 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Efficient-3DiM: Learning a Generalizable Single-image Novel-view Synthesizer in One Day
Oct 04, 2023


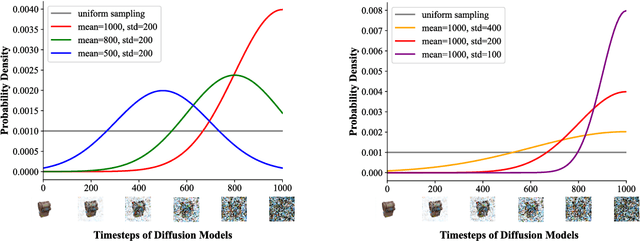
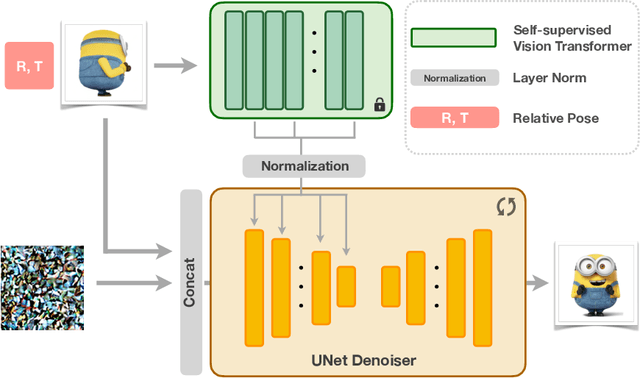
The task of novel view synthesis aims to generate unseen perspectives of an object or scene from a limited set of input images. Nevertheless, synthesizing novel views from a single image still remains a significant challenge in the realm of computer vision. Previous approaches tackle this problem by adopting mesh prediction, multi-plain image construction, or more advanced techniques such as neural radiance fields. Recently, a pre-trained diffusion model that is specifically designed for 2D image synthesis has demonstrated its capability in producing photorealistic novel views, if sufficiently optimized on a 3D finetuning task. Although the fidelity and generalizability are greatly improved, training such a powerful diffusion model requires a vast volume of training data and model parameters, resulting in a notoriously long time and high computational costs. To tackle this issue, we propose Efficient-3DiM, a simple but effective framework to learn a single-image novel-view synthesizer. Motivated by our in-depth analysis of the inference process of diffusion models, we propose several pragmatic strategies to reduce the training overhead to a manageable scale, including a crafted timestep sampling strategy, a superior 3D feature extractor, and an enhanced training scheme. When combined, our framework is able to reduce the total training time from 10 days to less than 1 day, significantly accelerating the training process under the same computational platform (one instance with 8 Nvidia A100 GPUs). Comprehensive experiments are conducted to demonstrate the efficiency and generalizability of our proposed method.
This Looks Like Those: Illuminating Prototypical Concepts Using Multiple Visualizations
Oct 28, 2023We present ProtoConcepts, a method for interpretable image classification combining deep learning and case-based reasoning using prototypical parts. Existing work in prototype-based image classification uses a ``this looks like that'' reasoning process, which dissects a test image by finding prototypical parts and combining evidence from these prototypes to make a final classification. However, all of the existing prototypical part-based image classifiers provide only one-to-one comparisons, where a single training image patch serves as a prototype to compare with a part of our test image. With these single-image comparisons, it can often be difficult to identify the underlying concept being compared (e.g., ``is it comparing the color or the shape?''). Our proposed method modifies the architecture of prototype-based networks to instead learn prototypical concepts which are visualized using multiple image patches. Having multiple visualizations of the same prototype allows us to more easily identify the concept captured by that prototype (e.g., ``the test image and the related training patches are all the same shade of blue''), and allows our model to create richer, more interpretable visual explanations. Our experiments show that our ``this looks like those'' reasoning process can be applied as a modification to a wide range of existing prototypical image classification networks while achieving comparable accuracy on benchmark datasets.
Perceptual MAE for Image Manipulation Localization: A High-level Vision Learner Focusing on Low-level Features
Oct 10, 2023
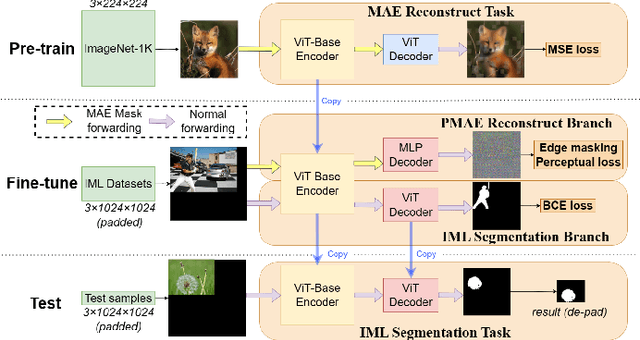
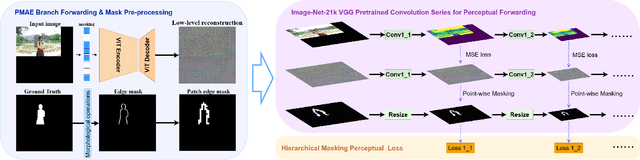
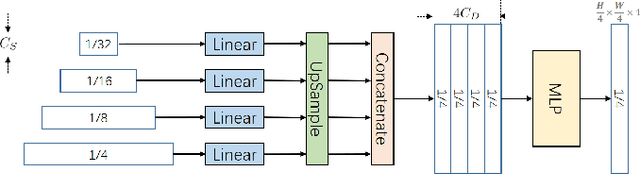
Nowadays, multimedia forensics faces unprecedented challenges due to the rapid advancement of multimedia generation technology thereby making Image Manipulation Localization (IML) crucial in the pursuit of truth. The key to IML lies in revealing the artifacts or inconsistencies between the tampered and authentic areas, which are evident under pixel-level features. Consequently, existing studies treat IML as a low-level vision task, focusing on allocating tampered masks by crafting pixel-level features such as image RGB noises, edge signals, or high-frequency features. However, in practice, tampering commonly occurs at the object level, and different classes of objects have varying likelihoods of becoming targets of tampering. Therefore, object semantics are also vital in identifying the tampered areas in addition to pixel-level features. This necessitates IML models to carry out a semantic understanding of the entire image. In this paper, we reformulate the IML task as a high-level vision task that greatly benefits from low-level features. Based on such an interpretation, we propose a method to enhance the Masked Autoencoder (MAE) by incorporating high-resolution inputs and a perceptual loss supervision module, which is termed Perceptual MAE (PMAE). While MAE has demonstrated an impressive understanding of object semantics, PMAE can also compensate for low-level semantics with our proposed enhancements. Evidenced by extensive experiments, this paradigm effectively unites the low-level and high-level features of the IML task and outperforms state-of-the-art tampering localization methods on all five publicly available datasets.
Decompose Semantic Shifts for Composed Image Retrieval
Sep 18, 2023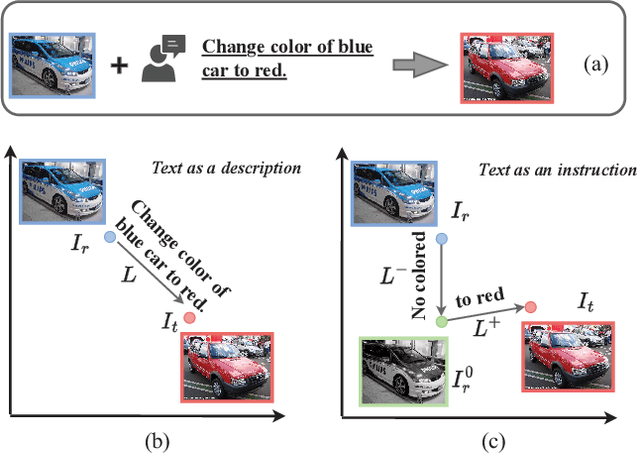
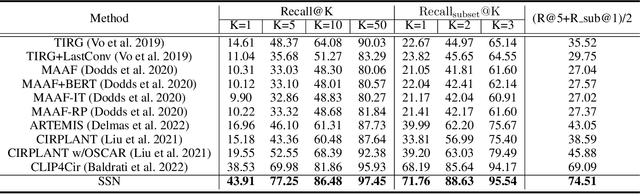

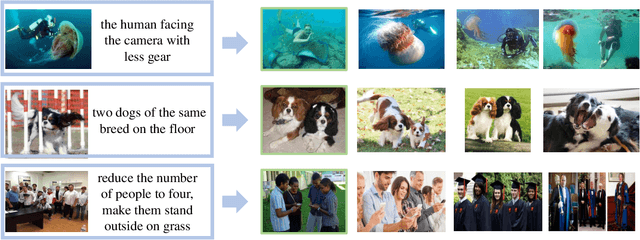
Composed image retrieval is a type of image retrieval task where the user provides a reference image as a starting point and specifies a text on how to shift from the starting point to the desired target image. However, most existing methods focus on the composition learning of text and reference images and oversimplify the text as a description, neglecting the inherent structure and the user's shifting intention of the texts. As a result, these methods typically take shortcuts that disregard the visual cue of the reference images. To address this issue, we reconsider the text as instructions and propose a Semantic Shift network (SSN) that explicitly decomposes the semantic shifts into two steps: from the reference image to the visual prototype and from the visual prototype to the target image. Specifically, SSN explicitly decomposes the instructions into two components: degradation and upgradation, where the degradation is used to picture the visual prototype from the reference image, while the upgradation is used to enrich the visual prototype into the final representations to retrieve the desired target image. The experimental results show that the proposed SSN demonstrates a significant improvement of 5.42% and 1.37% on the CIRR and FashionIQ datasets, respectively, and establishes a new state-of-the-art performance. Codes will be publicly available.
Cross-head mutual Mean-Teaching for semi-supervised medical image segmentation
Oct 16, 2023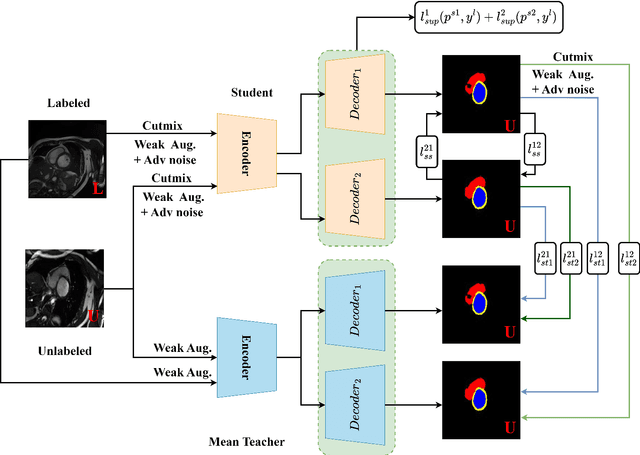
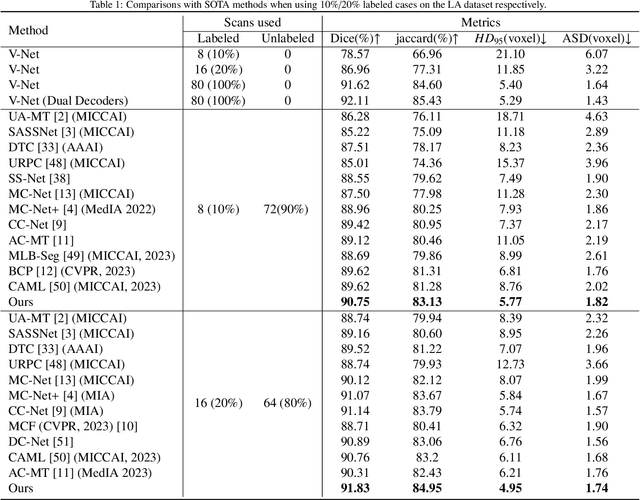
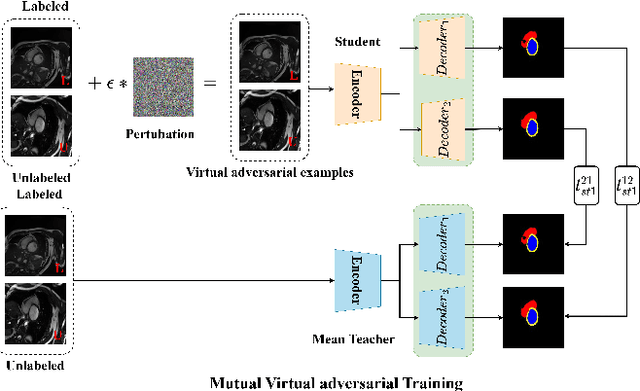
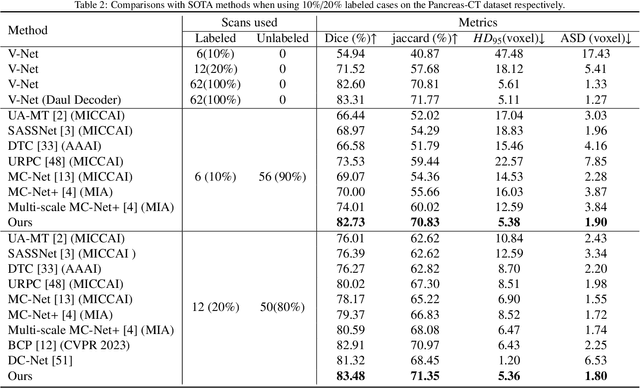
Semi-supervised medical image segmentation (SSMIS) has witnessed substantial advancements by leveraging limited labeled data and abundant unlabeled data. Nevertheless, existing state-of-the-art (SOTA) methods encounter challenges in accurately predicting labels for the unlabeled data, giving rise to disruptive noise during training and susceptibility to erroneous information overfitting. Moreover, applying perturbations to inaccurate predictions further reduces consistent learning. To address these concerns, we propose a novel Cross-head mutual mean-teaching Network (CMMT-Net) incorporated strong-weak data augmentation, thereby benefitting both self-training and consistency learning. Specifically, our CMMT-Net consists of both teacher-student peer networks with a share encoder and dual slightly different decoders, and the pseudo labels generated by one mean teacher head are adopted to supervise the other student branch to achieve a mutual consistency. Furthermore, we propose mutual virtual adversarial training (MVAT) to smooth the decision boundary and enhance feature representations. To diversify the consistency training samples, we employ Cross-Set CutMix strategy, which also helps address distribution mismatch issues. Notably, CMMT-Net simultaneously implements data, feature, and network perturbations, amplifying model diversity and generalization performance. Experimental results on three publicly available datasets indicate that our approach yields remarkable improvements over previous SOTA methods across various semi-supervised scenarios. Code and logs will be available at https://github.com/Leesoon1984/CMMT-Net.
A Simple and Robust Framework for Cross-Modality Medical Image Segmentation applied to Vision Transformers
Oct 09, 2023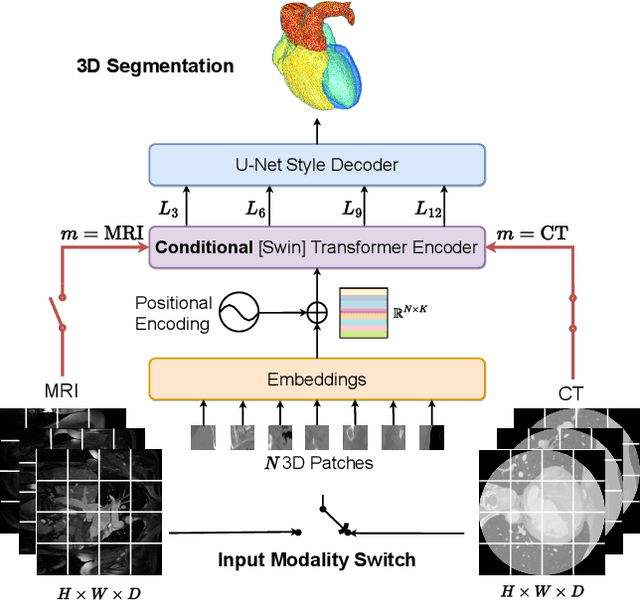
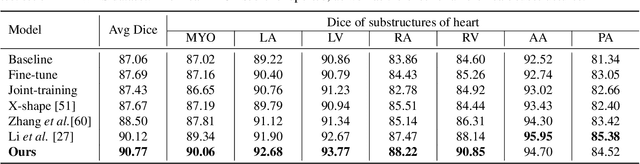
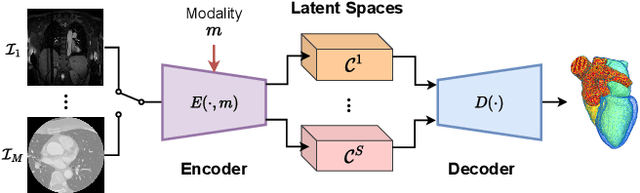

When it comes to clinical images, automatic segmentation has a wide variety of applications and a considerable diversity of input domains, such as different types of Magnetic Resonance Images (MRIs) and Computerized Tomography (CT) scans. This heterogeneity is a challenge for cross-modality algorithms that should equally perform independently of the input image type fed to them. Often, segmentation models are trained using a single modality, preventing generalization to other types of input data without resorting to transfer learning techniques. Furthermore, the multi-modal or cross-modality architectures proposed in the literature frequently require registered images, which are not easy to collect in clinical environments, or need additional processing steps, such as synthetic image generation. In this work, we propose a simple framework to achieve fair image segmentation of multiple modalities using a single conditional model that adapts its normalization layers based on the input type, trained with non-registered interleaved mixed data. We show that our framework outperforms other cross-modality segmentation methods, when applied to the same 3D UNet baseline model, on the Multi-Modality Whole Heart Segmentation Challenge. Furthermore, we define the Conditional Vision Transformer (C-ViT) encoder, based on the proposed cross-modality framework, and we show that it brings significant improvements to the resulting segmentation, up to 6.87\% of Dice accuracy, with respect to its baseline reference. The code to reproduce our experiments and the trained model weights are available at https://github.com/matteo-bastico/MI-Seg.
R&B: Region and Boundary Aware Zero-shot Grounded Text-to-image Generation
Oct 17, 2023Recent text-to-image (T2I) diffusion models have achieved remarkable progress in generating high-quality images given text-prompts as input. However, these models fail to convey appropriate spatial composition specified by a layout instruction. In this work, we probe into zero-shot grounded T2I generation with diffusion models, that is, generating images corresponding to the input layout information without training auxiliary modules or finetuning diffusion models. We propose a Region and Boundary (R&B) aware cross-attention guidance approach that gradually modulates the attention maps of diffusion model during generative process, and assists the model to synthesize images (1) with high fidelity, (2) highly compatible with textual input, and (3) interpreting layout instructions accurately. Specifically, we leverage the discrete sampling to bridge the gap between consecutive attention maps and discrete layout constraints, and design a region-aware loss to refine the generative layout during diffusion process. We further propose a boundary-aware loss to strengthen object discriminability within the corresponding regions. Experimental results show that our method outperforms existing state-of-the-art zero-shot grounded T2I generation methods by a large margin both qualitatively and quantitatively on several benchmarks.
SalUn: Empowering Machine Unlearning via Gradient-based Weight Saliency in Both Image Classification and Generation
Oct 19, 2023With evolving data regulations, machine unlearning (MU) has become an important tool for fostering trust and safety in today's AI models. However, existing MU methods focusing on data and/or weight perspectives often grapple with limitations in unlearning accuracy, stability, and cross-domain applicability. To address these challenges, we introduce the concept of 'weight saliency' in MU, drawing parallels with input saliency in model explanation. This innovation directs MU's attention toward specific model weights rather than the entire model, improving effectiveness and efficiency. The resultant method that we call saliency unlearning (SalUn) narrows the performance gap with 'exact' unlearning (model retraining from scratch after removing the forgetting dataset). To the best of our knowledge, SalUn is the first principled MU approach adaptable enough to effectively erase the influence of forgetting data, classes, or concepts in both image classification and generation. For example, SalUn yields a stability advantage in high-variance random data forgetting, e.g., with a 0.2% gap compared to exact unlearning on the CIFAR-10 dataset. Moreover, in preventing conditional diffusion models from generating harmful images, SalUn achieves nearly 100% unlearning accuracy, outperforming current state-of-the-art baselines like Erased Stable Diffusion and Forget-Me-Not.
IterInv: Iterative Inversion for Pixel-Level T2I Models
Oct 30, 2023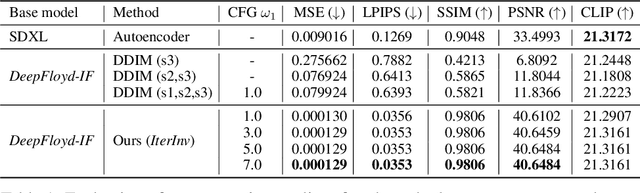

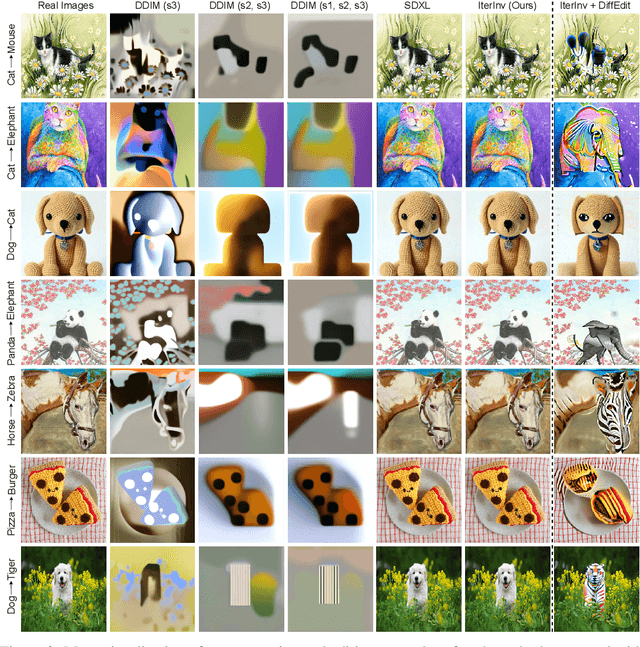
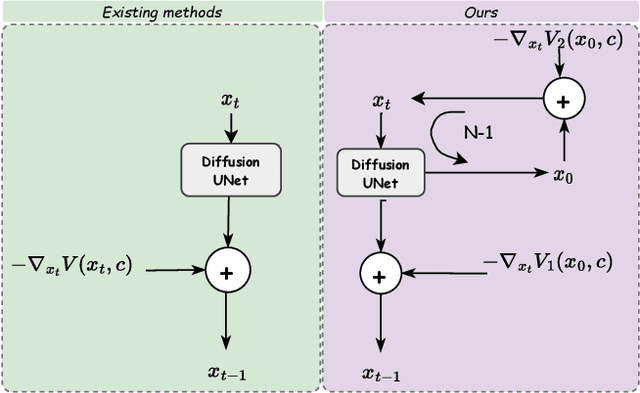
Large-scale text-to-image diffusion models have been a ground-breaking development in generating convincing images following an input text prompt. The goal of image editing research is to give users control over the generated images by modifying the text prompt. Current image editing techniques are relying on DDIM inversion as a common practice based on the Latent Diffusion Models (LDM). However, the large pretrained T2I models working on the latent space as LDM suffer from losing details due to the first compression stage with an autoencoder mechanism. Instead, another mainstream T2I pipeline working on the pixel level, such as Imagen and DeepFloyd-IF, avoids this problem. They are commonly composed of several stages, normally with a text-to-image stage followed by several super-resolution stages. In this case, the DDIM inversion is unable to find the initial noise to generate the original image given that the super-resolution diffusion models are not compatible with the DDIM technique. According to our experimental findings, iteratively concatenating the noisy image as the condition is the root of this problem. Based on this observation, we develop an iterative inversion (IterInv) technique for this stream of T2I models and verify IterInv with the open-source DeepFloyd-IF model. By combining our method IterInv with a popular image editing method, we prove the application prospects of IterInv. The code will be released at \url{https://github.com/Tchuanm/IterInv.git}.
Steered Diffusion: A Generalized Framework for Plug-and-Play Conditional Image Synthesis
Sep 30, 2023
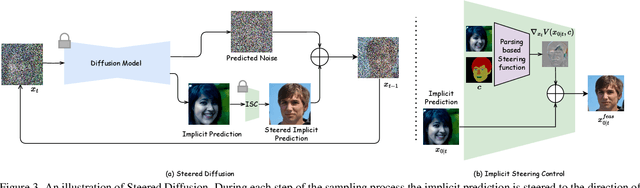
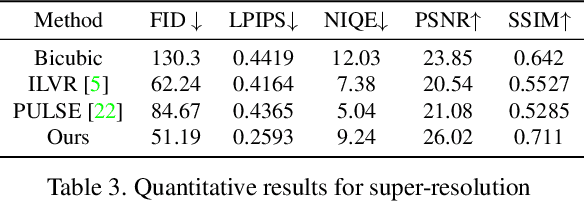
Conditional generative models typically demand large annotated training sets to achieve high-quality synthesis. As a result, there has been significant interest in designing models that perform plug-and-play generation, i.e., to use a predefined or pretrained model, which is not explicitly trained on the generative task, to guide the generative process (e.g., using language). However, such guidance is typically useful only towards synthesizing high-level semantics rather than editing fine-grained details as in image-to-image translation tasks. To this end, and capitalizing on the powerful fine-grained generative control offered by the recent diffusion-based generative models, we introduce Steered Diffusion, a generalized framework for photorealistic zero-shot conditional image generation using a diffusion model trained for unconditional generation. The key idea is to steer the image generation of the diffusion model at inference time via designing a loss using a pre-trained inverse model that characterizes the conditional task. This loss modulates the sampling trajectory of the diffusion process. Our framework allows for easy incorporation of multiple conditions during inference. We present experiments using steered diffusion on several tasks including inpainting, colorization, text-guided semantic editing, and image super-resolution. Our results demonstrate clear qualitative and quantitative improvements over state-of-the-art diffusion-based plug-and-play models while adding negligible additional computational cost.