using a pre-trained inverse model that characterizes the conditional task. This loss modulates the sampling trajectory of the diffusion process. Our framework allows for easy incorporation of multiple conditions during inference. We present experiments using steered diffusion on several tasks including inpainting, colorization, text-guided semantic editing, and image super-resolution. Our results demonstrate clear qualitative and quantitative improvements over state-of-the-art diffusion-based plug-and-play models while adding negligible additional computational cost.
Guided Frequency Loss for Image Restoration
Sep 27, 2023Image Restoration has seen remarkable progress in recent years. Many generative models have been adapted to tackle the known restoration cases of images. However, the interest in benefiting from the frequency domain is not well explored despite its major factor in these particular cases of image synthesis. In this study, we propose the Guided Frequency Loss (GFL), which helps the model to learn in a balanced way the image's frequency content alongside the spatial content. It aggregates three major components that work in parallel to enhance learning efficiency; a Charbonnier component, a Laplacian Pyramid component, and a Gradual Frequency component. We tested GFL on the Super Resolution and the Denoising tasks. We used three different datasets and three different architectures for each of them. We found that the GFL loss improved the PSNR metric in most implemented experiments. Also, it improved the training of the Super Resolution models in both SwinIR and SRGAN. In addition, the utility of the GFL loss increased better on constrained data due to the less stochasticity in the high frequencies' components among samples.
To See is to Believe: Prompting GPT-4V for Better Visual Instruction Tuning
Nov 13, 2023Existing visual instruction tuning methods typically prompt large language models with textual descriptions to generate instruction-following data. Despite the promising performance achieved, these descriptions are derived from image annotations, which are oftentimes coarse-grained. Furthermore, the instructions might even contradict the visual content without observing the entire visual context. To address this challenge, we introduce a fine-grained visual instruction dataset, LVIS-Instruct4V, which contains 220K visually aligned and context-aware instructions produced by prompting the powerful GPT-4V with images from LVIS. Through experimental validation and case studies, we demonstrate that high-quality visual instructional data could improve the performance of LLaVA-1.5, a state-of-the-art large multimodal model, across a wide spectrum of benchmarks by clear margins. Notably, by simply replacing the LLaVA-Instruct with our LVIS-Instruct4V, we achieve better results than LLaVA on most challenging LMM benchmarks, e.g., LLaVA$^w$ (76.7 vs. 70.7) and MM-Vet (40.2 vs. 35.4). We release our data and model at https://github.com/X2FD/LVIS-INSTRUCT4V.